
Рисунок 3.54 - Пример звукового образа END: а – СВО; б – ДСВО
Email: bond005@yandex.ru
Материал отсканирован из книги «Прикладные нечёткие системы» ( под ред. Т.Тэрано, К. Асаи, М. Сугено. – М.: «Мир», – 1993; страницы 157 – 170 )
3.7 РАСПОЗНАВАНИЕ РЕЧИ
Словосочетание «человеко-машинный интерфейс» часто можно услышать в значении «контакт человека и машины». С точки зрения человека идеальным способом передачи своих намерений является диалог с машиной. Для этого человек может воспользоваться несколькими средствами, но только не речью, хотя с теми, кто находится рядом, он издавна привык разговаривать, не испытывая необходимости осваивать ради этого новые правила и средства. В настоящее время, когда появилась необходимость диалога с роботами или компьютерами, вполне естественно использовать дружественный диалог с помощью слов. Для этого, однако, в будущем придется решать многочисленные проблемы, а существующие сейчас средства имеют ряд ограничений, и им до диалога ещё далеко, хотя практическое их применение так или иначе началось. В рассматриваемом ниже примере в процесс распознавания речи вводятся понятия нечётких множеств, благодаря чему появляется возможность справиться с различиями говорящих и изменениями речи во времени.
3.7.1 Проблемы распознавания речи
Рассмотрим механизм образования речи. Источником гласных звуков являются голосовые связки, изменение формы звукового пути в которых меняет условия их резонанса, преобразуя гласные звуки в звуковые колебания. Согласные звуки издаются не голосовыми связками – их источник располагается в другой части звукового пути. Распознавание речи – это процесс извлечения словесной информации, содержащейся в издаваемых таким образом звуках.
Существуют различные методы распознавания речи, однако в последнее время основным стал метод сопоставления с эталоном. Это связано главным образом с прогрессом в области электронных компонентов, в частности с увеличением вычислительной мощности процессоров и объемов памяти. При сопоставлении с эталоном звуки преобразуются в характерные образы, которые сравниваются с заранее запасенными эталонными образами, и вычисляется степень их подобия. Результатом распознавания является наиболее похожий эталонный образ.
При распознавании речи путем сопоставления с эталоном возникает несколько проблем, среди которых наиболее типичными являются следующие.
1. Временные изменения характерных образов речи. Причиной изменений является различная скорость произнесения одних и тех же звуков, т. е. непостоянство длительности звуков. Даже одни и те же слова, произносимые человеком, каждый раз меняются по длительности. Если же одни и те же слова произносятся разными людьми, их длительности могут еще больше различаться.
2. Влияние размеров органа речи на образы. Как уже говорилось выше, размеры органов речи у людей различны. Поэтому, даже если слова произносятся органами одинаковой формы, их резонансные частоты могут различаться. На образах это проявляется как индивидуальная особенность человека.
Кроме этого существуют проблема артикуляционного сопряжения, т.е. различия одного и того же звука, обусловленные влиянием различных звуков до и после него, проблема акцента, возникающая за счет различия в манере говорить и в условиях жизни говорящих, и другие проблемы. Ниже обсуждаются только первые две проблемы.
Первая проблема связана с необходимостью подстраивать временные интервалы при сопоставлении образов (временная нормализация). Известен простой способ согласования длительностей образов – линейное сопоставление. Однако, поскольку изменение длительности образов не обязательно должно быть линейным, для решения проблемы предлагается использовать ДП-сопоставление, вводящее в процедуру сопоставления образов принципы динамического программирования [26]. ДП-сопоставление. будучи нелинейным сопоставлением, устанавливает временное соответствие, обеспечивая при сопоставлении пары характерных образов минимальную ошибку или максимальную степень подобия. С этой целью используется метод динамического программирования, который позволяет повысить точность сопоставления и вносит существенный вклад в развитие распознавания речи, хотя и требует для своей реализации большого объема вычислений.
Что касается изменений, связанных с говорящим (вторая проблема), то задача, на первый взгляд, кажется простой, поскольку человек способен распознавать любой голос, но на самом деле она чрезвычайно сложна. В настоящее время эта задача решается с помощью метода статистической обработки изменений, связанных с говорящим, или метода большого числа шаблонов. В соответствии с последним методом в процессе сопоставления образов применяется большое число разнотипных эталонных образов, относящихся к одной категории, благодаря чему даже при наличии изменений во входном образе удается установить соответствие одному из многочисленных эталонных образов. Число эталонных образов, подготовленных для каждой категории, не оговаривается: известно, что их число может быть 20 – 60 [27]. Вместе с тем следует отметить, что при большом числе образов объем вычислений в процессе сопоставления будет возрастать.
Для того чтобы решить проблему артикуляционного сопряжения, часто применяют большие единицы распознавания типа слов, произносимые с паузой. Можно не принимать во внимание проблему частотных изменений (вторую проблему), если ограничиться одним пользователем. Распознавание в этом случае начинается после обучения по голосу этого человека. Такой метод называют распознаванием определённого говорящего. Почти все известные в настоящее время устройства распознавания речи созданы на основе распознавания слов определенного говорящего, что объясняется изложенными выше причинами. С другой стороны, распознавание без обучения для любого голоса называют распознаванием неопределенного говорящего. Создаются и устройства на основе этого метода, но число распознаваемых ими слов достигает всего нескольких десятков, а сами устройства довольно громоздки.
Ниже рассматривается реализация устройства распознавания неопределенного говорящего на 109 и более слов с помощью простых вычислений с введением в процесс распознавания слов понятий нечётких множеств [28].
3.7.2 Нечёткое сопоставление образов
Рассмотрим прежде всего характерные образы для распознавания речи.
В качестве признаков, извлекаемых из речи, хорошо известны LPC (коэффициент линейного предсказания), кепстр, спектр и другие. Среди этих признаков авторы выбрали спектр», позволяющий легко установить соответствие с физической величиной. На спектральном временном образе (СВО), по осям которого откладываются время и частоты, получаемые в результате деления речи на короткие интервалы и спектрального анализа на этих интервалах, хорошо выражены особенности речи. Считывая спектр, человек может «читать» по СВО произносимые звуки.
Как указывалось выше, человек произносит слова, изменяя органом речи резонансную частоту, поэтому особенно важными в СВО являются резонансные частоты, то есть выбросы. Резонансные частоты для гласных звуков называют формантами, однако используют и название «локальный выброс» как расширение понятия форманта на согласные звуки [29]. В рассматриваемом здесь методе распознавание произносимого слова осуществляется путем определения, какой локальный выброс присутствует и как он меняется во времени. Две проблемы, указанные в разделе 3.7.1, в данном случае проявляются как изменение длительности образа и изменение частоты локальных выбросов, обусловленные говорящим.
Поскольку интерес представляет лишь местоположение локального выброса, данные можно представить в двоичном виде: 1 – на месте локального выброса, 0 – в других местах, локализовав тем самым положение выброса и сократив объем данных. Полученный образ называют двоичным спектральным временным образом (ДСВО) и используют его как особенность речи. Применение ДСВО при сопоставлении образов заключается в том, что для слова, выраженного с помощью ДСВО, рассматривается функция принадлежности, учитывающая то, как проявляются на ДСВО изменения частоты для разных людей и как происходят изменения во времени. Этот метод называют нечётким сопоставлением образов [30].
На рис. 3.54 представлены примеры образов: а – СВО слова END, произнесённого мужчиной: б – ДСВО, полученный из СВО путем преобразования в двоичный код. По горизонтальной оси отложена частота, по вертикальной – время, на оси частот на каждые 10 мс приходится 15 выборок. На рис. 3.54,а значение каждого элемента представлено восемью битами, в ДСВО (рис. 3.54,б) данные по 15 выборкам можно представить двумя байтами, что очень удобно для ввода в компьютер.
Рисунок 3.54 - Пример звукового образа END: а – СВО; б – ДСВО
Обозначим число записанных слов через п, множество слов через I = {i1, i2, i3, ..., in} и множество образов этих слов через X = {x1, x2, ..., xj}. Множество I – это обычное множество из n элементов, а множество X можно рассматривать как нечёткое множество, в котором xj (j = 1, 2, 3, ... n) представляет различные образы слова ij . Таким образом, можно определить множество функций принадлежности M = {m1, m2, ..., mn} подобно тому, как определяется множество образов xij слова ij . Рассматриваемое здесь нечёткое сопоставление образов заключается в следующем. При вводе неизвестного образа y ( ) с использованием функции принадлежности M вычисляется степень сходства Sj образов xj и у, и результатом распознавания является слово j, такое что
) с использованием функции принадлежности M вычисляется степень сходства Sj образов xj и у, и результатом распознавания является слово j, такое что
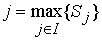 . .
|
(3.32) |
При использовании нечёткой логики часто возникает проблема определения функции принадлежности. В данном случае следует решить, как определить сходство образов слов xj. Функция принадлежности должна иметь какое-то отношение к человеку, однако по причинам, изложенным в разд. 3.7.5, её целесообразно приписать устройству распознавания. Поэтому, считая сходство главной целью, приняли следующую последовательность построения функции принадлежности.
Для всех слов, которые должны быть записаны, собираются голоса многих говорящих и преобразуются в ДСВО. Для каждого слова суммируются все образы и составляется двумерная функция принадлежности, в которой из этих данных выбраны изменения в представлении слова. В частности, определяется среднее арифметическое образов, отобранных в соответствии с некоторым критерием из ДСВО одного слова. При суммировании возникает одна трудность. Среди двух типов упомянутых ранее изменений частотные изменения вызывают лишь изменение на оси частот положений 1, которые являются элементами, показывающими резонансную частоту в образе, в то время как при временных изменениях происходит изменение длин образа, что затрудняет суммирование.
В связи с этим перед суммированием с помощью линейного растяжения/сжатия осуществляется согласование длин образов. Эта процедура представляет собой простой способ выравнивания длин сравниваемых образов за счет прореживания и вставок. По сравнению с нелинейным растяжением/сжатием он дает существенно меньший объем вычислений. Пример функции принадлежности, полученный в соответствии с этой процедурой, показан на рис. 3.55. Объектом распознавания является слово START. Прежде всего выполняется согласование по длине и совмещение левого ДСВО с соседним. Соответствующие элементы при этом суммируются. Затем прибавляется следующий ДСВО: такой процесс повторяется до получения образа справа, который используется как функция принадлежности. Обычная функция принадлежности принимает значения от 0 до 1, однако в данном случае она представлена в виде целых чисел со значениями от 0 до 15, то есть по четыре бита на элемент.
Рисунок 3.55 - Пример функции принадлежности слова START
Определим теперь степень подобия. Пусть y () – ДСВО неизвестного входного голоса. Если с помощью функций принадлежности mj определить его степени принадлежности ко всем нечётким множествам, то можно узнать, какое это слово. Однако использование введенной выше функции принадлежности приводит к ряду проблем. Поясним это с помощью рис. 3.56.
На рис. 3.56,а показаны локальные выбросы некоторого голоса. Если выбросы есть для частот f1 и f2, можно записать
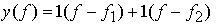 . .
|
(3.33) |
где 1 обозначает следующую функцию:
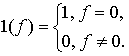
На рис. 3.56,б и в приведены функции принадлежности множеств образов слов j и k, причём на рис. 3.56,б имеются два локальных выброса, на рис. 3.56,в – один. Местоположение двух локальных выбросов в первом случае полностью совпадает с максимумами функции принадлежности, их степень принадлежности равна 1. Поэтому максимумы функции принадлежности нормализуются до значения 0,5. Степень принадлежности Dj образа y к xj будет иметь вид
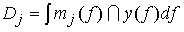 . .
|
(3.35) |
В случае рис. 3.56,а она почти равна 1 и показывает сходство со словом j. С другой стороны, функция на рис. 3.56,в принадлежит к типу функций с одним локальным выбросом, что свойственно согласным звукам. Ее максимум равен 1. Если определить по формуле (3.34) степень принадлежности образа рис 3.56,а к образу xk , определенному через функцию принадлежности на рис. 3.56,в то также получим значение, почти равное 1. Возникает противоречие: образ на рис. 3.56,а обладает одинаковым сходством и с xj , и с xk . Поэтому определяем инверсную степень принадлежности
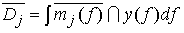 . .
|
(3.36) |
где 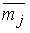 – функция принадлежности, представляющая известный образ дополнительного множества j. За счет введения формулы (3.35) инверсная степень принадлежности для рис. 3.56,а и в становится большой и появляется возможность выделить близость рис. 3.56,а к б.
– функция принадлежности, представляющая известный образ дополнительного множества j. За счет введения формулы (3.35) инверсная степень принадлежности для рис. 3.56,а и в становится большой и появляется возможность выделить близость рис. 3.56,а к б.
В рассуждениях, представленных выше, мы ограничились только частотой, уменьшив для простоты размерность: фактически имеет место двумерное распределение. В этом случае не только трудно учесть число локальных выбросов и нормализовать значение выбросов функции принадлежности, но и нецелесообразно отводить четыре бита на каждый элемент. Для вычисления степени подобия без нормализации определим её как отношение формул (3.34) и (3.35):
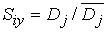
В случае когда нормализация не производится, Dj , стоящее в числителе этой формулы, будет возрастать с увеличением числа локальных выбросов в у, но за счет того, что в знаменателе стоит величина 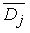 , которая, как и Dj , легко принимает большие значения при увеличении числа локальных выбросов, нормализация не требуется.
, которая, как и Dj , легко принимает большие значения при увеличении числа локальных выбросов, нормализация не требуется.
В реальном устройстве распознавания приходится оперировать с дискретными величинами. В этом случае используется следующее выражение для степени подобия:
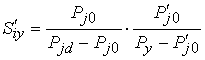 . .
|
(3.37) |
где
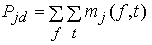 ,
,
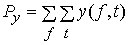 ,
,
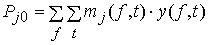 ,
,
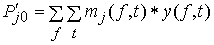 .
.
Знак • обозначает произведение элементов mj и y, а * – логическое произведение mj и y уровня 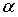 , то есть
, то есть
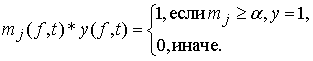
Если значения элементов функции принадлежности представлены четырьмя битами, то чаще всего 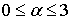 .
.
Формула (3.37) состоит из двух членов, причем оба по виду похожи на формулу (3.36). Числитель и знаменатель левого члена – это, соответственно, 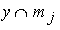 ,
, 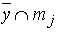 ; правого –
; правого – 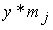 ,
, 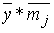 .
.
3.7.3 Структура системы
С помощью описанного выше метода распознавания была создана реальная система распознавания. Блок-схема системы показана на рис. 3.57. Звук с помощью микрофона преобразуется в сигнал; на группе фильтров производится разложение сигнала по частотам, затем выполняется преобразование в двоичный код и составляется ДСВО. Блок, обозначенный на рисунке пунктиром, относится к упомянутому выше обучению, в обычном методе распознавания неопределенного говорящего он не используется. Работа остальных блоков осуществляется следующим образом.
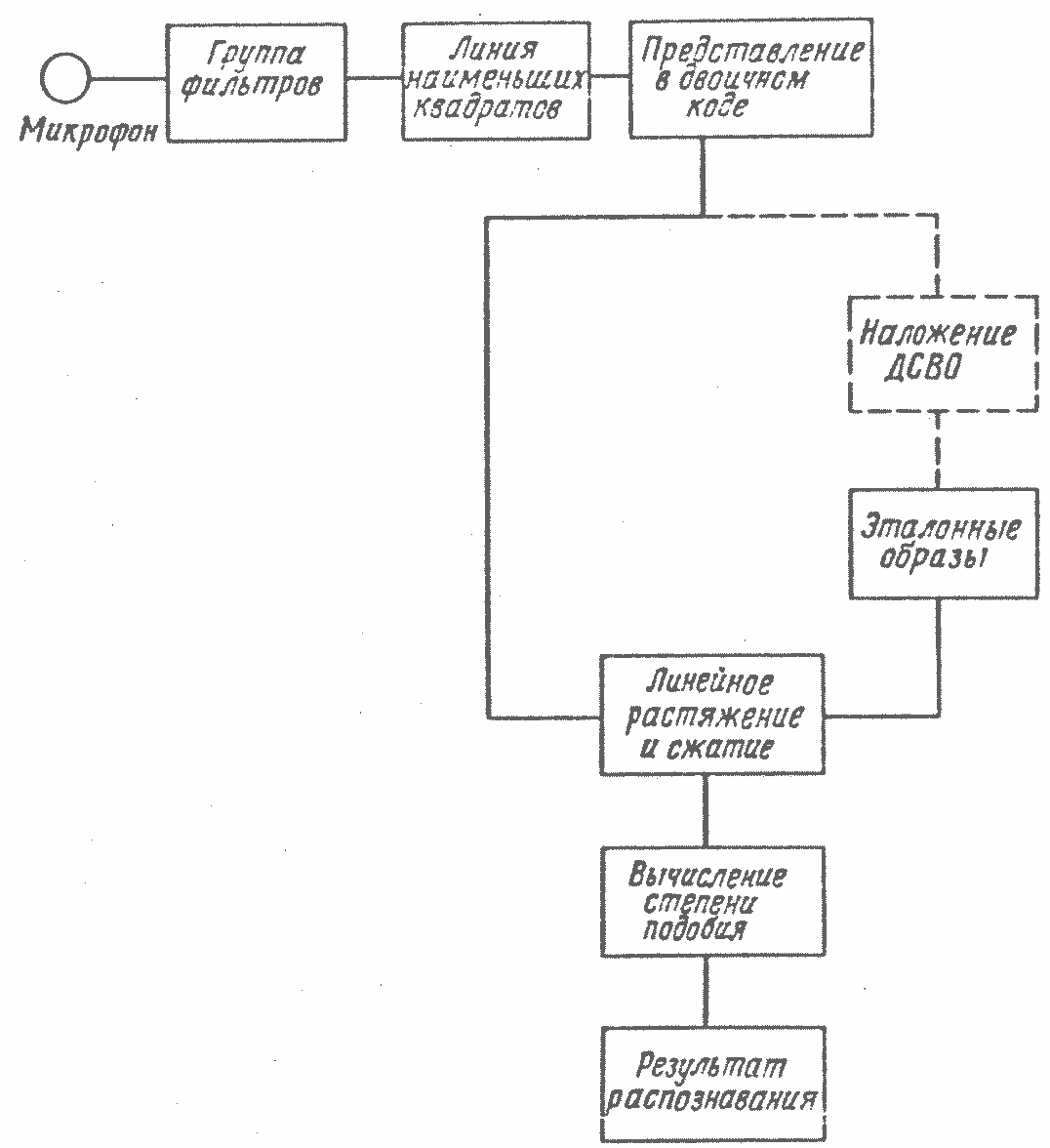
Рисунок 3.57 - Блок-схема системы распознавания
1. Группа фильтров – это набор из нескольких полосовых фильтров, в данной системе их 15. Центральные частоты – 250...6300 Гц с шагом 1/3 октавы: острота резонанса фильтpa Q равна 6. Выходные сигналы фильтров сглаживаются, квантуются выборками через 10 мс. В результате получаются 15-мерные векторы. Выходы фильтров на данном этапе представлены восемью битами.
2. Преобразование в ДСВО. Среди 15 данных из группы фильтров выделяются пиковые значения, их окрестности принимаются за 1, а остальные места за 0, таким образом выполняется преобразование в двоичный код. При этом характеристики источника звука нормализуются. Звук, образующийся при колебаниях голосовых связок, за счет колебательных свойств связок ослабевает на высоких частотах. Поэтому перед преобразованием в двоичный код определяется линия наименьших квадратов для 15 значений данных, и её наклон корректируется [31]. Затем в области над этой линией выделяются пиковые значения и выполняется преобразование в двоичный код. В реальном устройстве вычисление линии наименьших квадратов отсутствует; в нем используются фильтры, которые позволяют достичь почти такого же результата [32]. По наклону полученной линии можно узнать разновидность звука: отрицательный наклон – звонкий, положительный – глухой, и в ДСВО добавляется 16-й столбец данных с 1 и 0 соответственно.
3. Блок сравнения. Степень подобия между неизвестным входным образом и функцией принадлежности, зафиксированной как эталонный образ, вычисляется по формуле (3.37). Длительности обоих образов согласуются с помощью линейного сжатия/расширения, аналогичного тому, которое выполняется при формировании функции принадлежности. Временные изменения фиксируются в функции принадлежности в виде изменений, нормированных линейным сжатием/расширением. Иначе говоря, в эталонном образе появляются, кроме 0 и 15, промежуточные значения, и блок сжатия/расширения ведет себя как нелинейный.
3.7.4 Эксперименты по распознаванию
Ниже описаны результаты экспериментов по распознаванию неопределенного говорящего. Эксперименты проводились на японском, английском и немецком языках. Японский набор включал 110 команд управления аппаратурой для автоматизации учреждений, дополненный цифрами и обычными словами [33], английский и немецкий – 120 слов такого же содержания, а также названия животных и цветов [34]. Особого внимания выбору слов не уделяли, поэтому попадались группы из нескольких трудноразличимых слов. Например, в японском языке – «року», «коку», «оку», в английском – «quick», «quit», в немецком – «nein», «neun» и др.
Эти слова записывались на ленту в звукоизолированном или почти звукоизолированном помещении, аналоговая запись преобразовывалась в цифровой код, который вводился в миникомпьютер, где формировались эталонные образы. (Для справки отметим, что английские слова собирались на западном побережье США, немецкие – в северных районах ФРГ.)
В табл. 3.12 приведены средние коэффициенты распознавания, полученные в экспериментах при описанных выше условиях. Как следует из таблицы, коэффициент распознавания для любого языка составляет примерно 93%.
Таблица 3.12. Коэффициент распознавания неопределенного говорящего
| Язык | Японский | Английский | Немецкий |
| Коэффициент распознавания, % | 93,2 | 92,8 | 95,7 |
3.7.5 Групповое применение
Изложенный выше метод неопределенного говорящего позволяет, по идее, распознавать любой голос без обучения путем обработки речи многих людей и формирования эталонных образов. Однако на практике нет необходимости в распознавании любого голоса. Например, часто достаточно распознавать голоса ограниченного круга людей, сотрудников учреждения. Более того, целесообразно несколько повысить коэффициент распознавания, ограничивая число пользователей. Как уже говорилось выше, данный метод позволяет встраивать функции принадлежности в устройство. Это сделано для того, чтобы пользователи при обучении создавали собственные групповые функции принадлежности. Такой метод применения называется групповым.
В экспериментах по распознаванию при групповом применении регистрация и распознавание проводились в четырех группах по 10 мужчин и женщин в каждой. Использованы те же данные, что и в экспериментах по методу неопределенного говорящего, однако после обучения по десяти голосам из одной группы вводились голоса тех же людей, но при других обстоятельствах. В результате в среднем по четырем группам коэффициент распознавания составил 95,90%, то есть по сравнению с методом неопределенного говорящего удалось повысить коэффициент распознавания на несколько процентов.
Естественно, если обучение ведется одним человеком, устройство можно использовать для реализации метода определенного говорящего. В этом случае изменения по частоте и длительности по сравнению с методом неопределенного говорящего незначительны, поэтому значения элементов функции принадлежности целесообразно представить двумя битами, а запись одного слова делать три раза. В результате можно получить средний коэффициент распознавания по трём указанным языкам 98–99%, точнее говоря, это значение, усредненное по 120 словам на японском и других языках по данным распознавания для десяти мужчин и женщин для каждого языка.
В данном разделе в качестве примера было рассмотрено применение нечёткой логики для распознавания речи. Известны другие попытки использования нечёткой логики в этих целях [35, 36], однако все они отличаются от описанного здесь подхода, в котором использована идея нечёткого сопоставления образов. Этот метод сопоставления позволяет с помощью простых вычислений добиться высокого коэффициента распознавания и обеспечивает распознавание более 100 слов по методу неопределенного говорящего. Наряду с этим, используя процедуру обучения функции принадлежности, его можно адаптировать для метода определенного и неопределённого говорящего и для группового использования.
МОЯ БИБЛИОТЕКА