|
Прогнозирование на предприятии является важным этапом процесса управления. Результаты этого этапа используются при выявлении наиболее предпочтительных альтернатив будущего состояния предприятия, а также путей их достижения. Они во многом обуславливают процесс планирования деятельности предприятия, как стратегического, так и оперативного. От эффективных прогнозов, таким образом, зависит результативность работы предприятия в целом.
В современных условиях прогнозирование сопряжено с большим количеством трудностей. Поэтому целью данной работы является разработка новых и эффективных методов повышения точности прогнозирования.
При осуществлении прогнозирования в экономической и социальной сферах часто используются регрессионные прогнозные модели. При применении регрессий становится более ясным воздействие отдельных факторов, благодаря чему можно лучше понять природу исследуемого явления. Именно способность регрессионного уравнения отобразить взаимосвязь между явлениями нашла себе практическое применение в прогностическом анализе.
Для достижения, поставленных целей необходимо решить следующие задачи:
- рассмотреть 3 метода повышения точности прогнозирования с использованием прогнозной модели на основе парной линейной регрессии и определить какими параметрами исходных статистических данных определяется выбор того или иного метода;
- найти параметры методов, которые позволяют максимизировать выигрыш от их применения.
Для нахождения оптимальных значений величин 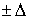 для первого, второго и третьего методов необходимо провести имитационное моделирование. Имитироваться должны различные геометрические места нахождения статистических данных. Необходимо построить регрессионные уравнения и путем вариации величин во всех методах, найти выигрыш в величине точности прогноза от значений . Выигрыш достигается за счет непопадания аномальных и неоднородных исходных дынных в определенную область. для первого, второго и третьего методов необходимо провести имитационное моделирование. Имитироваться должны различные геометрические места нахождения статистических данных. Необходимо построить регрессионные уравнения и путем вариации величин во всех методах, найти выигрыш в величине точности прогноза от значений . Выигрыш достигается за счет непопадания аномальных и неоднородных исходных дынных в определенную область.
Прогнозирование является очень важным для любой отрасли и применяется даже в спорте (прогнозирование исхода матчей в футболе, хоккее и т.д.). Поэтому проводилось и проводится много исследований связанных с прогнозированием, в т. ч. и магистрами ДонНТУ. Однако методы, которые будут рассмотрены в данной выпускной работе, являются новыми и ранее не использовались. Наиболее близкой к теме моей выпускной работы является выпускная работа магистра Щербак И. В. "Исследование метода повышения точности регрессионных прогнозных моделей". Однако в ней используется один метод, который не является полным аналогом ни одного из рассматриваемых мною методов.
Во всем мире выпущено много книг, посвященных прогнозированию. В Украине это, например, книга "Статистичне моделювання та прогнозування", автором которой является Ерина А. М. (Киевский национальный экономический университет). В данном учебном пособии рассматриваются методологические принципы статистического моделирования и прогнозирования социально-экономических явлений процессов, проверки гипотез и верификации прогнозов, также представлены различные модели динамики (трендовые, сезонные, полного цикла), комплексное их использование при прогнозировании, адаптация основных принципов регрессионного анализа к специфике объектов моделирования. Из книг, написанных в России хочется отметить книгу "Математические методы построения прогнозов", авторы Грешилов А. А., Стакун В. А., Стакун А. А. (Москва), в которой рассмотрены методы анализа динамических (временных) рядов и построения прогнозов, в том числе методы оценки параметров моделей и диагностической проверки моделей; методы оценки ошибки прогнозов и подправления прогнозов.
Также существует большое количество систем (программ) для прогнозирования. Основные из которых:
1) Система STATISTICA (www.statsoft.ru). Система STATISTICA производится компанией StatSoft Inc., основанной в 1984 г в городе Тулса (Оклахома, США). Компания StatSoft – лидер в разработке программ для анализа данных, визуализации, классификации и прогнозирования. Компания StatSoft Russia является российским представительством американской компании StatSoft. Пакет STATISTICA имеет более 350 тыс. зарегистрированных пользователей во всем мире и является наиболее динамично развивающимся пакетом на рынке статистического программного обеспечения. Имеются версии системы на немецком, французском, японском, испанском, польском и других языках. Пользователями системы являются крупнейшие университеты, исследовательские центры, компании, банки всего мира, государственные учреждения.
В модуле Временные ряды реализован широкий набор методов описания, построения моделей, декомпозиции и прогнозирования временных рядов как во временной, так и в частотной области.
В системе STATISTICA реализованы регрессионные методы анализа временных рядов для переменных с запаздыванием (лагом) или без него, в том числе - регрессия, проходящая через начало координат, нелинейная регрессия и интерактивное "что-если" прогнозирование.
2) Система Forecast Pro (www.forecastpro.com), разработанная компанией Business Forecast Systems, центральный офис которой находится в Белмонте, Массачусетс. Forecast Pro лидер на рынке среди программ прогнозирования. Forecast Pro легок в изучении и прост в использовании. В режиме эксперта, создание точных прогнозов очень просто. Пользователь предоставляет исторические данные и встроенная экспертная система анализируя эти данные, выбирает подходящую методику прогнозирования и производит прогноз. Система Forecast Pro, предназначена для статистического прогнозирования доходов, объема продаж, потребностей в услугах и других важных параметров. Пакет Forecast Pro поддерживает в числе прочих методы экспоненциального сглаживания, алгоритм Бокса-Дженкинса (ARIMA), алгоритм периодического спроса Кростона, модели малых объемов, событийные модели (для прогнозирования рекламных акций и перебоев в работе предприятия), а также многоуровневые (иерархические модели). Включена функция ручной и автоматической коррекции прогнозов. Также значительно улучшена логика экспертного отбора нужной модели прогнозирования.
3) Пакет СТАТПРО (www.icm.by/public/developments/p141/indexr.html) (Белорусский государственный университет) предназначен для статистического прогнозирования количественных и нечисловых показателей и имеет следующее возможности:
– анализ структуры данных, который позволяет выбрать адекватную модель для прогнозирования: выполняет заполнение пропущенных значений, полиномиальное и медианное сглаживание, фильтрацию, обнаружение "выбросов" и "разладок", исключение сезонности, обнаружение скрытых периодичностей, проверку наличия тренда;
– краткосрочное прогнозирование временных рядов методами экспоненциального сглаживания;
– прогнозирование нестационарных временных рядов на основе модели тренда из заданного класса параметрических функций;
– прогнозирование стационарных временных рядов на основе модели авторегрессии и скользящего среднего (APCC);
– параметрическое регрессионное прогнозирование на основе модели множественной линейной регрессии;
– непараметрическое регрессионное прогнозирование;
– прогнозирование состояний с применением модели логистической регрессии;
– прогнозирование с помощью моделей линейного и квадратичного дискриминантного анализа.
Ряд алгоритмов, реализованных в пакете, являются оригинальными научными разработками, выполненными на кафедре математического моделирования и анализа данных БГУ: байесовский подход к прогнозированию для трендовых моделей и модели авторегрессии, локально-медианный метод прогнозирования временных рядов с трендом, регуляризованный метод оценки коэффициентов регрессионных моделей, устойчивые (робастные) к искажениям данных методы прогнозирования.
4) Программа для прогнозирования, находящаяся на сайте http://forecasting.ikernel.org, осуществляет прогнозирование по временному ряду. Данный сервис позволяет строить прогнозы временных рядов, основанные либо на данных пользователя, либо основанные на имеющихся в открытых источниках финансовых данных в интерактивном онлайн-режиме. Сам процесс прогнозирования с точки зрения интерфейса пользователя максимально упрощен и позволяет строить прогнозы очень быстро — за несколько кликов мыши.
5) Программа Excel-прогноз (http://Excelprognoz.narod.ru) предназначена для прогнозирования сезонных продаж. Рассматриваются две сезонности (периодичности): годовая и недельная. Программа работает внутри электронной таблицы Excel, поэтому можно использовать все вычислительные и графические средства Excel.
Парная линейная регрессия – причинная модель статистической линейной связи между двумя количественными переменными х и у.
Модель парной линейной регрессии имеет вид: y=a+bx+ε
где
y – зависимая переменная (предиктор);
x – независимая переменная (регрессор);
a + bx – детерминированная составляющая;
ε – случайная составляющая (случайный остаток, возмущение), характеризующая отклонение от теоретической линии. Мε = 0, Dε = σ2;
a, b – параметры регрессии, которые должны быть определены по выборочным данным.
Параметр b показывает, на сколько единиц в среднем изменится зависимая переменная (например, выпуск продукции в стоимостном выражении), если независимая переменная (например, число занятых) увеличится на единицу.
Независимая переменная х – неслучайная величина, а зависимая переменная y – случайная величина, поскольку в нее входит случайная составляющая ε.
Поскольку изменение только одной независимой переменной х не может вобрать в себя все источники вариации зависимой переменной y, то случайная составляющая ε отражает совокупное влияние на зависимую переменную всех других (кроме х) факторов.
Можно сделать следующие предположения относительно возмущения ε:
1) Возмущение ε является случайной переменной;
2) математическое ожидание ε равно нулю;
3) дисперсия возмущений постоянна;
4) последовательные значения ε не зависят друг от друга.
При построении линейной парной регрессии принимается гипотеза о том, что для каждого наблюдения i справедлива следующая взаимосвязь: yi= a + bxi + ε
Математическое ожидание, дисперсия и ковариации возмущения εi имеют следующие значения: E(εi)=0;
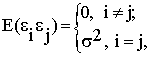
где i, j = 1, …, n – номер наблюдения; символ Е указывает на операцию определения математического ожидания, отсюда Е(εiεi) – дисперсия возмущения, Е(εiεj) – ковариация.
Необходимо определить параметры a и b. Однако истинные значения этих параметров получить нельзя, так как объем информации ограничен – выборка ограниченного объема, поэтому получаемые расчетные значения параметров являются статистическими оценками истинных параметров a и b. Обозначим соответствующие (выборочные) оценки как 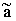 и и 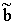 . .
Приняв некоторую гипотезу о форме кривой, описывающей взаимосвязь переменных у и х (например, простая линейная взаимосвязь) тем не менее не удается однозначно подобрать параметры уравнения, так как через область в которой расположены точки, соответствующие отдельным наблюдениям, можно провести множество прямых. Необходим некоторый критерий. В качестве такого критерия, естественно, принять требование о соотношении значений наблюдений и расчетных данных, т.к. существует стремление провести прямую в целом наиболее близко к данным наблюдения. Различные методы оценивания параметров опираются на различные критерии, измеряющие степень близости расчетных и фактических данных, и, соответственно дают разные значения оценок параметров для одной и той же совокупности наблюдений. Наиболее распространенным является метод наименьших квадратов (МНК). [1]
Для оценки применимости регрессионной прогнозной модели необходимо оценить модули величины коэффициента взаимной корреляции между регрессором Х и Y. Величина доверительного интервала прогнозирования является мерой качества прогноза по этой модели. В реальных производственных ситуациях из-за влияния неучтенных в прогнозной модели факторов ошибок измерений экономических характеристик, особенно при малых объемах выборки, точность прогноза получается достаточно низкой.
В данной работе, рассматриваются три метода повышения точности прогнозирования с использованием прогнозной модели на основе парной линейной регрессии.
Первый метод заключается в нахождении по исходным статистическим данным линейного регрессионного уравнения, параметры которого определяются с помощью метода наименьших квадратов, и смещении этого уравнения относительно исходного на величину . Т.о. получается коридор, в который не попадают неоднородные точки.
Постановка задачи: пусть имеются 20 точек, вероятность попадания регрессионных данных в интервал Р=0,8, 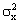 , , 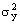 . .
Тогда, воспользовавшись первым методом, получаем, следующий рисунок (Рис. 1)
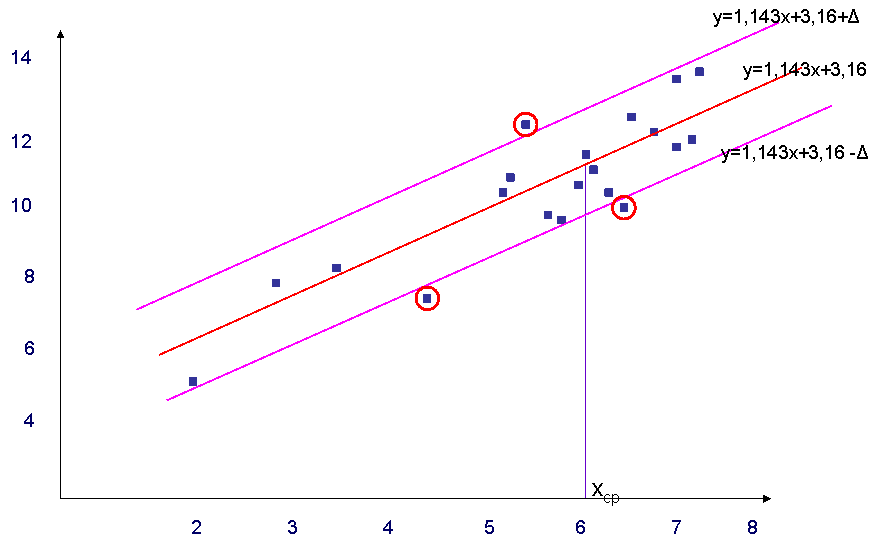
Рис.1 - Первый метод
Второй метод заключается в нахождении линейного регрессионного уравнения, величины среднего значения регрессора и восстановлении перпендикуляра в точке хср (среднее значение х) по найденному регрессионному уравнению. Далее строятся две прямые, смещенные на величину , параллельные построенному перпендикуляру. Для приведенного выше примера, получаем (Рис. 2)
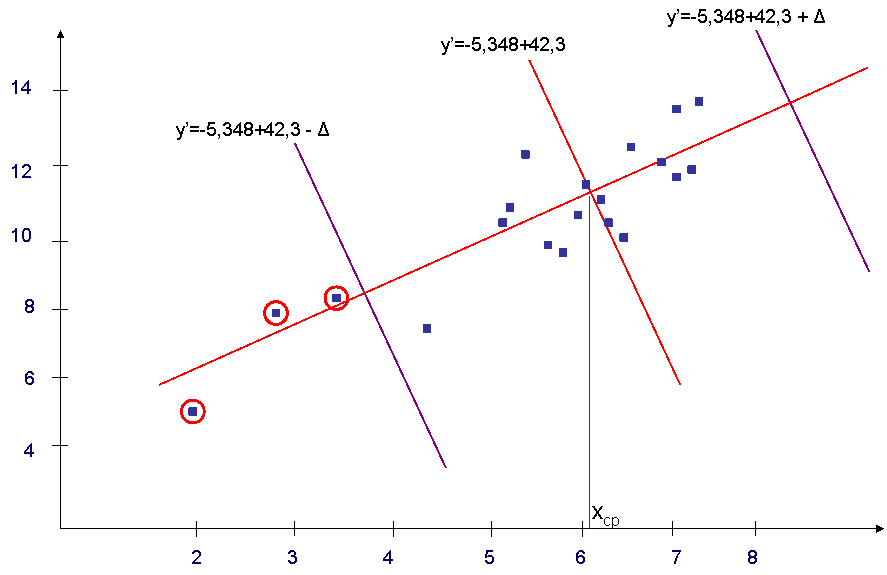
Рис.2 - Второй метод
Третий метод заключается в комбинации использования первых двух методов. Необходимо учесть что, чтобы общая вероятность попадания в прямоугольный коридор была равна 0,8, необходимо брать вероятности равные 0,89. Результат использования третьего метода представлен на рисунке 3.
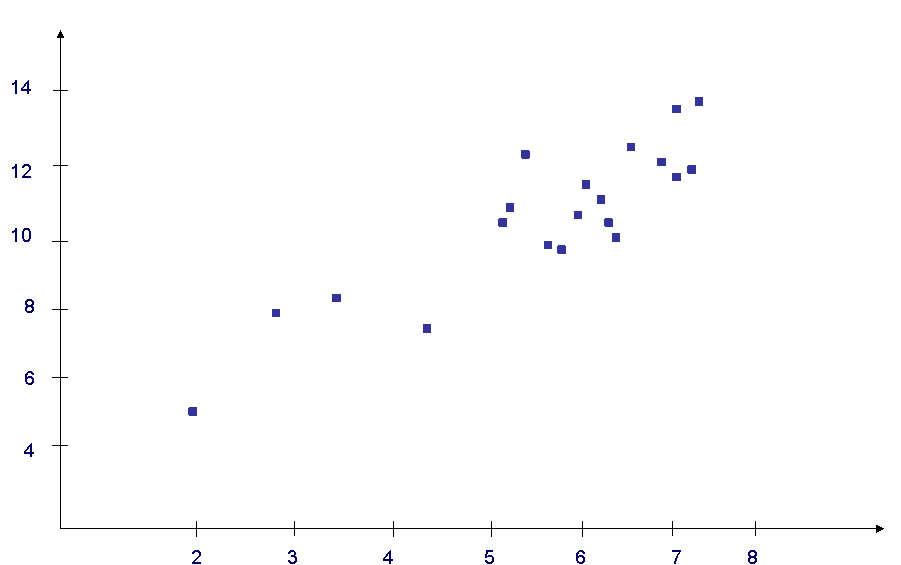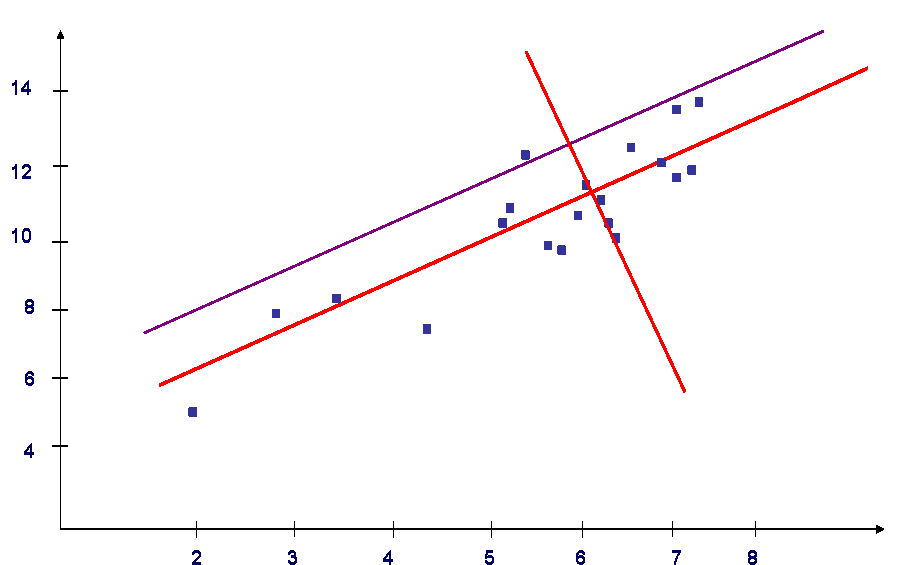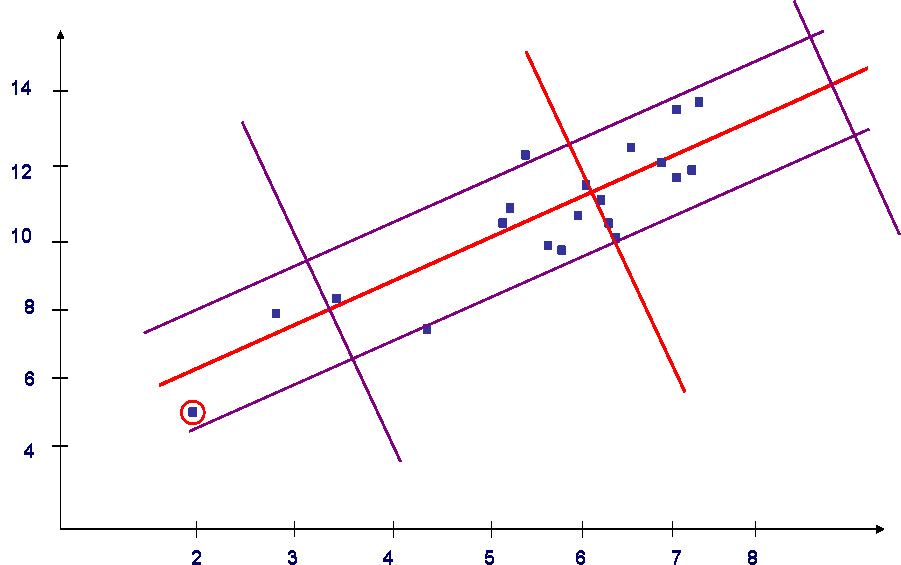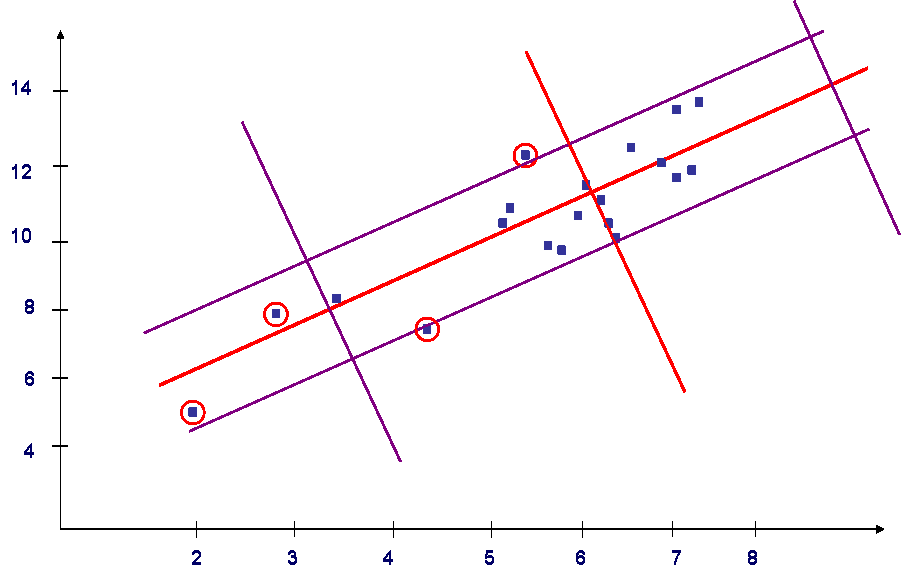
Рис.3 - Третий метод
(Анимированное изображение состоит из 11 кадров, 12 циклов повторения)
Критерием эффективности является коэффициент, который находится по формуле:
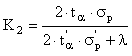
где
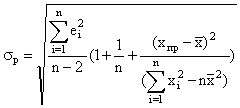
λ – величина смещения;
tα, tα'– доверительный интервал для исходных данных и данных после отбрасывания точек.
Величина смещения λ находится следующим образом. По исходному регрессионному уравнению находится в т. хпр (х прогнозное) находится значение упр. Далее после отбрасывания точек находится новое регрессионное уравнение. В это уравнение подставляется значение хпр и находится соответственно новое значение упр, а величина смещения будет равна абсолютному значению разности полученных величин упр.
Графически это можно представить следующим образом (Рис. 4):
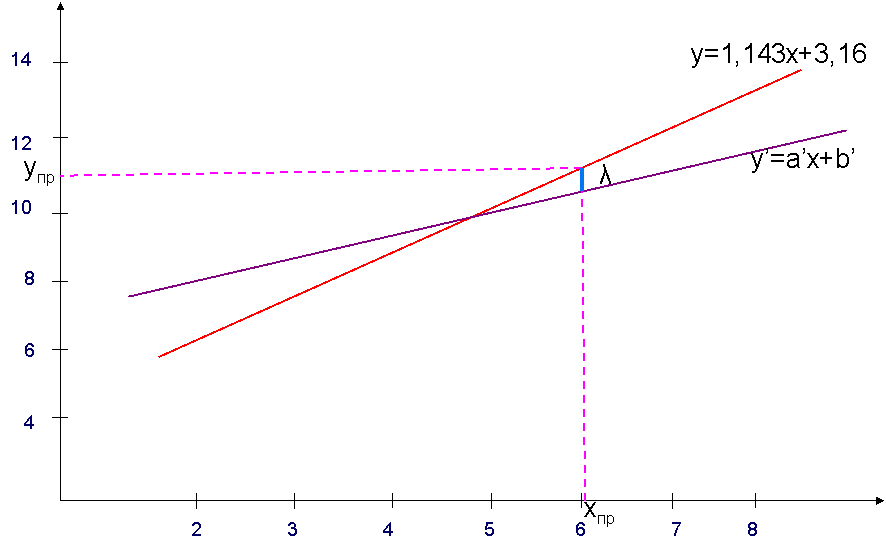
Рис.4 - Определение величины смещения
На рисунках 5 и 6 показаны результаты проводимых исследований.
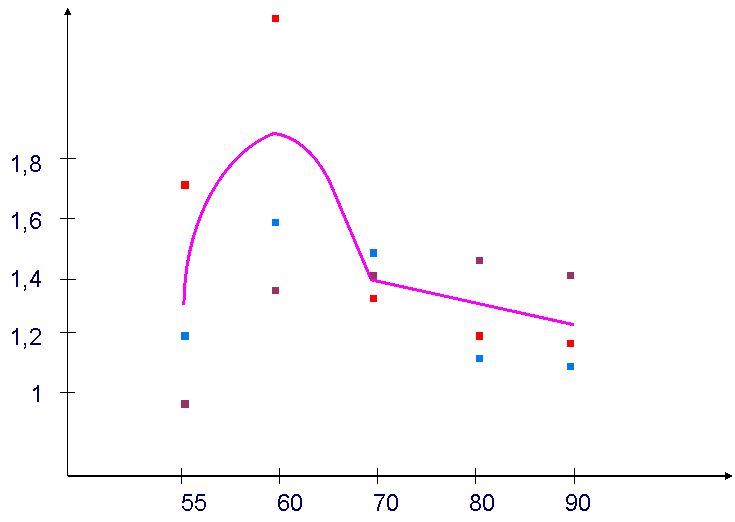
Рис.5 - Выигрыш 1-го метода
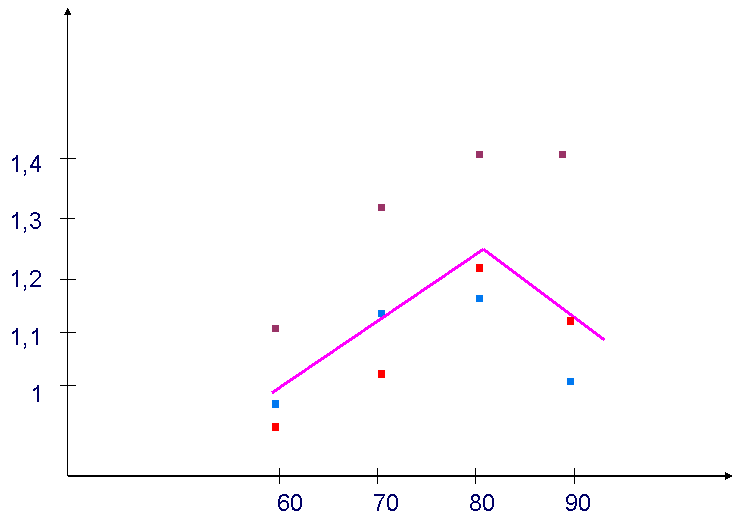
Рис.6 - Выигрыш 2-го метода
Было проведено 3 эксперимента с различными выборками данных (N=20), на основании которых было получено, что выигрыш при соответствующих значениях параметров , и m1, при использовании первого метода, в среднем составил 85%, что соответствует отбрасыванию 40% исходных данных, при использовании третьего метода 24,6%, что соответствует отбрасыванию 20%. Результаты, в различных случаях будут разными, т. к. выигрыш и количество отбрасываемых точек зависит от взятых параметров (количество данных, их разброс, , и т. д.)
В результате исследования было выявлено, что использование любого из трех перечисленных методов повышения прогноза приводит к увеличению точности прогнозирования. Все три рассмотренных метода предназначены для отбрасывания неоднородных данных в регрессионных уравнениях.
В случае, если разброс случайных значений yi намного превышает разброс случайных значений хi, то целесообразно использовать первый метод.
В случае, когда разбросы случайных значений хi намного превышает yi, то целесообразно использовать второй метод.
В случае, когда разбросы значений хi и yi соизмеримы, то целесообразно использовать третий метод, т. к. в этом случае он дает наибольший выигрыш среди представленных трех методов.
Отбрасывание неоднородных данных при использовании любого из трех методов, приводит к выигрышу, который определяется отношением доверительного интервала прогнозирования без отбрасывания неоднородных точек к сумме доверительного интервала и величины смещения при отбрасывании неоднородных точек.
Величина выигрыша любого из рассмотренных методов имеет максимум, величина которого определяется параметрами 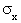 , , 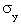 , Rxy.
Максимальный выигрыш от использования данных методов может достигать 100 и более процентов. , Rxy.
Максимальный выигрыш от использования данных методов может достигать 100 и более процентов.
В случае, если плотность распределения вероятностей экспериментальных данных будет иметь не нормальное распределение, выигрыш от применения рассмотренных методов сохраняется, однако величина будет другой. Данные методы подходят для любых симметричных распределений экспериментальных данных относительно уравнения регрессии.
Рассмотренные методы могут использоваться для случая нелинейных регрессионных моделей, если эти модели сводятся к линейным путем использования специальных подстановок.
По результатам имитационного моделирования выигрыш от применения методов повышения достоверности прогнозирования составил от 15,65% до 85%, что позволяет рекомендовать предложенные методы для увеличения точности прогнозирования с использованием регрессионных прогнозных моделей.
Предложенные методы позволяют более эффективно, с наименьшими затратами (по сравнению, например, с многократными измерениями с целью устранения ошибок или анализом на однородность) получить достаточный выигрыш, не вникая в сущность экономических проблем.
Литература
1) Четыркин Е.М. Статистические методы прогнозирования. Изд. 2-е, перераб. и доп. М., "Статистика", 1997
2) Колемаев В.А. Эконометрика: Учебник. – М.: ИНФРА-М, 2004 – 160 с.
3) Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. – М.: ЮНИТИ, 1998.
4) Єріна А. М. Статистичне моделювання та прогнозування: Навч. посібник - К.: КНЕУ, 2001 - 170 с. http://www.gmdh.net/articles/theory/StatModeling.pdf
5)Грешилов А. А., Стакун В. А., Стакун А. А. Математические методы построения прогнозов. - М.: Радио и связь, 1997 - 112 с. http://www.gmdh.net/articles/theory/TimeSeries.pdf
6) Орлов А.И. Прикладная статистика. Учебник. - М.: Издательство «Экзамен», 2004. - 656 с.
7) Green W. H. Econometric analysis: 4th ed. - N. Y.: Macmillan Publishing Company, 2000
|
