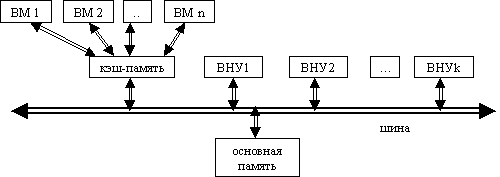
Рисунок 3.1 Многопроцессорная ВС с общим кэшем и общей памятью
Главной причиной использование многопроцессорных ЭВМ является их высокая производительность, при обычных технологиях производства узлов вычислительной системы. Несколько процессоров в составе ВС могут функционировать параллельно во времени и независимо друг от друга и вместе с тем взаимодействовать между собой и с другим оборудованием системы. Производительность многопроцессорных систем увеличивается за счет того, что мультипроцессорная организация создает возможность для одновременной обработки нескольких задач или параллельной обработки одной задачи [6].
В структурной организации многопроцессорной системы наиболее существенен способ связи между процессорами и памятью системы [3].
Параллельные вычислительные системы делятся на два больших класса: SIMD и MIMD. SIMD (single instruction - multiple data) - "один поток команд - много потоков данных" - команды выдаются одним управляющим процессором, а выполняются одновременно на всех обрабатывающих процессорах над локальными данными этих процессоров. MIMD (multiple instruction - multiple data) - "много потоков команд - много потоков данных" - совокупность компьютеров, работающих по своим программам и со своими исходными данными.
В настоящее время осваиваются супервычисления на системах из микро-процессоров с кэш-памятями и разделяемой (логически - общей) физически распределенной основной памятью.
Существующие параллельные вычислительные средства класса MIMD образуют три подкласса: симметричные мультипроцессоры (SMP), кластеры и массово параллельные системы (МРР).
Симметричные мультипроцессоры состоят из совокупности процессоров, обладающих одинаковыми возможностями доступа к памяти и внешним устройствам и функционирующих под управлением одной операционной системы (ОС). Частным случаем SMP служат однопроцессорные компьютеры. Все процессоры SMP имеют разделяемую общую память с единым адресным пространством.
Использование SMP обеспечивает следующие возможности:
Однако степень масштабируемости SMP систем ограничена в пределах технической реализуемости одинакового для всех процессоров доступа в память со скоростью, характерной для однопроцессорных компьютеров. Как правило, количество процессоров в SMP не превышает 32. На данный момент SMP структура наиболее распространена в классе профессиональных рабочих станций на базе RISC процессоров.
Для построения систем с большим числом процессоров применяются кластерный или МРР подходы. Оба эти направления используют SMP как системообразующий вычислительный модуль (ВМ).
Кластерная система образуется из модулей, объединенных системой связи или разделяемыми устройствами внешней памяти, например дисковыми массивами. В настоящее время для образования кластерных систем используются либо специализированные фирменные средства (например, MEMORY CHANNEL фирмы DEC), либо универсальные локальные и глобальные сети такие, как Ethernet, FDDI (Fiber Distributed Data Interface), и другие сети, например, с протоколами TCP/IP (Transmission Control Protocol / Internet Protocol), либо дисковые массивы с высокоскоростными широкими двойными (Wide/Fast) и квадро PCI SCSI контроллерами [5].
Размер кластера варьируется от нескольких модулей до нескольких десятков модулей.
Массово параллельные системы, в отличие от кластеров, имеют более скоростные, как правило специализированные, каналы связи между ВМ, а также широкие возможности по масштабированию. Кроме того, в МРР фиксируется некоторый достаточно высокий уровень интерфейса прикладных программ (API), поддерживаемый распределенной ОС. Однако поддержка работоспособности и оптимизация загрузки процессоров в МРР менее развита по сравнению с кластерами в силу разнообразности исполняемых программ и отсутствия функциональных связей между программами
Начиная с 1980 года идея SMP архитектур, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание небольших мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины [3]. Из-за малого размера процессоров и заметного сокращения требуемой полосы пропускания шины, достигнутого за счет возможности реализации достаточно большой кэш-памяти, такие машины стали исключительно эффективными по стоимости. В первых разработках подобного рода машин удавалось разместить весь процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная архитектура. Современные конструкции позволяют разместить до четырех процессоров на одной плате, предел количества процессоров в SMP - не более 32-х [5].
Общий вид такой многопроцессорной ВС представлен на рисунке 3.1. Здесь ВМ - вычислительный модуль (процессор), всего n-штук, ВНУ - внешние устройства, всего k-штук.
В качестве основной памяти может использоваться память с горизонтальным расслоением или же для повышения надежности - блочно-модульная память.
Основными проблемами в данной архитектуре являются следующие: скорость работы кэш памяти, блокировка при совместном доступе нескольких процессоров на одновременную запись или запись/чтение данных по одному и тому же адресу. Кэш-память должна работать с тактовой частотой в n раз большей тактовой частоты процессора, т.к. она должна обеспечивать данными процессоры с частотой один раз в такт. В противном случае каждый процессор должен быть блокирован до момента получения (или записи) им требуемых данных, что очень сильно снижает производительность и вообще смысл многопроцессорной ВС.
Вообще такая структура сходна с однопроцессорной ВС с кэшем. Она недостаточно эффективна и как правило практически не применяется.
Данная модель мультипроцессорной системы наиболее распространена в настоящее время. Структурная схема многопроцессорной ВС с раздельными кэшами и общей памятью представлен на рисунке 3.2.
Каждый ВМ имеет собственную локальную кэш-память, имеется общая разделяемая основная память, все вычислительные модули (ВМ) подсоединены к основной памяти посредством шины. К шине подключены также внешние устройства. Все действия с использованием транзакций шины, производимые ВМ и внешними устройствами, с копиями строк, как в каждой кэш-памяти, так и в основной памяти, доступны для отслеживания всем ВМ. Это является следствием того, что в каждый момент на шине передает только один, а воспринимают все, подключенные к шине абоненты.
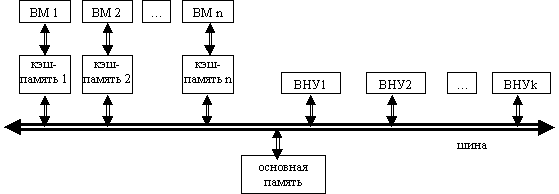
По сравнению с многопроцессорная ВС с общим кэшам и общей памятью в данной системе возникает наряду с проблемой пропускной способности шины еще и проблема когерентности кэш-памяти.
В такой вычислительной системе кэши могут содержать как разделяемые, так и частные данные. Частные данные - это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними. Когда кэшируется элемент частных данных, их значение переносится в кэш для сокращения среднего времени доступа, а также требуемой полосы пропускания. Поскольку никакой другой процессор не использует эти данные, этот процесс идентичен процессу для однопроцессорной машины с кэш-памятью. Если кэшируются разделяемые данные, то разделяемое значение реплицируется и может содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания такая репликация данных способствует также общему сокращению количества обменов. Т.о. кэширование разделяемых данных вызывает проблему когерентности кэш-памяти.
Обычно в малых мультипроцессорах используется аппаратный механизм, называемый протоколом, позволяющий решить эту проблему. Такие протоколы называются протоколами когерентности кэш-памяти [3]. Существуют два класса таких протоколов:
В мультипроцессорных системах, использующих микропроцессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение - шину памяти.
Имеются два подхода поддержания когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором. Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи можно потребовать, чтобы процессор имел достоверную копию данных в своей кэш-памяти прежде, чем выполнять в нее запись. Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго и вызывает аннулирование его копии. Другой процессор для завершения своей операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение. Представителем данного протокола является алгоритм MESI описанный в главе 3.5.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах. Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками:
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи. При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
Для обеспечения когерентности памяти модели ВС с раздельными кэшами и общей памятью можно использовать алгоритм MESI (Modified, Exclusive, Shared, Invalid) [5]. Алгоритм MESI представляет собой организацию когерентности кэш-памяти с обратной записью. Этот алгоритм предотвращает лишние передачи данных между кэш-памятью и основной памятью. Так, если данные в кэш-памяти не изменялись, то незачем их пересылать.
Каждая строка кэш-памяти ВМ может находиться в одном из следующих состояний:
М - строка модифицирована (доступна по чтению и записи только в этом ВМ, потому что модифицирована командой записи по сравнению со строкой основной памяти);Состояние строки используется, во-первых, для определения процессором ВМ возможности локального, без выхода на шину, доступа к данным в кэш-памяти, а, во-вторых, - для управления механизмом когерентности.
Для управления режимом работы механизма поддержки когерентности используется бит WT, состояние 1 которого задает режим сквозной (write-through) записи, а состояние 0 - режим обратной (write-back) записи в кэш-память.
При исполнении команд чтения и записи состояние строки кэш-памяти, к которой выполняется доступ, определяется таблицей 3.1.
Таблица 3.1 Переходы состояний кэш памяти| Исх. Состояние строки | Состояние после чтения | Состояние после записи |
| I | Если WT=1, тогда Е, иначе S; Обновление строки путем ее чтения из основной памяти | Сквозная запись в основную память; I |
| S | S | Сквозная запись в основную память; Если WT=1 тогда Е, иначе S |
| Е | Е | М |
| М | М | М |
Промах чтения в кэш-памяти заставляет вызвать строку из основной памяти и сопоставить ей состояние Е или S. Кэш-память заполняется только при промахах чтения. При промахе записи транзакция записи помещается в буфер и посылается в основную память при предоставлении шины.
При несостоятельной строке в состоянии I команда чтения данного из этой строки вызывает чтение строки из основной памяти, размещение ее в кэш-памяти и изменение состояния этой строки в кэш-памяти на Е или S. Состояние Е будет, если установлен режим сквозной записи, при котором запись производится и в строку кэш-памяти и в строку основной памяти. Состояние S устанавливается при режиме обратной записи, что позволяет модифицировать данные строки кэш-памяти без немедленной модификации строки основной памяти, что, в свою очередь, увеличивает производительность. До тех пор, пока к данным строки не будет доступа других ВМ или внешних устройств, не будет обратной записи, и ВМ не будет использовать шину.
При состоянии I строки команда записи в эту строку изменяет только содержимое строки основной памяти (сквозная запись), но не изменяет содержимое кэш-памяти и сохраняет состояние строки I.
В состоянии S строки чтение данного из этой строки не меняет ее состояние. Если установлен режим сквозной записи, то после завершения записи состояние строки меняется на Е, при режиме обратной записи выполняется сквозная запись, но состояние строки остается прежним S.
Если состояние строки Е, то чтение сохраняет это состояние, а запись переводит строку в состояние М.
Наконец, если состояние строки М, то как команды чтения, так и команды записи не меняют этого состояния.
Для поддержки когерентности строк кэш-памяти при операциях ввода/вывода и обращениях в основную память других процессоров на шине генерируются специальные циклы опроса состояния кэш-памятей. Эти циклы опрашивают кэш-памяти на предмет хранения в них строки, которой принадлежит адрес, используемый в операции, инициировавшей циклы опроса состояния. Возможен режим принудительного перевода строки в состояние I, который задается сигналом INV. При этом состояние строк определяется таблицей 3.2.
Таблица 3.2 Принудительный перевод строки в состояние I| Исходное состояние | INV=0 | INV=1 |
| I | I | I |
| S | S | I |
| Е | S | I |
| М | S; обратная запись строки | I; обратная запись строки |