В библиотеку
Экспоненциальное сглаживание
Источник: http://www.anchem.chtd.tpu.ru/edubook/math/stat_ru/modules/sttimser.html#exponential
Приведено описание метода, рассмотрено простое
экспоненциальное сглаживание, индексы
качества подгонки.
Общее введение
Экспоненциальное сглаживание – это очень популярный метод прогнозирования
многих временных рядов. Исторически метод был независимо открыт Броуном и Холтом.
Броун служил на флоте США во время второй мировой войны, где занимался
обнаружением подводных лодок и системами наведения. Позже он применил открытый
им метод для прогнозирования спроса на запасные части. Свои идеи он описал в
книге, вышедшей в свет в 1959 году. Исследования Холта были поддержаны
Департаментом военно-морского флота США. Независимо друг от друга, Броун и Холт
открыли экспоненциальное сглаживание для процессов с постоянным трендом, с
линейным трендом и для рядов с сезонной составляющей.
Gardner (1985), предложил "единую" классификацию методов экспоненциального
сглаживания. Превосходное введение в эти методы можно найти в книгах Makridakis,
Wheelwright, and McGee (1983), Makridakis and Wheelwright (1989), Montgomery,
Johnson, and Gardiner (1990).
Простое экспоненциальное сглаживание
Простая и прагматически ясная модель временного ряда имеет следующий вид: Xt
= b +  t,
где b – константа и (эпсилон) – случайная ошибка. Константа b относительно стабильна на каждом временном
интервале, но может также медленно изменяться со временем. Один из интуитивно
ясных способов выделения b состоит в том, чтобы использовать сглаживание
скользящим средним, в котором последним наблюдениям приписываются большие веса,
чем предпоследним, предпоследним большие веса, чем пред-предпоследним и т.д.
Простое экспоненциальное именно так и устроено. Здесь более старым наблюдениям
приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего
среднего, учитываются все предшествующие наблюдения ряда, а не те, что
попали в определенное окно. Точная формула простого экспоненциального
сглаживания имеет следующий вид:
t,
где b – константа и (эпсилон) – случайная ошибка. Константа b относительно стабильна на каждом временном
интервале, но может также медленно изменяться со временем. Один из интуитивно
ясных способов выделения b состоит в том, чтобы использовать сглаживание
скользящим средним, в котором последним наблюдениям приписываются большие веса,
чем предпоследним, предпоследним большие веса, чем пред-предпоследним и т.д.
Простое экспоненциальное именно так и устроено. Здесь более старым наблюдениям
приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего
среднего, учитываются все предшествующие наблюдения ряда, а не те, что
попали в определенное окно. Точная формула простого экспоненциального
сглаживания имеет следующий вид:
St =
 *Xt +
(1-)*St-1
*Xt +
(1-)*St-1
Когда эта формула применяется рекурсивно, то каждое новое сглаженное значение
(которое является также прогнозом) вычисляется как взвешенное среднее текущего
наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от
параметра(альфа).
Еслиравно 1,
то предыдущие наблюдения полностью игнорируются. Еслиравно 0,
то игнорируются текущие наблюдения. Значениямежду 0, 1
дают промежуточные результаты.
Эмпирические исследования Makridakis и др. (1982; Makridakis, 1983) показали,
что весьма часто простое экспоненциальное сглаживание дает достаточно точный
прогноз.
Выбор лучшего значения параметра(альфа)
Gardner (1985) обсуждает различные теоретические и эмпирические аргументы в
пользу выбора определенного параметра сглаживания. Очевидно, из формулы,
приведенной выше, следует, чтодолжно попадать
в интервал между 0 (нулем) и 1 (хотя Brenner et al., 1968, для
дальнейшего применения анализа АРПСС считают, что 0<<2).
Gardner (1985) сообщает, что на практике обычно рекомендуется братьменьше .30.
Однако в исследовании Makridakis et al., (1982),большее .30,
часто дает лучший прогноз. После обзора литературы, Gardner (1985) приходит к
выводу, что лучше оценивать оптимальнопо данным (см.
ниже), чем просто "гадать" или использовать искусственные рекомендации.
Оценивание лучшего значенияс помощью
данных. На практике параметр сглаживания часто ищется с поиском на сетке.
Возможные значения параметра разбиваются сеткой с определенным шагом. Например,
рассматривается сетка значений от= 0.1 до= 0.9, с
шагом 0.1. Затем выбирается, для которого
сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус
прогнозы на шаг вперед) является минимальной.
Индексы качества подгонки
Самый прямой способ оценки прогноза, полученного на основе определенного
значения- построить
график наблюдаемых значений и прогнозов на один шаг вперед. Этот график включает
в себя также остатки (отложенные на правой оси Y). Из графика ясно видно,
на каких участках прогноз лучше или хуже.
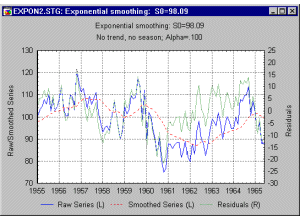
Такая визуальная проверка точности прогноза часто дает наилучшие результаты.
Имеются также другие меры ошибки, которые можно использовать для определения
оптимального параметра(см. Makridakis,
Wheelwright, and McGee, 1983):
Средняя ошибка. Средняя ошибка (СО) вычисляется простым
усреднением ошибок на каждом шаге. Очевидным недостатком этой меры является то,
что положительные и отрицательные ошибки аннулируют друг друга, поэтому она не
является хорошим индикатором качества прогноза.
Средняя абсолютная ошибка. Средняя абсолютная ошибка (САО)
вычисляется как среднее абсолютных ошибок. Если она равна 0
(нулю), то имеем совершенную подгонку (прогноз). В сравнении со средней
квадратической ошибкой, эта мера "не придает слишком большого значения"
выбросам.
Сумма квадратов ошибок (SSE), среднеквадратическая ошибка.
Эти величины вычисляются как сумма (или среднее) квадратов ошибок. Это наиболее
часто используемые индексы качества подгонки.
Относительная ошибка (ОО). Во всех предыдущих мерах
использовались действительные значения ошибок. Представляется естественным
выразить индексы качества подгонки в терминах относительных ошибок.
Например, при прогнозе месячных продаж, которые могут сильно флуктуировать
(например, по сезонам) из месяца в месяц, вы можете быть вполне удовлетворены
прогнозом, если он имеет точность ?10%. Иными словами, при прогнозировании
абсолютная ошибка может быть не так интересна как относительная. Чтобы учесть
относительную ошибку, было предложено несколько различных индексов (см.
Makridakis, Wheelwright, and McGee, 1983). В первом относительная ошибка
вычисляется как:
ООt = 100*(Xt – Ft )/Xt
где Xt – наблюдаемое значение в момент времени t, и
Ft – прогноз (сглаженное значение).
Средняя относительная ошибка (СОО). Это значение вычисляется
как среднее относительных ошибок.
Средняя абсолютная относительная ошибка (САОО). Как и в
случае с обычной средней ошибкой отрицательные и положительные относительные
ошибки будут подавлять друг друга. Поэтому для оценки качества подгонки в целом
(для всего ряда) лучше использовать среднюю абсолютную относительную
ошибку. Часто эта мера более выразительная, чем среднеквадратическая ошибка.
Например, знание того, что точность прогноза ±5%, полезно само по себе, в то
время как значение 30.8 для средней квадратической ошибки не может быть так
просто проинтерпретировано.
Автоматический поиск лучшего параметра. Для минимизации
средней квадратической ошибки, средней абсолютной ошибки или средней абсолютной
относительной ошибки используется квази-ньютоновская процедура (та же, что и в
АРПСС). В большинстве случаев эта процедура более эффективна, чем обычный
перебор на сетке (особенно, если параметров сглаживания несколько), и
оптимальное значениеможно
быстро найти.
Первое сглаженное значение S0.
Если вы взгляните снова на формулу простого экспоненциального сглаживания, то
увидите, что следует иметь значение S0 для вычисления первого
сглаженного значения (прогноза). В зависимости от выбора параметра(в частности,
еслиблизко к 0),
начальное значение сглаженного процесса может оказать существенное воздействие
на прогноз для многих последующих наблюдений. Как и в других рекомендациях по
применению экспоненциального сглаживания, рекомендуется брать начальное
значение, дающее наилучший прогноз. С другой стороны, влияние выбора уменьшается
с длиной ряда и становится некритичным при большом числе наблюдений.
Сезонная и несезонная модели с трендом или без тренда
В дополнение к простому экспоненциальному сглаживанию, были предложены более
сложные модели, включающие сезонную компоненту и трендом. Общая идея таких
моделей состоит в том, что прогнозы вычисляются не только по предыдущим
наблюдениям (как в простом экспоненциальном сглаживании), но и с некоторыми
задержками, что позволяет независимо оценить тренд и сезонную составляющую.
Gardner (1985) обсудил различные модели в терминах сезонности (отсутствует,
аддитивная сезонность, мультипликативная) и тренда (отсутствует, линейный тренд,
экспоненциальный, демпфированный).
Аддитивная и мультипликативная сезонность. Многие временные
ряды имеют сезонные компоненты. Например, продажи игрушек имеют пики в ноябре,
декабре и, возможно, летом, когда дети находятся на отдыхе. Эта периодичность
имеет место каждый год. Однако относительный размер продаж может слегка
изменяться из года в год. Таким образом, имеет смысл независимо экспоненциально
сгладить сезонную компоненту с дополнительным параметром, обычно обозначаемым
как (дельта).
Сезонные компоненты, по природе своей, могут быть аддитивными или
мультипликативными. Например, в течение декабря продажи определенного вида
игрушек увеличиваются на 1 миллион долларов каждый год. Для того чтобы учесть
сезонное колебание, вы можете добавить в прогноз на каждый декабрь 1 миллион
долларов (сверх соответствующего годового среднего). В этом случае сезонность – аддитивная. Альтернативно, пусть в декабре продажи увеличились на 40%, т.е. в
1.4 раза. Тогда, если общие продажи малы, то абсолютное (в долларах) увеличение
продаж в декабре тоже относительно мало (процент роста константа). Если в целом
продажи большие, то абсолютное (в долларах) увеличение продаж будет
пропорционально больше. Снова, в этом случае продажи увеличатся в определенное
число раз, и сезонность будет мультипликативной (в данном случае
мультипликативная сезонная составляющая была бы равна 1.4). На графике различие
между двумя видами сезонности состоит в том, что в аддитивной модели сезонные
флуктуации не зависят от значений ряда, тогда как в мультипликативной модели
величина сезонных флуктуаций зависит от значений временного ряда.
(дельта).
Сезонные компоненты, по природе своей, могут быть аддитивными или
мультипликативными. Например, в течение декабря продажи определенного вида
игрушек увеличиваются на 1 миллион долларов каждый год. Для того чтобы учесть
сезонное колебание, вы можете добавить в прогноз на каждый декабрь 1 миллион
долларов (сверх соответствующего годового среднего). В этом случае сезонность – аддитивная. Альтернативно, пусть в декабре продажи увеличились на 40%, т.е. в
1.4 раза. Тогда, если общие продажи малы, то абсолютное (в долларах) увеличение
продаж в декабре тоже относительно мало (процент роста константа). Если в целом
продажи большие, то абсолютное (в долларах) увеличение продаж будет
пропорционально больше. Снова, в этом случае продажи увеличатся в определенное
число раз, и сезонность будет мультипликативной (в данном случае
мультипликативная сезонная составляющая была бы равна 1.4). На графике различие
между двумя видами сезонности состоит в том, что в аддитивной модели сезонные
флуктуации не зависят от значений ряда, тогда как в мультипликативной модели
величина сезонных флуктуаций зависит от значений временного ряда.
Параметр сезонного сглаживания .
В общем, прогноз на один шаг вперед вычисляется следующим образом (для моделей
без тренда; для моделей с линейным и экспоненциальным трендом, тренд
добавляется; см. ниже):
Аддитивная модель:
Прогнозt = St + It-p
Мультипликативная модель:
Прогнозt = St*It-p
В этой формуле St обозначает (простое) экспоненциально
сглаженное значение ряда в момент t, и It-p обозначает
сглаженный сезонный фактор в момент t минус p (p – длина
сезона). Таким образом, в сравнении с простым экспоненциальным сглаживанием,
прогноз "улучшается" добавлением или умножением сезонной компоненты. Эта
компонента оценивается независимо с помощью простого экспоненциального
сглаживания следующим образом:
Аддитивная модель:
It = It-p +*(1-)*et
Мультипликативная модель:
It = It-p +*(1-)*et/St
Обратите внимание, что предсказанная сезонная компонента в момент t
вычисляется, как соответствующая компонента на последнем сезонном цикле плюс
ошибка (et, наблюдаемое минус прогнозируемое значение в момент
t). Ясно, что параметрпринимает
значения между 0 и 1. Если он равен нулю, то сезонная составляющая
на следующем цикле та же, что и на предыдущем. Еслиравен 1,
то сезонная составляющая "максимально" меняется на каждом шаге из-за
соответствующей ошибки (множитель (1-) не
рассматривается из-за краткости введения). В большинстве случаев, когда сезонность присутствует, оптимальное значениележит между 0
и 1.
Линейный, экспоненциальный, демпфированный тренд.
Возвращаясь к примеру с игрушками, мы можем увидеть наличие линейного тренда
(например, каждый год продажи увеличивались на 1 миллион), экспоненциального
(например, каждый год продажи возрастают в 1.3 раза) или демпфированного тренда
(в первом году продажи возросли на 1 миллион долларов; во втором увеличение
составило только 80% по сравнению с предыдущим, т.е. на $800,000; в следующем
году вновь увеличение было только на 80%, т.е. на $800,000 * .8 = $640,000 и
т.д.). Каждый тип тренда по-своему проявляется в данных. В целом изменение
тренда – медленное в течение времени, и опять (как и сезонную компоненту) имеет
смысл экспоненциально сгладить его с отдельным параметром [обозначаемым (гамма)
– для линейного и экспоненциального тренда,
(гамма)
– для линейного и экспоненциального тренда, (фи)
– для демпфированного тренда].
(фи)
– для демпфированного тренда].
Параметры сглаживания(линейный и
экспоненциальный тренд) и(демпфированный
тренд). Аналогично сезонной компоненте компонента тренда включается в
процесс экспоненциального сглаживания. Сглаживание ее производится в каждый
момент времени независимо от других компонент с соответствующими параметрами.
Еслиравно 0,
то тренд постоянен для всех значений временного ряда (и для всех прогнозов).
Еслиравно 1,
то тренд "максимально" определяется ошибками наблюдений. Параметручитывает, как
сильно изменяется тренд, т.е. как быстро он "демпфируется" или, наоборот,
возрастает.
В начало