ДонНТУ, ФВТИ, ПМИ
Автореферат на квалификационную работу магистра
на тему:
«Исследование
методов организации данных в задачах разбиения графов больших
размерностей»
Выполнила Краснокутская Мария
ВВЕДЕНИЕ
Параллельные вычисления позволяют значительно повысить эффективность и
скорость обработки информации при решении современных задач. Такие
задачи возникают в электромеханике, при оптимизации сложных систем,
при прогнозировании погоды, моделировании разнообразных технических и
природных процессов.
Одна из основных проблем, которая возникает в каждом параллельном
вычислении, это распределение обработки данных между процессорами.
Решением может быть использование математической модели, в основе
которой лежит граф потоков данных (ГПД). Программа представляется
набором вычислительных узлов-подзадач, которые имеют фиксированное
количество информационных входов и выходов. Каждая подзадача
выполняется на отдельном процессоре. Узлы-подзадачи – вершины графа
потоков данных, а информационные потоки между ними – ребра графа.
Оптимальное распределение обработки данных между процессорами
минимизирует время выполнения всех вычислений. Задача распределения
обработки данных на процессоры сводится к задаче разбиения графа.
Необходимо разбить граф потоков данных так, чтобы количество связей
между подграфами было минимальным. Практический опыт показал, что
качество распределения задач между процессорами сильно влияет на
производительность, что обусловило значительный интерес к алгоритмам
разбиения графов [1].
К сожалению, разбиение графа – NP-сложная задача, и поэтому все
известные алгоритмы разбиения являются эвристическими и дают
приближенный к оптимальному результат. Однако, не смотря на это
ограничение, было разработано много алгоритмов разбиения графов,
дающих высококачественное разбиение за малое время [2].
При программной реализации любого из этих алгоритмов встает задача
выбора типа данных для представления информации о графе. Существуют
различные способы внутреннего представления графов в оперативной
памяти ЭВМ, в том числе в виде списков (массивов) вершин и ребер,
списков (массивов) смежности, матриц смежности, а также в виде
комбинаций этих структур хранения. Выбор внутреннего представления
оказывает решающее влияние на эффективность выполнения различных
операций над графами [3].
Целью данной работы является исследование методов организации данных в
задачах разбиения графов больших размерностей.
ПОСТАНОВКА ЗАДАЧИ О РАЗБИЕНИИ ГРАФА
Исходным объектом для задач разбиения служит неориентированный граф.
Пространством решений служит множество всевозможных разбиений графа на
непересекающиеся подграфы. На разбиения графа могут накладываться
ограничения D. Для различных задач, естественно, возможны различные
ограничения.
Задачи декомпозиции имеют следующий набор основных критериев:
• число внешних соединений между подграфами;
• число подграфов.
Первый
критерий определяется функционалом внешних связей. Смысл второго
критерия очевиден: он просто равен числу подграфов разбиения.
Постановки задач могут варьироваться в зависимости от свойств графа,
которые задаются моделируемым объектом.
Пусть
задан неориентированный взвешенный граф G(V,E)
порядка n, где
V={v1,…,vn}
– множество вершин;
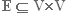 – множество ребер.
– множество ребер.
Требуется определить разбиение множества вершин V графа G(V,E) на k –
подмножеств (V1,…,Vk) таким образом, чтобы для частей графа
G1(V1,E1),…, Gk(Vk,Ek) выполнялись следующие требования:
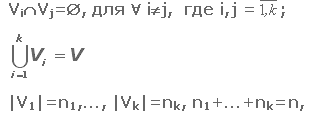 |
(1.1) |
Сечением разбиения C(V1,…,Vk) будем называть совокупность ребер, соединяющих вершины, которые принадлежат разным подграфам.
В качестве критерия оптимальности Q, определяющего эффективность биразбиения (бисекции) (V1,…,Vk) будем рассматривать вес сечения - сумма всех ребер сечения:
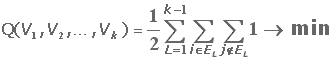 |
(1.2) |
В этом случае оптимальным k-разбиением является
решение (V1*,…,Vk*) экстремальной задачи (1.2), то есть разбиение
(V1*,…,Vk*) с минимальным весом сечения C(V1*,…,Vk*).
Частным случаем задачи k-разбиения является задача
(1.1) бисекции графа – когда граф разбивается на два подграфа (k=2). В
этом случае решение задачи разбиения графа (V1,V2) будем называть
бисекцией.
Система требований (1.2), предъявленных к
разбиению (V1,…,Vk), определяет область поиска D задачи разбиения
графа. Данная задача относится к задачам переборного типа и общее
число допустимых решений |D| можно вычислить из выражения:
 |
(1.3) |
где t – общее число подграфов, имеющих одинаковые размерности [4].
ОБЗОР АЛГОРИТМОВ РАЗБИЕНИЯ ГРАФОВ
Среди наиболее известных алгоритмов разбиения
графов можно выделить алгоритмы:
- алгоритм Kernighan-Lin / Fiduccia-Mattheyses (KL/FM);
- уровневое ячеечное разбиение;
- многоуровневые схемы;
- алгоритм спектральной бисекции.
Kernighan-Lin алгоритм (KL) разработан в 60-х
годах прошлого столетия. Алгоритм используется для улучшения
начального (возможно случайного) разбиения графа, путем обмена
вершинами из начальных наборов с целью уменьшения числа разрезающих
ребер. KL алгоритм основан на понятии веса - величины, которая
определяет выигрыш от перемещения вершины из одного подмножества в
другое. Вес рассчитывается для каждой вершины как количество
соединений вершины с другим подмножеством, минус количество соединений
с подмножеством, в котором вершина находится. Пока есть вершины с
положительным весом, алгоритм меняет вершины с максимальным весом
местами с вершинами из другого подмножества.
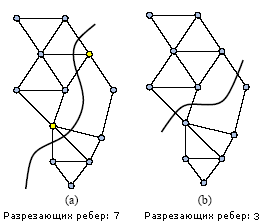 |
Шаг KL
- алгоритма |
Недостатком данного подхода является то, что
перемещения вершин могут привести к локальному минимуму. Для
преодоления локальных минимумов, алгоритм использует поиск экстремума
– вершины с отрицательным весом перемещаются, с целью нахождения более
глобального минимума. Причем, если вершина уже была перемещена, то она
не участвует в дальнейшем просмотре. Во время этих перемещений
алгоритм запоминает лучшее полученное разбиение. Когда перемещения
закончены алгоритм восстанавливает это наилучшее разбиение. Этот
процесс может повторяться, используя новое разбиение как стартовую
точку [5].
Fiduccia and Mattheyses предложили модификацию KL
алгоритма . FM алгоритм основан на KL-алгоритме, но за один его шаг
перемещается только одна вершина, после этого для каждой вершины
пересчитывается вес. Затем для каждого подмножества строится очередь
вершин. Вершины помещаются в нее по убывания веса. Просмотр вершин
происходит в том порядке, в котором вершины расположены в очереди.
Если условия балансировки нарушается, вершина не может быть
перенесена. При перемещении вершины в другой набор она удаляется из
очереди. При пересчете весов всех вершин очереди строятся заново.
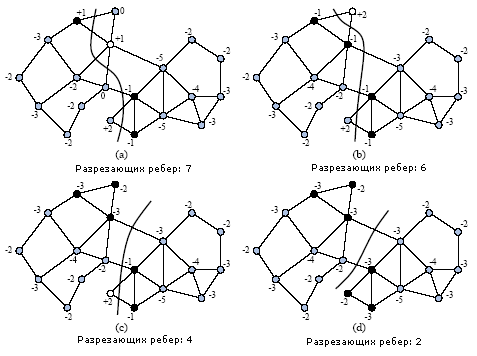 |
Шаги KL/FM-алгоритма
Белым помечена вершина, которая перемещается, черным - очереди
вершин |
Уровневое ячеечное разбиение. Обычно разбиение
будет иметь мало разрезающих ребер, если смежные вершины находятся в
одном подмножестве. Уровневое ячеечное разбиение (Levelized Nested
Dissection - LND) пытается помещать связанные вершины вместе,
начинаясь с подмножества, которое содержит только одну вершину и затем
увеличивает подмножество путем добавления смежных вершин. Подробнее,
алгоритм заключается в следующем: выбирается начальная вершина и
помечается номером 0. Потом все смежные с ней вершины помечаются
номером 1. Затем всем вершинам, которые еще не помечены и связанным с
уже помеченным номером вершинам назначается этот номер, увеличенный на
1 и т. д. Этот процесс продолжается пока половине вершин не будет
назначен номер. Помеченные вершины образуют одно подмножество, а
непомеченные вершины - другое.
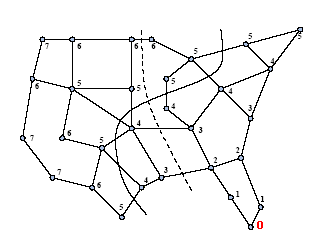 |
Сплошной линией показано
разбиение, полученное LND-алгоритмом.
Пунктирная линия показывает разбиение более
высокого качества |
К недостатку данного алгоритма можно отнести то
что полученное таким образом разбиение сильно зависит от начальной
выбранной вершины. Поэтому можно сделать вывод, что данный алгоритм
должен быть дополнен методами отыскания начальной вершины.
Многоуровневые схемы. Недавно был разработан новый
класс алгоритмов разбиения, который основывается на многоуровневом
подходе. Алгоритм состоит из трех фаз: стадия укрупнения, стадия
разбиения, стадия многоуровневого улучшения .
На стадии укрупнения графа формируется
последовательность графов, каждый из которых получается из
предыдущего, путем объединения смежных вершин, пока не получится
наименьший граф. Затем производится начальное разбиение наименьшего
графа. После этого разбиение улучшается на графе каждого уровня
начиная с минимального и заканчивая исходным графом (для этого может
использоваться KL/FM алгоритм, алгоритм спектральной бисекции).
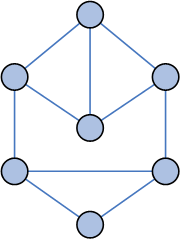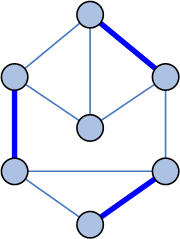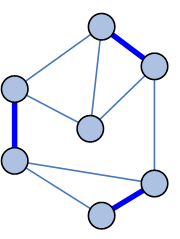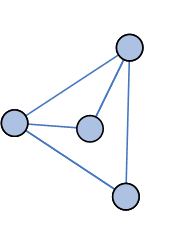 |
Анимаця показывает
один шаг стадии укрупнения |
Многоуровневые алгоритмы эффективны по двум
причинам. Во-первых, алгоритм позволяет скрыть большое количество
ребер на укрупненном графе. Во-вторых, KL/FM метод работает более
эффективно при многоуровневой схеме.
Перемещение одной вершины в укрупненном графе эквивалентно перемещению
большого числа вершин исходного графа. Перемещение группы вершин
позволяет избежать некоторых видов локальных минимумов.
Алгоритм спектральной бисекции [1]. Алгоритм
спектральной бисекции основан на использовании собственных векторов и
чисел. Этот метод получил большое внимание, так как дает хорошее
соотношение между универсальностью, качеством и эффективностью.
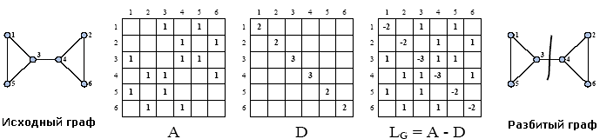
Разбиение графа методом спектральной бисекции
По этому алгоритму в соответствии каждой вершине
графа ставится переменная x, равная +1 или –1, таким образом, что
сумма всех x-ов равна 0. Первое условие подразумевает разбиение на два
различных набора. Второе требует чтобы наборы были равного размера,
учитывая четность исходного количества. Назовем вектор x
вектор-индикатор, т.к. он показывает принадлежность каждой вершины к
набору.
Затем определяется функция от x, определяющая
число граней, пересекающихся между наборами. Теперь, когда имеется
функция для минимизации, преобразуем ее к матричной форме, используя
матрицу Лапласа L.
| Минимизировать |
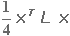 |
(2.1) |
| При условии: |
 |
Так как разбиение графа - NP-трудная задача,
необходимо ослабить ограничения дискретности на x и сформулировать
новую непрерывную задачу. Эта непрерывная задача - только приближение к
дискретной, и значения, определяющие ее решение, должны быть
отображены назад к ±1 в соответствии с некоторой соответствующей
схемой. Идеально, когда решение близко к ±1 .
| Минимизировать |
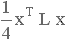 |
(2.1) |
| При условии: |
 |
Если U1, U2 …- нормализованные собственные векторы
L с соответствующими собственными значениями λ1 < =λ2 <= λ3…., то
матрица L имеет следующие свойства:
(I) L симметрична.
(II) Ui попарно ортогональны.
(III) U1=n-0.51, λ1=0
(IV) Если граф замкнутый, то только λ1 принимает нулевое значение.
Затем выразим Х в терминах собственных векторов L:
x=ΣαiUi, где αi – вещественные
константы, такие, что Σ(αi)2 =n . Свойство (II)
гарантирует, что это всегда возможно. Заменой для x мы получаем
функцию, для минимизации, зависящую от собственного значения матрицы
Лапласа λ2.
f (x)=0.25(α22 λ2+ α32
λ3 +…+ αn2 λn) начиная с λ1=0.
Очевидно
(α22 + α32 +…+ αn2
) λ2 <= (α22 λ2+ α32
λ3 +…+ αn2 λn) учитывая
упорядоченность собственных величин f(x)>=n λ2/4.
Мы можем минимизировать f(x)=n λ2/4,
выбирая 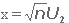 .
.
Полученный вектор x – решение непрерывной задачи.
Остается решить задачу отображения вектора x к дискретному разделению.
Для этого находится медиана значений xi, и затем отображается вершины
выше значения медианы в один набор, ниже в другой. Если несколько
вершин имеют значение медианы, то они распределяются, не нарушая
равновесия. Это решение - самая близкая дискретная точка к
непрерывному оптимуму.
ИССЛЕДОВАНИЕ МЕТОДОВ ОРГАНИЗАЦИИ ДАННЫХ
Как уже говорилось, при реализации алгоритма
встает задача выбора типа данных для представления информации о графе.
Задание графов с помощью матриц удобно для
алгоритмов, использующие матричные вычисления (например, алгоритм
спектральной бисекции). Однако, при обработке графа большой
размерности (n=1000, 10000), матрицы занимают слишком много памяти.
Следует учесть, что матрицы графов потоков данных довольно разрежены,
т. е. матрицы содержат много нулей.
Рассмотрим следующие представления матрицы при
программной реализации алгоритма:
- двумерный массив;
- массив динамических массивов (первый элемент динамического массива –
число ненулевых элементов в строке матрицы);
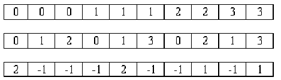
- три массива: массив ненулевых элементов матрицы, массивы индексов
строк и столбцов, соответствующих этим элементам;
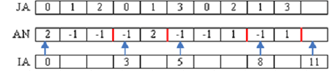
- матрица в формате RR(C)O. Сокращенное название данного формата
происходит от английского словосочетания "Row - wise Representation
Complete and Ordered" (строчное представление, полное и упорядоченное)
[6].
|
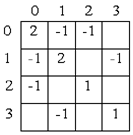
а) |
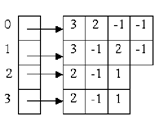
б) |
|
в) |
|
г) |
|
Рисунок – Способы представления матрицы; а) двумерный массив; б) массив динамических массивов; в) три массива; г) матрица в формате RR(C)O
|
Для примера рассмотрим матрицу
Лапласа, которая используется в алгоритме спектральной бисекции.
Представляя матрицу Лапласа двумерным массивом мы
занимаем единиц памяти. Массив динамических массивов занимает 2n+m
единиц памяти, где – число ребер графа.
Найдем, при каких значениях m выгоднее использовать вторую структуру
(когда она занимает меньше памяти):
2n +m<=n2
m<=n2-2n
Рассмотрим программную реализацию этих способов
представления матриц
| BYTE *m_matrix; double *m_LaplasMatrix;
m_matrix = (BYTE*)LocalAlloc(LPTR, m_vertixes*m_vertixes);
m_LaplasMatrix = (double*)LocalAlloc(LPTR, m_vertixes*m_vertixes*sizeof(double)); |
На рисунке показана реализация двумерного
массива на языке C++. Переменная m_matrix содержит указатель на
двумерный массив, содержащий матрицу смежности для графа, m_vertixes
задает число вершин графа, m_LaplasMatrix - указатель на двумерный
массив, содержащий матрицу Лапласа. Объем занимаемой памяти –
(m_vertixes)2·1 байт + (m_vertixes)2·8
байтов=(m_vertixes)2·9 байтов
(1 байт – размер типа BYTE, 8 байтов – размер типа
данных double).
|
WORD **m_lists;
double **m_LLists;
m_lists = (WORD**)malloc(m_vertixes*sizeof(WORD*));
for(int i=0; i<m_vertixes; i++){
int k=0;
for(int j=0; j<m_vertixes; j++){
if(isEdge(i, j)) k++;
}
m_lists[i] = (WORD*)LocalAlloc(LPTR, (k+1)*sizeof(WORD));
}
m_LLists = (double**)malloc(m_vertixes*sizeof(double*));
for(int i=0; i<m_vertixes; i++){
m_LLists[i] =
(double*)LocalAlloc(LPTR, (m_lists[i][0])*sizeof(double));
} |
На рисунке показана реализация массива динамических массивов на языке C++. Переменная m_mlists содержит указатель на массив указателей. Каждый из m_mlists[i] – указатель на динамический массив, содержащий список смежности для графа. Первый элемент каждого динамического массива содержит число смежных вершин - k. Функция isEdge(i, j) определяет, есть ли ребро между i-ой и j-ой вершинами.
Переменная m_LLists содержит указатель на массив указателей. Каждый из m_LLists[i] – указатель на динамический массив, содержащий ненулевые элементы матрицы. Объем занимаемой памяти :
(4 байта + 2 байта)·m_vertixes+2 байта · m_edges+4 байта·m_vertixes +8 байтов·m_edges
= (22 m_vertixes+10 m_edges) байтов
где m_edges – число ребер графа;
4 байта – размер указателя;
2 байта – размер типа данных WORD;
8 байтов – размер типа данных double
Рассмотрим когда массив динамических массивов занимает меньше памяти чем двумерный массив:
| 22 m_vertixes+10 m_edges<=9 m_vertixes2;
m_edges<0.9m_vertixes2-2.2m_vertixes |
(3.1) |
Представляя матрицу тремя массивами мы занимаем
6m+n единиц памяти, где m<=n2 – число ребер графа. Найдем,
при каких значениях m выгоднее использовать данную структуру:
6m+3n<=n2;
m<=(n2-3n)/6
Рассмотрим программную реализацию данного способа. Списки индексов строк и столбцов (m_rows и m_cols) представляются массивами типа DWORD (4 байта), список ненулевых элементов m_laplasItems представляется массивом типа double (8 байтов). Объем занимаемой памяти :
(2·4 байта+ 8 байтов)·(3 m_vertixes+6 m_edges)=(48m_vertixes+96m_edges)
байтов
где m_edges – число ребер графа, m_vertixes – число вершин
Рассмотрим когда три массива занимают меньше
памяти чем двумерный массив:
|
48 m_vertixes +96m_edges<=9 m_vertixes2;
m_edges<0.0625 m_vertixes2-0.5 m_vertixes |
(3.2) |
В формате RR(C)O также, используются три
одномерных массива. Значения ненулевых элементов матрицы и
соответствующие им столбцовые индексы хранятся в этом формате по
строкам в двух массивах AN и JA. Массив указателей IA, используется
для ссылки на компоненты массивов AN и JA, с которых начинается
описание очередной строки. Последняя компонента массива IA содержит
указатель первой свободной компоненты в массивах AN и JA, т.е. равна
числу ненулевых элементов матрицы, увеличенному на единицу. Список
индексов столбцов (m_JA) и массив указателей IA представляются
массивами типа DWORD (4 байта), список ненулевых элементов m_AN
представляется массивом типа double (8 байтов). Объем занимаемой
памяти:
(4 байта + 8 байтов)·2 m_edges + 4 байта
·(m_vertixes+1)=
(24 m_edges + 4 m_vertixes + 4) байтов
где m_edges – число ребер графа, m_vertixes – число вершин.
Рассмотрим когда три массива занимают меньше памяти чем двумерный
массив:
|
24 m_edges + 4 m_vertixes + 4<=9 m_vertixes2;
m_edges<(9 m_vertixes2-4 m_vertixes+4)/24 |
(3.3) |
В качестве предварительного исследования
определялось время умножения матрицы на вектор, так как эта операция
является основной во многих алгоритмах разбиения. На
следующих рисунках приведены диаграммы зависимости времени
умножения матриц от степени разреженности матрицы для матриц
размерностью 10×10, 100×100 и 1000×1000 соответственно. Для вычисления
каждой точки графика задавалась размерность матрицы, число ненулевых
элементов. По этим данным случайным образом создавалось 10 матриц.
Каждая матрица умножалась на вектор 1000 раз. Для построения диаграммы
бралось среднее время умножения всех этих матриц на вектор. Вычисления
проводились на компьютере с процессором Intel Celeron с тактовой
частотой 2,93 GHz и оперативной памятью 1GB.
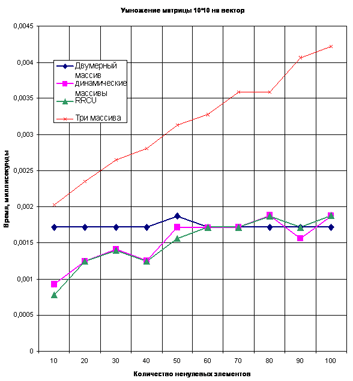
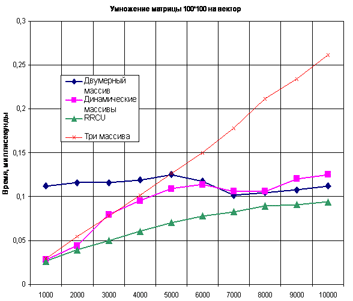
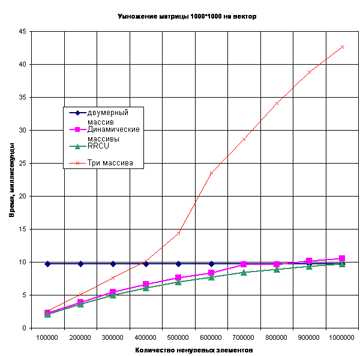
Как видно, степень разреженности матрицы мало влияет на скорость умножения, когда матрица задана двумерным массивом. При реализации матрицы с помощью массива динамических массивов, трех массивов и в формате RR(C)O видно, что с чем больше число ненулевых элементов в матрице, тем больше время умножения. Причем до определенного значения это время меньше соответствующего для двумерного массива (для матрицы, заданной динамическими массивами и в формате RR(C)O). Для матрицы, заданной тремя массивами это не выполняется. Время ее умножения на вектор больше времени умножения двумерного массива при любой степени разреженности матрицы.
Рассмотрим матрицу, задаваемую динамическими массивами. Для такой матрицы 10×10 это значение – приблизительно 65 ненулевых элементов, для матрицы 100×100 – 650, для матрицы 1000×1000 – 7000. То есть можно сказать что при количестве нулевых элементов больше 35% использование массива динамических массивов является более оптимальным по времени. Рассмотрим матрицу в формате RR(C)O. Для такой матрицы 10×10 это значение – приблизительно 65 ненулевых элементов, для матриц 100×100 и 1000×1000 время умножения на вектор меньше времени умножения двумерного массива при любом количестве ненулевых элементов. То есть можно сказать что при графах больших размерностей использование формата RR(C)O предпочтительнее двумерного массива и массива динамических массивов
При написании реферата
магистерская работа еще не завершена. Окончательное завершение -
январь 2007г. Полный текст работы и все материалы по теме могут быть
получены у автора или его руководителя после указанной даты.
ПЕРЕЧЕНЬ
ССЫЛОК
-
Bruce Hendrickson, Robert Leland.
Multidimensional Spectral Load Balancing. Sandia National
Laboratories Albuquerque, 1993
hendrickson93multidimensional.pdf
(204 Kb)
http://citeseer.csail.mit.edu/hendrickson93multidimensional.html
-
Bradford L. Chamberlain. Graph
Partitioning Algorithms for DistributingWorkloads of Parallel
Computations, 1998
generals.pdf
(340 Kb)
http://www.cs.washington.edu/homes/brad/cv/pubs/degree/generals.html
-
Графы.AGraph: библиотека классов для работы с помеченными графами.
http://www.caravan.ru/~alexch/AGraph
-
Д. И. Батищев, Н. В. Старостиным. Методические
указания по проведению лабораторных работ «задачи декомпозиции
графов» по курсу «Эволюционно-генетические алгоритмы решения
оптимизационных задач» для студентов факультета ВМК специальности
«Прикладная информатика». Нижегородский государственный университет,
2001
www.unn.ru/rus/books/met_files/Met_graph.doc
-
Kirk Schloegel, George Karypis, Vipin Kumar. Graph
Partitioning for High Performance Scientific
Simulations.University of Minnesota, Department of Computer
Science, Minneapolis, 2000
http://citeseer.ist.psu.edu/schloegel00graph.html
-
Представление разреженных матриц.
Быстрицкий В.Д.
http://alglib.sources.ru/articles/zeromatr.php.
Действия
над разреженными матрицами
http://alglib.sources.ru/sparse/.



