Email: bond005@yandex.ru
Материал взят из сборника трудов научной сессии МИФИ–2006: том 3, "Интеллектуальные системы и технологии" ( под ред. Ядыкина И.М., Рыбиной Г.В., Синицына С.В. – М.:МИФИ, 2006, страницы 194 – 195 )
ИНТЕГРАЦИЯ ВИЗУАЛЬНОГО И РЕЧЕВОГО СПОСОБОВ УПРАВЛЕНИЯ ПРОЦЕССОМ ВВОДА И РЕДАКТИРОВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ
Рассматривается включение речевого интерфейса в текстовый процессор Microsoft Word с целью повышения эффективности работы пользователя при вводе и редактировании документов. Распознавание речевых команд осуществляется с помощью метода нечёткого сопоставления образов.
Речевой интерфейс, как более естественный для человека, приобретает всё большую востребованность в современных человеко-машинных системах. В основе его построения лежит задача распознавания речи, для решения которой, несмотря на множество предложенных способов, не найден приемлемый метод. Наметились основные направления, базирующиеся на вероятностном, метрическом и нейросетевом подходах. Также перспективен для решения трудноформализуемых задач, к которым относится задача распознавания речи, подход на основе нечёткой логики[1]. В работе [2] описан метод нечёткого сопоставления образов и приведена высокая оценка его эффективности в распознавании английских, немецких и японских слов. Однако, вопросы применения данного метода к распознаванию русскоязычных слов не рассмотрены.
Данная работа посвящена анализу эффективности метода нечёткого сопоставления в задаче распознавания изолированных русских слов, возникающей при интеллектуализации интерфейса текстового процессора Microsoft Word. Рациональное сочетание речевого и стандартного визуального способов управления процессом ввода и редактирования текстовой информации позволит снизить нагрузку на тактильно-зрительные каналы человека и тем самым повысить эффективность его работы.
Речевой сигнал представляется в виде двумерного спектрального временного образа (СВО), получаемого с помощью оконного преобразования Фурье. СВО позволяет выделить местоположение резонансных частот, т.е. локальных выбросов, что является определяющей особенностью речевого сигнала [2]. На этом основании СВО можно преобразовать к двоичному виду, не теряя указанных информативных признаков речи, с помощью следующей замены: 1 – на месте локального выброса, 0 – в других местах. Полученный образ называют двоичным спектральным временным образом (ДСВО) и используют его как отражение особенностей речевого сигнала.
В качестве единиц речи рассматриваются слова, набор которых определяет словарный состав речевого командного интерфейса с редактором Word.
Для распознавания изолированных слов, произносимых в реальном времени, применялся метод нечёткого сопоставления с эталоном [2]. Эталонные образы для каждого слова словаря формировались как среднее арифметическое ДСВО различных вариантов произношения данного слова и затем подвергались нормализации. В результате формируется бинарное нечёткое отношение между множеством F (номеров частот f) и множеством T (номеров временных интервалов t) в виде:
где R – нечёткое отношение, которое ставит каждой паре элементов 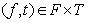 величину функции принадлежности
величину функции принадлежности 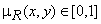 [1].
[1].
Обозначим число записанных слов через n, множество слов через I = {i1, i2, ...in} и множество нечётких отношений, характерных для каждого слова, через R = {r1, r2, ...rn}. Входной неизвестный образ y рассматривается как обычное (чёткое) отношение между множеством частот и множеством временных интервалов. Для него вычисляются степени сходства Sj с каждым нечётким отношением rj . Результатом распознавания является слово j, такое, что
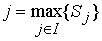 .
.
Степень подобия вычисляется по формуле 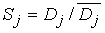 , где
, где 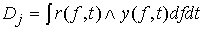 ,
, 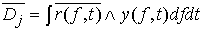 .
.
В результате исследований установлено, что метод нечёткого сопоставления точно распознаёт даже сильно зашумлённые образы, если они не деформированы. Однако, при распознавании речевых образов русского языка, которые характеризуются сильной изменчивостью по структуре расположения локальных выбросов, точность составила 85%.
Список литературы