Источник: http://www.sagecertification.org/publications/library/proceedings/usits97/full_papers/banga/banga.pdf
Перевод: Лысых А.А.
Широко распространенное использование Всемирной паутины и связанных приложений накладывает интересные требования производительности на сетевые серверы. Способность измерять эффект от этих требований важна для того, чтобы настроить и оптимизировать различные программные компоненты составляющие Web-сервер. Чтобы измерять эти параметры, необходимо генерировать реалистичные запросы HTTP клиента. К сожалению, точная генерация такого трафика в испытательном стенде с ограниченными возможностями не тривиальна. В частности обычно используемый подход неспособен генерировать частоту запросов клиента, которая превышает вместимость сервера, тестируемого даже в короткие промежутки времени. Эта статья исследует ловушки, с которыми каждый сталкивается, измеряя способности Web-сервера, используя синтетическую рабочую нагрузку. Мы предлагаем и оцениваем новый метод для генерации трафика сети, который может генерировать пульсирующий трафик, с пиковыми загрузками, которые превышают способности сервера. Наконец, мы используем предложенный метод, чтобы измерить работу Web-сервера.
Взрывной рост в использовании Всемирной паутины привел к увеличенной загрузке ее основных сетей и серверов, а также протоколов, на которых основана сеть. Улучшение работы сети было темой большого количества недавних исследований, которые рассматривали различные аспекты проблемы, такие как: улучшенное кэширование Web [5, 6, 7, 23, 31], расширения протокола HTTP [4, 20, 25, 18], улучшенные HTTP серверы и proxy [2, 33, 7] и реализации серверных ОС [16, 17, 10, 24].
До настоящего времени большинство работ по измерению производительности программного обеспечения сети сконцентрировалось на точной характеристике рабочих нагрузок Web-сервера в терминах типов запрашиваемых файлов, размеров передачи, местоположение ссылок запрашиваемых в URL и другие схожие характеристик [3, 5, 6, 8, 9, 12]. Некоторые исследователи пытались оценивать производительность web-серверов и proxy используя реальные рабочие нагрузки непосредственно [13, 15]. Однако, этот подход страдает от экспериментальных трудностей, создаваемых попытками измерение действующей системы без вторжения в нее и присущей невоспроизводимости действующих рабочих нагрузок.
Недавно, было предпринято некоторое усилие в отношении оценки Web-сервера с помощью генерации синтетического трафика HTTP клиента, основанного на инвариантах, наблюдаемых в реальном трафике сети [26, 28, 29, 30, 1]. К сожалению, есть ловушки, которые возникают в генерации тяжелого и реалистичного трафика, используя ограниченное число клиентских машин. Эти проблемы могут привести к существенному отклонению условий эталонного тестирования от действительности и будут не в состоянии предсказать производительность данного Web-сервера.
В испытательном стенде оценки Web-сервера, состоящем из небольшого количества клиентских машин, трудно моделировать много независимых клиентов. Как правило, используется схема генерации загрузки, которая приравнивает загрузку клиента к числу клиентских процессов в испытательной системе. Добавление процессов клиента предположительно должно увеличивать общую частоту запросов клиента. К сожалению, некоторые особенности протокола TCP ограничивают способность генерации трафика, такой наивной схемы. Из-за этого, генерация частоты запросов, которая превышает способности сервера, нетривиально, оставляя неучтенным эффект скачка частоты запросов. В дополнение, данная схема генерирует трафик клиента, который имеет малое подобие в его временных характеристиках к реальному трафику сети. Кроме того, есть фундаментальные различия между задержками и потерями глобальных и локальных сетей, использующихся в во время испытаний. Оба этих фактора могут оставить неучтенными определенные важные аспекты работы Web-сервера. Наконец, необходимо позаботиться о том, чтобы гарантировать, что ограниченные ресурсы в моделируемых клиентских системах не исказят результаты работы сервера.
В этой статье, мы исследуем эти проблемы и их влияние на процесс оценки Web-сервера. Мы предлагаем новую методологию генерации HTTP запросов, которая дополняет работу по моделированию рабочей нагрузки сети. Наша деятельность сосредотачивается на тех аспектах метода генерации запросов, которые являются важными для обеспечения масштабируемого средства генерации реалистичных HTTP запросов, включая пиковые нагрузки, которые превышают способности сервера. Мы ожидаем, что эта методология генерации запросов, вместе с набором данных HTTP запросов, таких как используются в системе эталонного тестирования SPECWeb [26] и временной характеристикой HTTP трафика, приведет к системе тестирования, которая сможет более точно предсказать фактическую производительность Web-сервера.
Остальная часть этой статьи организована следующим образом. Раздел 2 дает краткий обзор динамики типичного HTTP сервера, работающего на подсистеме сети TCP/IP Unix. Раздел 3 идентифицирует проблемы, которые возникают в процессе попыток измерения производительности такой системы. В Разделе 4 мы описываем нашу методологию. Раздел 5 дает количественную оценку нашей методологии, и представляет измерения характеристик Web-сервера, используя предложенный метод. Наконец, Раздел 6 описывает связанные с данной работы и Раздел 7 предлагает некоторые заключения.
В этом разделе, мы даем краткий обзор работы типичного сервера HTTP на машине с реализацией TCP/IP на основе Unix. Описание обеспечивает основание для обсуждения в следующих разделах. Для простоты, мы сосредотачиваем наше обсуждение на сетевой подсистеме на основе ВSD [14, 32]. Работа многих других реализаций TCP/IP, таких как содержится в системе Unix V и Windows NT, является подобной.
В протоколе HTTP, для каждого выбранного URL, браузер устанавливает новое соединение TCP к соответствующему серверу, посылает запрос на это подключение и затем читает ответ сервера. Для отображения типичной Web-страницы, браузеру может понадобиться инициализировать несколько HTTP транзакций, чтобы загрузить различные компоненты (текст HTML, изображения) страницы.
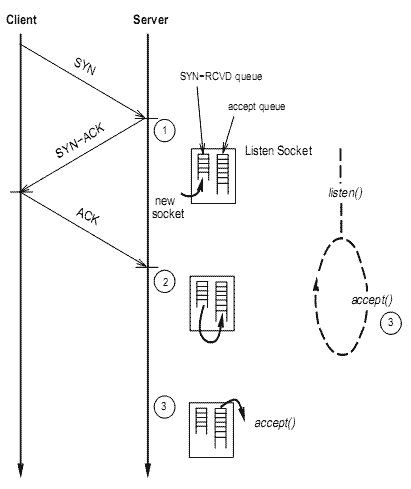
Рисунок 1 показывает последовательности событий в фазе установки подключения HTTP транзакции. В начале, процесс Web-сервера слушает запросы на подключения на сокете привязанном к известному порту - обычно это порт 80. Когда запрос установки подключения (TCP SYN пакет) от клиента получен на этом сокете (рисунок 1, позиция 1), TCP сервера отвечает пакетом SYN-ACK TCP, создает сокет для нового, незавершенного подключения, и помещает его в прослушиваемую очередь SYN-RCVD сокетов. Позже, когда клиент отвечает пакетом ACK на SYN-ACK пакет сервера (позиция 2), TCP сервер удаляет сокет, созданный выше, из SYN-RCVD очереди и помещает его в прослушиваемую очередь сокетов подключений, ждущих подтверждения (очередь подтверждений). Каждый раз когда процесс WWW-сервера выполняет системный вызов accept(), (позиция 3), первый сокет в очереди подтверждений прослушиваемого сокета удаляется и возвращается ответ. После принятия подключения сервер WWW прямо или косвенно, передавая это подключение к вспомогательному процессу, читает HTTP запрос от клиента, посылает назад соответствующий ответ, и закрывает подключение.
Рисунок 1 - Жизненный цикл установления HTTP соединения
В большинстве реализаций TCP/IP на основе Unix, переменная ядра somaxconn ограничивает максимальный задел на прослушиваемом сокете. Этот задел – верхняя граница суммы длин SYN-RCVD очереди и очереди подтверждения. В контексте предыдущего обсуждения, TCP сервера отбрасывает поступающие пакеты SYN (рисунок 1, позиция 1) всякий раз, когда эта сумма превышает значение задела в полтора раза. Когда TCP клиента теряет SYN-ACK пакет, он переводится в показательный возвратный режим повторной передачи SYN, пока он не получит SYN-ACK, или пока не истечет его таймер установки подключения.
Средняя длина SYN-RCVD очереди зависит от средней задержки передачи между сервером и его клиентами туда и обратно, и частоты запросов подключения. Поэтому сокет остается в этой очереди на время сроком на время, равное задержке передачи между сервером и клиентом туда и обратно. Длинные задержки и высокая частота запросов увеличивают длину этой очереди. Средняя длина очереди подтверждения зависит от того, как быстро HTTP сервер обрабатывает accept() и от частоты запросов. Если сервер работает на уровне своих максимальных возможностей, он не может выполнить accept() достаточно быстро, чтобы не отставать от частоты запросов подключения и очередь растет.
Каждое состояние сокета протокола содержится в структуре данных, названной Управляющим Блоком Протокола (PCB). TCP содержит таблицу активных PCB в системе. PCB создается, когда создается сокет в результате системного вызова или в результате нового устанавливаемого подключения. Подключение TCP закрывается любо активно одним из пиров выполняющая системный вызов close(), либо пассивно в результате поступившего управляющего FIN пакета. В последнем случае, PCB освобождается, когда приложение последовательно выполняет close() на связанном сокет. В предыдущем случае, FIN пакет посылается пиру и после того как поступает и принимается FIN/ACK пира, PCB появляется в наличии на интервал времени, равным так называемому, TIME-WAIT периоду реализации. Цель этого TIME-WAIT состояния в том, чтобы в повторно передать ACK закрывающегося процесса FIN пиру, если оригинальный ACK потерян, и позволить обнаружение задержавшихся пакетов, дублировать TCP сегменты этого подключения.
Со многим традиционными реализациями TCP/IP существует известная проблема, которая ограничивает пропускную способность Web-сервера. Многие системы основанные на BSD имеют маленькое значение по умолчанию и максимальные значения для somaxconn. Так как этот порог может быть достигнут, когда очередь подтверждения и/или SYN-RCVD очередь заполняются, низкое значение может ограничить пропускную способность, отказываясь от запросов подключения напрасно. Как обсуждалось выше, SYN-RCVD очередь может расти из-за длинных задержек передачи туда и обратно между сервером и клиентами, и высокой частоты запросов. Если предел слишком низок, поступающее подключение может быть отклонено даже при том, что Web-сервер может иметь достаточные ресурсы, чтобы обработать запрос. Даже в случае длинной очереди подтверждения, обычно предпочтительно принять подключение, если очередь не содержит достаточный объем работы для поддержания сервер в режиме занятости по крайней мере на начальном интервале повторной передачи TCP клиента (6 секунд для 4.4BSD). Чтобы решить эту проблему, некоторые продавцы увеличили максимальное значение somaxconn и поставляют их системы с большими максимальными значениями (например Digital Unix 32767, Solaris 1000). В Разделе 3, мы увидим, как этот факт взаимодействует с генерацией WWW запросов.
Этот раздел описывает проблемы, которые возникают при попытках измерить производительность Web-сервера, используя испытательный стенд, состоящий из ограниченного числа клиентских машин. По причине стоимости и легкости управления, каждый хотел бы использовать небольшое количество клиентских машин, чтобы моделировать большую совокупность web клиентов. Мы сначала описываем прямолинейную обычно используемую схему генерации трафик, и идентифицируем возникающие проблемы.
В простом методе, набор из N клиентских процессов выполняется на P клиентских машинах. Обычно, клиентские машины и сервер совместно используют LAN. Каждый процесс клиента неоднократно устанавливает HTTP подключение, посылает HTTP запрос, получает ответ, ждет в течение определенного времени (время обдумывания), и затем повторяет цикл. Последовательность запрошенных URL поступает из базы данных, спроектированной так, чтобы отразить реалистичные распределения URL запросов, наблюдаемые в сети. Времена обдумывания выбраны так, чтобы средняя частота URL запросов равнялась указанному числу запросов в секунду. N обычно выбирается так, чтобы быть как можно больше для данного P, чтобы добиться высокой максимальной частоты запросов. Чтобы уменьшать стоимость и для простоты управления экспериментом, P должен быть низким. Все популярные эталонные web тесты, которые мы знаем, используют схему генерации загрузки, подобную этой [26, 28, 29, 30].
Несколько проблем возникают при попытке использования простой схемы, описанной выше, для генерации реалистичных HTTP запросов. Мы описываем эти проблемы подробно в следующих подразделах.
Во всемирной паутине, HTTP запросы генерируются огромным количеством клиентов, где каждый клиент имеет распределение времени обдумывания с большим матожиданием и дисперсией. Кроме того, время обдумывания клиентов весьма зависимо; факторы, типа шаблонов сна/пробуждения реального пользователя, и публикации web контента в запланированное время вызывают высокую корреляцию HTTP запросов клиента. В результате трафик HTTP запросов поступающий на сервер является пульсирующим [8] и с пиковой частотой, превышающей среднюю частоту в 8 – 10 раз [15, 27]. Кроме того, пиковая частота запросов может легко превысить возможности сервера.
В отличие от этого, в простом методе генерации запросов, небольшое количество клиентов имеет независимое распределение времени ожидания с маленьким матожиданием и дисперсией. В результате сгенерированный трафик имеет небольшую пульсацию. Простой метод генерирует новый запрос только после того, как предыдущий запрос завершен. Все это в сумме с тем, что только ограниченное число клиентов может быть поддержано в маленьком испытательном стенде, подразумевает, что клиенты остаются по существу в жесткой взаимосвязи с сервером. Таким образом, частота сгенерированных запросов никогда не превышает возможности сервера.
Рассмотрим Web-сервер, который подвергнут HTTP запросам от увеличивающегося числа клиентов в испытательном стенде, используя простой метод. Для простоты, предположим, что клиенты используют постоянное время обдумывания равное 0 секунд, то есть, они посылают новый запрос немедленно после того, как предыдущий запрос завершен. Для загрузки маленьких документов, небольшое количество клиентов (3-5 для нашей испытательной системы) достаточно, чтобы управлять сервером на полной мощности. Если дополнительные клиенты добавляются к системе, единственное что происходит - очередь подтверждения в сервере растет, добавляя, таким образом, задержку очереди между моментом, когда клиент видит подключение как установленное, и моментом, когда сервер принимает подключение и обрабатывает запрос. Эта задержка в очереди уменьшает частоту, с которой клиент посылает запросы. Так как каждый клиент ждет ожидающей решения транзакции, для завершения перед инициализацией нового запроса, сетевая частота запросов на подключение всех клиентов остается равной пропускной способности сервера.
Добавляя еще больше клиентов, очередь подтверждения сервера в конечном счете заполняется. В этой точке TCP сервера начинает отбрасывать запросы на установку подключения, которые прибывают, в то время как сумма SYN-RCVD очереди и очереди подтверждения находится на пределе. Когда это случается, клиенты, запросы на подключение которых были отброшены, входят в экспоненциальную задержку TCP и генерируют далее запросы с очень низкой частотой. (Для систем на базе 4.4BSD это - 3 запроса в течение 75 секунд.) Поведение изображено на рисунке 2. Сервер насыщается в точке A, и затем частота запросов остается равной пропускной способности сервера, пока очередь подтверждения не заполняется (точка B). После того частота увеличивается на 0.04 запроса в секунду на каждого добавленного клиента.
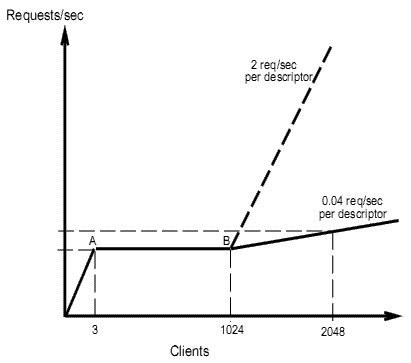
Рисунок 2 - Зависимость частоты запросов от количества клиентов
Чтобы генерировать существенную частоту запросов за рамками возможностей сервера, придется использовать огромное число клиентских процессов. Предположим что для определенного размер запрашиваемого файла, пропускная способность сервера - 100 подключений в секунду, и мы хотим генерировать 1100 запросов в секунду. Необходимо 15000 клиентских процессов ((1100-100) / (3/75)) свыше количества, равного максимальному размеру очереди подтверждения прослушиваемого сокета чтобы достигнуть этой частоты запросов. Как было сказано в Разделе 2, многие продавцы теперь конфигурируют свои системы большим значением somaxconn, чтобы избежать напрасного отбрасывания поступающих TCP подключений. Таким образом, с somaxconn = 32767, мы нуждаемся в 64151 процессе (15 x 32767 + 15000), чтобы генерировать 1100 запросов в секунду. Эффективная поддержка такого большого количества клиентских процессов на небольшом количестве клиентских машин не выполнима.
Реальный Web-сервер, с другой стороны, может легко быть перегружен огромным (фактически бесконечной) совокупностью клиентов, существующих в Интернете. Как упомянуто выше, абсолютно нормально для сервера получить скачок частоты запросов, которая превышает среднюю частоту в 8 – 10 раз. От таких скачков сервер должен временно быть перегружен. Важно оценить работу Web-сервера при перегрузке. Например, это - известный факт, что много сетевых подсистем на базе Unix и не-Unix, страдают от бедного поведения при перегрузке [11, 19]. При тяжелой сетевой загрузке эти системы управляемые на основе прерываний могут входить в состояние, названное receiver-livelock [22]. В этом состоянии, система тратит все ее ресурсы, обрабатывающие поступающие сетевые пакеты (в этом случае TCP SYN пакеты), только для того, чтобы отказываться от них позже, потому что не остается процессорного времени, чтобы обслужить прикладные программы-получатели (в этом случае Web-сервер).
Синтетические запросы, сгенерированные используя простой метод, не могут воспроизвести пульсирующий аспект реального трафика, и поэтому не в состоянии оценить поведение Web-серверов при перегрузке.
Сеть на основе глобальной сети имеет сетевые характеристики, которые отличаются от LAN, на которых обычно оцениваются Web-серверы. Аспекты работы сервера, которые зависят от этих сетевых характеристик, не оценены. В частности простой метод не моделирует высокие и переменные задержки глобальной сети, которые, вызывают длинные SYN-RCVD очереди в прослушиваемом сокете сервера. Кроме того, потери пакетов из-за перегрузки отсутствуют в испытательных стендах на основе LAN. Maltzahn et al. [13] обнаружил большое отличие от идеализированных чисел опубликованных в [7] в производительности Squid proxy. Большая часть этой деградации приписана эффектам глобальной сети, которые имеют тенденцию сохранять ресурсы сервера, типа заморозки памяти на расширенные промежутки времени.
Генерируя синтетические HTTP запросы от небольшого количества клиентских машин, необходимо позаботиться о том чтобы, ограничение ресурсов на клиентской машине случайно не искажали измеряемую производительность сервера. С увеличивающимся числом моделируемых клиентов на одну клиентскую машину, вероятно, возникнет нехватка процессорного времени и памяти клиента. В конечном счете, точка, в которой критическим параметром в транзакции сети теперь является не сервер, а клиент, достигается. Проектировщики коммерческих эталонных тестов Web-серверов также обратили внимание на эту ловушку. Эталонный тест WebStone [30] явно предупреждает об этой потенциальной проблеме, но не дает никакого систематического метода, чтобы избежать ее.
Первичный фактор в препятствовании проблеме узких мест клиентка от влияния результаты производительности сервера - ограничение числа моделируемых клиентов на одну клиентскую машину. Кроме того, важно использовать эффективную реализацию TCP/IP (в частности эффективная реализация таблицы PCB [15]) на клиентских машинах, и избегать операций ввода-вывода в моделируемых клиентах, которые могут затронуть частоту HTTP транзакций неконтролируемыми способами. Например, запись регистрируемой информации на диск может затронуть поведение клиента сложными и нежелательными способами. Мы возвратимся к проблеме критических параметров клиента в Разделе 4, и покажем, как объяснить ограничения ресурсов клиента в установке испытательного стенда.
В этом разделе, мы описываем дизайн нового метода генерации трафик. Этот метод обращается к проблемам, поднятым в предыдущем разделе. Должно быть отмечено, что наша деятельность отдельно не обращается к проблеме точного моделирования рабочих нагрузок сети в терминах типов файлов запроса, размера передачи и местоположения ссылок в запрашиваемых URL; наоборот, мы концентрируемся на механизмах генерации мощного параллельного трафик, который имеет временное поведение, подобное реальному трафику. Назначение нашей деятельности - дополнить существующую работу, сделанную по теме характеристики рабочей нагрузки сети [5, 6, 7, 23, 31], и может легко использоваться вместе с ней.
Основной архитектуре нашего испытательного стенда показана на рисунке 3. Набор из P клиентских машины подключен к тестируемой машине-серверу. Каждая клиентская машина выполняет множество процессов S-клиента. Структура S-клиента, и число S-клиентов, которые выполняются на одной машине, является критичными для нашего метода и более подробно описываются ниже. Если эффекты глобальной сети должны быть учтены, клиентские машины должны быть подключены к серверу через маршрутизатор, который имеет достаточную мощность чтобы обслуживать максимальный ожидаемый трафик. Цель маршрутизатора состоит в том, чтобы моделировать задержки глобальной сети, вводя искусственную задержку в механизм маршрутизации.
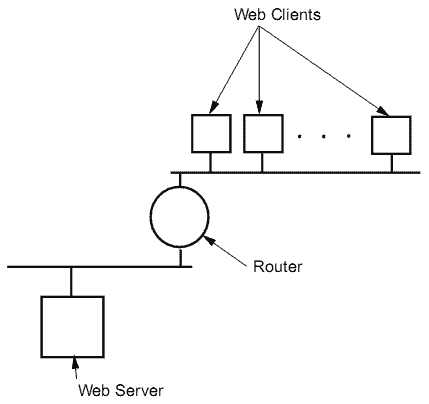
Рисунок 3 - Архитектура тестовой системы
S-клиент состоит из пары процессов, связанных Unix доменом socketpair. Один процесс в S-клиенте – это процессе установки подключения, он является ответственным за генерацию HTTP запросов с определенной частотой и с определенным распределением запросов. После того, как подключение установлено, процесс установки подключения посылает HTTP запрос серверу, после чего он передается процессу обработки подключения, который обрабатывает HTTP ответ.
Процесс установки подключения S-клиента работает следующим образом: процесс открывает D подключений к серверу, используя D сокетов в режиме неблокирования. Эти D запросов подключения растянуты на T миллисекунд. T обязано быть больше чем максимальная задержка передачи туда и обратно между клиентом и сервером (помните, что искусственная задержка может быть добавлена в маршрутизаторе).
После того, как процесс выполняет неблокированный connect(), чтобы инициализировать подключение, он делает запись текущего времени в переменной, связанной с используемым сокетом. В плотном цикле, процесс проверяет, завершено ли подключение для любого из его D активных сокетов, или прошло ли T миллисекунд с тех пор как connect() был выполнен на этом сокете. В первом случае, процесс посылает HTTP запрос на недавно установленное подключение, передает это подключение другому процессу S-клиента через Unix домен socketpair, закрывает сокет, и затем инициализирует другое подключение к серверу. Во втором случае, процесс просто закрывает сокет и инициализирует другое подключение к серверу. Обратите внимание на то что закрытие сокета в обоих случаях не генерирует никаких пакетов TCP в сети. В действительности, это преждевременно прерывает период блокировки времени установки TCP подключения. Завершение просто высвобождает ресурсы сокета в ОС.
Процесс обрабатывающий подключение S-клиента ждет 1) поступления данных на любое из активных подключений, или 2) поступления нового подключения на сокете домена Unix, соединяя его с другим процессом. В случае новых данных на активном сокете, он читает эти данные; если завершается ответ сервера, то закрывается сокет. Новое подключение, прибывая на сокет домена Unix просто добавляется к набору активных подключений.
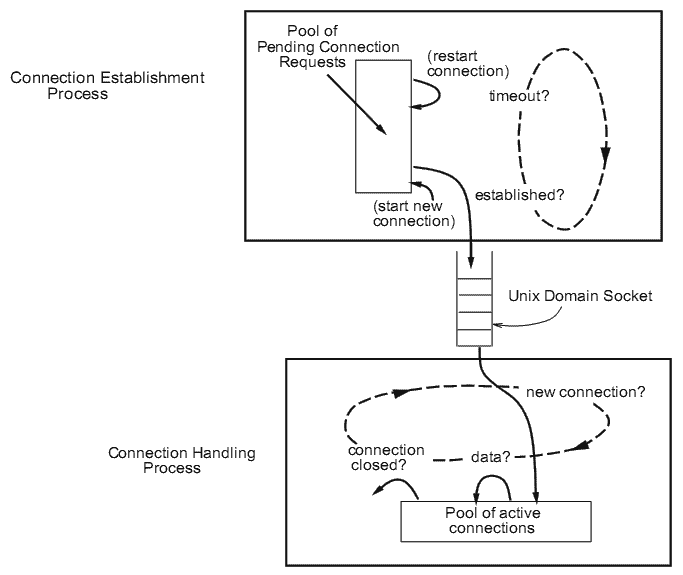
Рисунок 4 - S-клиент
Объяснение структуры S-клиента следующие. Две ключевых идеи (1), сокращение таймаута установки TCP подключения, и (2), поддержка постоянного числа несвязанных сокетов (моделируемые клиенты), которые пытаются установить новые подключения. Условие (1) достигнуто использованием неблокирования соединения и закрытием сокета, если не было установлено ни одно подключение в течение T секунд. Условие (2) гарантирует тот факт, что процесс установки подключения пытается установить другое подключение немедленно после то как подключение было установлено.
Цель (1) состоит в том, чтобы разрешить генерацию частоты запросов вне рамок пропускной способности сервера с разумным числом клиентских сокетов. Его эффект - то, что каждый клиентский сокет генерирует пакеты SYN с частотой по крайней мере l/T. Сокращение установки подключения до 500 миллисекунд само по себе заставило бы частоту запросов системы следовать за пунктирной линией на рисунке 2.
Идея содержащаяся в (2) должна гарантировать, что сгенерированная частота запросов независима от частоты с которой сервер обрабатывает запросы. В частности, как только частота запросов соответствует пропускной способности сервера, дополнительные задержки очереди в очереди подтверждения сервера больше не уменьшают частоту запросов моделируемых клиентов. Как только пропускная способность сервера достигнута, добавление дополнительных сокетов (дескрипторов) увеличивает частоту запросов на l/T запрос на дескриптор, устраняя плоскую часть графика на рисунке 2.
Чтобы увеличивать максимальную частоту генерации запросов, мы можем или уменьшить T или увеличить D. Как сказано выше, T должен быть больше чем максимальное время передачи туда и обратно между клиентом и сервером. Это для того, чтобы избежать случая, когда клиент прерывает неполное подключение в состоянии SYN-RCVD в сервере, но чей SYN-ACK от сервера (см. рисунок 1), еще не достиг клиента. Учитывая значение T, максимальное значение D обычно ограничивается в соответствии с ограничениями накладываемыми ОС на максимальное число открытых дескрипторов в одном процессе. Однако, в зависимости от мощности клиентской машины, возможно, что один S-клиент с большим D может насытить клиентскую машину.
Поэтому, пока клиентская машина не насыщена, D может быть настолько велик, насколько это позволяет ОС. Когда необходимо множество S-клиентов, чтобы генерировать данную частоту, должно использоваться наибольшее допустимое значение D, поскольку это сохраняет низким общее количество процессов, таким образом уменьшая перегрузку благодаря контекстным переключениям, и нехватке памяти между различным процессами S-клиентов. Тема следующего раздела - как определять максимальная частоту, которую может безопасно генерировать одна клиентская машина, не рискуя искажением результатов из-за критических параметров стороны клиента.
Как было отмечено в предыдущем разделе, оценивая Web-сервер, очень важно управлять клиентскими машинами в рамках области загрузки, где они не ограничивают наблюдаемую производительность. Наш метод нахождения максимального числа S-клиентов, которые могут безопасно выполняться на одной машине, и таким образом определение значения P необходимого для генерации определенной частоты запросов - следующие. Работа, которую клиентская машина должна проделать, в значительной степени определена суммой числа сокетов D всех S-клиентов, выполняющихся на той машине. Так как мы не хотим управлять клиентом в области близкой к максимуму его пропускной способности, мы выбираем это значение как наибольшее число N, для которого кривая зависимости пропускной способности от частоты запросов при использовании одной клиентской машины не отличается от той же самой кривой при использовании двух клиентских машин. Соответствующее число S-клиентов, которые мы должны использовать, определяется, распределяя эти N дескрипторов на такое малое количество процессов которое допускает ОС. Мы называем частоту запросов сгенерированную этими N дескрипторами максимальной чистой частотой запросов клиентской машины.
Возможно, что дескрипторный предел единственного процесса (налагаемый ОС) меньше чем среднее число одновременно активных подключений в процессе обрабатывающем подключения S-клиента. В этом случае мы не имеем никакой альтернативы, кроме как использовать большее число S-клиентов с меньшими значениями D, чтобы генерировать ту же самую частоту. Из-за увеличенной нехватки памяти и контекстного переключения, это может вызвать фактически более низкую максимальную чистую частоту запросов для клиентской машины, чем если бы ограничение ОС на число дескрипторов в процессе было бы выше. Из-за этого, число машин, необходимых для генерации определенной частоты запросов, может быть выше в этом случае.
Представленная схема генерирует HTTP запросы с тривиальным распределением времени обдумывания, то есть, она использует константу для этих целей, чтобы достигнуть определенной постоянной частоты запросов. Возможно генерировать более сложные процессы запросов, добавляя соответствующие периоды обдумывания между точкой, где S-клиент обнаруживает что подключение было установлено и точкой, когда он затем пытается инициализировать другое подключение. Таким образом, любой процесс поступления запроса, чья пиковая частота запросов ниже или равна максимальной чистой частоте запросов системы, может быть сгенерирован. В частности система может быть параметризирована для генерации автомоделируемого трафика [8].
В этом разделе мы представляем экспериментальные данные для определения количества проблем, идентифицированных в Разделе 3, и для оценки производительности нашего предложенного метода. Мы измеряем ограничения генерации запросов при наивном подходе и оцениваем метод генерации запросов на базе S-клиента, предложенный в Разделе 4. Мы также измеряем производительность Web-сервера, используя наш метод.
Все эксперименты были выполнены в испытательном стенде, состоящем из четырех рабочих станций Sun Microsystems SPARCstation 20 модели 61 (60MHz SuperSPARC +, 36 Кб l8, 1 Мб L2, SPECint92 98.2) в качестве клиентских машин. Рабочие станции оборудованы 32 Мб памяти и работают под управлением SunOS 4.1.3_U1. Наш сервер – двух процессорный SPARCStation 20 созданный из двух бывших машин SPARCStation 20 модели 61. Эта машина имеет 64 Мб памяти и работает под управлением Solaris 2.5.1. Локальная сетей ATM 155Mbit/s соединяет машины, используя сетевые адаптеры FORE Systems SBA-200. Для нашего HTTP сервера, мы использовали программное обеспечение NCSA httpd версии 1.5.1. В наших экспериментах мы не использовали никакой искусственной задержки маршрутизатора, соединяющего клиентов с сервером. Мы еще не оценили количественно эффект создаваемый задержками глобальной сети в работе сервера.
Ядро сервера ОС было настроено, используя рекомендации Sun по улучшению производительности Web-сервера. Таким образом, мы увеличили предел всех ожидающих подключений (accept+SYN-RCVD, очереди) до 1024 и уменьшили период TIME-WAIT до 3-х секунд.
Цель нашего первого эксперимента состоит в том, чтобы количественно характеризовать ограничения простой схемы генерации запросов, описанной в Разделе 3. Мы запустили увеличивающееся число клиентских процессов, распределенных по четырем клиентским машинам. Каждый клиент пробовал установить HTTP подключение к серверу, посылал запрос, получал ответ и затем повторял цикл. Каждый HTTP запрос поступал на единственный файла размера 1294 байта. Мы измерили частоту запросов (входящие SYN в секунду) на сервере.
В подобном тесте мы запускали 12 S-клиентов, распределенных по четырем клиентским машинам с увеличивающимся числом дескрипторов на один S-клиент и измерили частоту запросов, наблюдаемую на сервере. Каждый S-клиент имел период таймаута T установки подключения равный 500ms. Запрашивался тот же самый файл что и в случае простых клиентов.
На рисунке 5 изображен график зависимости полной частоты запросов подключения, наблюдаемой на сервере, от общего количества клиентских процессов для простого теста клиента. Рисунок 6 содержит график того же самого показателя для теста S-клиента, но с общим количеством дескрипторов в S-клиентах на оси X.
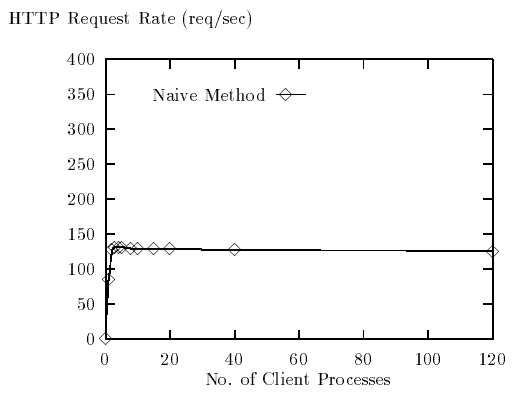
Рисунок 5 - Зависимость частоты запросов от количества клиентов
Рисунок 6 - Зависимость частоты запросов от количества дескрипторов
По причинам, обсуждаемым ранее, простая схема генерирует не больше, чем приблизительно 130 запросов в секунду (которая является пропускной способностью нашего сервера для этого размера запроса). В этом положении, сервер может принять подключения точно с той частотой, с которой они сгенерированы. Поскольку мы добавляем больше клиентов, увеличивается длина очереди подтверждения прослушиваемого сокета сервера и частота запросов остается почти постоянной на уровне пропускной способности сервера.
С S-клиентами, частота запросов увеличивается линейно с общим количеством дескрипторов, используемых для установки подключения клиентскими процессами. Чтобы выделить различие в поведении этих двух схем, мы не показываем полной кривой для S-клиентов на этом рисунке. Полная кривая показывает линейное увеличение частоты запросов на всем отрезке вплоть до 2065 запросов в секунду с нашей конфигурацией четырех клиентских машин. За этой точной, начинаются ограничения ресурсной базы клиента, и частота запросов прекращает увеличиваться. Для достижения более высоких частот необходимо большее количество клиентских машин. Таким образом, мы видим, что S-клиенты позволяют генерировать загрузку, которая намного превышает пропускную способность сервера. Сгенерированная загрузка также очень хорошо масштабируется с числом используемых дескрипторов.
Будучи в состоянии надежно генерировать высокую частоту запросов, мы использовали новый метод, чтобы оценить, как обычный коммерческий Web-сервер ведет себя при высокой загрузке. Мы измерили пропускную способность HTTP, достигнутую сервером в терминах транзакций в секунду. В этом тесте использовался тот же самый 1294-байтовый файл.
На рисунке 7 представлен график зависимости пропускной способности сервера от полной частоты запросов подключения. Как прежде, сервер насыщается приблизительно при 130 транзакциях в секунду. Поскольку мы увеличиваем частоту запросов свыше пропускной способности сервера, пропускная способности сервера уменьшается, сначала несколько медленно, и затем более быстро достигая приблизительно 75 транзакций в секунду при 2065 запросов в секунду. Это падение пропускной способности при увеличивающейся частотой запросов происходит из-за того, что ресурсов центрального процессора тратятся на обработку протокола поступающих запросов (пакеты SYN), которые в конечном счете отбрасываются из-за задела на прослушиваемом сокете (заполнена очередь подтверждения).
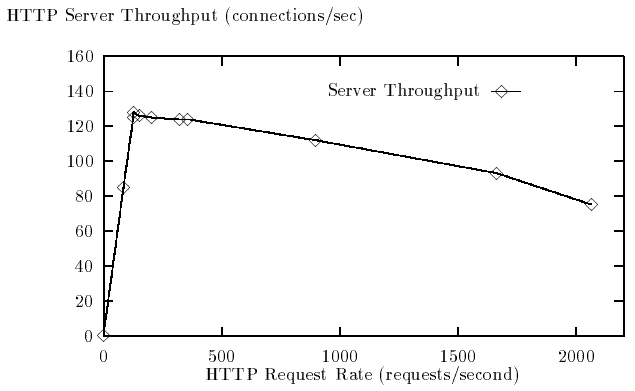
Рисунок 7 - Зависимость пропускной способности web-сервера от частоты запросов
Наклон снижения пропускной способности соответствует приблизительно 325 мкс времени обработки на SYN пакет. В то время как это может показаться большим, это совместимо с нашим наблюдением работы системы сервера, основанной на сетевой подсистеме 4.4BSD реализованной в SunOS 4.1.3_U1 на тех же самых аппаратных средствах.
Это большое снижение в пропускной способности перегруженного сервера выделяет важность оценки поведения Web-сервера при перегрузке. Заметьте, что невозможно оценить этот аспект работы Web-сервера с текущими тестами, основанными на простой схеме генерации запросов.
В Разделе 3, мы отмечали, что один из недостатков наивной схемы генерации трафика - нехватка пульсации в трафике запросов. Пик в частоте запросов может временно перегрузить сервер. Так как рисунок 7 показывает ухудшающуюся производительность при перегрузке, у нас возникла мотивация для исследования работы Web-сервера при пульсирующих условиях.
Мы сконфигурировали значения времени обдумывания S-клиента так, чтобы он генерировал пульсирующий трафик запросов. Мы характеризовали пульсирующий трафик двумя параметрами, a) отношение между максимальной и средней частотой запросов, и b) доля времени, в течение которого частота запросов превышает среднюю частоту. Всякий раз, когда норма запроса выше среднего, она равна максимуму. Период - 100 секунд. Для четырех различных комбинаций этих параметров мы меняли среднюю частоту запросов и измеряли пропускную способность сервера. Рисунок 8 содержит график зависимости пропускной способности Web-сервера от средней частоты запросов. Первый параметр в отметке каждой кривой - a), второй - b), выраженные в процентах. Например, (6, 5) означает случай, где в для 5 % времени частота запросов в 6 раз превышает среднюю частоту запросов.
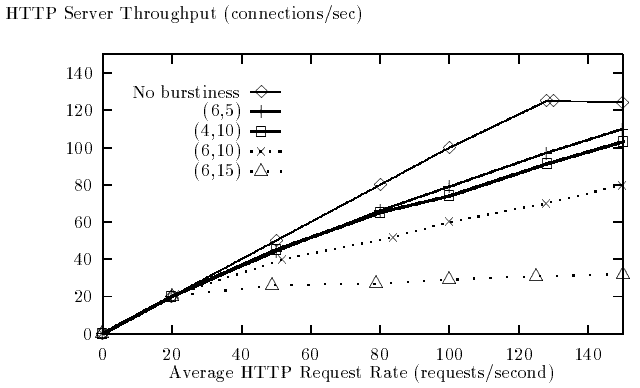
Рисунок 8 - Зависимость пропускной способности web-сервера от частоты запросов в условиях пульсации
Как ожидается, даже маленькое количество пульсаций может ухудшить пропускную способность Web-сервера. Для случая с 5%-ым отношением пиков и пиковой частотой превышающей в 6 раз среднее число, пропускная способность для средней частоты запросов значительно ниже пропускной способности сервера, она падает на 12-20 %. Вообще, высокая пульсация и в параметре a) и в b) существенно ухудшает пропускную способность. Это предсказуемо, в связи с наблюдаемым уменьшением производительности сервера за точной насыщения на рисунке 7.
Отметьте, что наша рабочая нагрузка только приближенно отражает то, что можно было бы видеть в реальности. Задача этого эксперимента - показать что использование S-клиентов позволяет генерировать распределение запросов сложной природы и с высокими пиковыми частотами. Это не возможно с использованием простой схемы генерации запросов. Кроме того, мы показали что эффект такой пульсации на работу сервера существенен.
Существует много работ для характеристики инвариантов в WWW трафике. Последняя, Arlitt и Williamson [3] характеризует несколько аспектов рабочих нагрузок Web-сервера, таких как распределение запрашиваемых типов файлов, размер передачи, местоположение ссылок в запрашиваемых URL и связанной с ними статистики. Crovella и Bestavros [8] искали самоподобие в WWW трафике. Инварианты, о которых сообщают эти попытки использовались в оценке производительности Web-серверов, и многих методах, предложенных исследователями, чтобы улучшить работу WWW.
Попытки тестирования Web-сервера имеют намного больше свежих источников. WebStone от SGF [30] был одним из самых ранних эталонных тестов Web-сервера и - фактический промышленным стандартом, хотя было несколько других разработок [28, 29]. WebStone очень подобен простой схеме которую мы описали в Разделе 3 и страдает от ее ограничений. Недавно SPEC выпустили SPECWeb96 [26], который является стандартизированным эталонным тестом Web-сервера с рабочей нагрузкой, полученной из исследования некоторых типичных серверов в Интернете. Метод генерации запросов этого теста также подобен простой схеме и таким образом он также страдает от тех же самых ограничений.
В резюме, все средства тестирования сети, о которых мы знаем, оценивают Web-серверы моделируют только аспекты рабочих нагрузок сервера, которые принадлежат типам файлов запроса, размерам передачи и местоположению ссылок в запрашиваемых URL. Не один из известных тестов не пытается точно моделировать эффекты перегрузок на производительности сервера. Наш метод, основанный на S-клиентах, допускает генерацию HTTP запросов с пульсациями и с высокими частотами. Это предназначено для того, чтобы дополнить усилия по характеристике рабочей нагрузки для оценки Web-сервера.
Эта статья исследует ловушки, которые возникают в процессе генерации синтетических рабочих нагрузок Web-сервера в испытательном стенде, состоящем из небольшого количества клиентских машин. Она выявляет ограничения простой схемы генерации запросов, которые лежит в основе современных систем эталонного тестирования Web-серверов. Мы предлагаем и оцениваем новую стратегию, которая исключает этим проблемы, используя набор специально созданных клиентских процессов. Начальный опыт в использовании этого метода для оценки обычного Web-сервера указывает на то, что измерение работы Web-сервера при перегрузке и пульсирующих условиях трафика дает новые и важные понимания в работе Web-сервера. Наша новая методология делает возможным генерацию реалистичного, пульсирующего HTTP трафика и таким образом оценку важного аспекта работы Web-серверов.