Тевелев А. Д. Доклад на тему "Применение методов Data Mining в системе обработки и анализа медикостатистической информации"
Доклад подготовлен для Дня Науки на кафедре АСУ (апрель, 2005 г.)
Традиционные подходы в способах и методах получения и использования информации, существующие в сложившейся инструктивно-нормативной базе по медико-социальному обеспечению населения в настоящее время уже не соответствуют современным требованиям и недостаточно ориентированы на качественные показатели. Большую помощь руководителям лечебных учреждений и главным специалистам органов управления при анализе показателей, характеризующих динамику тенденций здоровья населения, планировании распределения ресурсов здравоохранения области, управлении специализированными медицинскими службами, должны оказать автоматизированные информационные системы (АИС).
Цель проектируемой системы – автоматизировать процесс сбора, хранения и обработки медикостатистической информации Донецкого Региона, а также автоматизацию анализа накопленных данных. Медицинская статистика Донецкого региона собирает данные с различных лечебно-профилактических учреждений, а также по районам, и населенным пунктам. Данные представляют собой числовые показатели распространенности различных заболеваний, количества больных, смертности и т. п. Данные собираются за определенное время, называемое отчетным периодом. За время функционирования Донецкого УЗО, накоплен достаточно обширный банк данных, поэтому возникает задача рационального хранения, и использования этих данных, получение из них знаний, с целью возможности прогнозирования и принятия решений, способствующих более эффективному функционированию здравоохранения.
На первых стадиях информатизации всегда требуется навести порядок именно в процессах повседневной рутинной обработки данных, на что и ориентированы системы обработки данных (СОД). Системы второго класса – системы интеллектуального анализа данных (ИАД) - являются вторичными по отношению к ним.
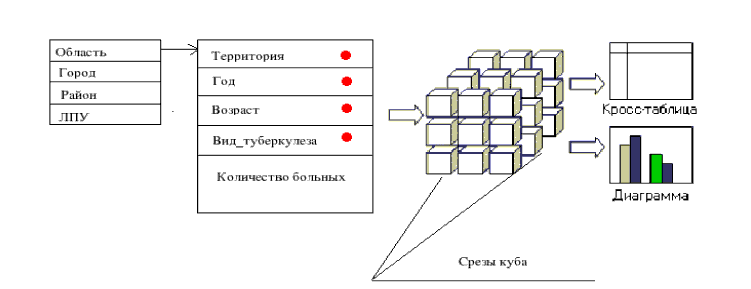
В качестве технологии системы СОД предполагается использовать технологию OLAP. В основе концепции оперативной аналитической обработки (OLAP) лежит многомерное представление данных. Cуществует два класса OLAP систем – многомерный OLAP (MOLAP) – данные хранятся в многомерном виде и реляционный OLAP – данные в OLAP систему поступают из плоских таблиц реляционных БД. В разрабатываемой системе используется реляционный OLAP, так как реляционные базы данных наиболее приемлемы, для хранения больших обьемов информации, таких как данные медицинской статистики. При разработки данной системы учитывалось многообразие информации, собираемой медицинской статистикой, поэтому, система проектируется таким образом, чтобы иметь возможность настраиваться на любую форму медико-статистической отчетности. Поэтому первым этапом в разработке данной системы было создание структуры базы данных для хранения информации. Центр медико-статистической информации донецкого региона работает с 48 формами государственной статической отчетности, каждая из которых имеет собственную предметную область анализа данных. В данном проекте будут рассмотрены только несколько форм, однако в разрабатываемой системе будет обеспечена возможность ее последующего расширения. Чтобы иметь понятие о предметной области, рассмотрим таблицу данных о заболеваниях туберкулезом. Данные в таблицу собираются по Территориям (Область, Город, Район, ЛПУ) за каждый отчетный год. Исходя из структуры таблицы возможно построить таблицу фактов, имеющую следующие ключевые поля - Код_территории, Год, Код_вида_туберкулеза, Возрастная_категория, а также поле данных – Количество_больных.
На данный момент, мною реализована реляционная база данных в СУБД InterBase, хранящая в себе данные форм медико-статистической отчетности. Клиентский интерфейс к базе данных написан на языке C++ с помощью среды визуального программирования Cbuilder. Так как мы имеем дело с реляционным OLAP то для построения куба используются средства на стороне клиентского приложения, обращающиеся к серверу InterBase для загрузки данных. Для исследуемой таблицы рассмотрим структуру OLAP модели. Она показана на рисунке.
Кружками отмечены поля, являющиеся измерениями куба. Фиксируя определенные значения измерений возможно получат срезы куба. Технология OLAP также позволяет отображать данные в виде диаграмм и кросс таблиц. Для реализации технологии OLAP в среде Cbuilder применяется компоненты Dynamic Cube, компании Data Dynamic. OLAP система дает основу для проведения интеллектуального анализа данных или “раскопки данных”, Data Minig, как его называют в иностранной литературе. Можно дать следующее определение: ИАД - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей. Оперативная аналитическая обработка и интеллектуалный анализ данных - две составные части процесса поддержки принятия решений. Но сегодня большинство систем OLAP заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти два вида анализа должны быть тесно объединены в разрабатываемой системе, то есть система должны фокусироваться не только на доступе, но и на поиске закономерностей. На рисунке представлена общая схема интеграции систем ИАД и ROLAP. Рассотрим задачи которые должна решать система анализа данных. Любой анализ данных производится с определенной целью. Основная цель анализа данных в медицинской статистике – получить необходимую информацию для принятия решений в области управления здравоохранением.
Можно выделить следующие задачи, применимо к рассматриваемой форме:
1)Прогнозирование показателя заболеваемости туберкулезом на определенный период в будущем.
2)Прогнозирование показателя заболеваемости для территорий, по которым нет данных.
3)Выявление возрастных групп риска, наиболее подверженных заболеванию.
4)Выявление связей между показателями заболевамости по определенным видам туберкулеза.
5)Выявление связей между показателями заболеваемости в различных населенных пунктах.
6)Выявление связи между возрастными группами населения и видами заболевания.
7)Решение задач классификации. Выявление территорий с опасной тенденцией развития заболевания. Выявление форм заболевания, несущих наибольшую угрозу эпидемии.
Такая информация поможет легче предотвращать нежелательные последствия эпидемий и проводить лечебно-профилактическую работу среди населения. Таже информация полученная с помощью такого исследования может быть полезной для научного медицинского исследования.
Рассмотрим пути решения данных задач. В Data Mining применяется широкий спектр методов, среи которых регрессионный анализ, временные ряды, деревья решений, нейронные сети и другие. С задачами классификации и прогнозирования хорошо справляются нейронные сети. В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
При решении задачи прогнозирования заболеваемости туберкулезом, входными данными нейронной сети могут быть измерения куба – Время, Территория, Вид туберкулеза, Возраст. Натренировав сеть, используя имеющиеся данные за предыдущие периоды, можно будет осуществлять прогнозы на будущее. Аналогично, возможно натренировать сеть на обнаружение чрезвычайных ситуаций, таких как эпидемии. В данном случае, при обучении, на вход нейроной сети должны подаваться все параметры, соответствующие ситуации. Так как ситуации с заболеванием исследуются на определенной територии и в определенный период, то данные параметры являютяс фиксированные, и на вход сети подаем три переменные – Возраст, Вид туберкулеза, и Количество больных. На выход подаем некоторую числовую меру анализа класса ситуации. Например в простейшем случае может существовать два класса – Обычный уровень заболеваемости. (Y< и высокий уровень заболеваемости (Y>N), где параметр уровня N выбирается из соображений эффективности для конкретной нейронной сети.
Другой метод, позволяющий решать задачу классификации данных – это метод K-ближайших соседей. Рассмотрим ситуацию с туберкулезом легких в ряде городов Донецкой области за 2002 год. Данные представим на графике, где по оси X будет отложена возрастная категория граждан, по оси Y – показатель заболеваемости для данной категории. На пересечении этих значений будем отмечать знаком “+” пары параметров “возраст”/”количество заболевших”, для которых был зарегистрирован опасный уровень заболевания, а знаком “-” - обычный уровень. На рисунке приведены данные по следующим населенным пунктам – Макеевка, Константиновка, Мариуполь. Опасный уровень заболевания зарегистрирован был в Константиновке, и для него приведены данные со знаком +. В Макеевке уровень заболеваемости оставался в норме, и для него данные имеют знак минус. Кружками отмечены данные по городу Мариуполь, подлежащие классификации. Взяты только 3 возрастные категории – 35-39, 40-44, 60-64, так как для осуществления классификации достаточно считывать информацию, не во всех, а в некоторых ключевых точках. Видим, что при 1-м 2-х, 3-х или 4-х ближайших соседях знаки распределятся “неопределенность”, +, +. При пяти ближайших соседях получаем все три плюса. Такиим образом получили первые результаты при количестве ближайших соседей K=5. По полученным результатам можно сказать, что в 2002 году в городе Мариуполь была опасная ситуация по туберкулезу. Для более детального анализа можно взять дополнительные точки. Выбор параметра K также является ключевым моментом при решении данной задачи. Для оценки этого параметра используется метод кросс-проверки.
Основная идея метода заключается в разделении выборки данных на v "складок" (случайным образом выделенные изолированные подвыборки или сегменты). По фиксированному значению К строится К - БС модель для получения предсказаний на v - ом сегменте (при этом остальные сегменты используются как примеры) и оценки ошибки. Для регрессионных задач наиболее часто в качестве оценки ошибки выступает сумма квадратов, а для классификационных задач удобней рассматривать точность (процент корректно классифицированных наблюдений). Далее процесс последовательно повторяется для всех возможных вариантов выбора v. По исчерпании v "складок" (циклов), вычисленные ошибки усредняются и используются в качестве меры устойчивости модели (т.е. меры качества предсказания в точках запроса). Вышеописанные действия повторяются для различных К , и значение соответсвующее наименьшей ошибке (или наибольшей классификационной точности) принимается как оптимальное (оптимальное в смысле метода кросс - проверки).Кросс - проверка вычислительно емкая процедура и следует быть готовым предоставить время для работы алгоритма особенно, если объем образцовой выборки велик. Альтернативный путь - самостоятельно задать значение параметра К. Этот способ приемлем, особенно если распологать обоснованными предположениями относительно возможного значения параметра данными и для них было подобрано оптимальное значение.
Одним из методов, позволяющим выявить ассоциации данных является метод ограниченного перебора. Этот метод вычисляет частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X > a; a < X < b и др., где X — какой либо параметр, “a” и “b” — константы. Ограничением служит длина комбинации простых логических событий. На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных. Также ассоциации данных в исследуемой системе перспективно выявлять методами регрессионного анализа.
Применение методов Data Mining в совокупности дает в последствии информацию для принятия решений на основе накопленных данных. Анализ данных дает необходимую информацию для принятия решений не только в медицине но и в области самой медицинской статистики, например позволяя определять обьекты, сбор данных по которым необходим в большей мере чем по другим. Таким образом решается задача самосовершенствования системы управления через обратную связь. Однако не следует забывать, что конечным звеном системы принятия решений все-равно является человек, инструменты OLAP и Data Mining позволяют лишь облегчить его задачу, выделив важную информацию, способную стать основой для действий в руках специалиста.