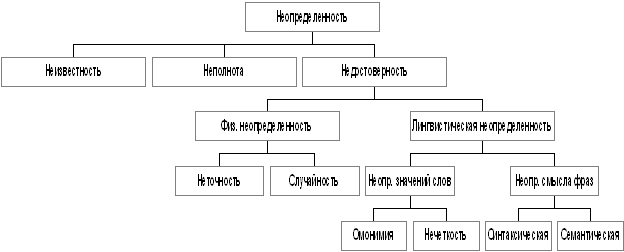
Рис. 1. Классификация видов неопределенности
нечеткость классификации отдельных сторон текущего финансового положения корпорации или состояния рынка ценных бумаг.
Первоначальный источник - http://www.vmgroup.ru/download/publications/ (ZIP-file 3.2 Mb)
Автор – Недосекин А.О. д.э.н., к.т.н.
Итак, причины, определяющие уровень эффективности функционирования корпорации, частично находятся за пределами корпорации и не подлежат тотальному контролю со стороны этой корпорации. Такое положение дел вызывает феномен неопределенности. Ниже приведена классификация видов неопределенности (рис. 1). Если спроецировать эту классификацию на специфику финансовых решений, то мы можем обозначить два укрупненных вида неопределенности:
Рис. 1. Классификация видов неопределенности
нечеткость классификации отдельных сторон текущего финансового положения корпорации или состояния рынка ценных бумаг.
Неопределенность – это неустранимое качество рыночной среды, связанное с тем, что на рыночные условия оказывает свое одновременное воздействие неизмеримое число факторов различной природы и направленности, не подлежащих совокупной оценке. Но и даже если бы все превходящие рыночные факторы были в модели учтены (что невероятно), сохранилась бы неустранимая неопределенность относительно характера реакций рынка на те или иные воздействия.
Рыночная неопределенность законно считается «дурной» (научный термин), т.е. не обладающей статистической природой. Экономика непрерывно порождает изменяющиеся условия хозяйствования, она подчинена закономерностям циклического развития, при этом хозяйственные циклы не являются стопроцентно воспроизводимыми, т.к. циклическая динамика макроэкономических факторов находится в суперпозиции с динамикой научно-технического прогресса. Возникающая в результате этой суперпозиции рыночная парадигма является уникальной. Из всего сказанного следует, что не удается получить выборки статистически однородных событий из их генеральной совокупности, наблюдаемых в неизменных внешних условиях наблюдения. То есть классически понимаемой статистики нет.
Во всех определениях термина «статистика» есть общее зерно, которое собственно, и относится к статистике в самом общем смысле слова, и это зерно в следующем. Мы имеем некий набор наблюдений по одному объекту или по совокупности объектов. Причем мы предполагаем, что за случайной выборкой наблюдений из гипотетической их генеральной совокупности кроется некий фундаментальный закон распределения, который сохранит свою силу еще на определенный период времени в будущем, что позволит нам прогнозировать тренд будуших наблюдений и расчетный диапазон отклонений этих наблюдений от расчетных ожидаемых трендовых значений.
Если мы договорились, что все наблюдения совершались в неизменных однотипных внешних условиях и/или наблюдались объекты с одинаковыми свойствами по факту, например, их появления по одной и той же причине, то мы оцениваем и подтверждаем искомый закон распределения частотным методом. Разбивая весь допустимый диапазон наблюдаемого параметра на ряд равных интервалов, мы можем подсчитать, сколько наблюдений попало в каждый выбранный интервал, то есть построить гистограмму. Известными методами мы можем перейти от гистограммы к плотности вероятностного распределения, параметры которого можно оптимальным образом подобрать. Таким образом, идентификация статистического закона завершена.
Если же мы имеем дело с «дурной» неопределенностью, когда у нас нет достаточного количества наблюдений, чтобы вполне корректно подтвердить тот или иной закон распределения, или мы наблюдаем объекты, которые, строго говоря, нельзя назвать однородными, тогда классической статистической выборки нет.
В то же время, мы, даже не имея достаточного числа наблюдений, склонны подразумевать, что за ними стоит проявление некоторого закона. Мы не можем оценить параметры этого закона вполне точно, но мы можем прийти к определенному соглашению о виде этого закона и о диапазоне разброса ключевых параметров, входящих в его математическое описание. И вот здесь уместно ввести понятие квазистатистики.
Квазистатистика – эта выборка наблюдений из их генеральной совокупности, которая считается недостаточной для идентификации вероятностного закона распределения с точно определенными параметрами, но признается достаточной для того, чтобы с той или иной субъективной степенью достоверности обосновать закон наблюдений в вероятностной или любой иной форме, причем параметры этого закона будут заданы по специальным правилам, чтобы удовлетворить требуемой достоверности идентификации закона наблюдений.
Такое определение квазистатистики дает расширительное понимание вероятностного закона, когда он имеет не только частотный, но и субъективно-аксиологический смысл. Здесь намечены контуры синтеза вероятности в классическом смысле - и вероятности, понимаемой как структурная характеристика познавательной активности эксперта-исследователя.
Также это определение намечает широкое поле для компромисса в том, что считать достаточным объемом выборки, а что – нет. Например, эксперт, оценивая финансовое положение предприятий машиностроительной отрасли, понимает, что каждое предприятие отрасли уникально, занимает свою рыночную нишу и т.д., и поэтому классической статистики нет, даже если выборка захватывает сотни предприятий. Тем не менее, эксперт, исследуя выборку какого-то определенного параметра, подмечает, что для большинства работающих предприятий значения данного параметра группируются внутри некоторого расчетного диапазона, ближе к некоторым наиболее ожидаемым, типовым значениям факторов. И эта закономерность дает эксперту основания утверждать, что имеет место закон распределения, и далее эксперт может подыскивать этому закону вероятностную или, к примеру, нечетко-множественную форму.
Аналогичные рассуждения можно провести, если эксперт наблюдает один параметр единичного предприятия, но во времени. Ясно, что в этом случае статистическая однородность наблюдений отсутствует, поскольку со временем непрерывно меняется рыночное окружение фирмы, условия ее хозяйствования, производственные факторы и т.д. Тем не менее, эксперт, оценивая некоторое достаточно приличное количество наблюдений, может сказать, что «вот это состояние параметра типично для фирмы, это – из ряда вон, а вот тут я сомневаюсь в классификации». Таким образом, эксперт высказывается о законе распределения параметра таким образом, что классифицирует все наблюдения нечетким, лингвистическим способом, и это уже само по себе есть факт генерации немаловажной для принятия решений информации. И, раз закон распределения сформулирован, то эксперт имел дело с квазистатистикой.
Понятие квазистатистики дает широкий простор для применения нечетких описаний для моделирования законов, по которым проявляется та или иная совокупность наблюдений. Строго говоря, не постулируя квазистатистики, нельзя вполне обоснованно с научной точки зрения моделировать неоднородные и ограниченные по объему наблюдения процессы, протекающие на фондовом рынке и в целом в экономике, невозможно учитывать неопределенность, сопровождающую процесс принятия финансовых решений.
Если соотносить вероятностные, нечетко-множественные и экспертные описания применительно к эффективности решения финансовых задач, то можно использовать схему рис. 2. Видно, что по мере усиления неопределенности классические вероятностные описания уступают место, с одной стороны, субъективным вероятностям, основанным на экспертной оценке, а, с другой стороны, вероятностям, определенным не количественно, а качественно (приблизительно). При этом точечные оценки вероятностных распределений замещаются интервальными (для экспертных методов) и треугольно-нечеткими (для методов теории нечетких множеств).
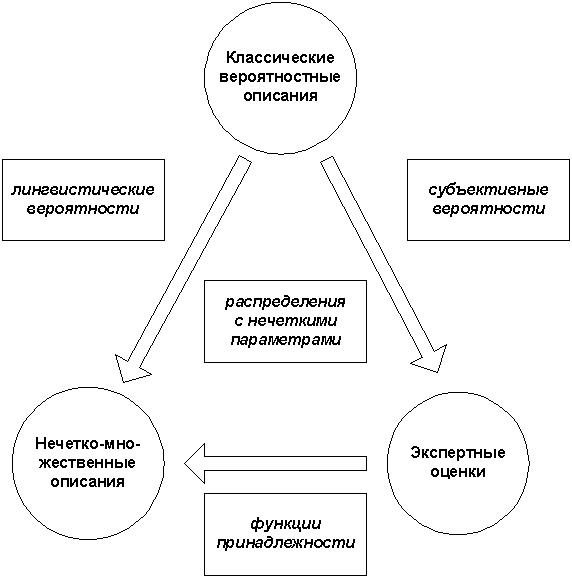
Рис. 2. Соотношение классических, экспертных и нечетко-множественных вероятностных описаний
Если поток исходных данных математической модели наблюдается как статистика, то нет ничего лучше как исследовать эту статистику на основе вероятностных моделе. Но если статистики нет, эксперт встает перед выбором:
· совсем отказываться от применения вероятностей при моделировании (оставаясь, например, в границах интервальных подходов, которые представляют собой одну из разновидностей экспертных методов). Эксперт предполагает, что наблюдаемый параметр может произвольным образом колебаться в пределах некоторого интервала вещественной оси. И все свои последующие выводы эксперт делает на основе этой интервальной оценки;
· вводить в модель субъективные (аксиологические) вероятности и вероятностные распределения. Эти вероятностные формализмы не имеют частотного смысла, а представляют собой либо результат виртуального пари по Cэвиджу, либо вероятность относительно свидетельства в смысле Кайберга, либо точечную оценку, основанную на принципе максимума энтропии Гиббса-Джейнса . Отдельно встает вопрос об обосновании выбора этих оценок, которое производится в рамках специализированной экспертной модели;
· учитывать неопределенность с применением нечетких формализмов тремя путями:
· а) переходить от классических вероятностных распределений к вероятностным распределениям с нечеткими параметрами (подробно эта процедура излагается в приложении П1.8 к настоящей диссертационной работе);
· б) замещать количественные вероятности качественными (лингвистическими в смысле Заде;
· в) распознавать состояния финансовых систем с использованием нечетких классификаторов.
Во всех трех случаях ключевым модельным формализмом является функция принадлежности нечеткого подмножества лингвистической переменной, заданной на соответствующем вещественном носителе.
Продемонстрируем на простейшем примере, как эволюционирует модельное представление данных при переходе от экспертных оценок к нечетко-множественным описаниям. Пусть некоторому экспертному сообществу, в которое входит N экспертов, предлагается сопоставить количественные значения наблюдаемого параметра Х и его качественное описание – нечеткое подмножество «Высокий уровень Х» лингвистической переменной «Уровень фактора Х», для которой параметр Х является носителем. Всего предполагается классификация носителя Х по пяти уровням: {Очень низкий, Низкий, Средний, Высокий, Очень высокий}.
Результатом опроса является N интервалов вещественной оси [ai, bi], i =1..N. Определим А = mini{ai}, B = mini{maxi(ai), mini(bi)}, C = maxi{maxi(ai), mini(bi)}, D = maxi{bi}. Тогда четыре пары чисел – (A,0), (B,1), (C,1), (D,0) - являются множеством вершин трапециевидной функции принадлежности (рис. 3).
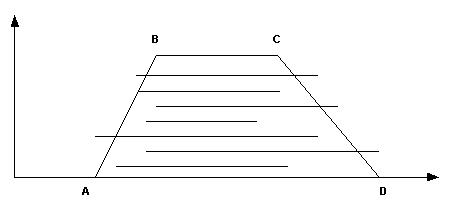
Рис. 3. Функция принадлежности, построенная по результатам экспертного опроса
Наклонные ребра функции вида рис. 3 могут быть и нелинейными, если принять во внимание неравномерность расположения экспертных интервалов. Однако, в условиях дефицита экспертных суждений при ограниченной их надежности, целесообразнее использовать линейную модель снижения уверенности по мере расширения интервала достоверности.
Если функция вида рис. 3 определена, и аналогичная модель построена для низких уровней фактора X, то остальные три состояния параметра (очень низкое, среднее и высокое) описываются функциями принадлежности, которые являются композициями двух уже построенных. Например (рис. 4), очень высокий уровень параметра Х описывается трапециевидной функцией, у которой левое наклонное ребро равно единице минус функция принадлежности состояния «высокий уровень Х», а правого наклонного ребра просто нет (вернее, оно имеет координаты (¥, 1), ((¥, 0)). При таком построении обеспечивается непротиворечивость классификации.
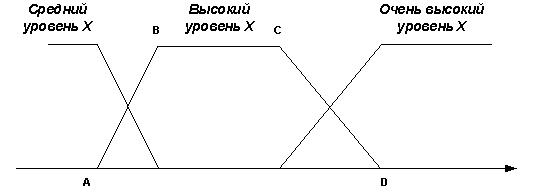
Рис. 4. Построение двух функций принадлежности на основе исходной функции
Таким же образом определяются все недостающие функции принадлежности, и в результате мы получаем пятиуровневый классификатор параметра Х.
Особого внимания заслуживает вопрос, как производить уточнение полученных нечетких формализмов на основе результатов математического моделирования финансовых систем. Осуществляя такое уточнение, необходимо принимать во внимание ряд моментов:
· шкалирование (лингвистическая классификация) всегда производится относительно ряда значений параметра, измеренных примерно в один и тот же период времени (вертикальный принцип) по ряду наблюдаемых одновременно финансовых систем;
· полученная на одном интервале времени лингвистическая интерпретация результатов может претерпеть коррекцию в будущем. Эта коррекция может быть обусловлена, например, сменой макроэкономической парадигмы в стране, где производится наблюдение. Например, Россия первой половины 90-х годов прошлого века несопоставима по наблюдаемым параметрам с Россией начала нынешнего века;
· при уточнении нечетких параметров модели возникает механизм обратной связи, когда вновь появляющиеся эмпирические данные вызывают необходимость повторной лингвистической интерпретации данных.
В целом, вопрос о технологиях лингвистической интерпретации экономических данных, с учетом фактора обратной связи, подлежит дополнительному исследованию, предмет которого выходит за рамки настоящей диссертационной работы.
Сделаем ряд замечаний относительно существа финансового риск-менеджмента. Под риском мы здесь понимаем возможность финансовых потерь, вытекающая из специфики тех или иных явлений природы и видов деятельности человека.
Классификационная система рисков включает в себя группы, виды, подвиды и разновидности рисков . В зависимости от возможного результата (рискового события) все риски подразделяются на чистые (с обязательно нулевым результатом) и спекулятивные (где возможен как положительный, так и отрицателльный исход операции). Финансовые риски (предмет собственно финансового риск-менеджмента) являются спекулятивными. Они входят в состав коммерческих рисков (опасность потерь в результате финансово-хозяйственной деятельности. При этом чистые риски входят составляющей коммерческого риска на уровне прогнозных сценариев неблагоприятного развития событий (климатические катаклизмы, забастовки, техногенные катастрофы, криминальные факторы и т.д.).
Сугубо финансовые риски подразделяются на риски, связанные с покупательной способностью денег (инфляционные, валютные риски и риски ликвидности) и на инвестиционные риски (риски упущенной выгоды, риски снижения доходности и риски прямых финансовых потерь). В свою очередь, на низовом уровне иерархии инвестиционных рисков находятся процентные риски, кредитные риски, биржевые риски, селективные риски и риски банкротства.
Каждый из выделенных видов финансового риска имеет свою специфическую процедуру управления. Например, чистые риски подлежат страхованию, а инвестиционные риски часто анализируются на основе дерева вероятностей . Но во всех случаях базовым подходом в оценке рисков в нынешнем финансовом менеджменте является использование точечных вероятностей и вероятностных распределений сценариев возможных событий, влияющих на финансовый результат.
О проблемах, связанных с использованием вероятностей в риск-менеджменте, написано довольно много. Отказ от классического понимания вероятности и использование субъективно-аксиологической вероятности есть не что иное как стратегическое отступление науки перед лицом дурной неопределенности. И если раньше мы имели дело в ходе исследования только с финансовой моделью хозяйствующего субъекта, то теперь мы должны верифицировать вероятностную модель, предложенную экспертом, т.е. исследовать познавательную активность и самого эксперта. Вероятности не дают никакой информации о том, как они получены, если не предваряются дополнительными качественными соображениями о принципе вероятностной оценки. Одним из таких принципов, продуктивно использовавшихся до сих пор, является принцип максимума правдоподобия Гиббса-Джейнса, который в настоящий момент подвергнут обоснованной критике в связи с тем, что принцип максимума энтропии не обеспечивает автоматически монотонности критерия ожидаемого эффекта. Принцип генерации условных вероятностных оценок Фишберна выдвигает лишь идею назначения точечных оценок вероятностей, удовлетворяющих критерию максимума правдоподобия, однако не существует доказательств полноты выбранного поля сценариев.
Все идет к тому, что сценарно-вероятностные методы анализа риска начинают себя понемногу изживать. На смену им приходят нечетко-множественные подходы, которые, с одной стороны, свободны от вероятностной аксиоматики и от проблем с обоснованием выбора вероятностных весов, а, с другой стороны, включают в себя все возможные сценарии развития событий. Так, треугольно-нечеткое число включает в себя все числа в определенном интервале, однако каждое значение из интервала характеризуется определенной степенью принадлежности к подмножеству треугольного числа. Такой подход позволяет генерировать непрерывный спектор сценариев реализации по каждому из прогнозируемых параметров финансовой модели.
Наконец, нечетко-множественный подход позволяет учитывать в финансовой модели хозяйствующего субъекта качественные аспекты, не имеющие точной числовой оценки. Оказывается возможным совмещать в оценке учет количественных и качественых признаков, что резко повышает уровень адекватности применяемых методик.
Несколько замечаний следует сделать относительно методов оценки риска в фондовом менеджменте. Классическая мера риска по Марковицу – это среднеквадратическое отклонение распределения доходности актива. Эта мера риска была подвергнута критике за то, что она с одинаковым безразличием учитывает риск как роста, так и падения актива, что в глазах инвестора есть два совершенно неравнозначных события. Из этого соображения возникал мера downside-риска, т.е. такого, который сопряжен лишь с падением цены актива ниже требуемого уровня. Одной из разновидностей downside-риска является широко применяемый в банковском риск-менеджменте показатель Value-at-Risk – статистическая оценка максимальных потерь за фиксированное время при заданном уровне доверительной субъективной вероятности. Проблема, как и везде, состоит в том, что оценка Value-at-Risk предполагает наличие достоверной оценки параметров распределения доходности портфеля. И с этой точки зрения оценка Value-at-Risk базируется на том же информационном контенте, что и классическая оценка риска по Марковицу.
Субъективный фактор в процессе принятия финансовых решений до сих пор не имел удовлетворительной теории для количественного оценивания. В то же время неопределенность, сопровождающая финансовые решения, постоянно рождает неуверенность принимающего эти решения лица, порождает риск неверной интерпретации исходной инвормации для принятия решения. И такую неуверенность уже давно следовало бы научиться количественно измерять.
Неуверенность ЛПР в своих оценках ситуации порождает качественные высказывания в терминах естественного языка. Например, рассматривая фундаментальные характеристики ценной бумаги, инвестор оценивает текущее значение показателя P/E (цена к доходам), которое равно 20. «Много» это или «мало», вот вопрос. На этом этапе инвестор может обратиться к финансовому консультанту.
Консультант, выступая как эксперт, первым делом должен построить гистограмму, где по оси Х отложены значения показателя P/E, а по оси Y – то, с какой относительной частотой выпадают те или иные значения показателя. Эксперт должен построить гистограммы в вертикальном и горизонтальном разрезах, т.е. как по секторам экономики, так и в различные периоды времени. Эксперт должен отметить, что доходность ценной бумаги состоит в обратном отношении к ее надежности, и зачастую люди покупают высококапитализированные компании, имея ввиду в первую очередь низкий риск дефолта, а во вторую очередь рассматривая уже соображения, связанные с доходностью. Что же до объективного уровня P/E, то все зависит от периода анализа. Например, для высокотехнологичных компаний США в 1999-2000 г.г. характерным уровнем P/E был уровень в несколько десятков единиц. Сегодня же типовое значение – 10-15, потому что произошла коррекция.
Поэтому, производя качественную классификацию уровня P/E, эксперт должен руководствоваться максимумом информации, относящейся к объекту оценки. И наиболее точным ответом на вопрос инвестора будет пятиуровневый классификатор, определенный на носителе P/E (подробно об этом формализме см. в разделе П1.10 приложения 1 к настоящей работе). Качество построенного таким образом классификатора существенно зависит от квалификации эксперта, потому что вполне формализованных методов перехода от набора гистограмм к классификатору не существует. Очень многое в этом смысле является предметом эвристики и интуиции. Некоторые простейшие приемы такого перехода мы можем здесь обозначить.
Пусть имеется унимодальная гистограмма фактора P/E для P/E>0 (рис. 5). По общим правилам статистики определим среднее значение m гистограммы и среднеквадратическое отклонение от среднего s. Построим набор из пяти узловых точек пятиуровнего классификатора по правилу
m1 = m - t1s,
m2 = m - t2s,
m3 = m + t3s,
m4 = m + t4s,
m5 = m + t5s, (1.1)
где ti – коэффициенты, в классической статистике являющиеся коэффициентами Стьюдента, а в квазистатистике выбираемые на основе дополнительных соображений. Для каждой узловой точки классификатора справедливо, что в ней уровень фактора P/E распознается, однозначно, со стопроцентной экспертной уверенностью. Например, точка m1 отвечает очень низкому уровню P/E.
Далее поделим каждый отрезок [mi, mi+1] на три зоны равной длины: зону абсолютной уверенности, зону пониженной уверенности и зону абсолютной неуверенности. Нанесем эти дополнительные точки на ось носителя P/E. Тогда можно в зоне уверенности принять соответствующую функцию принадлежности за 1, в зоне абсолютной неуверенности – за 0, а зону неуверенности описать наклонным ребром соответствующего трапециевидного нечеткого числа. Таким образом, первое приближение классификатора построено.
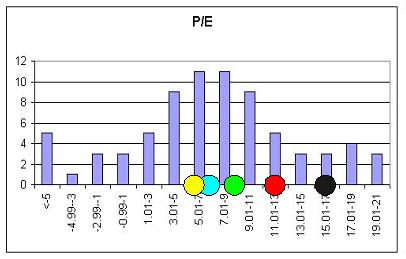
Рис. 5. Гистограмма фактора P/E и соответствующие узловые точки
В дальнейшем эксперт может, уточняя полученный классификатор на основании дополнительных соображений, управлять местоположением узловых точек классификатора и получать новые функции принадлежности.
Пусть теперь инвестор, получив экспертное заключение, созрел для того, чтобы принимать решение. Он говорит себе: «Сегодня у компании Х цена акций $20, а соотношение P/E составляет 41. Ее капитализация – 100 млрд долларов, однако я считаю, что компания все равно переоценена, и такой уровень P/E – слишком высокий. Для этой компании я считаю приемлемым диапазон P/E порядка 30-35. И даже если сегодня цена компании растет, я тем не менее нахожу, что этот рост ненадежен и может смениться спадом. Я буду покупать эти акции при целевой цене на уровне $15-$17, что соответствует моим ожиданиям».
Таким образом, инвестор произвел свою самостоятельную оценку ситуации и принял решение. При этом в основаниях этого решения мы можем увидеть:
· ожидания – связанные с перспективами роста данных акций;
· нечеткую классификацию, когда инвестор сопоставлял текущую капитализацию компании с ее P/E и производил анализ уровня показателя.
Все, что инвестор говорит на словах, он может вполне трансформировать в описания на языке математики. И тогда ожидания, предпочтения и нечеткие оценки, сделанные инвестором, явятся исходной инвформацией для моделирования предпосылок для принятия (непринятия) инвестиционного решения.
Оценивая акции, инвестор может производить и макроэкономические оценки, например, перспектив тех или иных отраслей или даже национальной экономики. Уже в том утверждении, что США проходят фазу рецессии, содержится огромное количество информации, которую необходимо учитывать для принятии решения. Подробно об этом говорится в главе 3 диссертации, а сейчас ограничимся тем замечанием, что рецессия ставит одни отрасли в привелегированное положение, а другие отрасли оказываются ущемленными. Значит, идет межотраслевое перераспределение инвестиционных рисков, которое надо иметь ввиду.
Инвестор, покупая или продавая акции, должен составить себе мнение о том, какой рынок сейчас одерживает победу – «медвежий» или «бычий». Это дает ему основания считать, «что на «медвежьем» рынке переоцененные активы, скорее всего, упадут, а недооцененные, если и упадут, то неглубоко. И наоборот: на «бычем» рынке недооцененные активы, скорее всего, возрастут, а переоцененные, если и возрастут, то несильно». Все, что отмечено курсивом в этих закавыченных предложениях, представляет собой предмет оценки инвестором текущего состояния рынка и его переспектив.
Таким образом, на примере инвестиционных решений, мы заключаем, что огромное количество информации содержится в трудноформализуемых интуитивных предпочтениях ЛПР. Если эти предпочтения и допущения ЛПР обретают вербальную форму, они сразу же могут получить количественную оценку на базе формализмов теории нечетких множеств и составить обособленный контент исходной информации в рамках финансовой модели. Мы можем назвать этот обособленный контент экспертной моделью.
Информация экспертной модели образует информационную ситуацию относительно уровня входной неопределенности финансовой модели. Она выступает как фильтр для исходных оценок параметров, преобразуя их из ряда наблюдений квазистатистики в функции принадлежности соответствующего носителя параметра тем или иным нечетко описанным кластерам (состояниям уровня параметра). Таким образом, от нечеткой оценки входных параметров после ряда преобразований мы можем перейти к нечетким оценкам финансовых результатов и оценить риск их недостижения в рамках принимаемых в плановом порядке финансовых решений.
©ДонНТУ, Приходченко Б.В.