Efficient XML File Reading for Game Development
Christoph Luerig
Abstract
Modern game engines read a lot of data during game start up in nearly all sub-modules. The general data format XML is about to establish itself as the de facto norm in this area. One of its strength is ease of readability. Many standard tools and exporters for this format exist that make the game developer's life much easier. When using this data format in large files, however, one finds that the associated costs are higher memory consumption, longer reading times and memory fragmentation. These are especially painful in console game development.
In this article we show that these disadvantages can be avoided, not by using the standard DOM (document object model), but by using the SAX (simple application interface for XML). Both are different approaches to parsing XML data. The latter one is less known among game developers and seems to be a lot more difficult to use at first. However, we will show that, if applied properly, the amount of work that needs to be done is about the same for both approaches; only the control flow is different.
Introduction
XML [RFC 3076] is a generalization of the HTML format where elements and attributes can be individually defined by the user. Today, this data format has a diverse range of applications where heterogeneous data needs to be specified. As the data format is ASCII or Unicode, it is especially interesting for game developers. It can be generated automatically by a tool, but is still editable by hand for quick and simple changes.
A wide variety of tools and standards are meanwhile developed to help the handling of XML files. Several standards are created to specify the syntax and even the semantics of special XML formats. One of the older format specifications is DTD. It is a special extension to the XML format that specifies a special XML syntax. A more advanced approach is the one that SCHEMA [derVlist2002] has taken. SCHEMA is a syntax and semantics specification language for XML files. SCHEMA specifications are themselves written in XML. Its ability to specify semantics covers things like default values or constraints. There some XML Editors like XMLSpy [XMLSpy] out there that can process Schema specifications to assist the user in editing files. Most database programs provide the possibility to export their data in XML format. Another interesting XML technology is XSLT [W3CR]. XSLT is a grammar transformation language with which it is possible to transform data from one XML format into another. This is, of course, very interesting from a game development perspective as the developer often has to cope with format changes in the game data as the design of the game matures.
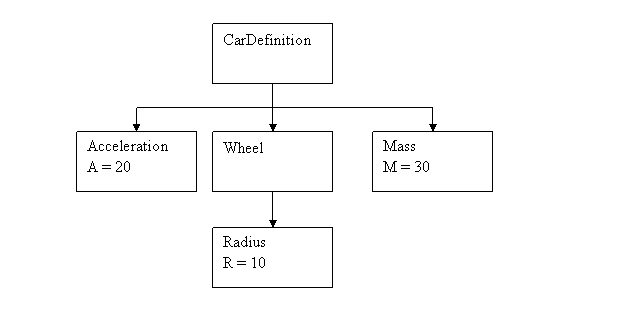
Seeing all those possibilities XML offers, we concentrate in the rest of the article on how to get the XML data into the game in the most simple and efficient manner. As a simple toy example, consider the following XML specification which represents a stripped down version of a car:
<?xml version="1.0" encoding="utf-8"?>
<CarDefinition>
<!--This is a simple xml test file to check the car definintion stuff-->
<Acceleration a="20.0" />
<Wheel>
<Radius r="10.0" />
</Wheel>
<Mass m="30.0" />
</CarDefinition>
It will be used as an example in the following explanations of parsing options. For simplification, we do not use any text constructs like <Radius>10.0</Radius> in the presented example. Extending the presented approaches to accommodate for these constructs is straightforward.
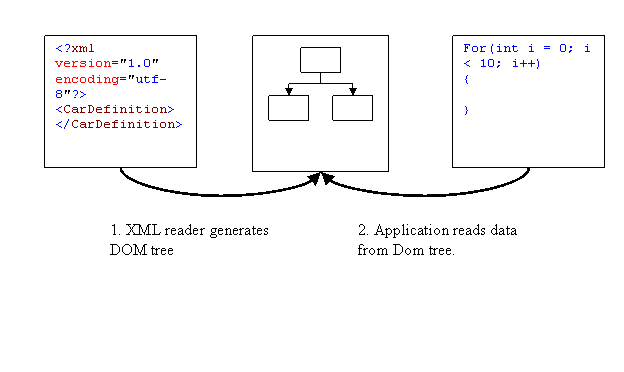
For reading XML files, public domain parsers exist; They fall into two categories. The most common among game developers is the DOM (document object model). With the DOM, the parser reads the complete XML file and generates a hierarchical representation of it in memory that can be then analyzed by the application. The SAX (simple API for XML) reads in the XML file as a stream and generates events alongside that have to be processed by the user application. Both models will be analyzed and compared in more detail in the following sections.
DOM model
The document object model is the most. This XML parser generates a tree structure of the document in main memory that can be processed by the application. Once processing is finished the tree is removed from memory. The above described model would have the following representation as a DOM tree in memory:
The parser provides methods to navigate within this structure for the application to extract the necessary data once the document has been read from the file into memory. The control flow of the system for that is as follows:
For the implementation of the DOM tree reader we use TinyXML [SFTXml]. It needs only a few lines to be initialized. For our case the code to initialize the reader, and to start the processing, looks like this:
TiXmlDocument doc("CarDefinition.xml");
doc.LoadFile();
TiXmlHandle hDoc(&doc);
TiXmlHandle carHeader = hDoc.FirstChildElement("CarDefinition");
Car testCar;
testCar.Parse(carHeader);
With the “LoadFile” command, the complete tree is generated in memory. All further calls are commands to extract the data from the tree. This extraction is done by the objects that need the data. All XML elements can be asked for further information. This is done for the extraction of the car definition block here. The car declaration is as follows:
class Car
{
public:
void Parse(TiXmlHandle handle);
protected:
Wheel m_wheel;
float m_acceleration;
};
The Parse method is responsible for extracting the data from the tree to fill in the member variables. The implementation is straightforward:
void Car::Parse(TiXmlHandle handle)
{
TiXmlElement* section;
section = handle.FirstChildElement( "Acceleration" ).Element();
section->QueryFloatAttribute( "a" , &m_acceleration);
section = handle.FirstChildElement( "Mass" ).Element();
section->QueryFloatAttribute( "m" , &m_mass);
m_wheel.Parse(handle.FirstChildElement( "Wheel" ));
}
One can see the use of the construct Handle and pointer in this code. The handle is a NULL tolerant pointer and makes navigation in the DOM tree structure much easier. Whenever a structure that is queried for - like in the above example the acceleration element - does not exist, the query command will return a NULL pointer. Any successive operations on this pointer will result in an exception. The handle is tolerant in this case and further handles can be queried from the handle for the element that does not exist. Only in the final stage where the data is actually accessed does the NULL pointer become explicit. This way it is possible to restrict error checks for missing data to the places where concrete elements are removing the need to scatter checks all over the code. Error checks have been omitted in this small sample for readability but should, of course, be included in actual production code. The handle can wrap most types of pointers in the TinyXML implementation.
The car itself now hands over the pointer of the child element with the wheel information and passes control over to the wheel to extract its data from the DOM tree:
class Wheel
{
public:
void Parse(TiXmlHandle handle);
protected:
float m_radius;
};
void Wheel::Parse(TiXmlHandle handle)
{
TiXmlElement* section;
section = handle.FirstChildElement("Radius").Element();
section->QueryFloatAttribute("r",&m_radius);
}
After this is done the complete information about the car is in memory, and the DOM tree can be destructed as it is no longer used.
We will go into details about advantages and disadvantages of this approach after we have discussed the alternative in the following section.
|