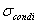 (R), где condi является условием. Таким образом, восстановаить начальное отношение можно объединив следующие фрагменты:
(R), где condi является условием. Таким образом, восстановаить начальное отношение можно объединив следующие фрагменты: Краткий обзор.Процесс выполнения запросов в распределенных базах данных требует точных оценок и прогнозов для повышения характеристик системы. Для решения задачи распределения данных и оптимизации запросов рассматриваются мобильные агенты и эволюционный алгоритм. Данная проблема до сих пор является нерешенной вследствие динамических изменений числа компонент и архитектурной сложности топологий в современных системах. Распределенные системы моделируются в виде структуры графа, в которой определен вектор динамических затрат. Вектор затрат формируется с использование мобильных агентов, определяющих статистические затраты и вектор обновлений. Для перераспределения данных предложено использовать эволюционный метод. Экспериментальные результаты доказывают эффективность предложенного метода.
Ключевые слова: распределенная база данных, фрагментация данных, распределение данных, эволюционные вычисления, мобильные агенты.
Необходимость распределенных баз данных возникает в связи с расширением компьютерных сетей и в связи с тем, что предприятия и организации в ходе своей работы выполняют географически распределенные операции. Международные компании хранят свои данные на различных узлах компьютерной сети, возможно в различной форме от сплошных файлов до иерархических, реляционных, объектно-ориентированных баз данных. Сама компьютерная сеть имеет разнообразные средства передачи данных, сетевые топологии и сетевые скорости. При выборе подхода к созданию распределенных баз данных необходимо предусмотреть различные факторы, влияющие на работу системы: скорость работы центрального процессора, время передачи данных, время, необходимое для записи/чтения данных с диска. При построении таких распределенных систем возникают некоторые проблемы в управлении данными. Система должна быть высоко масштабируемой без возникновения критических точек отказа. В соответствии с сегодняшними требованиями к компьютерным вычислениям, временная задержка не должна оказывать влияние на работу приложения в режиме реального времени. Главной целью при создании таких систем является обеспечение равномерного доступа к физически распределенным данным, несмотря на расстояние между местом, где возникает запрос на доступ к данным, и местом расположения данных. Возможным решением является представление распределенной базы данных в виде графа и выполнение управления системой автоматически, используя специальных агентов. Предлагается решить задачу ре-фрагментации и перераспределения данных с помощью эволюционного алгоритма.
Система управления распределенными базами данных [8] должна обеспечить выполнение как локальных приложений вычислительных составляющих, так и глобальные приложения на более вычислительных машинах; система также должна обеспечить язык запросов высокого уровня с возможностью осуществления распределенных запросов для выполнения распределенного приложения. Должны быть обеспечены уровни прозрачности. Для улучшения выполнения глобальных запросов, данные могут быть разделены на части и распространены по компонентам системы. Системы распределенных баз данных поддерживают фрагментацию данных в том случае, если отношение, сохраненное внутри системы, может быть разделено на части, называемые фрагментами. Эти фрагменты могут храниться на различных узлах, которые расположены на одной или разных машинах. Цель состоит в том, чтобы сохранить фрагменты в том месте, где они наиболее часто используются для улучшения работы системы. Могут быть созданы фрагменты горизонтальные, вертикальные и смешанные (комбинация горизонтальной и вертикальной фрагментации).
Пусть R[A1,A2,...,An] - отношения, где Ai, i=1,...,n - атрибуты . Горизонтальный фрагмент можно получить, наложив ограничение: Ri = (R), где condi является условием. Таким образом, восстановаить начальное отношение можно объединив следующие фрагменты:
R = R1 U R2 U . . . U Rk.
Вертикальный фрагмент можно получить операцией проектрования:
Ri=  (R),
(R),
{Ax1,Ax2,...,Axn}
где Axi, i=1,...,p - атрибуты. Начальное отношение может быть восстановлено объединением фрагментов следующим образом:
R=R1 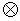 R2 . . . Rl.
R2 . . . Rl.
Распределенная база данных может быть представлена [5] в виде графа, где узлы обозначены как (V), и представляют собой набор вершин, и грани (E) показывают непосредственное соединение между узлами. Каждая грань имеет соответствующие затраты, но эти затраты будут рассмотрены позже в этом документе. Для примера рассмотрим на Рисунке 1 распределенную систему и получим на Рисунке 2 соответствующее представление этой же системы в виде графа.

Рисунок1. Система распределенной базы данных.

Рисунок 2. Соответствующий граф системы на рисунке 1.
Система должна сохранять независимость распределенных данных таким образом, что изменения в физическом расположении данных не нарушали функциональности приложения. При хорошем управлении распределенной базой данных можно выделить две фазы: первая фаза проектирования распределенной базы данных требует значительных усилий, а вторая фаза подразумевает стадию ре-конфигурации для регулирования работы системы. Одним из вопросов на стадии проектирования является задача представления фрагментации и распределения данных. Значительные улучшения в работе системы могут быть также достигнуты за счет осуществления фрагментации и распределения данных на стадии усовершенствования. Использование специальных агентов может принести большую пользу работе системы из-за того, что агенты программного обеспечения могут действовать автономно от имени администратора сети. Элементы системы не требуют постоянного соединения, агенты могут перемещаться по компьютерной сети и выполняться на различных хостах. Агенты могут быть «умными», принимать решения и реагировать на изменения окружающей среды, и самое главное, могут сотрудничать для выполнения своих общих целей.
Далее предложено построение системы распределенной базы данных, где предложено для улучшения управления системой использовать агентов. Рассмотренная архитектура обеспечивает высокую масштабируемость системы и оптимизацию ее работы. Усовершенствование работы осуществляется на основании определения затрат между узлами:
Во-первых, определяются начальные затраты; эти затраты определяются на основании сетевой скорости передачи данных, требуемого времени доступа к данным и вычислительным возможностям узла. Назовем их начальные оценочные затраты.
Во-вторых, в некоторый момент времени можно получить более точные затраты системы; назовем их обновленные вычисленные затраты.
Агент трансляции выполняет трансляцию локальных имен в глобальные имена и обеспечивает общий язык распределенных запросов ,гарантируя независимость локальной системы управления базами данных.
Агент поиска информации собирает данные с соответствующих фрагментов, связываясь с Транслятором. Фактически они строят запрос на общем языке агентов.
Оптимизатор может быть одним для целой системы или может быть клонирован; он содержит оптимизатор запросов. Одно из назначений Оптимизатора – получить обновленные вычисленные затраты на основании статистики от сайтов, которая касается количества обращений к данным на конкретном узле.
Задача фрагментации базы данных и распределения данных смоделирована в виде графа. Необходимо распределить m кортежей по n узлам графа при заданном значении затрат между вершинами графа. Также заданной является статистика по частоте обращений к кортежам в графе (эта частота определяется агентами). Задачу распределение кортежей можно свести к оптимизационной задаче, целью которой является минимизация затрат при генерации запросов в графе. Для решения задачи предлагается использовать эволюционный алгоритм [6]. Предложенный алгоритм называется эволюционный алгоритм фрагментации и распределения в распределенной базе данных.
В предложенном алгоритме используется популяция фиксированного размера. Необходимо распределить m кортежей по узлам, которые обозначим t1, t2,..., tm. Ограничений на максимальное или минимальное число кортежей, хранимых на одном узле, не устанавливается. Потенциальное решение задачи (хромосома) представляет собой строку фиксированной длины {x1, x2,...,xm}, где гены xi, xi 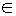 {1, 2,..., n},обозначают на каком узле расположен i-ый кортеж.
{1, 2,..., n},обозначают на каком узле расположен i-ый кортеж.
Потенциальное решение оценивается на основании реального значения фитнесс - функции F, F : X ->R, где X определяет область потенциального решения. Фитнесс функция хромосомы учитывает затраты граней между вершинами (узлами) и статистику относительно частоты запросов кортежей в графе:
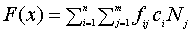 ,
,
где fij, i {1,2,...,n}, j {1,2,...,m}, представляет собой частоту обращений к кортежу j с узла i графа. Также, ciNj, i {1,2,...,n}, j {1,2,...,m},, представляет собой затраты граней между узлом i и узлом, содержащем кортеж j, который обозначен как Nj . Фитнесс - функция F должна быть минимизирована.
Для предложенного алгоритма [3] рассматривают разрядный отбор [4], двухточечный оператор кроссовера и слабый оператор мутации [1]. Лучшие из родителей и потомков входят в следующее поколение.[2].
Алгоритм заканчивается после определенного числа генераций, которые не улучшают лучшее значение популяции [7]. Лучшее решение, полученное в процессе поиска, рассматривается как решение задачи.
Рассмотрим граф, имеющий пять узлов (n = 5). Обозначим эти пять узлов следующим образом: N1, N2, N3, N4, N5. Соответствующие затраты для граней между заданными узлами изображены на Рисунке 4. Замечание: Нас интересует только непосредственные затраты между двумя узлами, и поэтому существуют узлы без граней между ними, даже если между ними существует путь с использованием промежуточного узла.
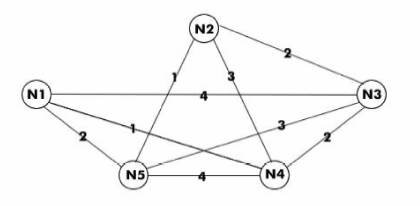
Рисунок 3.Предложенное построение.
Задан набор данных 1.200.000 кортежей. Данные кортежи обозначим как t1, t2,..., tm., где m представляет собой количество кортежей. Существующая фрагментация набора данных и распределение кортежей по узлам изображены в Таблице1.
Таблица 1. Фрагментация и распределение набора данных кортежей по узлам.
| Узел | Фрагментация набора данных | Количество кортежей/узлов |
| N1 | t1-t100.000 | 100.000 |
| N2 | t100.001-t380.000 | 280.000 |
| N3 | t380.001-t540.000 | 160.000 |
| N4 | t540.001-t720.000 | 180.000 |
| N5 | t720.001-t200.000 | 480.000 |
Статистика относительно частоты обращений к кортежам с каждого узла представлена в Таблицах 2 - 6.
Таблица 2. Частота Обращений к кортежа с узла N1.
| Кортежи | Частота |
| t40.001-t90.000 | 4 |
| t420.001-t560.000 | 10 |
| t610.001-t730.000 | 12 |
| t980.001-t1.100.000 | 5 |
Таблица 3. Частота Обращений к кортежа с узла N2.
| Кортежи | Частота |
| t250.001-t330.000 | 2 |
| t560.001-t680.000 | 14 |
| t1.100.001-t1.200.000 | 7 |
Таблица 4. Частота Обращений к кортежа с узла N3.
| Кортежи | Частота |
| t1-t100.000 | 3 |
| t250.001-t290.000 | 10 |
| t880.001-t970.000 | 9 |
| t990.001-t1.000.000 | 16 |
Кортежи, которые не появляются в таблицах, содержащих частоту запросов, никогда не запрашиваются. Они останутся внутри узлов, которые содержали их до применения эволюционного алгоритма фрагментации и рспределения. Предложенный алгоритм применялся для данных, описанных выше в таблицах. Выбранные значения параметров алгоритма описаны в Таблице 7.
Таблица 5. Частота Обращений к кортежа с узла N4.
| Кортежи | Частота |
| t100.001-t170.000 | 3 |
| t220.001-t330.000 | 7 |
| t450.001-t560.000 | 13 |
| t680.001-t770.000 | 8 |
Таблица 6. Частота Обращений к кортежа с узла N5.
| Кортежи | Частота |
| t200.001-t260.000 | 12 |
| t700.001-t830.000 | 6 |
| t920.001-t980.000 | 1 |
Table 7. Параметры эволюционного алгоритма фрагментации и распределения.
| Размер популяции | Числогенераций, которые не улучшают текущее решение | Вероятность рекомбинации | Вероятность мутации |
| 200 | 50 | 0.7 | 0.1 |
После выполнения эволюционного алгоритма, кортежи перераспределяются между узлами графа, учитывая частоту обращений к кортежам. Путь перераспределения кортежей описан в таблице 8.
В эволюционном алгоритме, который называется эволюционный алгоритм фрагментации и распределения, предложена стадия ре-конфигурации, подразумевающая ре-фрагментацию и перераспределения данных в распределенной системе. Предложенный алгоритм был успешно применен и экспериментальные результаты доказали его эффективность.
В будущей работе, метод может быть улучшен за счет вычисления весовых затрат и определения факторов, таких как необходимость репликации данных, важность реального времени ответа (некоторые приложения не требуют реального времени ответа), частота обращений к данным (некоторые данные могут запрашиваться раз в месяц).
Вес факторов в вычислении затрат может меняться со временем, также изменения в сетевой топологии или средствах передачи данных могут повлиять на время ответа. Полезно использовать статистику для пересчета затрат, чтобы получить лучшее время ответа для всех запросов на любой узел.
Таблица 8. Перераспределение кортежей по узлам после применения эволюционного алгоритма.
| Узел | Ре-фрагментированный набор данных | Число кортежей/узлов |
| N1 | t680.000-t770.000, t1.000.001-t1.100.000 | 190.000 |
| N2 | t170.001-t200.000, t250.00-t260.000, t330.001-t380.000, t560.001-t610.000, t770.001-t830.000, t970.001-t980.000, t1.100.001-t1.200.000 | 310.000 |
| N3 | t1-t40.000, t90.000-t100.000, t260.001-t330.000, t380.001-t420.000, t880.000-t970.000, t990.001-t1.000.000 | 260.000 |
| N4 | t40.001-t90.000, t100.001-t170.000, t420.001-t560.000, t980.001-t990.000 | 270.000 |
| N5 | t200.001-t250.000, t610.001-t680.000, t830.001-t880.000 | 170.000 |
[1] Bдck, T., Fogel, D.B., Michalewicz, Z. (Editors), Handbook of Evolutionary Computation, Institute of Physics Publishing, Bristol and Oxford University Press, New York, 1997.
[2] Bдck, T., Optimal mutation rates in genetic search, Proceedings of the 5th International Conference On Genetic Algorithms, Ed. S. Forrest, Morgan Kaufmann, San Mateo, CA, 2-8, 1993.
[3] Dumitrescu, D., Lazzerini, B., Jain, L.C, Dumitrescu, A., Evolutionary Computation, CRC Press, Boca Raton, FL., 2000.
[4] Goldberg, D.E., Deb, K., A comparative analysis of selection schemes used in genetic algorithms, Foundations of Genetic Algorithms G.J.E. Rawlins (Ed.), Morgan Kaufmann, San Mateo, CA, 69-93, 1991.
[5] Moldovan, G., Reorganization of a Distributed Database, Babes-Bolyai University, Seminar of Models, Structures and Information Processing, Preprint nr. 5, p. 3-10, 1984.
[6] Levin, K. D., Morgan, H. L., Optimizing distributed databases-A framework for research, Proceedings of AFZPS NCC, vol. 44. AFIPS Press, pp. 473-478, 1975.
[7] Mitchell, M., An Introduction to Genetic Algorithms, MIT Press, Cambridge, MA, 1996.
[8] Oszu, M. T., Valduriez, P., Principles of Distributed Database Systems, Prentice Hall, Englewood Cli.s, NJ, 1999.
[9] Piattini, M. and Diaz, O., Advanced Database Technology and Design, Artech House, Inc. 685 Canton Street Norwood, MA 02062, 2000.
[10] Weiss, G., Multiagent System, A Modern Approach to Distributed Arti.cial Intelligence, MIT Press , USA, 2000.