9.1 CЕТИ С РАДИАЛЬНЫМИ БАЗИСНЫМИ ФУНКЦИЯМИ
Использование многослойного персептрона с целью решения проблемы нелинейной классификации
достаточно эффективно. Однако, многослойный персептрон часто имеет много слоев с весами и обобщенный
образец связности. Вмешательство и перекрестное сцепление среди скрытых узлов приводит к высоко нелинейному
обучению сети с плоскими областями функциональной ошибки, которая возникает возле аннулирований различного
веса. Это может привести к очень медленной конвергенции процедуры обучения. Поэтому пробуждается интерес
для исследования других путей для без потери важных особенностей аппроксимации произвольных нелинейных
функциональных отображений между многомерными пространствами. В то же время появляется новая точка зрения
на интерпретацию функции классификации образов с целью рассмотреть классификацию образов как задачу
интерполяции данных в гиперпространстве, где, обучающие множества для поиска гиперповерхностей, будут
лучше всего соответствовать обучающим данным. Ковер (1965), установил в своей теореме на разделимость
образов, что задача классификации образов, приводимая нелинейно в многомерном пространстве, имеет
большую вероятность быть линейно разделимой, чем в маломерном пространстве. Оттуда можно сделать
заключение, что, как только эти образы были преобразованы в своих взаимозаменяемых частях, которые
могут быть линейно разделимыми, задача классификации стала относительно легка для решения.
Это обуславливает метод радиальных базисных функций, который может быть существенно быстрее,
чем методы, использованные для обучения многослойных персептронных сети.
Метод радиальных базисных функций происходит от техники в выполнении точной интерполяции набора данных
точек в многомерном пространстве. В этом методе радиальных базисных функций мы не считаем нелинейную
функцию скалярного произведения входного вектора и вектора весов в скрытом узле. Вместо этого мы определяем
активацию скрытого узла расстоянием между входным вектором и вектором прототипа.
Как упоминалось, метод радиальных базисных функций развивался от точного подхода интерполяции, но с
модификациями в целях обеспечения гладкой функции интерполяции. Построение сети с функции радиального
базиса включает три различных слоя: входной, скрытый, выходной. Входной слой прежде всего состоит из
исходных узлов (или сенсорные единицы), чтобы хранить входные данные для обработки. Для сетей
с радиальными базисными функциями характерен только один скрытый слой. Этот скрытый слой
обеспечивает нелинейные изменения от пространства входов. Выходной слой, который представляет
отклик сети на образец активации, примененный ко входному слою, обеспечивает линейное преобразование
от узла скрытого слоя к выходному пространству. На рисунке 9.1 изображено преобразования, применимые
ко входному вектору каждым слоем сети радиальных базисных функций.
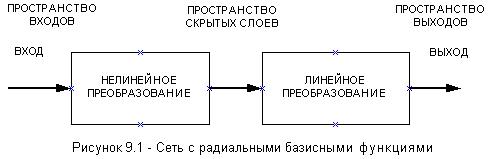
Отметим, что нелинейная соответствие
использовано для того, чтобы преобразовать нелинейно разделимая задачу классификации в линейно разделимую.
Как показано на рисунке 9.1, процедура обучения может быть осуществлена двумя стадиями.
Первая стадия - нелинейное преобразование. На этой стадии нелинейной функции отображения должно быть найдено
такое соответсвие, что мы будем иметь линейную отделимость пространства. Это подобно тому, что обсуждалось
в Главе 3, где не линейная квадратная дискриминантная функция преобразовывается в линейную функцию fi(x), i = 1,..,M,
представленной соответственно 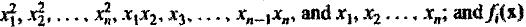 , и линейно независимы от (веса).
Вернемся к задаче радиальных базисных функций. Базисные функции, использованные в этой схеме - целиком
локализованные функции. Параметры, управляющие базисной функцией (соответствие скрытым узлам) могут быть
определены, используя относительно быстрые методы обучения без учителя. В некоторых из этих методов обсуждалось
Вторая стадия сети с радиальными базисными функциями - линейное преобразование, которое определяет вес для
выходного слоя. Это – линейная задача и поэтому также быстрая.
, и линейно независимы от (веса).
Вернемся к задаче радиальных базисных функций. Базисные функции, использованные в этой схеме - целиком
локализованные функции. Параметры, управляющие базисной функцией (соответствие скрытым узлам) могут быть
определены, используя относительно быстрые методы обучения без учителя. В некоторых из этих методов обсуждалось
Вторая стадия сети с радиальными базисными функциями - линейное преобразование, которое определяет вес для
выходного слоя. Это – линейная задача и поэтому также быстрая.
Как упоминалось в предыдущем параграфе, сети с радиальными базисными функциями – модификация точного подходу
интерполяции, в котором количество базисных функций определяется посредством соответствия скорее, чем посредством
размера набора данных. То есть, есть количество базисных функций намного меньше, чем данных образца (M«N, где
М – количество базисных функций, я N представляет количество точек данных образца). Центры базисных функций не
будут продуманы для векторов начальных данных. Соответствующие центры будут определены в течение процесса
обучения.
Пусть x будет d-мерным входным вектором, t – желаемый одномерный вектор, N число входные векторы xn,
n= 1,2,...N, и M – количество базисных функций в скрытом узле. Набор базисных функций может быть выбран
по следующей обобщенной форме: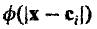 .
Аргумент функции - евклидово расстояние между входным вектором x и центром ci. Это оправдывает имя
радиальной базисной функции.
.
Аргумент функции - евклидово расстояние между входным вектором x и центром ci. Это оправдывает имя
радиальной базисной функции.
9.4 СРАВНЕНИЕ СЕТЕЙ С РАДИАЛЬНЫМИ БАЗИСНЫМИ ФУНКЦИЯМИ И МНОГОСЛОЙНОГО ПЕРСЕПТРОНА
Как сети с радиальными базисными функциями (RBF), так и многослойный персептрон (MLP) беспечивают методы для приближения нелинейных функциональных отображений между многомерными пространствами. Однако, структуры этих двух сетей весьма отличаются друг от друга. Ниже перечислены важных отличия между сетями RBF и сетями MLP.
- Сеть RBF имеет один скрытый слой, тогда как MLP может иметь один или больше скрытых слоев и сложный образец связности. Вмешательство и перекрестное сцепление между скрытыми единицами в многослойном персептроне может вести к медленной конвергенции процедуры обучения.
- В многослойных персептронных сетях отклики активаций вершин глобальной природы, и выход такой же для всех точек гиперплоскости, тогда как отклики активации локальных вершин в RBF сетях в смысле выхода каждой функции узла f(.) такой же для всех точек, имеющих такое же евклидово расстояние от соответствующего центра и экспоненциально уменьшается с расстоянием.
- В многослойном персептроне все параметры обычно определены в то же время, что и часть единой глобальной стратегии обучения, включая обучение с учителем, тогда как сеть RBF, используя экспоненциальное разрушение нелинейности для построения локальных приближений к нелинейному отображению для скрытых слоев, достигается быстрым обучением и делает систему менее чувствительной к индикации обучающих данных.