ПРИМЕНЕНИЕ ГЕНЕТИЧЕСКИХ АЛГОРИТМОВ ДЛЯ ОБУЧЕНИЯ НЕЙРОННЫХ СЕТЕЙ
Федяев О.И., Соломка Ю.И.
(ДонНТУ, г.Донецк, Украина)
В теории нейронных сетей существуют две актуальных проблемы, одной из которых является выбор оптимальной структуры нейронной сети, а другой - построение эффективного алгоритма обучения нейронной сети.
Оптимизация нейронной сети направлена на уменьшение объёма вычислений при условии сохранения точности решения задачи на требуемом уровне. Параметрами оптимизации в нейронной сети могут быть:
размерность и структура входного сигнала нейросети;
синапсы нейронов сети. Они упрощаются с помощью удаления из сети или заданием "нужной" или "оптимальной" величины веса синапса;
количество нейронов каждого слоя сети: нейрон целиком удаляется из сети, с автоматическим удалением тех синапсов нейронов следующено слоя, по которым проходил его выходной сигнал;
количество слоёв сети.
Вторая проблема заключается в разработке качественных алгоритмов обучения нейросети, позволяющих за минимальное время настроить нейросеть на распознавание заданного набора входных образов. Моё сообщение посвящено именно этому вопросу.
Процесс обучения нейронной сети заключается в необходимости настройки сети таким образом, чтобы для некоторого множества входов давать желаемое (или, по крайней мере, близкое, сообразное с ним) множество выходов.
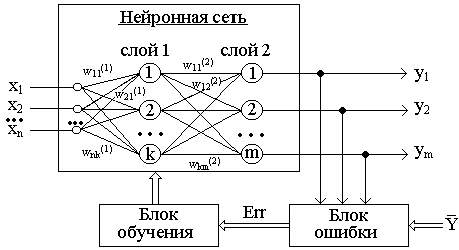
Рисунок 1 - Обучение "с учителем" многослойной нейронной сети
Стратегия "обучение с учителем" (рис. 1) предполагает, что есть обучающее множество {X,Y}.
Обучение осуществляется путем последовательного предъявления векторов обучающего множества, с одновременной подстройкой весов в соответствии с определенной процедурой, пока ошибка настройки по всему множеству не достигнет приемлемого низкого уровня.
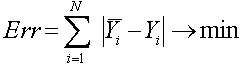
Зависимость реального выходного сигнала Y от входного сигнала X можно записать в виде: Y = F(W,X)+Err, где:
F(W,X) - некоторая функция, вид которой задается алгоритмом обучения нейронной сети;
W - множество параметров, позволяющих настроить функцию на решение определенной задачи распознавания образов (количество слоев сети, количество нейронов в каждом слое сети, матрица синаптических весов сети);
Err - некоторая ошибка, возникающая из-за неполного соответствия реального значения выходного сигнала нейронной сети требуемому значению, а также погрешности в вычислениях.
В последнее время для обучения многослойного персептрона широко используется процедура, получившая название алгоритма с обратным распространением ошибки (error backpropagation) [1].
Однако этому алгоритму свойственны недостатки[1]:
возможность преждевременной остановки из-за попадания в область локального минимума;
необходимость многократного предъявления всего обучающего множества для получения заданного качества распознавания.
отсутствие сколько-нибудь приемлемых оценок времени обучения.
Проблемы, связанные с алгоритмом обратного распространения привели к разработке альтернативных методов расчета весовых коэффициентов нейронных сетей. Впервые в 1989 году Дэвид Монтана и Лоуренс Дэвис использовали генетические алгоритмы в качестве средства подстройки весов скрытых и выходных слоев для фиксированного набора связей [2].
Генетический алгоритм является самым известным на данный момент представителем эволюционных алгоритмов и по своей сути является алгоритмом для нахождения глобального экстремума многоэкстремальной функции. Он заключается в параллельной обработке множества альтернативных решений. При этом поиск концентрируется на наиболее перспективных из них. Это говорит о возможности использования генетических алгоритмов при решении любых задач искусственного интеллекта, оптимизации, принятия решений.
Генетические алгоритмы для подстройки весов скрытых и выходных слоев используются следующим образом [2]. Каждая хромосома (решение, последовательность, индивидуальность, "родитель", "потомок", "ребенок") представляет собой вектор из весовых коэффициентов (веса считываются с нейронной сети в установленном порядке - слева направо и сверху вниз).
Хромосома a=(a1, а2, а3, … ,an) состоит из генов аi, которые могут иметь числовые значения, называемые "аллели".
Популяцией называют набор хромосом (решений).
Эволюция популяций - это чередование поколений, в которых хромосомы изменяют свои признаки, чтобы каждая новая популяция наилучшим способом приспосабливалась к внешней среде.
Заметим, что в нашем случае каждый "ген" в хромосоме - реальное число, а не бит.
Начальная популяция выбирается случайно, значения весов лежат в промежутке [-1.0, 1.0]. Для обучения сети к начальной популяции применяются простые операции: селекция, скрещивание, мутация, - в результате чего генерируются новые популяции.
У генетического алгоритма есть такое свойство как вероятность. Т.е. описываемые операторы не обязательно применяются ко всем хромосомам, что вносит дополнительный элемент неопределенности в процесс поиска решения. В данном случае, неопределенность не подразумевает негативный фактор, а является своебразной "степенью свободы" работы генетического алгоритма.
Оператор селекции (reproduction, selection) осуществляет отбор хромосом в соответствии со значениями их функции приспособленности. Здесь применим метод рулетки (roulette-wheel selection), с помощью которого осуществляется отбор. Колесо рулетки содержит по одному сектору для каждого члена популяции. Размер i-го сектора пропорционален соответствующей величине Psel(i) вычисляемой по формуле:
fi(x) - значение целевой функции i-й хромосомы в популяции;
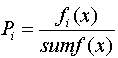
sumf(x) - суммарное значение целевой функции всех хромосом в популяции;
Для вычисления минимума функции f(x) требуется найти нормализованную величину ki: ki2pср-pi
pср - cреднее значение нормализованной величины p.
Ожидаемое число копий i-й хромосомы после оператора селекция определяются так: Ni=kin
где n - число анализируемых хромосом.
При таком отборе члены популяции с более высокой приспособленностью будут чаще выбираться, чем особи с низкой приспособленностью.
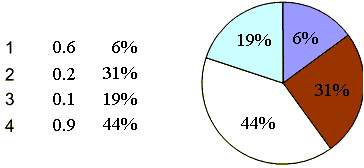
Рисунок 2 - Оператор селекции типа колеса рулетки с пропорциональными функции приспособленности секторами
Рассмотрим пример работы оператора селекции для вычисления минимума функции f(x)=sum(xi) [3]. Данные для удобства сведены в таблицу 1.
| Номер хромосомы | Начальная популяция (генерируется случайно) - величина погрешности fi | Нормализованная величина pi | Нормализованная величина ki=2piср-pi | Ожидаемое кол-во копий хромосомы в след. поколении | Реальное кол-во копий хромосомы в след. поколении |
| 1 | 0.8 | 0.5 | 0 | 0 | 0 |
| 2 | 0.2 | 0.125 | 0.375 | 1.5 | 1 |
| 3 | 0.5 | 0.3125 | 0.1875 | 0.75 | 1 |
| 4 | 0.1 | 0.0625 | 0.4375 | 1.75 | 2 |
| Суммарная функция (sumf(x)) | 1.6 | 1.00 | 1.00 | 4.00 | 4 |
| Среднее значение функции fср(x) | 0.4 | 0.25 | 0.25 | 1.00 | 1 |
| Min значение функции f(x) | 0.1 | 0.0625 | 0 | 0 | 0 |
Согласно этому выражению, первая хромосома из табл. 3.1 получит 0*4=0 копий, вторая - 0.375*4=1.5 копий, третья - 0.1875*4=0.75 и четвертая 0.4375*4=1.75. В результате хромосомы 2 и 3 получают 1 копию, хромосома 4 - 2 копии, и хромосома 1 не получает копий. Оценивая полученный результат, получим что: "лучшие" хромосомы дают большее число копий, "средние" остаются и плохие "умирают" после селекции.
Оператор кроссовера (crossover operator), иногда называемый кроссинговером, является основным генетическим оператором (рис. 3), за счет которого производится обмен частями хромосом между двумя (может быть и больше) хромосомами в популяции [1]. Может быть одноточечным или многоточечным. Одноточечным называется кроссовер, если при нем родительские хромосомы разрезаются только в одной случайной точке. Для реализации N-точечного кроссовера м.б. использовано два подхода :
Точек разрыва меньше, чем генов в хромосоме, либо
Если длина хромосомы L битов, то число точек разрыва равно (L-1), при этом потомки наследуют биты следующим образом: первому потомку достаются нечетные биты первого родителя и четные биты второго; у второго же потомка все наоборот. Т.е. получается как бы "расческа".
Кроме описанных типов кроссовера есть ещё однородный кроссовер. Его особенность заключается в том, что значение каждого бита в хромосоме потомка определяется случаным образом из соответствующих битов родителей. Для этого вводится некоторая величина 0
Вероятность кроссовера самая высокая среди генетических операторов и равна обычно 60% и больше.
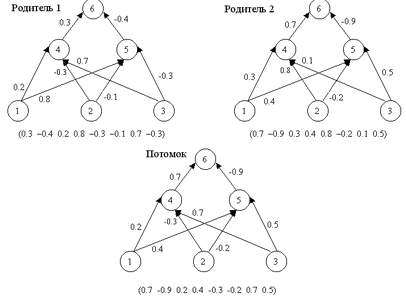
Рисунок 3 - Оператор скрещивания
Оператор мутации (mutation operator) - стохастическое изменение части хромосом. Он необходим для "выбивания" популяции из локального экстремума и способствует защите от преждевременной сходимости. Достигаются эти чудеса за счет того, что каждый ген строки, которая подвергается мутации, с малой вероятностью Pmut меняется на другой ген (добавляется случайная величина между -1.0 и 1.0 к весу). Это показано на рисунке 4.
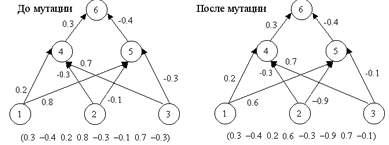
Рисунок 4 - Оператор мутации
Так же как и кроссовер, мутация проводится не только по одной случайной точке. Можно выбирать некоторое количество точек в хромосоме для изменения, причем их число также может быть случайным. Также можно изменять сразу некоторую группу подряд идущих точек. Вероятность мутации значительно меньше вероятности кроссовера и редко превышает 1%.
Обычно при реализации ГА к скрещиваемым особям сначала применяют оператор кроссовера, а потом оператор мутации, хотя возможны варианты. Например, оператор мутации можно применять только если к данной паре родительских особей не был применен оператор кроссовера (свойство вероятности). В принципе, никто не мешает вообще не использовать вероятность проведения данного генетического оператора и применять кроссовер ко всем отобранным особям, а мутацию к каждому 100 потомку. В общем здесь - полная свобода действий.
При исследовании эффективности обучения нейронных сетей в качестве тестовых примеров рассматривались:
двухслойная нейронная сеть с характеристиками: 4 входных сигнала, 3 нейрона скрытого слоя, 1 выходной сигнал;
трехслойная нейронная сеть с характеристиками: 5 входных сигналов, 3 нейрона в первом скрытом слое, 2 нейрона во втором скрытом слое, 2 выходных сигнала.
Сеть в обоих случаях являлась полносвязной, таким образом, между нейронами было в первом случае 15 связей, а во втором 25.
На вход НС подавалось обучающее множество, представляющее собой последовательность 0 и/или 1.
Выполнялось обучение нейронной сети с помощью алгоритма обратного распространения ошибки и с помощью генетических алгоритмов. Обучение в обоих случаях заканчивается, когда на всем обучающем реальный выходной сигнал был равен требуемому выходному сигналу.
Результаты работы операторов генетических алгоритмов были сравнены с результатами работы алгоритма обратного распространения ошибки. Генетический алгоритм работал с популяцией, состоящей из 30 векторов, первоначально сгенерированных случайным образом.
Для обучения нейронной сети достаточно было выполнить 500 генераций с помощью генетических алгоритмов. Алгоритмам обратного распространения требовалось во много раз большее число итераций - около 500000 итераций, где одна итерация - это полный пересчет всех обучающих данных (весовые коэффициенты, погрешность, значения выходов нейронной сети). Заметим, что при этом две генерации в генетическом алгоритме эквивалентны одной итерации алгоритма обратного распространения, так как обратное распространение на данном обучающем примере состоит из двух частей - прямой проход (вычисление выхода сети и ошибки) и обратный проход (наладка весов). Генетические алгоритмы выполняет только первую часть. Таким образом, две генерации занимают меньше времени, чем вычисления единственной итерации алгоритма обратного распространения.
Результат сравнения показан на рисунках 5 и 6. На оси X лежит количество итераций, а на оси Y - лучший показатель (минимальное значение суммы квадратов ошибок), определенный к этому времени.
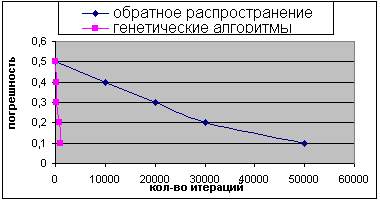
Рисунок 5 - Сравнение результатов работы генетических алгоритмов и алгоритма обратного распространения (первый случай).
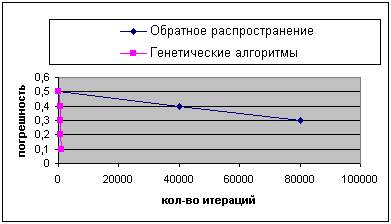
Рисунок 6 - Сравнение результатов работы генетических алгоритмов и алгоритма обратного распространения (второй случай).
Можно заметить, что генетические алгоритмы значительно выигрывают у обратного распространения для этой задачи, получая лучшие векторы весовых коэффициентов за меньшее количество времени.
Этот эксперимент показывает, что в некоторых случаях генетические алгоритмы - лучший метод обучения для нейронных сетей, чем простое обратное распространение. Это не подразумевает, что генетические алгоритмы выиграют у обратного распространения во всех случаях.
Возможно, что усовершенствование алгоритма обратного распространения могло бы помочь решить некоторые проблемы и дать результаты близкие к результатам, полученным с помощью генетических алгоритмов.
Следует заметить, что генетические алгоритмы будут наиболее полезны для подстройки весов в задачах, где обратное распространение и его аналоги не могут использоваться, например, в неконтролируемых задачах, когда ошибка выхода не может быть вычислена. Это часто имеет место для задач нейроуправления, в которых нейронные сети используются, чтобы управлять сложными системами (например, проведение роботов в незнакомых окружающих средах).
Список литературы: 1. В.Дюк, А. Самойленко. Data Mining: учебный курс (+CD). - СПб: Питер, 2001. - 386с. 2. Melanie Mitchell. An Introduction to Genetic Algorithms. Massachusetts Institute of Technology, 1998. - 280.
Соломка Ю.И. Применение генетических алгоритмов для обучения нейронных сетей.// Четверта міжнародна студентська науково-практична конференція "Світ молоді - молодь світу". 15-17 квітня 2004 р. Матеріали конференції. Частина 1. - Вінниця: ВІ МАУП, 2004. - 85-90.
 В библиотеку
В библиотеку