| Назад в библиотеку |
|
| B. Chandra, Indian Institute of Technology, New Delhi, India bchandra104@yahoo.co.in |
Sati Mazumdar , Vincent Arena University of Pittsburgh, Pittsburgh, USA maz1@pitt.edu |
and N. Parimi NSIT, New Delhi. |
Decision trees have been found very effective for classification especially in Data Mining. This paper aims at improving the performance of the SLIQ decision tree algorithm (Mehta et. al,1996) for classification in data mining The drawback of this algorithm is that large number of gini indices have to be computed at each node of the decision tree. In order to decide which attribute is to be split at each node, the gini indices have to be computed for all the attributes and for each successive pair of values for all patterns which have not been classified. An improvement over the SLIQ algorithm has been proposed to reduce the computational complexity. In this algorithm, the gini index is computed not for every successive pair of values of an attribute but over different ranges of attribute values. Classification accuracy of this technique was compared with the existing SLIQ and the Neural Network technique on three real life datasets consisting of the effect of different chemicals on water pollution, Wisconsin Breast Cancer Data and Image data It was observed that the decision tree constructed using the proposed decision tree algorithm gave far better classification accuracy than the classification accuracy obtained using the SLIQ algorithm irrespective of the dataset under consideration. The classification accuracy of this algorithm was even better compared to the neural network classification technique. Overall, it was observed that this decision tree algorithm not only reduces the number of computations of gini indices but also leads to better classification accuracy.
Classification of data is one of the important tasks in data mining. Various methods for classification have been proposed such as decision tree induction and neural networks. CART (Breiman et. al, 1984) is one of the popular methods of building decision trees but it generally does not do the best job of classifying a new set of records because of overfitting. The ID3 decision tree algorithm was proposed by Quinlan in 1981 and there have been several enhancements have suggested to the original algorithm which include C4.5 (Quinlan,1993).The focus of ID3 is on how to select the most appropriate attribute at each node of the decision tree. A measure called Gain is defined and each attribute…s gain is computed. The attribute with the largest gain is chosen as the splitting attribute.
One of the main drawbacks of ID3 is regarding the attribute selection measure used. The splitting attribute selection measure Gain used in ID3 tends to favour attributes with a large number of distinct values. This drawback was overcome to some extent by introducing a new measure called Gain Ratio. Gain Ratio takes into account the information about the classification gained by splitting on the basis of a particular attribute. The Gini index is an alternative proposed to Gain ratio and is used in in SLIQ algorithm (Mehta et. al.,1996). ID3 was also inadequate in handling missing or noisy data. Several enhancements to ID3 have since been proposed to overcome these drawbacks. These drawbacks are dealt with in SLIQ.
In the case of SLIQ algorithm has to be computed for each attribute at every node. In this paper, an Elegant decision tree algorithm has been proposed which is an improvement over the SLIQ algorithm. It is shown that this algorithm not only reduces the number of computations of gini indices drastically but also increases the classification accuracy over the original SLIQ algorithm and the Neural Network classification technique.
SLIQ (Supervised Learning In Quest) and SPRINT (Shaefer et.al, 1996) was developed by the Quest team at IBM. SPRINT basically aims at parallelizing SLIQ. The tree is generated by splitting one of the attributes at each level. The basic aim is to generate a tree which is the most accurate for prediction. The gini Index, the measure of diversity of a tree, was introduced. With the help of the gini index it is decided which attribute is to be split and what is the splitting point of splitting of the attribute. The gini index is minimised at each split, so that the tree becomes less diverse as we progress. The class histograms are built for each successive pairs of values of attributes. At any particular node, after obtaining all the histograms for all attributes, the gini index for each histogram is computed. The histogram that gives the least gini index gives us the splitting point P for the node under consideration. The method to calculate gini index for a sample histogram with 2 classes namely A and B is defined as follows:
Table 1 - Sample Class Histogram
| Attribute Value < P | A | B |
| L | a1 | a2 |
| R | b1 | b2 |
P Splitting value for an attribute
a1 denotes the number of attributes which are less than P and belong to class A
a2 denotes the number of attributes which are less than P and belong to class B
b1 denotes the number of attributes which are greater than P and belong to class A
b2 denotes the number of attributes which are greater than P and belong to class B
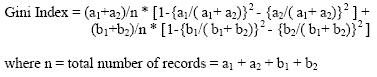
Using this formula, the gini indices are computed for each histogram for each attribute. Once the gini index for each histogram is known, the split attribute is chosen to be the one whose class histogram gives the least gini index, and the split value equals the splitting point P for that histogram. The stopping criterion is when the gini index at a node becomes zero, as this implies that all data records at that node have been classified completely.
SLIQ proposes to scan each attribute, and each value corresponding to an attribute in order to ascertain the best split. However, in the case of large databases, with numerous data records, this process of scanning each attribute and each corresponding pair of successive values leads to a huge number of computations. In the modified SLIQ algorithm, it is proposed that instead of performing calculations for the gini index at each value in an attribute, the calculation be performed at a certain fixed interval within the range of values of an attribute. For instance, the computation may be performed at intervals of 10% of the number of records at each node. This would result in the total number of computations being significantly lesser than that in SLIQ. In SLIQ, the total number of computations per node is the product of the number of attributes (n) and the number of records at that node (m). In case of the modified algorithm, the total computations at a node is the product of the number of attributes (n) and the number of groups formed (g=m/k where k is the interval/group size). It is to be noted that since the number of unclassified patterns varies at each progressive node of the tree, the computation to divide these unclassified patterns into various groups has to be performed separately at each node of the tree. An optimum value of k needs to be chosen to generate the best results. Thus, depending on the value of k, a significant reduction is observed in the modified algorithm.
Algorithm
Input : Training set, samples consisting of attributes A1– An and records R1– Rm. num is the no. of groups into
which each attribute has to be divided into for computation of gini index.
attr stores the splitting attribute
ginival stores the final gini index
splitval stores the final splitting value of attribute attr
Assumed to be c no. of classes
//initializations
ginival = infinity // high value
splitval = 0
attr = 0
Copy records R1– Rm from samples to data.
Maketree(data)
{
Classification accuracy using original SLIQ algorithm, the Elegant decision tree algorithm and the Neural Network technique was compared using three datasets viz. the pollution dataset, Wisconsin Breast Cancer Dataset and the Image Dataset.
The pollution dataset comprises of data samples (107 records or patterns) for testing the chemical pollution of water based on a set of 15 attributes which signify the effect of 15 different types of chemicals. The output reveals whether or not the water sample is polluted, denoted by 1 or 0. Decision trees were built both by SLIQ and the modified SLIQ algorithm using 87 records for training. Remaining 20 records were used for testing the classification accuracy.
All the data sets were also for trained using Neural Network technique. Back propagation algorithm (Rumelhart, 1986) was used for classification. The model comprised of 15 input neurons and 2 output neurons.
Comparison of classification accuracy on test data using various classification techniques
Table 2. Classification Accuracy of Datasets using Various Algorithms
| Classification Techniques | SLIQ | Elegant Decision Tree | Neural Networks |
| Pollution data | 60% | 80% | 70% |
| Breast cancer data | 75% | 100% | 90% |
| Image data | 75% | 95% | 90% |
It is observed that for all the data sets the elegant decision tree algorithm gives better classification accuracy compared to the original SLIQ decision tree algorithm. The new algorithm gives better classification accuracy even compare to neural networks.
The paper presents an elegant decision tree algorithm which is a modification of SLIQ algorithm. The main advantage of this algorithm is that it helps in drastic reduction of the number of computation of gini indices at each node of the tree and at same time helps in increasing the classification accuracy. The classification results on three popular data sets show that this new algorithm gives far more superior classification accuracy compared to the SLIQ algorithm and the neural networks technique.
|