
The logic programming have been forgotten in the light of everybody's craze for object oriented programming languages, nevertheless there are specific range of tasks, which may be solved only with the help of logic programming languages. Development of hardware have come up to difficult overcoming barrier and it is not enough bide some time or buy more expensive equipment, for getting more high-end system. It would be more effective to increase speed at the expense of cluster’s, multiprocessor’s organization and enhancement. But support of such systems with the help of software product is rather limited. This work is devoted to extension of capabilities use of distributed system in logical programming.
During the seventies logical programming and database have been developed simultaneous. Prolog – the most popular programming language in logic – have appeared as a result of reduction of more general methods theorem proving for achievement of facilities of effective programming. By analogy relational data model sprang up in the issue of reduction of complex hierarchical and network model for support capacity nonprocedural handling of multiple data. During the seventies and at the beginning of the eighties prolog and relational databases received wide spreading not just in academic and scientific environment, but in business world too.
One of the most important questions by construction computer systems is increment of speed. But to reach high speed is possible only in two ways: extensive (improvement of architectures, processors, increment of clock frequency) or intensive (optimization, code ejection, paralleling). Always to refresh and to buy new expensive equipment is less profitably, then to buy software which works more effective and more fast on any equipment that you have. Paralleling during the process of translation offers advantages in program’s working, in speed of executing code. Development of hardware reached difficult overcoming barrier. As the practice indicates – receiving more high-ended systems, relatively existing, in close perspective is hardly probably. There are always tasks for which it’s not enough efficiency of one system.
The program on prolog language consists of set of facts, defined relations between database objects (facts) and set of rules (patterns of relations between the database objects). For program working user have to enter request – the set of terms, everyone of which ought be true. Facts and rules from database are used for definition the type of substitutions for variables in request (so called unification), which conform with the information in database.
Facts are written in the form of predicates. Lets input some notions for the predicate description. Closure – sentence which consists of head and body. Head contains predicate and arguments. The body contains of sets of characters (including null). Predicate is closures ensemble with the same head and the set of arguments.
The problem of integration of different programming paradigms follows from the structure of the program on prolog language. Logic paradigm on the one hand, and for example, functional – on the other. The solution of such integration task, and the process paralleling prolog program itself, may be built by one of the next schemes, which are singled out starting from degree of seamlessness of this process wrt the program text:
Usage of any given principles demands the translator language modification. In case of full-fledged seamlessness there is necessity of internal database modification and translation algorithms. The intermediate seamlessness demands extension of language dialect and putting into operation secondary predicates, which command simultaneous computing. In case of absence of seamlessness there is necessity in rework of interface for integration of translator with modules written on other programming languages, which will be explicitly realize parallelism (for example code insertions on language C with usage MPI).
From the user’s point of view, the most optimal is realization of mechanism of full-fledged seamlessness. It makes possible for user to write the program code without knowing secondary extensions or off-site languages. This problem is especially actual in connection with appearance of great number users, who don’t possess extensive skills in programming.
In total during writing language translator of logic programming by principle of full-fledged seamlessness we may sign out some possible types of paralleling:
Among existing realizations AND-parallelism realized in such translators like Parlog (creator Parallel Logic Programming Ltd.), OR-parallelism in translators like «Actor prolog» (creator Morozov Ŕ.Ŕ.) and in YAP Prolog (creator LIACC/Universidade do Porto). Besides, there are other prolog realizations, both supporting paralleling and without.
Building of translator with paralleling possibility by principle of full-fledged seamlessness with using OR-parallelism is possible with the help of code modification of existing translator, or with the help of new realization. Usage of modification of existing translators is connected with such obstacle negotiation like modification of internal forming data structure, also it is connected with existing code bases with the paralleling mechanism itself. To find the advantages in paralleling process the most reasonable way is to create new translator, with knowingly chosen principle of internal data presentation and relation translation code with paralleling code
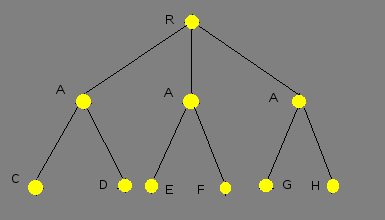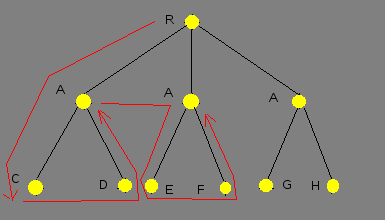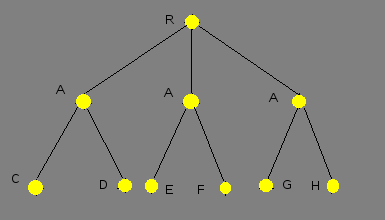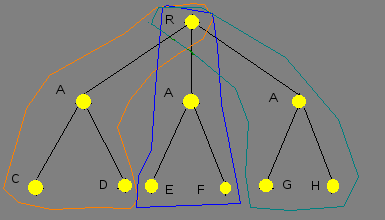
This work is devoted to studying OR-type. This type of parallelism occurs in case when one subgoal may be unified with some closure heads, and the bodies of those closures compute by different computation modules. In contrast to classical prolog type, where tree traversal carries out sequential (pic. 1).
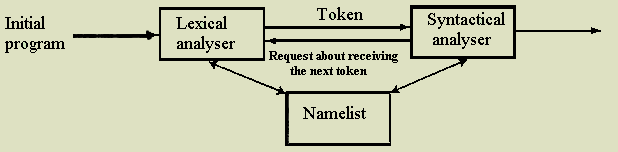
Lexical review corresponds the first translator’s phase. It’s main task is in partitioning of existing program code on ňîęĺíű, filling of namelist, comments cutting (in case if it is possible) and delivery the chain of ňîęĺíîâ on exit for syntactic analyser. When building namelist, lexical analyser delivers on exit the object’s code chain in those lists. The task of building lexical analyser becomes easier with using instrument Flex. It makes possible to build lexical analyser almost like grammar language indication in the form of regular expressions and actions with one or other classes singled out objects.
Let’s input the next denotations:
In case of sequential variant of lexical analyser general work time will be similar to the general processing time:
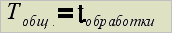
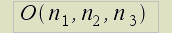
In parallel variant of lexical analyser general working time will consist of time of program partitioning, serialization received objects for transferring on net, data integration in unit, processing on every computation units itself, serialization of generated namelists, transferring them into central unit, integration and patching of separated namelists in ultimate table:
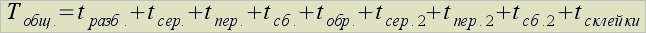
The operation of patching of received namelists in one table will take the greatest amount of time. Time complexity of given operation should be estimated the next way:
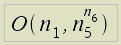
That’s why it is reasonable to realize sequential variant of lexical analyser with the help of instrument Flex. The next stage of program processing is syntactical analysis. On this stage the syntactical program rightness is testing and internal data structures with facts and initial program’s rules are forming. It is reasonable to form two tables on the stage of syntactical analysis: the facts table and rules one. Such a partitioning will make possible to simplify the forming of searching tree on the stage of unification. There is also have to be formed matrix with information about relations of dependence between the program objects on the stage of syntactical analysis. It will make possible to form the fetch from base of facts and rules only with necessary information, which would be sent to nodes together with the information about request quickly on unification stage.
There are many different approaches (both software-based and hardware-based) to paralleling realization. Successful usage of those approaches will make possible to solve major problem with more high intensity, but to spend acceptable period of time, during which the solution’s urgency keeps.
The main problems, staying in prolog-system’s realization with using OR-parallelism way, are in effective realization of interprocess communication, data exchange. Besides, there is necessity of optimization of internal presentation of data for communication procedure reduction. The scheduler should be realized for solving the tasks of primary program partitioning on parallelized sections and coordination of separate processes work.
In realization of system it is reasonable to use distributed computing on cluster system, as far as it is one of the most scaled paralleling schemes of computational process.
At the moment work is on phase of active development. The most probable time of ending is December,2008. Then the final results one may receive from author or supervisor of studies.