Алгоритм TD PSOLA (алгоритм синхронного накладывающегося окна с равномерным шагом) реализует модификацию речевого сигнала во времени времени, при использовании готовой дифонной базы данных. Из-за высокой вычислительной эффективности это приносит большой прогресс в синтезе текста в речь.
Синтез, основанный на TD PSOLA алгоритме, реализуется склейкой фонем, выделенных из человеческого речевого сигнала, разделенного на сегменты, названные дифонами. Мы в состоянии достигнуть синтезируемой речи, связывая эти сегменты. Кроме того, алгоритм позволяет, изменить скорость и продолжительность речи. Для периодических сигналов мы в состоянии изменить частоту, изменяя расстояние между периодами, и продолжительность, добавляя или опуская некоторых из них. Для непериодических сигналов мы только в состоянии изменить продолжительность специфических частей сигнала.Если бесконечный периодический сигнал, мы в состоянии сдвинуть на период от оригинального T0 до необходимого T, суммируя оконные данные Si(n), порожденный из X (n) сигнала.
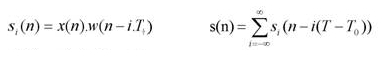
Образцы Si (n) отличаются от ноля только на интервале, зависящем от F фактора восстановления, определенного как отношение размера L окна анализа k W(n) шагу периода.
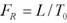
Практически, мы выбираем F = 2, когда спектр si (n) сигналa приближается к спектру S(n) сигнала. Тогда процесс связи изменяет шаг, не затрагивая частоты формант. Использование различного фактора восстановления вызывает сильную деградацию синтезируемой речи, например бульканье или эффект металлического голоса.
Концептуальная схема дифонного синтезатора показана на рисунке 1. Есть три основных фазы синтеза. В первой фазе необходимо, создать базу данных, чтобы сохранить образцы естественного языка. Тогда, специфические сегменты корпуса, такие как фонемы, дифоны, периоды, и т.д. автоматически будут определены. Этот шаг сделан специальным программным обеспечением, частью нашей системы. Отметки времени для специфических сегментов корпуса, продукции программного обеспечения, сохранены в базе данных.
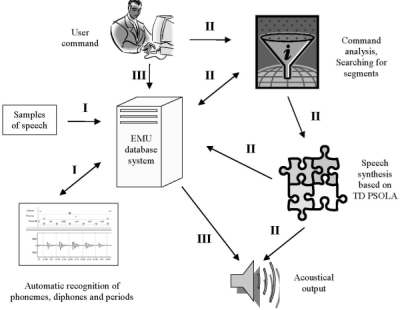
Рис. 1: Концептуальная схема дифонного синтезатора
Вторая фаза - речевой синтез. Пользователь пишет текст, который хочет синтезировать с желательной частотой. Во-первых, текст будет проанализирован. База данных просматривается и согласно правилам языка, выбираются соответствующие дифоны. Наконец, они синтезируются согласно TD PSOLA алгоритму. Синтезируемая речь сохраняется в базе данных для дальнейшей обработки (третья фаза), или может обрабатываться устройством продукцирования.
4.1 Шаблон базы данных
Первый шаг в процессе создания базы данных - создание шаблона базы данных. Наша БД была создана в Редакторе Шаблона иерархических БД. Было выбрано три основных иерархических уровня: фонема, дифон и уровень периода.
Иерархическая аннотация уровней - процесс ассоциации иерархических отметок времени с акустическим сигналом. После окончания загрузки речевых образцов в базу данных, могут быть сделаны аннотация фонемы и дифоны уровня. В уровне периода периодические части сигнала были разделены на периоды. Проблема деления непериодических частей была решена весьма просто. Они были разделены на секции, во время того, когда создаются периодические секции. Секции в иерархических уровнях отмечены в компьютерном алфавите SAMPA.
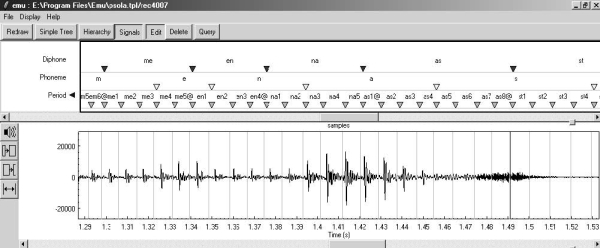
Рис. 2: Аннотация иерархических уровней в речевом сигнале
Оба частичных алгоритма TD PSOLA осуществлены на языке TCL, который позволяет программисту управлять библиотеками ядра иерархической БД.
Согласно входным параметрам (дифон разделенный на периоды или непериодические сегменты, число сегментов, которые надо добавить или пропустить) произведен новый список сегментов. Если пользователь хочет увеличить продолжительность синтезируемого текста, специфические периоды (отмеченные) дублируются в новом списке. С другой стороны, если он хочет сократить продолжительность синтезируемого текста, специфические периоды в новом списке пропускаются.
Входные параметры алгоритмов - отметки времени для синтезируемого дифона, тип окна анализа, и коэффициент для относительного изменения шага. В течение каждого периода для дифона:
o ищется максимальная ценность амплитуды, после чего отмечается соответствующее время t
o отмечается сегмент в интервале времени
Поскольку длина извлеченных сегментов 2.T0, то необходимо, использовать 50%-ое наложение, чтобы достигнуть оригинальной продолжительности речи. Использование большего наложения обеспечивает увеличение шага. С другой стороны, меньшее наложение вызывает уменьшение шага.
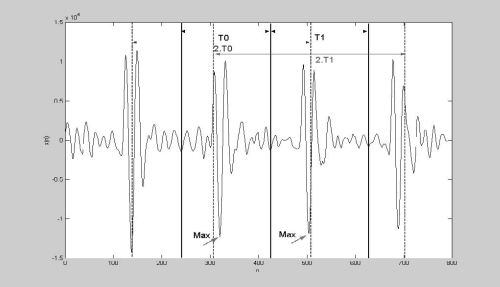
Рис. 3: TD PSOLA - извлечение сегментов
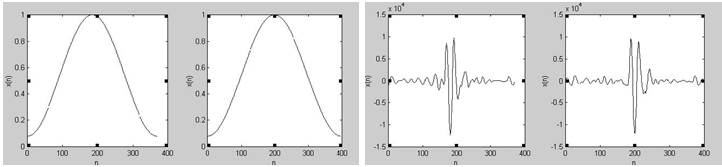
Рис. 4: a, b) окна Hammings'а, соответствующие извлеченным сигналам; c, d) Извлеченные сигналы после оконирования
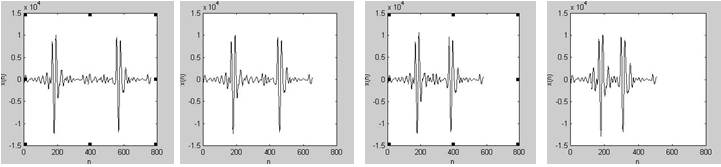
Рис. 5: a) Суммированные сигналы без наложения; b, c, d) Сигналы с наложением от 0,7. T, 0,5. T, 0,3. T
Речь, синтезируемая TD PSOLA алгоритмом, весьма понятна, однако человеческое ухо чувствует это как синтетическое. Кроме того, большое удлинение синтезируемого речевого сигнала, при добавлении периодов, вызывает эффект эха. Сокращение сигнала не вызывает неблагоприятное слуховое восприятие. Однако, опускание большого количества периодов в дифоне, вызывает потерю речевого информационного содержания. TD PSOLA алгоритм был осуществлен в TCL языке. В результате принадлежности группе интерпретируемых языков TCL является относительно медленным. Даже при том, что программа была оптимизирована, синтез предложения длится несколько секунд. Я предполагаю, что использование собранного языка например. C ++, объединенный с ростом работы аппаратных средств в будущем, мог сократиться на сей раз к сотням миллисекунд.. Бесспорныим преимуществом языка TCL остается возможность перенесения исходников TCL между операционными системами. Фундаментальной проблемой иерархической БД является большое количество ошибок в исходном тексте TCL. Много функций не работают должным образом, и некоторые из них, в особых случаях, не работают вообще. Поэтому некоторые из них должны были быть недавно осуществлены. Несмотря на то, что речь, созданная связью дифонов, превосходит связь фонем, этот подход не позволяет синтезировать высококачественную человеческую речь. Это вызвано тем фактом, что ни один, из огромного уоличества дифоннов в базе данных не в состоянии покрыть большое разнообразие человеческой речи. Использование многополосного пересинтеза Возбуждения на базе данных, могло бы немного улучшить качество речи, но ясно сформулировать задачи синтеза, остаются видением для будущего.
[1] Dutoit, T.: An Introduction to Text-to-speech Synthesis, http://tcts.fpms.ac.be/synthesis
[2] Cassidy, S., Harrington J.: Multi-level Annotation in the EMU Speech Database Management System, Speech Communication 33, 2002
[3] Dutoit, T., Leich, H.: MBR PSOLA TTS Synthesis Based on an MBE Re-Synthesis of the Segments Database, http://tcts.fpms.ac.be
[4] Syrdal, A. and Col.: TD PSOLA Versus Harmonic Noise Model In Diphone Based Speech Synthesis, http://www.zippy.ho.att.com