Существует много методов реализации формантного синтеза речи. Все они основаны на детальном знании фонем и фонетическом расчленении речи и базируются на двух фундаментальных понятиях: лингвистического - фонемы, и акустического - форманты.
Фонема - основная единица звукового строя языка. Звуковой состав различных языков имеет свои особенности. В русском языке насчитывают 41 фонему, из них 6 гласных и 35 согласных (в английском - 20 гласных и 24 согласных, в французском - 15 гласных и 20 согласных). Можно сказать, что фонема - наименьшая языковая единица, имеющая смыслоразличительное значение. Из последовательности фонем строятся слова. Смысл высказывания выражается посредством цепочки слов.
Под формантами понимаются частотные резонансы (полюса передаточной функции) речевой акустической системы. Параметры формант (частота, ширина, уровень) опеределяются акустическими свойствами системы. Наиболее важный параметр - частота форманты, тесно связан с геометрической конфигурацией речевого тракта. Поскольку в процессе речи конфигурация речевого тракта меняется, то соотвественно меняются формантные частоты (рис. 8.9).
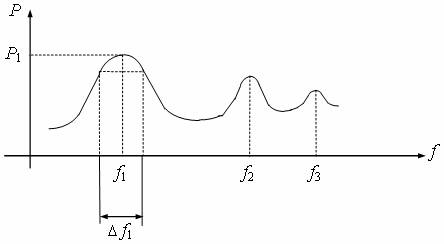
Для удовлетворительного синтеза речи обычно нужны две - четыре формантные частоты. Они лежат в диапазоне от 200 (первая форманта мужского голоса) до 2000 Гц (третья форманта женского голоса) [23]. Точным расположением формантных частот в звуковом спектре и определяется звук, который мы интерпретируем как речь. Причем, все формантные частоты присутствуют в речи одновременно и непрерывно перемещаются вверх-вниз по частотному спектру в соответсвии с особенностями произносимого слова. Поэтому, слушая говорящего человека, вы слышите звук не какой-либо одной частоты, а множество обертонов, которые образуются при фильтрации импульсов, формируемых на выходе голосового тракта.
Итак, в основе формантного синтеза лежит аналогия с моделью речеобразования человека. Рассмотрим формирование гласных звуков на модели (рис. 8.10).

Источник возбуждения создает импульсы основного тона, частота следования которых непрерывно меняется в процессе формирования речи. Речевой тракт при образовании гласных звуков работает как набор резонаторов, в которых происходит фильтрация сигнала возбуждения. В результате образуется спектральная картина, содержащая ряд максимумов. Максимумы соответствуют резонансам тракта (это и есть форманты). Таким образом, форманты - это некоторая частотная область концентрации энергии в спектре звука. Используют от двух до шести формант в зависимости от требуемой точности анализа речи. Суммарный выходной сигнал формантных фильтров (резонаторов) достаточно близко соответствует частотному спектру речи человека, и наш слух воспринимает его как речевое сообщение.
Приведем таблицу формантных частот для некоторых фонем гласных звуков.

Путем одновременной генерации формантных частот ![]() ,
, ![]() ,
, ![]() согласно таблицы 8.1 можно получить гласные звуки.
согласно таблицы 8.1 можно получить гласные звуки.
Структурная схема формантного синтезатора гласных звуков приведена на рис. 8.11.
Структурная схема форматного синтезатора гласных звуков включает
задающий генератор частоты основного тона, полосовые фильтры,
перестраиваемые на формантные частоты, соответствующие синтезируемой
фонеме с помощью переменных резисторов ![]() -
-![]() и сумматор, суммирующий сигналы с трех фильтров. В
спектрограмме выходного сигнала этой схемы содержатся три формантные
частоты, идентичные формантным частотам в спектрограмме речи человека,
произносящего те же гласные.
и сумматор, суммирующий сигналы с трех фильтров. В
спектрограмме выходного сигнала этой схемы содержатся три формантные
частоты, идентичные формантным частотам в спектрограмме речи человека,
произносящего те же гласные.
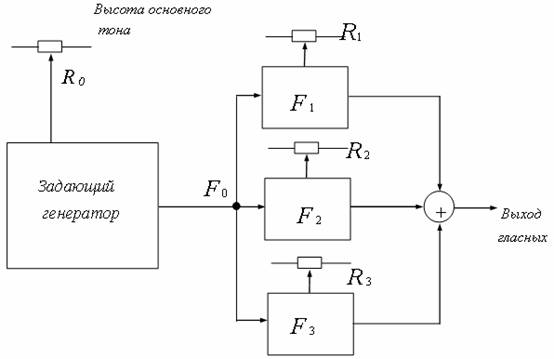
Рис. 8.11 - Структурная схема формантного синтезатора гласных звуков
Гораздо сложнее формировать согласные звуки. Согласные - звуки речи, при произношении которых в полости рта образуются преграды для выдыхаемого воздуха:
- взрывные - при полном смыкании органов речи (п, т, к);
- фрикативные - образуется щель (с, ф, х);
- носовые согласные (н, м);
- аффриката - согласный звук, представляющий слитное сочетание (ч -тщ, ц -тс).
Чтобы расширить диапазон синтезатора (рис. 8.11), необходимо ввести источник шума для формирования взрывных и фрикативных согласных, а также аналог носовой резонансной полости, имитирующий носовые согласные. Структура этого расширенного формантного синтезатора приведена на рис. 8.12.
Структура полного формантного синтезатора речи (рис. 8.12) усложняется не очень сильно, по сравнению с синтезатором гласных звуков. Значительно увеличилось количество регулировок в схеме. Три из них служат для управления амплитудой фрикативных, гласных и носовых звуков, один - для регулировки высоты тона, а пять остальных - для регулирования частот различных резонансов. Применив в качестве устройства управления регуляторами микропроцессор с соответствующим количеством портов ввода-вывода мы получим устройство, способное производить все необходимые регулировки со скоростью, достаточной для приемлемого приближения к нормальной речи человека.
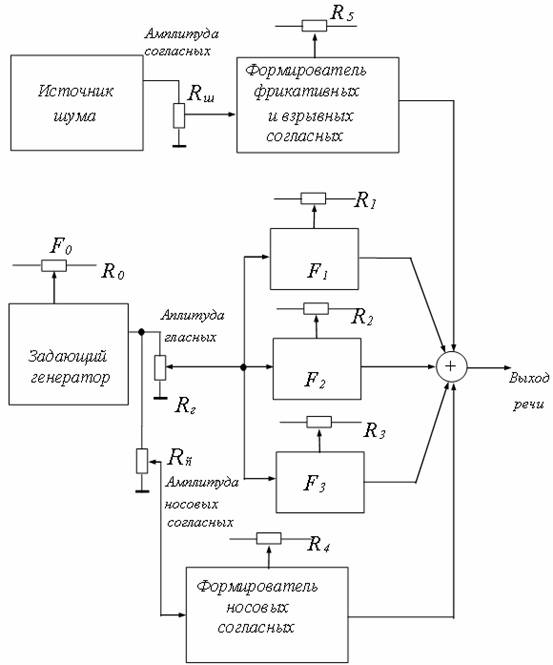
Рис. 8.12 - Структурная схема формантного синтезатора речи
Естественно, что чем больше обращений к справочной таблице будет производить микропроцессор по каждой фонеме, тем большей плавностью будет отличаться синтетическая речь и тем ближе она будет к естественной человеческой речи.
Преимущество формантного метода синтеза - в его универсальности (т.е. возможность иметь неограниченный словарь) так как здесь речь создается из отдельно генерируемых звуков. Правильно расставив звуки, можно произнести любое слово.
Универсальность эта, однако, не дается бесплатно - за нее приходится расплачиваться ухудшением разборчивости речи. Без соответствующей подготовки трудно понять, что говорит синтезатор.
Дополнительные трудности при реализации большого словаря создает множество имеющихся исключений из правил написания и произношения слов. Если проанализировать одну и ту же фонему, встречающуюся в различных словах, то может оказаться несколько вариантов произношения данной фонемы. Вариации произносимых фонем называют аллофонами. Аллофоны подразделяются на комбинаторные и позиционные. Комбинаторные оттенки обусловлены соседством данной фонемы с другими фонемами и являются следствием наложения одного звука на другой. Позиционные оттенки обусловлены положением фонемы в слове или фразе по отношению к ударному слогу, концу и началу слова и т.д.
Учет всех факторов позволяет оценить общее число аллофонов, необходимое
для качественного синтеза русской речи. Общее число аллофонов гласных ![]() и согласных
и согласных ![]() .
.
Другой класс лингвистических понятий, учет которых исключительно важен при создании систем синтеза речи, составляют интонация и ударение. Физически интонация и ударение реализуются совокупностью акустических средств (просодикой), к числу которых относятся:
1) мелодика (движение частоты основного тона голоса);
2) ритмика (текущее изменение длительности звуков и пауз);
3) энергетика (текущее изменение силы звука).
Этап преобразования печатного текста в последовательность фонем должен сопровождаться выделением информации, необходимой для задания просодических характеристик синтезируемых речевых сигналов.
Для этой цели текст анализируется и по определенным правилам разбивается на основные единицы: фраза, синтагма, акцентная группа, фонетическое слово.
Эти единицы маркируются, соответственно фразовым, синтагматическим, групповым и словесным ударениями. Каждой синтагме присваивается один из возможных интонационных типов. Это завершенность, незавершенность, вопрос или восклицание.
Под синтагмой понимают слово (или группу слов), представляющее собой цельную синтаксическую интонационно-смысловую единицу.
Например:
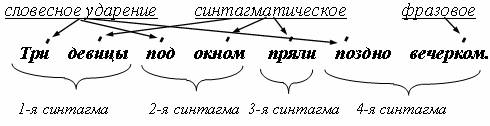
Таким образом, в качестве входной информации текстового сообщения используется размеченный орфографический текст, т.е. обычный орфографический текст с проставленными знаками словесного, синтагматического и фразового ударений.