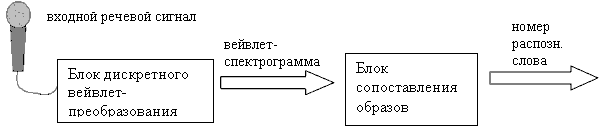
Рисунок 1 - Структура системы распознавания речи
Email: bond005@yandex.ru
Материал взят из электронного сборника трудов I международной научной конференции студентов, аспирантов и молодых учёных «Комп'ютерний моніторинг та інформаційні технології 2006» ( Донецк: ДонНТУ, 2005 )
ОРГАНИЗАЦИЯ РЕЧЕВОГО ВЗАИМОДЕЙСТВИЯ С ИНФОРМАЦИОННЫМИ СИСТЕМАМИ НА ОСНОВЕ НЕЧЕТКОЙ ЛОГИКИ
Диалог с компьютерами, роботами, автоматизированными системами управления с помощью речевых сообщений открывает большие перспективы:
В настоящее время увеличивается интенсивность обмена информацией в системе «человек-машина». Поэтому особое значение приобретает снижение нагрузки на тактильно-зрительные каналы человека. В информационных системах востребованной является идея голосового контроля и управления состоянием системы (речевое взаимодействие для контроля состояния работы самолета, бескнопочный телефон, речевое управление производственными процессами). Внедрение голосового интерфейса оставит глаза и руки оператора (пилота, водителя, рабочего за станком) свободными от перегрузки, что повысит надёжность и качество управления.
Реализация речевого диалога включает решение задачи распознавания речи. Требования к блоку распознавания речи, используемому для организации голосового контроля и управления, таковы:
В соответствии с этими требованиями предложена система распознавания речи. В ней используется словарная модель языка, т.е. объектом распознавания является слово целиком. Эта модель обеспечивает более высокую точность распознавания по сравнению с фонетической или слоговой моделью при условии ограниченного размера словаря [1].
Метод распознавания, применяемый в данной системе, основывается на задании эталонов слов словаря. Сравнение входного речевого сигнала с эталоном выполняется путем нечёткого сопоставления образов [2]. Этот метод прост в реализации. Его особенность является возможность эффективной работы только со словарями небольшого объёма, что удовлетворяет вышеизложенным требованиям.
Формирование образа распознаваемого речевого сигнала выполняется методом одномерного дискретного вейвлет-преобразования. Поскольку речевой сигнал характеризуется наличием амплитудных скачков, изменений знака производной функции сигнала и т.д., то вейвлет-преобразование наилучшим образом подходит для его обработки [3].
Рисунок 1 - Структура системы распознавания речи
Структура система изображена на рис.1. Звук с помощью микрофона преобразуется в сигнал; блок дискретного одномерного вейвлет-преобразования вычисляет детализирующие коэффициенты для вейвлет-декомпозиции сигнала уровня k:
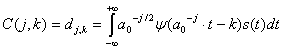
где j – параметр масштаба; k – параметр положения вейвлета на оси времени; a0 – начальное положение вейвлета на оси времени; 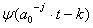 – вейвлет-функция
– вейвлет-функция  при дискретных значениях масштаба
при дискретных значениях масштаба 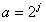 и положения по оси времени
и положения по оси времени 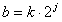 [3].
[3].
Вейвлет-преобразование целесообразно выполнить на 22 масштабах, что позволит полностью покрыть весь спектр речевого сигнала [1]. Базовая вейвлет-функция подбирается экспериментальным путём. В результате получается вейвлет-спектрограмма, которая показывает изменение амплитуды сигнала с течением времени на различных масштабах. Эта спектрограмма рассматривается как образ входного слова, который подаётся на вход блока сопоставления образов. В нём происходит вычисление степеней сходства данного образа с каждым эталонным. Предварительно с помощью линейного растяжения (сжатия) происходит согласование длин входного и эталонного образов. Каждый эталонный образ находится как среднее арифметическое образов из обучающего множества, предварительно сформированного для соответствующего слова. Согласование длин этих образов также происходит с помощью линейного растяжения (сжатия).
На выходе системы формируется номер слова, эталонный образ которого имеет максимальную степень сходства с входным образом.
Список литературы