В данном докладе рассматриваются два алгоритма фрактального сжатия изображений — базовый алгоритм и FE-алгоритм. Оба алгоритма реализованы программно и проводится их сравнительный анализ на конкретных изображениях.
Введение
В начале 1980-х годов М. Барнсли выдвинул идею [1] получения заранее заданного изображения как аттрактора хаотического процесса, для построения которого он использовал систему итерируемых функций (Iterated Function System — IFS) и систему аффинных преобразований. Основная идея фрактального сжатия изображений заключается в поиске коэффициентов сжимающих преобразований, которые отображают доменные блоки изображения в ранговые блоки. Доменные блоки могут пересекаться, а ранговые блоки полностью покрывают изображение и не пересекаются. При этом доменные блоки по размерам должны быть больше ранговых блоков. Полученный в результате, этот набор коэффициентов преобразований — есть код изображения. Закодированное изображение можно декодировать путем итеративного применения каждого преобразования с известными коэффициентами к соответствующему участку произвольного начального изображения. Основные свойства алгоритмов фрактального сжатия изображений: 1) высокий (от нескольких единиц до тысяч) коэффициент сжатия (во сколько раз сжатое изображение меньше исходного по объему информации), особенно для изображений, которые имеют свойства самоподобия; 2) время кодирования намного больше времени декодирования; 3) независимость качества декодированного изображения от масштаба его просмотра.
1. Базовый алгоритм фрактального сжатия изображений
Базовый алгоритм [2] состоит из следующих шагов.
Шаг 1. В изображении f выделяют множество доменных блоков, с возможностью их перекрытия, определяемого специально предусмотренным параметром.
Шаг 2. Изображение разбивают на не перекрывающиеся ранговые блоки {Rk}. Блоки {Rk} могут быть одинакового размера, но более эффективно использование адап¬тивного разбиения с переменным размером блоков (например, методом квадро-дерева). Это дает возможность плотно заполнять ранговыми блоками маленького размера части изображения, содержащие мелкие детали.
Шаг 3. Для каждого рангового блока перебирают доменные блоки. При этом предусматривают изменение ориентации доменов (3 варианта вращения, 2 варианта вращения с отражением, 2 варианта отражения и 8-ой вариант — исходная ориентация без изменений). При каждом из вариантов ориентации домен сжимают до размеров рангового блока и вычисляют оптимальные значения коэффициентов aij и bij преобразования
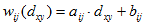
методом наименьших квадратов и по формуле
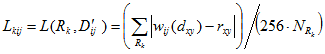
вычисляют нормированное значение параметра L(Rk , D'ij), который характеризует соответствие преобразованного сжатого i-го доменного блока wij(D'ij) в его j-ой ориентации ранговому блоку Rk. Здесь rxy ∈ Rk, dxy ∈ D'ij, D'ij — i-ый доменный блок в j-ой ориентации, сжатый до размеров рангового блока, NRk — количество пикселей в ранговом блоке. На этом шаге алгоритм работает в одном из двух режимах, выбираемом пользователем, — с поиском и без поиска наилучшего домена. В режиме поиска наилучшего домена для каждого ранга перебираются все домены, и выбирается тот i-ый домен и его j-ая ориентация, значение Lkij которого является минимальным среди всех остальных. В режиме без поиска наилучшего домена полный перебор доменов останавливают, как только обнаруживается такой i-ый домен и его j-ая ориентация, что его значение Lkij не превышает заданной допустимой погрешности (например, Lkij ≤ 0.05). В обоих режимах, если после перебора всех доменных блоков не нашлось таких, значения Lkij которых не превышают значение заданной допустимой погрешности, то делается проверка — находится ли рассматриваемый ранговый блок на максимально допустимом уровне разбиения рангов. Если нет, то этот ранговый блок разбивают на меньшие блоки и проводят данный шаг алгоритма для них. Если да, то из всех доменов выбирают тот домен и его вариант ориентации Dij, для которого значение Lkij является минимальным среди всех остальных, и считают рассматриваемый ранговый блок покрытым этим доменом.
Шаг 3 требует наибольших вычислений, т.к. для каждого рангового блока Rk алгоритм перебирает все доменные блоки и их варианты ориентации, проводя над каждым занимающие много машинного времени попиксельные операции изменения ори¬ентации и нахождения коэффициентов преобразования. Хорошее сжатие зависит от возможности найти хорошее соответствие между доменными и ранговыми блоками без необходимости глубокого разбиения ранговых блоков. Чрезмерно глубокое разбиение рангов приводит к слишком большому их количеству, что ухудшает коэф¬фициент сжатия, а недостаточно глубокое — к плохому качеству закодированного изо¬бражения. Одна из главных проблем фрактального сжатия изображений заключается в том, что большое количество доменных и ранговых блоков замедляет процесс коди¬рования.
2. FE-алгоритм фрактального сжатия изображений
Сравнение ранговых блоков с доменными в базовом алгоритме требует значи¬тельных вычислительных ресурсов, т.к. каждый ранг сравнивается с каждым доменом до тех пор, пока не достигается, по возможности, желаемое соответствие. В FE-алгоритме (Feature Extraction — выделение особенностей) [2] выделяется небольшое количество особенностей, характеризующих доменные и ранговые блоки. И первоначально, проводится сравнение именно этих характеристик, что значительно сокращает объем вычислений. В FE-алгоритме используется пять различных мер вариаций изображения: 1) стандартное отклонение; 2) асимметрия; 3) межпиксельная контрастность; 4) коэффициент бета, характеризующий насколько сильно отличаются значения пикселей от значения в центре блока; 5) максимальный градиент. Сам алгоритм включает следующие шаги.
Шаг 1. Аналогично шагу 1 базового алгоритма.
Шаг 2. Вычисление и хранение значений вектора характеристик для каждого доменного блока. Параллельно с этим производится покомпонентное отслеживание минимального и максимального значений. Эти значения затем используются для нор¬мирования компонентов всех векторов в промежутке значений от 0 до 1.
Шаг 3. При обработке рангового блока сначала вычисляют и нормируют его вектор характеристик. Затем вычисляют расстояния между вектором характеристик данного ранга и вектором характеристик каждого домена по формуле
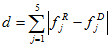
где fjR и fjD — это j-ые характеристики рангового и доменного блоков соответственно. Для последующего полного сравнения отбирается только заданный q процент доменов (напри¬мер, q = 2%) с минимальными значениями расстояния к данному рангу. Последующие действия аналогичны тем, которые выполняются в шаге 3 базового алгоритма (п.2), с той лишь разницей, что при последующем переборе доменов рассматриваются только выбранные q %.
Процедура выбора только доменов с самыми близкими расстояниями вектора характеристик к рангу является своеобразным фильтром, который существенно огра¬ничивает количество доменов для перебора и занимающих много машинного времени операций вычисления коэффициентов преобразования.
3. Сравнительный анализ алгоритмов
Оба алгоритма были реализованы автором программно и проведены соответст¬вующие эксперименты. Установлено, что FE-алгоритм, по сравнению с базовым, позволяет сжимать изображения за десятки раз меньшее время при одинаковых параметрах настройки алгоритмов (рис. 3.1). Но при этом базовый алгоритм обеспечивает в среднем на 30% более высокий коэффициент сжатия. Учитывая, что время кодирования в обоих алгоритмах не ограничивалось, такое различие, пожалуй, можно объяснить тем, что в FE-алгоритме процедура отбора по характеристическим особенностям не достаточно полно выявляет близость соответствия между доменными и ранговыми блоками на основании выбранного набора характеристик.

Рис. 3.1 — Зависимость времени кодирования от количества доменов
Таким образом, выделение характеристических особенностей может обеспечить значительное повышение скорости процесса кодирования, но, к сожалению, уменьшает коэффициент сжатия. Поэтому объектом дальнейших исследований является поиск более оптимального набора мер вариаций изображений в реализации FE-алгоритма.
Литература
- An introduction to Fractal Image Compression. Texas Instruments Europe, 1997
- Уэлстид С. Фракталы и вейвлеты для сжатия изображений в действии. Учебное пособие. — М.: Издательство «Триумф», 2003