
Andrey Lysykh
e-mail: lysykh@inbox.ru
| DonNTU / Master's portal / Andrey Lysykh | RUS | ENG |
|
|
Andrey Lysykhe-mail: lysykh@inbox.ru Faculty: Computer ScienceDepartment: Software EngineeringTheme of master's work: Research and modeling productivity of Apache web-server from influence of various factorsLeader: Valeriy I. Kostin |
| Biography :: Abstract :: Library :: Links :: Search report :: Individual task |
Web represents constantly developing system which extends due to new components and services by continuously increasing rates. The applications realizing such concepts as electronic commerce, digital libraries, video on demand and remote training, increase the Web-traffic even more quickly. Some popular Web-sites receive millions inquiries a day, often not providing thus small enough time of the response. Big time of the response becomes a source of disappointment for many Web-users and a problem for managers of many Web-sites. There are quite pertinent assumptions, that distribution of wireless technologies and growth of number of portable computers, pocket computers and mobile phones with an opportunity of Internet connection, will cause even more increase of the Web-sites traffic.
Web-servers are the key components of intranets and Internet. They give out the information in the form of the text, images, sound and videofiles, and also their various combinations (i.e. multimedia) in reply to requests. The Web-services accessible in intranets and Internet, are provided with a lot of the various servers using a wide spectrum hardware and the software. In these networks servers receive, keep and pass further the information. The majority of clients of intranets and Internet are Web-browsers. Business becomes more and more dependent on using Web, therefore performance data of servers (i.e. productivity) become vital. As more information and services can be received on a Web-site of the company, as more requests it receives. And as more requests a Web-site recives, as much probability, that users will wait too long for reaction to the request. And then, as a rule, Web-users will be disappointed and will be switched to other site.
In the given work we examinate the factors influencing productivity of Web-servers, and also the review problems related with productivity.
Now any web resource which cares about the productivity, faces a problem estimation of productivity within the limits of the growing traffic and its modification. It is necessary to own the information on parameters of resource productivity at the predicted traffic for maintenance of appropriate working capacity and fault tolerance. It's expensive and taking a lot of time to make these experiments on a working server. Thus the developed program model is actual and responds requests for software for estimation web-server productivity.
There are many works devoted to a problem of the analysis productivity of web-servers, to the analysis of various factors influencing on productivity, to modeling of separate characteristics of servers. However program model realy approached to working server, the model which could be used for a prediction characteristics of productivity in real conditions is absent. For this reason the given work is exclusively new in the given area.
Practical value of the given researches is great enough as the problem considered in given work is actual for any web-site which owners are excited with it's productivity within the limits of constantly growing and changing traffic accordingly. The effective analysis of productivity of a web-server by means of program model allows to save time and money.
The common sense prompts, that the best way of an estimation productivity of a concrete hardware platform is to test it at real workload. However in many cases this approach appears unacceptable. Therefore makes decision to spend standard reference tests. Reference testing (benchmarking) is a primary method of estimation efficiency of functioning of real system. Reference testing is intended for the comparative analysis of productivity (a run control tasks method). Results of reference testing are used for an estimation efficiency of functioning of the given system at precisely set loading. Popularity of standard reference tests in many respects speaks that their control tasks and working loadings measurable and are repeated. Therefore at a choice of a configuration of computer system from offered variants rely on reference tests; they also are used as means of the control and diagnostics. Manufacturers, developers and users apply reference tests to revealing "bottlenecks" of new systems.
It is extremely important to be able to predict the concrete Web-server will react to concrete loading. Reference testing cannot give exact answers to questions about work of all combinations of workloads and applications. Therefore the executor should choose from reference tests demanded. On the basis of concrete workload and the script of the application working process, reference testing should give the information on how the server will respond to real workload, even before it's commissioning.
Use of analytical methods is connected with necessity of construction of mathematical models of a web-server for strict mathematical terms. Analytical models of computing systems usually have likelihood character and are under construction based on concepts of the theories of mass service, probabilities and Markov's processes, and also methods diffusive approximations. The differential and algebraic equations can be applied also.
Unlike analytical imitating modeling removes the majority of the restrictions connected with an opportunity of reflection in models of real investigated web-server, dynamic mutual conditionality of current and subsequent events, complex interrelation between parameters and parameters of a system effectiveness, etc. Though imitating models in many cases are more labour-consuming, less laconic, than analytical, they can be as much as close to modelled system and are simple in use.
Practical use of models of a web-server in many cases assumes presence of the information on real characteristics of it's job. Such information can be received by empirical methods. The necessary information is going to by means of special means which provide measurement of the parameters describing dynamics of functioning of a web-server in modes of skilled and normal operation.
Research of processes or objects is replaced with construction of their mathematical models and research of these models at analytical modeling. Identity of the form of the equations and unambiguity of ratio between variables in the equations describing the original and model are put in a basis of a method. As the events occuring in a web-server, have casual character the likelihood mathematical models of the theory of mass service are the most suitable for their studying.
Some attempts have been accomplished to construct model productivity of a web-server.
Van der Mei [4] modelled a web-server as a queuing network with serial service. The model was used to predict parameters of productivity of a server and has been approved by means of measurements and modeling
Wells and others [5] have made the analysis productivity of web-servers, using, colored Petri nets. Their model is divided into three layers where each layer models the certain aspect of system. The model has some parameters, some of them are known. Unknown parameters are certain by means of modeling.
Banga [6] investigated traps which arise during generation of synthetic working loadings of a Web-server in the test bed consisting of a small amount of clients. They have revealed restriction of the simple scheme of generation of requests which underlies modern systems of reference testing of Web-servers. Banga has offered and has estimated new strategy which excludes this problems, using a set of specially created client processes. Initial experience in use of this method for an estimation of a usual Web-server has specified that measurement of Web-server working process at overload and pulsing conditions of the traffic gives new and important understanding about a Web-server operating. His new methodology makes possible generation realistic, pulsing HTTP traffic and thus an estimation of a prominent aspect of Web-servers operating.
However, the considered models are complex enough. There is a lack of simple model which at the simplicity remains adequate. The simple model establishes less amount of parameters, according to it it's easier to estimate, while the complex model usually contains such parameters which are difficult for receiving.
In this work described the model of a web-server which consists of the shared processor with the queue attached to them. The total of tasks in the system is limited. It is supposed, that process of receipt of requests to a server is Puasson whereas distribution of a service time is any. Such system name M/G/1/K*PS queue. An average service time and the maximal number of tasks - parameters which can be certain through the maximal estimation of probability. Also expressions for parameters productivity of a web-server, such as throughput, average time of the answer and probability of blocking are received.
we shall consider M/G/1/K queue with order of service - processor sharing as the given work considers as a web-server Apache - widely used multithreading server of a web (it means, that requests in him is processed by own thread or process during all cycle of a request life). Receipt of request according to Puasson distribution occurs with rate λ. The service time has the general distribution with an average x. The arrived request will be blocked, if the total tasks in system has reached predetermined value K. The task in queue receives small quantum of service and after that stops while each other task will not receive identical quantum of service in cyclic process. When the task has received demanded quantity of service, it leaves queue. Such system can be considered also as a network with queue with one node.
Function of probability of total tasks in system has is following,
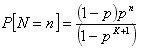
|
(1) |
where p – acting load and it is equal λx.
M/M/1/K*FCFS queue has the same function of probability. However distribution of a service time of M/M/1/K*FCFS queue should be indicative, and it's order of service should be FCFS.
The Web-server is modelled, using M/G/1/K*PS queue as shown in fig. 1. Requests comes according to Puasson process with rate λ. An average service time of each inquiry is x.The server can process simultaneously no more K requests. The inrequest will be blocked, if this number has been reached. The blocking probability designated as Pb. Therefore the rate of the blocked requests is certain as λPb.
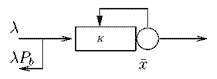
Figure 1 - M/G/1/K*PS web-server model
From (1) we can receive the following three parameters of productivity: average response time, throughput and blocking probability. Blocking probability Pb is equal to probability that system contains K tasks, the system is filled,
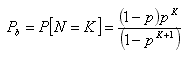
|
(2) |
Throughput H – rate of the processed requests. H is equal to accepted requests rate When the server reaches balance,
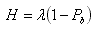
|
(3) |
Average response time T – expected time of task stay. Proceeding from Little law, we have
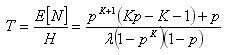
|
(4) |
In model there are two parameters x and K. It is supposed, that average response time at the certain frequency of requests receipt can be estimated by means of measurements. Estimations x and K obtain, minimizing the sum of squares of errors of observable average response time.
Let Ti is the average response time predicted by model and T^i is the average response time measured, at intensity of requests receipt λ, i=1..m. As prospective response time T^ are averages from the received results, it approximately normally distributed casual value with average T and a dispersion σ2T/n, when the number of indications n is very big. Hence, the pair parameters of model x and K can be estimated, minimizing the sum of square mistakes as follows,
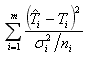
|
(5) |
As approach the prospective dispersion of response time σ^2i can be used instead of σ2i.
Now, the problem of parameter estimation becomes a question of optimization,
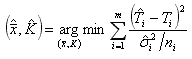
|
(6) |
Optimization can be solved by various ways, for example a method of most speedy descent, the integrated gradient, Newton and even direct search.
In the given work considered the problem modeling and the analysis of productivity one of the most popular web-server Apache. The essence of a problem that character of the traffic (requested data) is obviously unknown and it is necessary to simulate approximately as much as possible productivity of system on obviously unknown data. The basic purpose of researches - construction of program server model. The decision of the given problem is the model of a web-server based on M/G/1/K*PS queue. The given model repeats real parameters well enough. It's efficiency is confirmed experimentally.
Master's work isn't completed yet by the time this abstract issued. Completion of the thesis is expected till January, 2008. The Full text of the thesis and related materials can be obtained from the author or his leader after the specified date.
| Biography :: Abstract :: Library :: Links :: Search report :: Individual task |