Реферат
к магистерской работе "Разработка ПО для анализа и оптимизации деятельности подписного агентства"
составила: Кравченко Е.А.
ВВЕДЕНИЕ
Современный мир – это мир информации. Известно, что объём информации растёт по экспоненциальному закону, и очевидно, что это ставит человека перед задачей рационального и надёжного хранения информации, с обеспечением удобного доступа и гарантией целостности. Но обеспечение хранения информации это лишь часть задачи, возникающей перед человеком. Кроме того, что информацию необходимо накапливать, её также нужно обрабатывать и извлекать из общей массы фактов и данных полезное знание. Эта задача является нетривиальной, и она привела к появлению такого направления, как Data Mining - «добыча знаний». Под добычей знаний понимается извлечение из большого объёма информации о некотором процессе или явлении нового, неочевидного для пользователя знания, которое впоследствии может быть использовано. Датой зарождения этого направления принято считать 80ые годы прошлого века. Технология добычи знаний отделилась от классического статистического анализа и постепенно превратилась в самостоятельное направление (так, между классическим статистическим анализом и добычей знаний существует как ряд важных сходств, так и множество принципиальных отличий).
В данном направлении существует множество различных подходов, теоретических выкладок, мало связанных между собой (кроме тематики и терминологии), но не противоречащих, а дополняющих друг друга. В ходе выполнения работы планируется осуществить сравнительный анализ различных методов и подходов концепции Data Mining с последующим выбором наиболее подходящего (соответствующего тематике предметной области и отвечающего требованиям, выдвигаемых к полученному решению) алгоритма. Также планируется построение на его базе прогноза для исследуемой предметной области. В ходе изучения данного направления возможна корректировка и уточнение поставленной задачи.
1 ОБЗОР ОСНОВНЫХ ВОПРОСОВ DATA MINING
1.1 Истоки направления.
Важным этапом в выделении Data mining в самостоятельное направление было появление теории группового учёта аргументов. Основы этой методологии были заложены киевскими математиками Ивахненко.
МГУА как воплощение индуктивного подхода - это оригинальный метод построения моделей по экспериментальным данным в условиях неопределенности. Полученные по этому методу модели оптимальной сложности отображают неизвестные закономерности функционирования исследуемого объекта (процесса), информация о которых неявно содержится в выборке данных. В МГУА для построения моделей применяются принципы автоматической генерации вариантов, неокончательных решений и последовательной селекции лучших моделей по внешним критериям. Такие критерии основаны на делении выборки на части, при этом оценивание параметров и проверка качества моделей выполняются на разных подвыборках. Это разрешает обойтись без отягощающих априорных предположений, поскольку деление выборки разрешает автоматически (неявно) учесть разные виды априорной неопределенности. Эффективность метода подтверждена решением многочисленных реальных задач в экологии, гидрометеорологии, экономике, технике.
1.2 Типы моделей добычи знаний.
Компания IBM в ходе исследований в области Data Mining выделили 2 большие группы моделей добычи знаний: верификацию моделей (verification model) и модели поиска знаний (discovery model). По классификации специалистов IBM первая группа включает в себя задачи постановки и проверки некоторой статистической гипотезы. Данная группа задач весьма чувствительна к человеческому фактору – так как выдвижение гипотез ложиться на эксперта. Для второй групп задач этот фактор несущественен, так как поиск знаний выполняется автоматически на заданном наборе данных. Очевидно, что для этих задач важным является качество и объём данных (длина выборки, зашумлённость данных, наличие «пробелов» и т.д.).
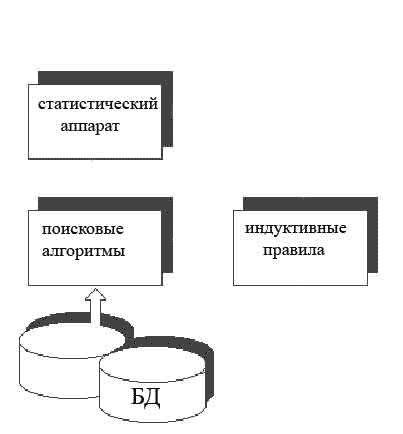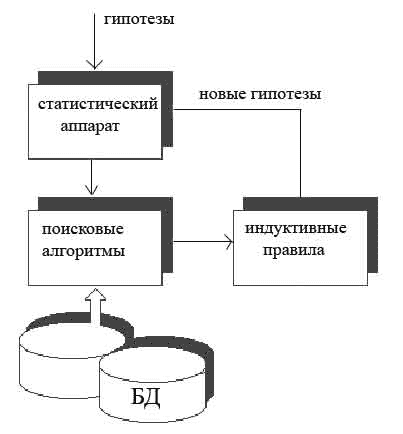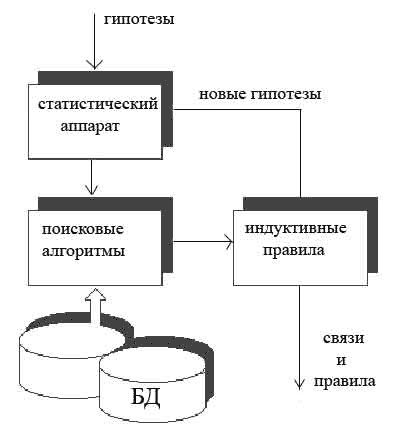
На рисунке показана общая схема выявления правил и связей в БД при совместном использовании гипотез, сформулированных экспертом и гипотез, сформированных автоматически.
1.3 Хранилища данных.
Разработка теоретических основ и практических рекомендаций по данному вопросу принадлежит профессору Билу Инмону (Bill Inmon). В своей работе «Построение хранилища данных» он излагает основные характеристики оптимального хранилища данных и приводит 4 основных требования:
- предметно-ориентированное построение: исключение всей ненужной информации, не имеющей прямого отношения к исследуемой области и наиболее точное отражение существенных признаков;
- интегрированность: обеспечение лёгкого доступа к данным для приложений и минимизация промежуточных кодирований;
- долгосрочность хранения: хранилище должно содержать данные не менее чем за 5 последних лет (и более), эти данные не должны изменяться;
- устойчивость к изменениям: хранилище должно обеспечивать сохранность данных и защиту от специального или случайного их изменения.
В контексте разработки хранилищ данных большое развитие получили алгоритмы очистки, подготовки и обобщения данных.
Также следует отметить подход доктора Камрана Парсея (Kamran Parsaye), сотрудника CEO of information Discovery, Canada. Его «парадигма бутерброда» (“sandwich paradigm”) предполагает итерационный анализ и пересмотр данных перед созданием специализированного хранилища.
1.4 Методы извлечения знаний
Центральное значение в направлении добычи данных занимают сами алгоритмы добычи данных. Один из крупнейших производителей ПО, поддерживающего технологию Data Mining, BaseGroup Labs, предоставляет следующую классификацию алгоритмов поиска знаний.
Все задачи, решаемые методами Data Mining, можно условно разбить на пять классов.
1. Классификация – отнесение объектов (наблюдений, событий) к одному из заранее известных классов. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
2. Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность объектов. Объекты внутри кластера должны быть «похожими» друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация. Часто применительно к экономическим задачам вместо кластеризации употребляют термин сегментация.
3. Регрессия, в том числе задача прогнозирования. Это установление зависимости непрерывных выходных переменных от входных. К этому же типу задач относится прогнозирование временного ряда на основе исторических данных.
4. Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые это задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
5. Последовательные шаблоны – установление закономерностей между связанными во времени событиями.
В общем случае, не принципиально, каким именно алгоритмом будет решаться одна из пяти задач Data Mining – главное иметь метод решения для каждого класса задач.
На сегодня наибольшее распространение получили самообучающиеся методы и машинное обучение. Рассмотрим кратко наиболее известные алгоритмы и методы, применяющиеся для решения каждой задачи Data Mining.
Деревья решений (decision trees) предназначены для решения задач классификации. Иногда используют другие названия метода - деревья классификации, деревья решающих правил. Они создают иерархическую структуру классифицирующих правил типа «ЕСЛИ…ТО…» (if-then), имеющую вид дерева. Чтобы принять решение, к какому классу следует отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид «Значение параметра А больше В?». Если ответ положительный, осуществляется переход к правому узлу следующего уровня; затем снова следует вопрос, связанный с соответствующим узлом и т. д. Приведенный пример иллюстрирует работу так называемых бинарных деревьев решений, в каждом узле которых, ветвление производится по двум направлениям (т. е. на вопрос, заданный в узле, имеется только два варианта ответов, например «Да» или «Нет»). Однако, в общем случае, ответов а, следовательно, ветвей, выходящих из узла, может быть больше. Дерево решений состоит из узлов, где производится проверка условия, и листьев – конечных узлов дерева, указывающих на класс (узлов решения).
Искусственные нейронные сети, в частности, многослойный персептрон, решают задачи регрессии и классификации. Однако, в отличие от дерева решений, нейронные сети не способны объяснять выдаваемое решение, поэтому их работа напоминает «черный ящик» со входами и выходами. Нейронные сети представляют собой вычислительные структуры, моделирующие простые биологические процессы, аналогичные процессам, происходящим в человеческом мозге. ИНС – это распределенные и параллельные системы, способные к адаптивному обучению путем реакции на положительные и отрицательные воздействия. В основе их построения лежит элементарный преобразователь, называемый искусственным нейроном или просто нейроном по аналогии с его биологическим прототипом. Структуру нейросети – многослойного персептрона - можно описать следующим образом. Нейросеть состоит из нескольких слоев: входной, внутренний (скрытый) и выходной слои. Входной слой реализует связь с входными данными, выходной – с выходными. Внутренних слоев может быть от одного и больше. В каждом слое содержится несколько нейронов.
Линейная регрессия, как это следует из названия, решает задачи регрессии. Но она предназначена для поиска линейных зависимостей в данных. Если же зависимости нелинейные, то модель с использованием линейной регрессии может быть не построена вообще. Для этого лучше воспользоваться более универсальным методом нахождения зависимостей, например, искусственной нейронной сетью.
Кластерный анализ. Главное назначение кластерного анализа – разбиение множества исследуемых объектов и признаков на однородные в соответствующем понимании группы или кластеры. Это означает, что решается задача кластеризации данных и выявления соответствующей структуры в них. Методы кластерного анализа можно применять в самых различных случаях, даже в тех случаях, когда речь идет о простой группировке, в которой все сводится к образованию групп по количественному сходству. Большое достоинство кластерного анализа в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ в отличие от большинства математико-статистических методов не накладывает никаких ограничений на вид рассматриваемых объектов, и позволяет рассматривать множество исходных данных практически произвольной природы. Это имеет большое значение, например, для прогнозирования конъюнктуры, сегментации, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов. Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы экономической информации, делать их компактными и наглядными.
В больших массивах данных получил распространение алгоритм k-средних (k-means). Его суть в том, что весь исходный набор примеров разбивается на k классов таким образом, что минимизируется евклидово расстояние между объектами внутри классов и максимизируется евклидово расстояние между классами.
Самоорганизующиеся карты (Self Organizing Maps – SOM), или карты Кохонена, так же как и методы кластерного анализа, используются для решения задач кластеризации и сегментирования. Самоорганизующаяся карта является разновидностью нейронной сети. Алгоритм функционирования самоорганизующихся карт представляет собой один из вариантов кластеризации многомерных. В алгоритме SOM все нейроны (узлы, центры классов) упорядочены в некоторую структуру, обычно двумерную сетку. В ходе обучения модифицируется не только нейрон-победитель (нейрон карты, который в наибольшей степени соответствует вектору входов и определяет, к какому классу относится пример), но и его соседи, хотя и в меньшей степени. За счет этого SOM можно считать одним из методов проецирования многомерного пространства в пространство с более низкой размерностью. При использовании этого алгоритма, векторы близкие на полученной карте, оказываются близки и в исходном пространстве.
Ассоциативные правила (association rules) позволяют находить закономерности между связанными событиями. Соответственно, они применимы для решения задач выявления ассоциаций. Примером ассоциативного правила, служит утверждение, что покупатель, приобретающий хлеб, приобретет и молоко с вероятностью 75%. Впервые эта задача была предложена для поиска ассоциативных правил для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis). Ассоциативные правила эффективно используются в сегментации покупателей по поведению при покупках, анализе предпочтений клиентов, планировании расположения товаров в супермаркетах, адресной рассылке. Однако сфера применения этих алгоритмов не ограничивается лишь одной торговлей. Их также успешно применяют и в других областях: медицине, для анализа посещений вебстраниц (Web Mining), для анализа текста (Text Mining), для анализа данных по переписи населения, в анализе и прогнозировании сбоев телекоммуникационного оборудования и т.д. Задачей поиска ассоциативных правил не является выявление всех правил, поскольку часть из них известны аналитикам, другие могут не представлять статистической ценности. Поэтому при поиске вводятся пороги поддержки и достоверности ассоциативных правил. Классическим алгоритмом нахождения ассоциативных правил считается алгоритм APriori.
Последовательные шаблоны (sequential patterns) представляют собой закономерности между связанными во времени событиями. Примером последовательного шаблона является утверждение, что клиент, заключивший договор на страхование имущества, через полгода заключает договор страхования от несчастного случая с вероятностью 70%. Для выявления подобных закономерностей в базе данных кроме самого события должна храниться информация о клиенте и времени события. Алгоритмы последовательных шаблонов похожи на алгоритмы ассоциативных правил. Распространение получили AprioriAll и AprioriSome [2].
Данное направление является, бесспорно, перспективным и интересным, научная работа по нему ведётся практически во всех крупнейших университетах мира. Традиционно исследования проводятся на базе кафедр прикладной математики (или, как более узконаправленный вариант, кафедр статистики и прогнозирования). Изыскания в данной области не сталкиваются с проблемой необходимости дорогостоящей материальной базы, что позволяет вести исследования даже при небольшом бюджете ВУЗа.
Среди лидеров мировой высшей школы, занимающихся, в том числе и вопросами Data Mining, стоит выделить следующие:
- School of Science and Computer Engineering (проф. Boetticher, G.D);
- University of Central Florida (проф. Wang, M.C, проф. Johnson M.E);
- Научное сообщество AAAI;
- The Queen’s University of Belfast.
В Украине также ведётся научно-исследовательская работа в данном направлении, в частности, в Киевском Национальном Техническом Университете, в Донецком Национальном Техническом Университете.
ВЫВОДЫ
Актуальность описанного выше направления столь очевидна, что нет никаких сомнений в его бурном развитии в будущем. Рост теоретических и практических работ, посвящённых технологиям добычи знаний в мировой практике за последние несколько лет, является ярким тому подтверждением. Огромное количество классов задач, для которых может быть успешно применена технология Data Mining и постоянный рост информатизации общества является гарантией того, что в ближайшие 5-10 лет данная технология уверенно займёт своё место практически во всех сферах деятельности. Поэтому основной задачей, стоящей перед программистами, работающими в данной сфере, является, прежде всего, исследование эффективности уже существующих алгоритмов и их оптимизация в контексте отдельных предметных областей.
На момент написания данного автореферата работа над магистерской работой не закончена. Планируемое время окончания - декабрь 2007 года. Со всеми результатами данной работы можно будет ознакомиться после указанной даты у автора или научного руководителя.
Перечень ссылок
- Вапник В.Н. Восстановление зависимостей по эмпирическим данным. М: Наука,
1979.
- Грешилов А.А., Стакун В.А., Стакун А.А., Математические методы построения прогнозов. М: Радио и связь, 1997
- Дюк В.А., Самойленко А.П. Data Mining: учебный курс – СПб: «Питер», 2001 –
368 с.
- Ивахненко А.Г. Индуктивный метод самоорганизации моделей сложных систем. К: Наукова Думка, 1982
- Ивахненко А.Г., Степашко В.С., Помехоустойчивость моделирования. К: Наукова Думка, 1982
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы:
компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Machine Learning, Neural and Statistical Classification. Editors D.
Mitchie et.al. 1994.
- Muller, J.-A., F.Lemke: Self-Organising Data Mining. BoD Hamburg 2000.
- Pyle, D.: Data Preparation for Data Mining. Morgan Kaufman Publ. San Francisco 1999.
- Sharkey, A.J.C.: Combining Artificial Neural Nets: Ensemble and Modular Multi-Net Systems. Springer:
London 1999
- Хальд А, Математическая статистика с техническими приложениями. М: ИЛ,
1956.
ДонНТУ>
Портал магистров ДонНТУ
Сайт Кравченко Е.А.