Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии.
Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена логистической регрессии, целью которой является построение моделей, предсказывающих вероятности событий.
Линейная модель связывает значения зависимой переменной Y со значениями независимых показателей Xk (факторов) формулой:
Y=B0+B1X1+:+BpXp+e
где e - случайная ошибка. Здесь Xk означает не "икс в степени k", а переменная X с индексом k.
Традиционные названия "зависимая" для Y и "независимые" для Xk отражают не столько статистический смысл зависимости, сколько их содержательную интерпретацию.
Величина e называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами N(0,?2), ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные X как неслучайные значения, Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения X (например, назначили зарплату работнику), а затем измеряют Y (оценили, какой стала производительность труда). За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного для неслучайных X корректно.
Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной , причем они могут быть вычислены и там, где значения y определены, и там где они не определены. Прогнозные значения являются оценками средних, ожидаемых по модели значений Y, зависящих от X.
Поскольку коэффициенты регрессии - случайные величины, линия регрессии также случайна. Поэтому прогнозные значения случайны и имеют некоторое стандартное отклонение , зависящее от X. Благодаря этому можно получить и доверительные границы для прогнозных значений регрессии (средних значений y).
Кроме того, с учетом дисперсии остатка могут быть вычислены доверительные границы значений Y (не средних, а индивидуальных!).
Для каждого объекта может быть вычислен остаток
ei=![]() . Остаток полезен для изучения
адеквантности модели данным. Это означает, что должны быть выполнены требования
о независимости остатков для отдельных наблюдений, дисперсия не должна зависеть
от X.
. Остаток полезен для изучения
адеквантности модели данным. Это означает, что должны быть выполнены требования
о независимости остатков для отдельных наблюдений, дисперсия не должна зависеть
от X.
Для изучения отклонений от модели удобно использовать стандартизованный остаток - деленный на стандартную ошибку регрессии.
Случайность оценки прогнозных значений Y вносит дополнительную
дисперсию в регрессионный остаток, из-за этого дисперсия остатка зависит от
значений независимых переменных (![]() ). Стьюдентеризованный остаток - это
остаток деленный на оценку дисперсии остатка:
). Стьюдентеризованный остаток - это
остаток деленный на оценку дисперсии остатка: ![]() .
.
Таким образом, мы можем получить: оценку (прогнозную) значений зависимой переменной Unstandardized predicted value), ее стандартное отклонение (S.E. of mean predictions), доверительные интервалы для среднего Y(X) и для Y(X) (Prediction intervals - Mean, Individual).
Это далеко не полный перечень переменных, порождаемых SPSS.
Пусть прогнозируется вес ребенка в зависимости от его возраста. Ясно, что дисперсия веса для четырехлетнего младенца будет значительно меньше, чем дисперсия веса 14-летнего юноши. Таким образом, дисперсия остатка ei зависит от значений X, а значит условия для оценки регрессионной зависимости не выполнены. Проблема неоднородности дисперсии в регрессионном анализе называется проблемой гетероскедастичности.
В SPSS имеется возможность корректно сделать соответствующие оценки за счет приписывания весов слагаемым минимизируемой суммы квадратов. Эта весовая функция должна быть равна 1/?2(x), где ?2(x) - дисперсия y как функция от x. Естественно, чем меньше дисперсия остатка на объекте, тем больший вес он будет иметь. В качестве такой функции можно использовать ее оценку, полученную при фиксированных значениях X.
Например, в приведенном примере на достаточно больших данных можно оценить дисперсию для каждой возрастной группы и вычислить необходимую весовую переменную. Увеличение влияния возрастных групп с меньшим возрастом в данном случае вполне оправдано.
В диалоговом окне назначение весовой переменной производится с помощью кнопки WLS (Weighed Least Squares - метод взвешенных наименьших квадратов).
В меню - это команда Linear Regression. В диалоговом окне команды:
- Назначаются независимые и зависимая переменные,
- Назначается метод отбора переменных. STEPWISE - пошаговое включение/удаление переменных. FORWARD - пошаговое включение переменных. BACKWARD - пошаговое исключение переменных. При пошаговом алгоритме назначаются значимости включения и исключения переменных (OPTIONS). ENTER - принудительное включение.
- Имеется возможность отбора данных, на которых будет оценена модель (Selection). Для остальных данных могут быть оценены прогнозные значения функции регрессии, его стандартные отклонения и др.
- Назначения вывода статистик (Statistics) - доверительные коэффициенты коэффициентов регресии, их ковариационная матрица, статистики Дарбина-Уотсона и пр.
- Задаются графики рассеяния остатков, их гистограммы (Plots)
- Назначаются сохранение переменных(Save), порождаемых регрессией.
- Если используется пошаговая регрессия, назначаются пороговые значимости для включения (PIN) и исключения (POUT) переменных (Options).
- Если обнаружена гетероскедастичность, назначается и весовая переменная.
Обычно демонстрацию модели начинают с простейшего примера, и такие примеры Вы можете найти в Руководстве по применению SPSS. Мы пойдем немного дальше и покажем, как получить полиномиальную регрессию.
Курильский опрос касался населения трудоспособного возраста. Как показали расчеты, в среднем меньшие доходы имеют молодые люди и люди старшего возраста. Поэтому, прогнозировать доход лучше квадратичной кривой, а не простой линейной зависимостью. В рамках линейной модели это можно сделать, введя переменную - квадрат возраста. Приведенное ниже задание SPSS предназначено для прогноза логарифма промедианного дохода (ранее сформированного).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2
/SAVE PRED MCIN ICIN.
*регрессия с сохранением предсказанных значений и доверительных интервалов средних и индивидуальных прогнозных значений.
Таблица 5.1 показывает, что уравнение объясняет всего 4.5% дисперсии зависимой переменной (коэффициент детерминации R2=.045), скорректированная величина коэффициента равна 0.042, а коэффициент множественной корреляции равен 0.211. Много это или мало, трудно сказать, поскольку у нас нет подобных результатов на других данных, но то, что здесь есть взаимосвязь, можно понять, рассматривая таблицу 6.2.
Таблица 6.1. Общие характеристики уравнения
|
R |
R Square |
Adjusted R Square |
Std. Error of the Estimate |
| .211 | |||
|
.045 |
.042 |
.5277 |
b Dependent Variable: LNV14M логарифм промедианного дохода
Результаты дисперсионного анализа уравнения регрессии показывает, что гипотеза равенства всех коэффициентов регрессии нулю должна быть отклонена.
Таблица 6.2. Дисперсионный анализ уравнения
|
Sum of Squares |
df |
Mean Square |
F |
Sig. |
|
| Regression | |||||
|
8.484 |
2 |
4.242 |
15.232 |
.000 |
|
| Residual | |||||
|
181.298 |
651 |
.278 |
|||
| Total | |||||
|
189.782 |
653 |
b Dependent Variable: LNV14M логарифм промедианного дохода
Таблица 6.3. Коэффициенты регрессии.
|
|
Unstandardized Coefficients |
|
Standardized Coefficients |
T |
Sig. |
|
|
B |
Std. Error |
Beta | ||
|
(Constant) |
-1.0569 |
0.1888 |
|
-5.5992 |
0.0000 |
|
V9 Возраст |
0.0505 |
0.0093 |
1.1406 |
5.4267 |
0.0000 |
|
V9_2 |
-0.0006 |
0.0001 |
-1.0829 |
-5.1521 |
0.0000 |
Регрессионные коэффициенты представлены в таблице 6.3. В соответствии с ними, уравнение регрессии имеет вид
Лог.промед.дохода = -1.0569+0.0505*возраст-0.0006*возраст2
Рисунок 6.1. Зависимость логарифма душевого дохода от возраста,
доверительные интервалы предсказания и среднего
предсказания

Стандартная ошибка коэффициентов регрессии значительно меньше величин
самих коэффициентов, их отношения - t статистики, по абсолютной величине
больше 5. Наблюдаемая значимость статистик (Sig) равна нулю, поэтому
гипотеза о равенстве коэффициентов нулю отвергается для каждого коэффициента.
Стоит обратить внимание на редкую ситуацию - коэффициенты бета по абсолютной
величине больше единицы. Это произошло, по-видимому, из-за того, что корреляция
между возрастом и его квадратом весьма велика.
Рисунок 6.1 показывает линию регрессии и доверительные границы для M(y) - матожидания y и для индивидуальных значений y. Он получается с помощью наложения полей рассеяния возраста с зависимой переменной, с переменной - прогнозом, с переменными - доверительными границами:
GRAPH /SCATTERPLOT(OVERLAY)=v9 v9 v9 v9 v9 v9 WITH pre_1 lmci_1 umci_1 lici_1 uici_1 lnv14m(PAIR).
Границы для M(y) значительно уже, чем для y, так как последние должны охватывать больше 95% точек графика.
На графике не прослеживается явной зависимости дисперсии остатка от значений независимой переменной - возраста. Некоторое сужение рассеяния данных для старших возрастов произошло, вероятно, за счет общего уменьшения плотности двумерного распределения.
Однозначно можно сказать, что они не могут быть использованы в качестве зависимой переменной Y. Это будет грубейшей ошибкой; в этом случае уравнением регрессии может быть предсказан, к примеру, пол имеющий код 1.5 или 0.5 при общепринятой кодировке пола 1-мужчины, 2-женщины. Может быть, это как-то интерпретируется с медицинской точки зрения, но в практике социальных исследований это будет едва ли возможно.
Для использования в качестве независимой переменной применяются индексные переменные (в англоязычной литературе dummy-variables).
Например, для семейного положения в данных Курильского обследования (женат, вдов, разведен, холост) стоит ввести три индикаторные переменные t1, t2 и t3 для выделения женатых, вдовых, и разведенных. Эти переменные будут равны, соответственно единице или нулю, в зависимости от того принадлежит или не принадлежит респондент к соответствующей группе по семейному положению.
Рисунок 6.2. Зависимость логарифма душевого дохода от возраста и
семейного
положения

Почему не 4 индексные переменные? Четвертая переменная определяется
однозначно через первые три, поэтому, введение ее вызвало бы коллинеарность, не
позволяющую найти коэффициенты регрессии.
Вот задание, которое позволяет изучить зависимость душевого дохода от возраста и семейного положения:
compute lnv14m =ln(v14/200).
compute t1=(v11=1).
compute t2=(v11=2).
compute t3=(v11=3).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2 t1 t2 t3 /SAVE PRED.
График связи возраста (V9) с предсказанным уравнением логарифмом доходов (переменная pre_2) получается командой
GRAPH /SCATTERPLOT(BIVAR)=v9 WITH pre_2 /MISSING=LISTWISE
Он представляет собой 4 параболы (рисунок 6.2). В соответствии с коэффициентами перед t1, t2 и t3 (см. таблицу 6.4), эти пораболы соответствуют, сверху вниз, холостякам, разведенным, женатым и вдовцам (порабола холостяков получается при t1=t2=t3=0).
Вероятно, полученное уравнение можно улучшить, исключив из уравнения переменные с незначимыми коэффициентами. Поскольку индексные переменные должны быть в определенной степени взаимосвязаны, уровень наблюдаемой значимости может определяться здесь коллинеарностью, поэтому "ревизию" переменных нужно проводить осторожно, чтобы существенно не ухудшить полученного уравнения.
Из-за взаимосвязи переменных здесь нет возможности говорить о том, какая переменная больше влияет на зависимую переменную. Обратите внимание на довольно редкий эффект: бета-коэффициенты для возраста и его квадрата по абсолютной величине больше 1!
Таблица 6.4. Коэффициенты регрессии с индексными переменными.
|
|
B |
Std. Error |
Beta |
T |
Sig. |
|
(Constant) |
-1.1721 |
0.1937 |
|
-6.0500 |
0.0000 |
|
V9 Возраст |
0.0635 |
0.0105 |
1.4298 |
6.0299 |
0.0000 |
|
V9_2 |
-0.0007 |
0.0001 |
-1.3243 |
-5.7351 |
0.0000 |
|
T1 Женат |
-0.2030 |
0.0766 |
-0.1540 |
-2.6488 |
0.0083 |
|
T2 Вдовец |
-0.2471 |
0.1352 |
-0.0850 |
-1.8279 |
0.0680 |
|
T3 Разведен |
-0.1494 |
0.1134 |
-0.0661 |
-1.3176 |
0.1881 |
Кроме того, модель с тремя "параллельными" параболами, вероятно, не полностью адекватна, каждая группа может иметь свою конфигурацию линии регрессии. Для учета этого в уравнении стоит использовать переменные взаимодействия. О том, как их конструировать - следующий раздел.
Предположим, что мы рассматриваем пару индикаторных переменных: X1 - для выделения группы женатых и X2 - для выделения группы "начальников", а прогнозируем с помощью уравнения регрессии все тот же логарифм дохода: Y=B0+B1*X1+B2*X2.
Это уравнение моделирует ситуацию, когда действие факторов X1 и X2 складывается, т.е. считается, к примеру, что женатый начальних имеет зарплату B1+B2, не женатый начальник B2. Это достаточно смелое предположение, так как, скорее всего, закономерность не так груба и существует взаимодействие между факторами, в результате которого их совместный вклад имеет другую величину. Для учета такого взаимодействия можно ввести в уравнение переменную, равную произведению X1 и X2:
Y=B0+B1*X1+B2*X2+B3*X1*X2.
Произведение X1*X2 равно единице, если факторы действуют совместно и нулю, если какой либо из факторов отсутствует.
Аналогично можно поступить для учета взаимодействия обычных количественных переменных, а также индексных переменных с количественными.
Для получения переменных взаимодействия, следует воспользоваться средствами преобразования данных SPSS.
Предсказания событий, исследования связи событий с теми или иными факторами с нетерпением ждут от социологов. Будем считать, что событие в данных фиксируется дихотомической переменной (0 не произошло событие, 1 - произошло). Для построения модели предсказания можно было бы построить, к примеру, линейное регрессионное уравнение с зависимой дихотомической переменной Y, но оно будет не адекватно поставленной задаче, так как в классическом уравнении регрессии предполагается, что Y - непрерывная переменная. С этой целью рассматривается логистическая регрессия. Ее целью является построение модели прогноза вероятности события {Y=1} в зависимости от независимых переменных X1,:,Xp. Иначе эта связь может быть выражена в виде зависимости P{Y=1|X}=f(X)
Логистическая регрессия выражает эту связь в виде формулы
![]() , где
Z=B0+B1X1+:+BpXp
(1).
, где
Z=B0+B1X1+:+BpXp
(1).
Название "логистическая регрессия" происходит от названия логистического
распределения, имеющего функцию распределения ![]() . Таким образом, модель, представленная
этим видом регрессии, по сути, является функцией распределения этого закона, в
которой в качестве аргумента используется линейная комбинация независимых
переменных.
. Таким образом, модель, представленная
этим видом регрессии, по сути, является функцией распределения этого закона, в
которой в качестве аргумента используется линейная комбинация независимых
переменных.
Отношение вероятности того, что событие произойдет к вероятности того, что оно не произойдет P/(1-P) называется отношением шансов.
С этим отношением связано еще одно представление логистической регрессии, получаемое за счет непосредственного задания зависимой переменной в виде Z=Ln(P/(1-P)), где P=P{Y=1|X1,:,Xp}. Переменная Z называется логитом.По сути дела, логистическая регрессия определяется уравнением регрессии Z=B0+B1X1+:+BpXp.
В связи с этим отношение шансов может быть записано в следующем виде
P/(1-P)=![]() .
.
Отсюда получается, что, если модель верна, при независимых
X1,:,Xpизменение Xk на
единицу вызывает изменение отношения шансов в![]() раз.
раз.
Механизм решения такого уравнения можно представить следующим образом
1. Получаются агрегированные данные
по переменным X, в которых для каждой группы, характеризуемой значениями
Xj=![]() подсчитывается доля объектов,
соответствующих событию {Y=1}. Эта доля является оценкой вероятности
подсчитывается доля объектов,
соответствующих событию {Y=1}. Эта доля является оценкой вероятности
![]() . В соответствии с этим, для каждой
группы получается значение логита Zj.
. В соответствии с этим, для каждой
группы получается значение логита Zj.
2. На агрегированных данных оцениваются коэффициенты уравнения Z=B0+B1X1+:+BpXp. К сожалению, дисперсия Z здесь зависит от значений X, поэтому при использовании логита применяется специальная техника оценки коэффициентов - взвешенной регрессии.
Еще одна особенность состоит в том, что в реальных данных очень часто группы
по X оказываются однородными по Y, поэтому оценки ![]() оказываются равными нулю или единице.
Таким образом, оценка логита для них не определена (для этих значений
оказываются равными нулю или единице.
Таким образом, оценка логита для них не определена (для этих значений
![]() ).
).
В некоторых статистических пакетах такие группы объектов просто-напросто отбрасываются.
В настоящее время в статистическом пакете для оценки коэффициентов используется метод максимального правдоподобия, лишенный этого недостатка. Тем не менее, проблема, хотя и не в таком остром виде остается: если оценки вероятности для многих групп оказываются равными нулю или единице, оценки коэффициентов регрессии имеют слишком большую дисперсию. Поэтому, имея в качестве независимых переменных такие признаки, как душевой доход в сочетании с возрастом, их следует укрупнить по интервалам, приписав объектам средние значения интервалов.
Если в обычной линейной регрессии для работы с неколичественными переменными нам приходилось подготавливать специальные индикаторные переменные, то в реализации логистической регрессии в SPSS это делается автоматически. Для этого в диалоговом окне специально предусмотрены средства, сообщающие пакету, что ту или иную переменную следует считать категориальной. При этом, чтобы не получить линейно зависимых переменных, максимальный код ее значения (или минимальный, в зависимости от задания процедуры) не перекодируется в дихотомическую (индексную) переменную. Впрочем, средства преобразования данных позволяют не учитывать любой код значения. Имеются другие способы перекодирования категориальных (неколичественных) переменных в несколько переменных, но мы будем пользоваться только указанным, как наиболее естественным.
В процедуре логистической регрессии в SPSS предусмотрены средства для автоматического включения в уравнение переменных взаимодействий. В диалоговом окне в списке исходных переменных для этого следует выделить имена переменных, взаимодействия которых предполагается рассмотреть, затем переправить выделенные имена в окно независимых переменных кнопкой c текстом >a*b>.
Процедура логистической регрессии в SPSS в диалоговом режиме вызывается из меню командой Statistics\Regression\Binary logistic:.
В качестве примера по данным RLMS изучим, как связано употребление спиртных напитков с зарплатой, полом, статусом (ранг руководителя), курит ли он.
Для этого подготовим данные: выберем в обследовании RLMS население старше 18 лет, сконструируем индикаторы курения (smoke) и пития (alcohol) (в обследовании задавался вопрос "Употребляли ли Вы в течении 30 дней алкогольные напитки")
COMPUTE filter_$=(vozr>18).
FILTER BY filter_$.
compute smoke=(dm71=1).
val lab smoke 1 "курит" 0 "не курит".
compute alcohol=(dm80=1).
val lab alcohol 1 "пьет" 0 "не пьет".
Укрупним переменную dj10 -(зарплата на основном рабочем месте). В данном случае группы по значениям этой переменной в основном достаточно наполнены, но мы с методической целью покажем один из способов укрупнения. Для этого вначале получаем переменную wage, которая содержит номера децилей по зарплате, затем среднюю зарплату по этим децилям (см. таблицу 6.5).
missing values dj6.0 (9997,9998,9999) dj10(99997,99998,99999).
RANK VARIABLES=dj10 (A) /NTILES (10) into wage /PRINT=YES /TIES=MEAN .
MEANS TABLES=dj10 BY wage /CELLS MEAN.
Таблица 6.5. Средняя зарплата по децилям.
|
WAGE децили зарплаты |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
DJ10 зарплата за 30 дней |
101 |
211 |
307 |
416 |
542 |
703 |
853 |
1108 |
1565 |
3464 |
Полученные средние используем для формирования переменной, соответствующей укрупненной зарплате (для удобства, чтобы коэффициенты регрессии не были слишком малы, в качестве единицы ее измерения возьмем сто рублей).
recode wage (1=1.01) (2=2.11) (3=3.07) (4=4.16) (5=5.42) (6=7.03) (7=8.53) (8=11.08) (9=15.65) (10 =34.64).
recode dj6.0 (sysmis=4)(1 thru 5=1)(6 thru 10=2) (10 thru hi=3) into manag.
var lab manag "статус" wage "зaработок".
val lab manag 4 "не начальник" 1 "шеф" 2 "начальничек" 3 "начальник".
exec.
Далее формируем переменную manag - " статус" из переменной dj6.0 - количество подчиненных.
Запускаем команду построения регрессии LOGISTIC REGRESSION, в которой использованы переменные wage - зарплата, manag статус, dh5 - пол (1 мужчины, 2 женщины) smoke - курение (1 курит, 0 не курит), dh5* wage - "взаимодействие" пола с зарплатой (для женщин значение - 0, для мужчин - совпадает с зарплатой).
LOGISTIC REGRESSION VAR=alcohol /METHOD=ENTER wage manag dh5 smoke dh5*wage /CONTRAST (dh5)=Indicator /CONTRAST (manag)=Indicator /CONTRAST (smoke)=Indicator /PRINT=CI(95) /CRITERIA PIN(.05) POUT(.10) ITERATE(20) CUT(.69) .
В выдаче программа, прежде всего, сообщает о перекодировании данных:
Dependent Variable Encoding:
Original Internal
Value Value
.00 0
1.00 1
Следует обратить внимание, что зависимая переменная здесь должна быть дихотомической, и ее максимальный код считается кодом события, вероятность которого прогнозируется. Например, если Вы закодировали переменную ALCOHOL 1-употреблял, 2-не употреблял, то будет прогнозироваться вероятность не употребления алкоголя.
Далее идут сведения о кодировании индексных переменных для категориальных переменных; из-за их естественности мы их здесь не приводим.
Далее следуют обозначения для переменных взаимодействия, в нашем простом случае это:
Interactions:
INT_1 DH5(1) by WAGE
Далее в выдаче появляется описательная информация о качестве подгонки модели:
-2 Log Likelihood 3289.971
Goodness of Fit 2830.214
Cox & Snell - R^2 .072
Nagelkerke - R^2 .102
которые означают:
· -2 Log Likelihood - удвоенный логарифм функция правдоподобия со знаком минус;
· Goodness of Fit - характеристика отличия наблюдаемых частот от ожидаемых;
· Cox & Snell - R^2 и Nagelkerke - R^2 - псевдо коэффициенты детерминации, полученные на основе отношения функций правдоподобия моделей лишь с константой и со всеми коэффициентами.
Эти коэффициенты стоит использовать при сравнении очень похожих моделей на аналогичных данных, что практически нереально, поэтому мы не будем на них останавливаться.
Рисунок 6.3. Классификационная
таблица
 На основе модели
логистической регрессии можно строить предсказание произойдет или не произойдет
событие {Y=1}. Правило предсказания, по умолчанию заложенное в процедуру
LOGISTIC REGRESSION устроено по следующему принципу: если
На основе модели
логистической регрессии можно строить предсказание произойдет или не произойдет
событие {Y=1}. Правило предсказания, по умолчанию заложенное в процедуру
LOGISTIC REGRESSION устроено по следующему принципу: если ![]() >0.5 считаем, что событие произойдет;
>0.5 считаем, что событие произойдет;
![]() ?0.5, считаем, что событие не
произойдет. Это правило оптимально с точки зрения минимизации числа ошибок, но
очень грубо с точки зрения исследования связи. Зачастую оказывается, что
вероятность события P{Y=1} мала (значительно меньше 0.5) или велика
(значительно больше 0.5), поэтому оказывается, что все имеющиеся в данных
сочетания X предсказывают событие или все предсказывают противоположное
событие.
?0.5, считаем, что событие не
произойдет. Это правило оптимально с точки зрения минимизации числа ошибок, но
очень грубо с точки зрения исследования связи. Зачастую оказывается, что
вероятность события P{Y=1} мала (значительно меньше 0.5) или велика
(значительно больше 0.5), поэтому оказывается, что все имеющиеся в данных
сочетания X предсказывают событие или все предсказывают противоположное
событие.
Поэтому здесь необходима другая классификация, которая демонстрирует связь
между зависимой и независимыми переменными. С этой целью стоит отнести к
предсказываемому классу ![]() , для которых {Y=1} ожидается c
большей вероятностью, чем в среднем, а остальные - к противоположному классу. В
нашем случае доля употреблявших алкоголь равна 69% и мы к классу предсказанных
значений отнесли значения X, для которых
, для которых {Y=1} ожидается c
большей вероятностью, чем в среднем, а остальные - к противоположному классу. В
нашем случае доля употреблявших алкоголь равна 69% и мы к классу предсказанных
значений отнесли значения X, для которых ![]() >0.69. Поэтому в процедуре указан
параметр /CRITERIA CUT(.69). Связь между этими классификациями представлена
таблица сопряженности (рмсунок 6.3). Но лучше в этой таблице вычислить
процентные соотношения пользуясь EXCEL или калькулятором.
>0.69. Поэтому в процедуре указан
параметр /CRITERIA CUT(.69). Связь между этими классификациями представлена
таблица сопряженности (рмсунок 6.3). Но лучше в этой таблице вычислить
процентные соотношения пользуясь EXCEL или калькулятором.
Таблица 6.6. Связь наблюдения и предсказания в логистической регрессии
|
Наблюдается |
Предсказано |
| |
|
Не пьет |
Пьет |
Всего | |
|
Не пьет |
43.8% |
21.5% |
31.3% |
|
Пьет |
56.2% |
78.5% |
68.7% |
Рисунок 6.4. Коэффициенты логистической
регрессии
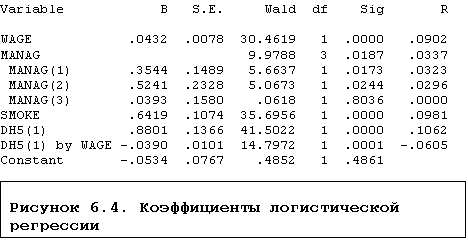
Основная информация содержится в таблице коэффициентов регрессии
(рисунок 6.4). Прежде всего, следует обратить внимание на значимость
коэффициентов. Наблюдаемая значимость вычисляется на основе статистики Вальда.
Эта статистика связана с методом максимального правдоподобия и может быть
использована при оценках разнообразных параметров.
Универсальность статистики Вальда позволяет оценить значимость не только отдельных переменных, но и в целом значимость категориальных переменных, несмотря на то, что они дезагрегированы на индексные переменные. Статистика Вальда имеет распределение хи-квадрат. Число степеней свободы, равно единице, если проверяется гипотеза о равенстве нулю коэффициента при обычной или индексной переменной и, для категориальной переменной, равно числу значений без единицы (числу соответствующих индексных переменных). Квадратный корень из статистики Вальда приближенно равен отношению величины коэффициента к его стандартной ошибке - так же выражается t-статистика в обычной линейной модели регрессии.
Рисунок 6.5. Экспоненты
коэффициентов
 В нашей таблице
коэффициентов почти все переменные значимы на уровне значимости 5%. Закрыв глаза
на возможное взаимодействие между независимыми переменными (коллинеарность),
можно считать, что вероятность употребления алкоголя повышена при высокой
зарплате, а также, у руководителей различного ранга. Из-за незначимости
статистики Вальда нет, правда, полной уверенности относительно повышенной
вероятности для начальников, имеющих более 10 подчиненных. Курение и
принадлежность к мужскому полу также повышают эту вероятность, однако,
взаимодействие "мужчина-зарплата" имеет обратное действие.
В нашей таблице
коэффициентов почти все переменные значимы на уровне значимости 5%. Закрыв глаза
на возможное взаимодействие между независимыми переменными (коллинеарность),
можно считать, что вероятность употребления алкоголя повышена при высокой
зарплате, а также, у руководителей различного ранга. Из-за незначимости
статистики Вальда нет, правда, полной уверенности относительно повышенной
вероятности для начальников, имеющих более 10 подчиненных. Курение и
принадлежность к мужскому полу также повышают эту вероятность, однако,
взаимодействие "мужчина-зарплата" имеет обратное действие.
В этой же таблице присутствует аналог коэффициента корреляции (R), также построенный на основе статистики Вальда. Для обычных и индексных переменных положительные значения коэффициента свидетельствуют о положительной связи переменной с вероятностью события, отрицательные - об отрицательной связи.
Кроме того, мы выдали таблицу экспонент коэффициентов eB и их доверительные границы (см. рисунок 6.5). Эта таблица выдана подкомандой /PRINT=CI(95) в команде задания логистической регрессии.
Согласно модели и полученным значениям коэффициентов, при фиксированных прочих переменных, принадлежность к мужскому полу увеличивает отношение шансов "пития" и "не пития" в 2.4 раза (точнее в 1.84-3.15 раза), курения - в 1.9 раза (1.54 - 2.35), а прибавка к зарплате 100 рублей - на 4.4% (2.8%-6%), правда такая прибавка мужчине одновременно уменьшает это отношение на 3.8% (5.7%-1.9%). Быть мелким начальником - значит увеличить отношение шансов в 1.43 (1.06 - 1.9) раза, чем в среднем, а средним начальником - в 1.7 (1.07-2.67) раза.
Как отмечено в документации SPSS, недостаток статистики Вальда в том, что при малом числе наблюдений она может давать заниженные оценки наблюдаемой значимости коэффициентов. Для получения более точной информации о значимости переменных можно воспользоваться пошаговой регрессией, метод FORWARD LR (LR - likelihood ratio - отношение правдоподобия), тогда будет для каждой переменной выдана значимость включения/исключения, полученная на основе отношения функций правдоподобия модели. Поскольку основная выдача построена на основе статистики Вальда, первые выводы удобнее делать на ее основе, а потом уже уточнять результаты, если это необходимо.
Программа позволяется сохранить множество переменных, среди которых наиболее полезной является, вероятно, предсказанная вероятность.
|


