Shunji SATOH, Shogo MIYAKE and Hirotomo ASO
We examine the number of cells and execution time taken to correctly recognize rotated patterns in two models: a rotation-invariant neocognitron (R-Neocognitron) and a neocognitron-type model (TD-R-Neocognitron) which recognizes rotated patterns by use of an associative recalled pattern. In numerical simulations handwritten patterns in CEDER database are used for training and evaluation of recognition rate. We show that TD-R-Neocognitron needs less cells than R-Neocognitron if the number of pattern classes is large. Execution time by TD-R-Neocognitron is about three times as much as that of R-Neocognitron, but TD-R-Neocognitron is more effective and efficient for patterns including many classes like Japanese characters.
Various visual models for pattern recognition based on the Neocognitron[1] have been proposed. We have proposed a rotation-invariant Neocognitron (referred to R-Neocognitron, see [2]), which is based on the Neocognitron. It can recognize also rotated patterns as well as correctly recognized patterns by Neocognitron. R-Neocognitron can recognize rotated patterns in any angles by learning of not-rotated patterns only.
Another type of models for recognition of rotated patterns also has been proposed by authors. The model (referred to TD-R-Neocognitron, see [3]) is based on Neocognitron-type models and recognizes rotated patterns by use of a result of an associa-tively recalled pattern given by a top-down process of the model. TD-R-Neocognitron is a model of visual pattern-integration and mental rotation. The recognition ability of TD-R-Neocognitron has the same recognition ability as that of R-Neocognitron; it is also tolerant for rotations, deformations and so on. It is very interesting that a behavior of TD-R-Neocognitron for mirrored-rotated patterns is same as one of human.
The aim of previous researches on Neocognitron-type networks was mainly to construct efficient models for recognition of rotated patterns and to improve the recognition rate [2, 3]. However, the number of cells and execution time taken to correctly recognize patterns should be also investigated in order to construct more efficient and effective visual models. It is especially significant to examine a tendency of the number of cells with increasing the number of training patterns; small number of cells is desired.
Because R-neocognitron recognizes rotated patterns by generating cells that detect rotated local patterns (local features), a lot of cells may be generated for target patterns. For example, when the model learns a not-rotated "2", new cells are generated so that the cells detect rotated local patterns of which the "2" is composed. Hence, the number of cells may dramatically increase with increasing the number of training patterns. On the other hand, TD-R-Neocognitron does not generate additional cells as R-Neocognitron. It recognizes a rotated pattern by estimating the rotation angle with the aid of an associatively recalled pattern. So it is expected that the number of cells in TD-R-Neocognitron is less than that of R-Neocognitron.
However, it is considered that TD-R-Neocognitron takes more times to recognize rotated patterns than R-Neocognitron because TD-R-Neocognitron needs a top-down process to recall a standard (not-rotated) pattern in order to estimate a rotational angle.
In this paper, we make numerical simulations by use of CEDER database including handwritten alphabets and numeral figures, and evaluate the two models on two points: (i) the number of cells and (ii) execution time.
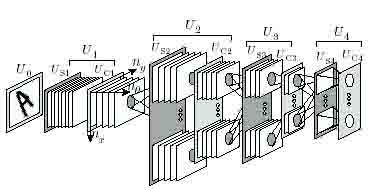
R-Neocognitron is a multi-layered neural model. The layer Usi and Uci preceded by an input layer UQ as shown in Fig. 1.
Figure 1: The structure of R-Neocognitron
The set of Usi and Uci is referred to a module [/;. Here the layer Usi denotes a layer consisting of S-cells in the Ith module, and Uci a layer consisting of C-cells. A layer is composed of a number of cell-plane stacks, and different cell-plane stacks detect different features of inputs. A cell-plane stack is composed of a number of cell-planes, and each cell-plane detects a different rotation angle of the features. Each cell in a cell-plane stack is located in a iftree-dimensional space. In the model the angle of a local pattern in an input is represented by a number ng assigned to a cell-plane in a cell-plane stack, and positional information of the pattern is represented by coordinates (nx,ny) of a firing cell in the cell-plane of n0.
The output response of an S-cell located on n = (nx,ny,no) of the /cth cell-plane stack in the Zth module is denoted by Usi(n,k), and the output response of a C-cell by Uci(n,k). The output response Usi(n,k) is given by
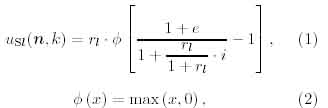
where
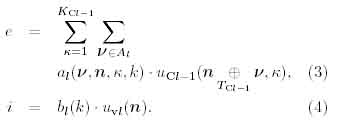
A binomial operator ® with M is defined by
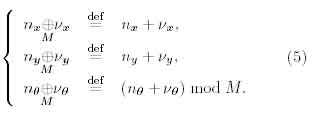
Here rl denotes a threshold value of a cell, ai(v,n,K,k) represents an excitatory connection from C-cells in the anterior layer to an S-cell and bi(k) an inhibitory connection from a V-cell to an S-cell. Each connection is linked to a restricted number of C-cells in the preceding module, and Al(C Z^3) defines the number of C-cells. Kcl denotes a number of cell-plane stacks in the Ucl layer and Tcl a number of cell-planes in the Uci layer.
The output response of a V-cell is given by
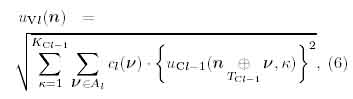
where the function ? is de?ned by
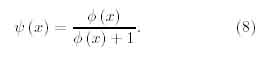
Here di(y) is an excitatory connection from an S-cell to a C-cell, DI(C Z3) represents a restricted region of the connection, TSI a number of cell-planes in the Usi layer.
While the learning stage, excitatory connections ai(v,n,K,k) and inhibitory connections 6j(fc) are modified. A learning method of neocognitron-type models as R-Neocognitron is a kind of winner-take-all rule. A winner cell is referred to a seed-cell. If a seed-cell, ugi(n,k), is selected, the modification rules of plastic connections of the S-cell are denoted by the following equations,
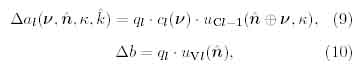
where the value qi is a constant positive value.
The structure of TD-R-Neocognitron is shown in Fig. 2. The model is composed of five parts; (1) R: the model of retina UQ, (2) BU: a bottom-up part which executes a recognition process, (3) Q: a queue, tentative results are queued in the Q, (4) TD: a top-down part which recalls standard patterns corresponding to a tentative result stored in Q and (5) AE: an angle estimator.
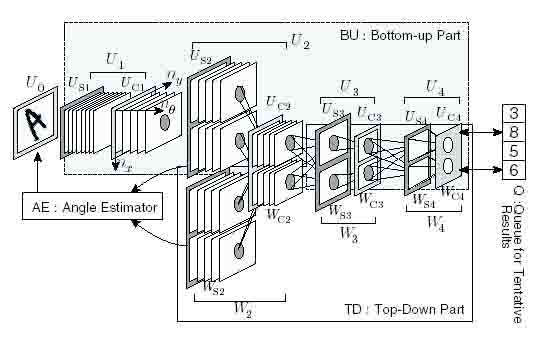
Figure 2: The structure of TD-R-Neocognitron.
Because the BU composed of Neocognitron-type layers in the higher modules and consequently the BU can not recognize largely rotated patterns, all gnostic cells would make no response if such the rotated patterns are presented in the retina Uo. At that time, the BU execute the following two processes in order to make one or more gnostic cells fire at force; (i): the BU decreases the value of selectivity (threshold) of S-cells in Us3 and Us4, and (ii): spreads the blurring region of C-cells in Uc2, Uc3 and Uc4- By executing these processes, the BU produces tentative (hypothetical) recognition results for a largely rotated pattern.
The tentative recognition results (hypotheses) given by the BU are queued in the Q shown in Fig. 2. Since the hypotheses must not be correct ones and the reliability would be low, a verifying process is executed.
The structure of the TD is shown in the lower part of Fig. 2. The TD is composed of modules W4, W3, and W2, and a module Wl includes two layers, Wsl and Wcl- Each layer includes a number of cell-planes or cell-plane stacks. A cell wsl is in the layer Wsl, and a cell wcl in the layer Wcl- Cells wvl are not depicted in Fig. 2. As shown in Fig. 2, two cells are unified into one common cell in order to decrease the number of cells in the whole model. For example a cell wss in the TD is identical with Us3 in the BU. The structure of the TD and the values of connections are the same as those of the BU, but the direction of information flow is centrifugal, that is, right to left in Fig. 2.
The TD recalls a standard not-rotated pattern corresponding to the hypothesis queued in Q. The output of a wci cell in Wci and the cell Wvl in in the backward paths are given by
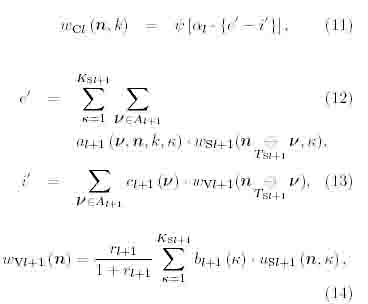
where al is a positive constant. The output of a wsl cell in Wsl is given by
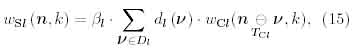
where ?l is a positive constant.
The AE determines the angle of an input rotated pattern by calculating the angle shift between the firing patterns appeared in Us2 and Ws2. The angle shift, ?, is given by
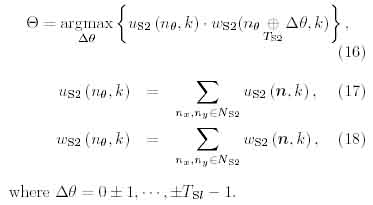
The largely rotated pattern is rotated in the angle estimated by the AE in order to verify the hypothesis queued in the Q, and the rotationally corrected input is recognize by the BU again. If the recognition result given by the second trial by the BU is equal to the hypothesis, the hypothesis is adopted as the final recognition result because the hypothesis is proofed. On the other hand, if the result given by the second trial is not equal to the hypothesis, the hypothesis is dismissed and other hypothesis in the Q will be verified.
The major learning rule for neocognitron-type models is an unsupervised learning with a kind of winner-take-all process, and the rule is adopted to S-cells (feature-extracting cells) in the layer U$2, C/S3 and f/s4 DThe learning of a module begins when learning of the preceding modules has been completely finished. The rule is summarized as the following: (I) A new cell-plane or cell-plane stack is generated, if a training pattern is presented and there are no S-cells which detect a local pattern in the training pattern. Then the generated S-cells in the plane or stack are so reinforced that the S-cells detects the local pattern. (II) If there are already S-cells that detects the local pattern, a new cell-plane or cell-plane stack is not generated.
Therefore, the number of cells tends to increase with increase of the number of training patterns because local patterns which are not learned yet may appear in new training patterns.
As shown in the past examinations R-Neocogni-tron showed is completely tolerant for rotations, so the model is trained so as to recognize point symmetrical patterns, "6"-"9" and "M"-"W," as identical ones in the recognition layer C/C4- On the other hand, TD-R-Neocognitron correctly distinguishes these patterns. In both models we regard the class "O" as the same class with "zero". Parameters for the number of cells are given in Table 1. 4.1 The Number of Cells
We compare the number of cells needed in R-Neocognitron with the number in TD-R-Neocognitron using training patterns, a set of handwritten alphabets and numeral figures given by CEDER database as shown in Fig. 3.

Figure 3: Examples of training patterns given in CEDER database.
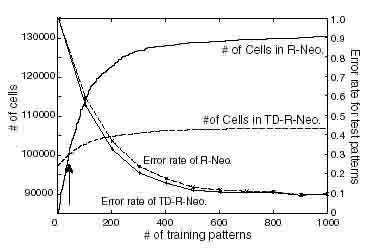
Figure 4: Averaged number of cells over 10 initial values vs. the number of training patterns, and error rate for 36 x 100 x (10 + 26) test patterns
After training the module U2 using 1,000 training patterns, we prepare ten different initial values of plastic connections in the third module 2 for the both models, and train the Uy, for each model using 1 ~ 1,000 training patterns. The Fig 4 shows the change of the averaged number of cells over 10 initial values with the increase of the number in training patterns.
If the number of training patterns is less than 50 (indicated by an arrow in Fig. 4), the number of cells in TD-R-Neocognitron is larger than that of R-Neocognitron, because the number of cells in the second module, U2 and W2, of TD-R-Neocognitron is twice as number as that of R-Neocognitron in which only U2 is in the second module. But the number of cells in R-neocognitron becomes larger than that of TD-R-Neocognitron if the number of training patterns exceeds about 50.
Table 1: The number of cell-plane stack, and the number of cells in one cell-plane stack. The numbers in columns marked by asterisks are not defined, and the numbers in parentheses in columns are ones of TD-R-Neocognitron.
| l=0 | l=1 | l=2 | l=3 | l=4 | |
| Nsl | * | 59 | 17 | 13 | 3 |
| Tsl | * | 16 | 8 | 4(1) | 2(1) |
| Ncl | 61 | 19 | 17 | 10 | 1 |
| Tcl | 1 | 8 | 4 | 2(1) | 1 |
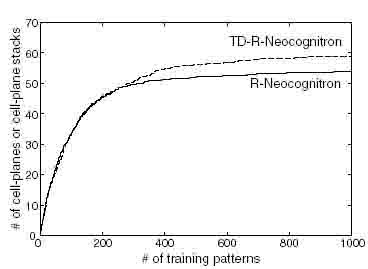
Figure 5: The number of cell-planes or cell-plane stacks in the module U$ for each model becomes larger with the increase in the number of training patterns.
As shown in Fig. 5, the averaged number of cell-planes or cell-plane stacks in the third module over 10 initial values increases with the number of training patterns. The number of cell-planes in TD-R-Neocognitron is almost equal to the number of cell-plane stacks in R-Neocognitron. This means that R-Neocognitron generates a lot of wasteful cells in the third module for handwritten patterns. More concretely, R-Neocognitron generates four times cells as many as TD-R-Neocognitron in the third module since Ts3 = 4 in R-Neocognitron and Ts3 = 1 in TD-R-Neocognitron. This means that there are few rotated local patterns which would be detected by S-cells in Us3. This results show that R-Neocognitron generates cells that detect local patterns, and in addition the model also generates cells which detect the rotated ones of those local patterns in any case. This is the reason why R-Neocognitron needs more cells than TD-R-Neocognitron as increase in the number of training patterns.
The ratios of averaged recognition time for each class of patterns by TD-R-Neocognitron to that by R-Neocognitron are shown in Fig. 6. We can observe that each recognition time for "zero" and "O" by TD-R-Neocognitron is less than that by R-Neocognitron. Reasons for this are; (i) TD-R-Neocognitron is composed of less cells than R-neocognitron and (ii) both a recall process by the TD and an angle estimation by the AE are not needed for these patterns. On the contrary, very similar patterns for rotations, e.g. "2"-"5," "M"-"W"-"V", take more execution time than other classes since there are many tentative recognition results for these patterns and a verifying process for each tentative result should be done.
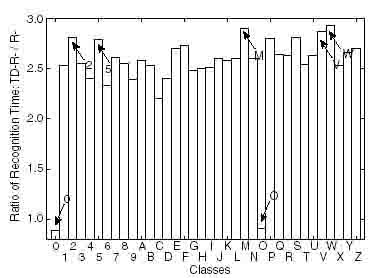
Figure 6: Relative recognition time for each class: R-neocognitron to TD-R-neocognitron.
We evaluate the two Neocognitron-type models from two points of view: (i) the number of cells and (ii) recognition time. From the results of numerical experiments we can see that R-Neocognitron works efficiently if the number of pattern-classes is relatively small or there are no point symmetrical patterns in target patterns, e.g. coin images or chip set images. On the other hand, TD-R-Neocognitron is more effective for recognition of huge numbers of pattern-classes such as Japanese characters which numbers amount to 6,349 in Japanese Industrial Standard.
This work was supported by JSPS Research Fellowships for Young Scientists. References