| Биография | Реферат | Библиотека | Ссылки | Отчет о поиске | Индивидуальное задание |
|
Введение На
сегодняшний день распределенные системы обработки данных используются
повсеместно. Многие базы данных поддерживают архитектуру клиент-сервер, в
которой данные располагаются на сервере, который получает запросы от клиентов.
Для каждого клиентского запроса сервер, как правило, передает клиенту большое
количество данных, которые являются ответом на запрос.. Коммуникационная
сеть может стать «бутылочным горлышком» в системе. Проблема минимизации
стоимости передачи ответов с сервера на клиент является
очень актуальной. В последнее время активно развивается новый метод, который
декомпозирует ответы в промежуточные результаты, что позволяет снизить
стоимости ответов. Эти промежуточные результаты передаются клиенту и клиент по
ним получает финальный ответ. Эксперименты над
запросами адаптированные с теста ТРС-Н показывают, что данный метод позволяет
значительно снизить стоимости передачи ответов. 
Рисунок 1 – Декомпозиция Покажем
небольшой пример декомпозиции запросов. Пусть имеются следующие таблицы: 
Рисунок 2 – Структура таблиц Подчеркнутый
атрибут для каждой связи – это ее первичный ключ. Номера в скобках после атрибутов – их размеры
в байтах. Здесь имеется ссылочная
целостность от атрибута order.custkey к атрибуту customer.custkey. Будем считать, что связь
располагается на стороне сервера, а запрос поступает со стороны клиента. Предположим,
пользователь на стороне клиента создал запрос Q1: 
Рисунок 3 – Исходный запрос Сервер
формирует ответ на запрос Q1 и посылает его обратно клиенту. Предположим, что на сервере
4000 записей, соответствующих ответу на запрос. Тогда число байт, переданных клиенту будет равно: 4000 * (25 + 8 + 4 + 4 +79 + 4 + 10) = 516 000. Посмотрим, сумеем ли мы снизить
количество переданной на клиент информации, сохранив
тем не менее все необходимые данные для получения ответа на исходный
запрос. На рисунке 3 показана часть
ответа на запрос Q1: 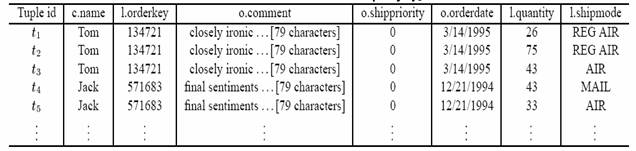
Рисунок 4 – Часть ответа на запрос Очевидно, что ответ на запрос
содержит избыточные данные. Например, записи t1 и t3 одинаковы, за исключением значения
полей l.quantity и l.shipmode. Записи t4 и t5 так же имеют избыточные данные.
Одна из причин избыточностей это то, что заказ может иметь несколько линейных
предметов с разными прочностями и формами. В обьединенных
результатах эти заказы создают несколько записей с одинаковыми значениями
атрибутов customer и order.
Основываясь на этом мы можем декомпозировать
ответ на Q1 на промежуточные результаты – виды V1 и V2: 
Рисунок 5 – Декомпозиция запроса Мы получим ответ на исходный запрос обьеденив полученные виды V1 и V2. В
ответе на запрос V1 будет 1200 записей и на запрос V2 будет 4000 записей. Используя
размеры полей таблиц можно посчитать, что размер ответа на эти виды будет
составлять 216 000 байт, в то время как размер ответа на исходный запрос составляет
516 000 байт. Используя ответы на виды V1 и V2 можно сформировать ответ на
исходный запрос. Из этого примера видно, что с помощью декомпозиции запросов
можно значительно снизить размер ответа на запрос, передавая клиенту результаты
видов. Клиент по этим результатам сможет сформировать ответ на исходный запрос. Этот
пример показывает, что существует возможность декомпозиции запросов на
промежуточные виды и что по ответам на эти виды можно получить ответ на
исходный запрос, при этом количество передаваемых данных уменьшается. Так же из
этого примера видно, что можно снизить избыточность ответов, что существует
более одного способа декомпозиции запроса. Если у клиента есть кеш с предыдущими ответами на запросы, то кешированные данные также могут быть использованы для
снижения стоимости коммуникаций. Цель и задачи Целью
данной работы является исследование проблемы минимизации
стоимости передачи результатов больших запросов с клиента на сервер.
Данная проблема существует в разнообразных распределенных приложениях с базами
данных. Будет рассмотрен новый метод, который декомпозирует ответы в
промежуточные результаты, что позволяет снизить стоимости ответов. Цель
исследований – нахождение баланса между минимизацией стоимости передачи данных
и снижением нагрузки формирования результата на клиенте и сервере. Основной
задачей является изучение и реализация математической модели, на которой
основан данный метод декомпозиции запросов. Предпологаемая научная новизна Рассматриваемый
метод декомпозиции запросов предполагает очень большое число планов
декомпозиции. Он нуждается в эффективном
алгоритме выбора размера промежуточного вида, поэтому при реализации
математической модели планируется произвести модификацию исходного метода, а
именно алгоритма нахождения промежуточных видов, с целью повышения
эффективности метода. Практическая ценность Так
как рассматриваемая в данной работе проблема является актуальной для
большинства распределенных систем обработки данных, поддерживающих архитектуру
клиент-сервер, то соответственно практическая ценность данных исследований
также достаточно велика. Снижение стоимости коммуникаций между клиентом и
сервером позволит экономить время и деньги как клиентам, использующим базу данных как сервис, так и серверу. Обзор существующих решенийОригинальная мотивация
нахождения видов для ответов на запросы появилась из контекста проектирования
хранилищ данных. Проблема нахождения «правильных» видов традиционно изучается
под именем выбора видов. Недавно был предложен подход к нахождению видов,
который учитывает все возможные виды, которые могут быть изобретены для
оптимизации данной метрики производительности базы данных. Этот подход уделяет особое внимание формальным
методам в нахождении набора видов,
который доказуемо глобально оптимальный для данного запроса или запросов и для
данной метрики производительности. Мы расширяем этот подход до минимизации
стоимости коммуникации в системах клиент-сервер. Минимизации
стоимостей коммуникаций является одной из ключевых проблем в распределенных
системах. Эвристические методы писка были предложены для нахождения
последовательности обьеденений и полуобьеденений,
которые снижают стоимости коммуникаций в распределенной обработке запросов. В полуобьеденениях связи для соединения на разных сторонах.
Все локальные операции, такие как выборка, проецирование и обьеденение
выполняются первыми, затем проецирование на атрибуты обьеденения
делится между двумя сторонами для исключения лишних записей. В нашем случае все
связи сохраняются на стороне сервера. Наш подход в проецировании результатов
запроса на стороне сервера в различные виды так, что глобально излишние записи
исключаются из этих видов. С другой стороны, так как все находится на стороне
сервера, мы можем сделать не только локальную выборку, а и глобальную выборку в
видах для снижения размеров видов. Одна из проблем в нашем подходе – нахождение
оптимального способа проецирования. Подход
использует информацию, предоставленную узлами планирование запросов, для
исключения некоторых планов стоимостей заранее. Модель стоимостей в подходе
включает коммуникационные стоимости, которые моделируются через сохраненные
константы. До сих пор наш метод был наиболее гибким. Предыдущие
распределенные методы фокусировались на проблеме размещения запроса на
различные источники. Поэтому они декомпозировали запросы на подзапросы среди
индивидуальных узлов сервера. Как только место исполнения запроса установлено,
и подзапросы дошли до индивидуальных серверов, наш метод может быть применен
для оптимизации запроса на уровне сервера. Другими словами, наш метод применим
на верхнем уровне традиционного локального оптимизатора запросов, который
уменьшает стоимость коммуникаций между источниками и стороной запроса. К тому
же, учитывая применение видов для построения результатов запроса, наш метод
может утилизировать кэшированные данные на стороне клиента с большей гибкостью.
Другой
подход – гибридная кусочная модель в распределенном
управлении запросами. Эта модель позволяет серверу выполнять разделение плана
доступа на клиенте, но если сервер просит вернуть 2 вида, которые будут
соединены на клиенте, они не вычисляют соединение 2-х связей, поэтому все
бесполезные записи, которые не использованы в других видах, остаются и
отправляются клиенту, нагружая сеть. Наш метод также оставляет некоторые
вычисления клиенту. На стороне сервера мы уменьшаем размер передаваемых данных
с помощью утилизации всех потенциальных обьеденений,
которые могут быть сформированы на клиентах и которые подобны полуобьединениям, выполняемым между разными сторонами
сервера. Итак, в этом методе передаваемые виды более не содержат избыточные
записи, что дает снижение коммуникационных стоимостей. К тому же, предыдущие
работы по распределенной обработке запросов не придавали значения исследованию
гарантий глобальной оптимальности предложенных решений. Наш же метод может
выбирать глобально оптимальные планы для снижения стоимости коммуникаций. Существуют
методы конвертирования связанных данных во вложенные структуры. Один из этих
методов декомпозирует результаты ,связанные результаты
запросов в связанные виды. Так же он использует всю информацию обьеденения для снижения избыточности и исключения
бесполезных данных в результате. Декомпозиция видов для каждого запроса
содержит строго один набор видов, т.е. по одному виду на каждую связь. Этот
метод неэффективен в получении результирующих данных с использованием
вложено-циклических обьединений. Также этот метод не
дает гарантий оптимальности полученных результатов. Методы
компрессии данных могут быть использованы для сжатия результатов для
эффективной передачи. Наш метод ортогонален данным методам. Также они могут
быть применены к результатам нашего метода для повышения эффективности. Существуют
методы, которые решают проблемы оптимального разбиения на виды. Они показывают,
что когда запрос содержит самообьединения, мы должны
выбрать дизьюнктивные виды в качестве оптимального
решения. В нашем методе мы фокусируемся на тех случаях, когда оптимальными
являются коньюктивные виды. Актуальные проблемы Так
как число возможных планов декомпозиции может быть очень большим и очень много
факторов влияет на выбор промежуточных видов, то метод нуждается в быстром,
масштабируемом и эффективном алгоритме выбора декомпозиции. Также актуальным
является нахождение правильного баланса между снижением стоимости коммуникаций
и загрузками клиента и сервера. Заключение В
данной работе рассмотрена проблема передачи ответов на
большие запросы-обьединения с сервера на клиент. Суть
проблемы заключается в избыточности передаваемых данных. Основная цель
исследований – минимизация стоимости передачи результатов запросов. Решением
данной проблемы является декомпозиция запросов на промежуточные виды. Данный
метод является гибким и высокоэффективным. Его эффективность подтверждена
экспериментально. В
основе метода декомпозиции лежит разбиение больших запросов на подзапросы.
Ответы на подзапросы передаются клиенту и клиент по
ним формирует ответ на исходный запрос. Перечень ссылок1.
R. Chirkova
and D. Suciu. A formal perspective on the view selection problem. Proc. of VLDB, pages 59–68, 2001. 2.
R. Chirkova and C. Li. Materializing views with
minimal size to answer queries. PODS, 2003. 3. Transaction Processing Performance Council: TPC. http://www.tpc.org/. |