Prolog — язык логического программирования. Логическое программирование, так же как и родственное ему направление — функциональное программирование, радикально отклоняется от основного пути развития языков программирования. Логическое программирование строится не с помощью некоторой последовательности абстракций и преобразований, отталкивающейся от машинной архитектуры фон Неймана и присущего ей набора операций, а на основе абстрактной модели, которая никак не связана с каким-либо типом машинной модели. Логическое программирование базируется на убеждении, что не человека следует обучать мышлению в терминах операций компьютера (на некотором историческом этапе определенные ученые и инженеры считали подобный путь простым и эффективным), а компьютер должен выполнять инструкции, свойственные человеку. В своем предельном и чистом виде логическое программирование предполагает, что сами инструкции даже не задаются, а вместо этого явно, в виде логических аксиом, формулируются сведения о задаче и предположения, достаточные для ее решения. Такое множество аксиом является альтернативой обычной программе. Подобная программа может выполняться при постановке задачи, формализованной в виде логического утверждения, подлежащего доказательству, — такое утверждение называется целевым утверждением. Выполнение программы состоит в попытке решить задачу, т. е. доказать целевое утверждение, используя предположения, заданные в логической программе.
Логическое программирование — это подход к информатике, при котором в качестве языка высокого уровня используется логика предикатов первого порядка в форме фраз Хорна. Логика предикатов первого порядка — это универсальный абстрактный язык предназначенный для представления знаний и для решения задач. Его можно рассматривать как общую теорию отношений. Логическое программирование базируется на подмножестве логики предикатов первого порядка, при этом оно одинаково широко с ней по сфере охвата. Логическое программирование дает возможность программисту описывать ситуацию при помощи формул логики предикатов, а затем, для выполнения выводов из этих формул, применить автоматический решатель задач (т. е. некоторую процедуру). При использовании языка логического программирования основное внимание уделяется описанию структуры прикладной задачи, а не выработке предписаний компьютеру о том, что ему следует делать. Другие понятия информатики из таких областей, как теория реляционных баз данных, программная инженерия и представление знаний, также можно описать (и, следовательно, реализовать) с помощью логических программ. Однако вернемся к языку Prolog: первая часть введения посвящена истории языка Prolog.
Разработка языка Prolog началась в 1970 году Аланом Кулмероэ и Филиппом Расселом. Их целью было создание языка, который мог бы делать логические заключения на основе заданного текста. Название Prolog является сокращением от "Programming in logic". Итак, Prolog, как язык, был разработан в Марселе в 1972 году. Предварительно на основе некоторого "принцип резолюции" Ковальского, сотрудника Эдинбургского университета, была создана модель, на основе которой и был разработан механизм логических выводов.
Первая реализация языка Prolog с использованием компилятора Никлауса Вирта "Algol-W" была закончена в 1972 году, а основы современного языка были заложены позднее, в 1973 г. Использование языка Prolog постепенно распространялось среди тех, кто занимался логическим программированием, в основном благодаря личным контактам, а не через коммерциализацию продукта. В настоящее время существует несколько различных, но довольно похожих между собой версий языка. Хотя стандарта языка Prolog не существует, однако версия, разработанная в Эдинбургском университете, стала наиболее широко используемым вариантом. Здесь надо отметить тот факт, что недостаток разработок эффективных приложений Prolog сдерживал его распространение вплоть до 1980 г.
Теория логического программирования со временем совершенствовалась. Существенный вклад в ее развитие внесла работа Р. Ковальского "Логика предикатов как язык программирования". В 1976 г. Ковальский и М. ван Эмден предложили два подхода к прочтению текстов логических программ — процедурный и декларативный. Оба этих подхода стали активно использоваться при написании программ на языке Prolog.
Только в 1977 году Д. Уоррен и Ф. Перейра создают в университете Эдинбурга интерпретатор/компилятор языка Prolog для ЭВМ DEC-10, тем самым переведя методы логического программирования в практическую плоскость. Позднее в 1980 году К. Кларк и Ф. Маккейб в Великобритании разработали версию Prolog для персональных ЭВМ.
Интересный факт: в октябре 1981 года мир облетела новость о японском проекте создания ЭВМ пятого поколения. В основу методологии разработки программных средств было положено логическое программирование. Целью проекта декларировалось создание систем обработки информации, базирующихся на знаниях, а главным средством реализации должен был стать именно язык Prolog.
В это же время (начало 1980-х годов) появляется множество коммерческих реализаций Prolog практически для всех типов компьютеров. К наиболее известным можно отнести "CProlog", "Quintus Prolog", "Silogic Knowledge Workbench", "Prolog-2", "Arity Prolog", "Prolog-86", "Тurbo Prolog" и др. В данной статье мы опирались на версию языка "SWI-Prolog".
Существует мнение, что Prolog — уже почти умерший язык, что он за небольшой промежуток времени (1970-1980-е годы) смог пройти весь жизненный цикл — от начальных разработок, стремительного повышения интереса со стороны узких специалистов, затем стремительный взлет популярности, падение интереса и почти полное забвение. Мнение вызвано тем, что такая судьба — обычное явление в мире информационных технологий, где новые, более совершенные, дидактически верные и теоретически более красивые языки программирования возникают каждый год и тихо умирают. Сторонники мнения аргументируют его тем, что структура Prolog-программ очень трудна для восприятия из-за того, что иногда невозможно визуально предугадать ход логического вывода — единственный предикат-факт, запрятанный где-то в конце текста программы, может направить работу в совершенно непредсказуемое русло. В некотором они правы: трудность сопровождения Prolog-программ и трудность мышления на Prolog для рядовых программистов оказались непреодолимыми препятствиями для его широкого распространения. Да и, конечно, во времена разработки Prolog ждали от него большего, но потом оказалось, что сам по себе язык программирования помочь в решении серьезнейших задач, например, связанных с принятием компьютером решений (machine reasoning), не может.
Но всё же язык Prolog используется и сегодня при решении целого класса достаточно специфических задач. Об этом — в следующей части.
У каждого из языков программирования есть свой круг задач, при решении которых он используется с наибольшей эффективностью. Для Prolog это задачи, связанные с разработкой систем искусственного интеллекта (различные экспертные системы, программы-переводчики, интеллектуальные игры). Он используется для обработки естественного языка и обладает мощными средствами, позволяющими извлекать информацию из баз данных, причем методы поиска, используемые в нем, принципиально отличаются от "традиционных".
Prolog нашел применение и в ряде других областей, например, при решении задач составления сложных расписаний. При этом он не является универсальным языком программирования и не предназначен, например, для решения задач, связанных с графикой или численными методами.
Prolog используется в различных системах, но обычно не в качестве основного языка, а в качестве языка для разработки некоторой части системы. Так Prolog достаточно часто используется для написания функций взаимодействия с базами данных.
Prolog используется при разработки расширеных поисковых систем, то есть систем, которые не просто озанимаются поиском текста (поиск текста — задача техническая, инженерная), но и играют роль некоторой "отвечающей системы" — программного комплекса, который умеет извлекать информацию (знания) из большой выборки текстовых файлов, а затем вести диалог с пользователем, отвечая (в обычном понимании этого слова) на вопросы посвященный этой теме). Почему в таком случае используется именно Prolog, а не какой-либо другой язык? Потому что именно он разрабатывался для задач, связанных с так называемым "искусственным интеллектом".
Также Prolog используется при написании новых специфичных языков программирования. Например, функциональный язык Erland постороен на основе Prolog. По сути, Erland является усовершенствованием Prolog для некоторых специфических целей, связанных с задами реального времени.
Некоторые приложения в таких областях, как экспертные системы, планирование, машинное обучение, так называемый "искусственный интеллект" игр, реализованы именно с помощью Prolog. Так что, несмотря на то, что сферы использования этого языка, хоть и не так велики и обширны, как сферы применения "традиционных" языков (C, Java и т.п.), представляют свой интерес.
Теперь же от вводных слов перейдем к описанию синтаксиса языка Prolog, чтобы понять его возможности и особенности (по сравнению с "традиционными" языками).
В этом разделе статьи речь пойдет о синтаксисе языка, то есть о совокупности правил написания различных элементов и предложений (синтаксических конструкций) данного языка программирования.
Так как синтаксис немного меняется от реализации к реализации, для начала сделаем небольшое "лирическое отступление" о реализациях языка Prolog, поскольку синтаксис меняется от реализации к реализации. Существует большое количество реализаций языка Prolog, как коммерческих, так и свободно распространяемых. Мы будем ориентироваться на SWI-Prolog (www.swi-prolog.org), разработанный в университете города Амстердам. Возможностей данной реализации вполне достаточно для первоначального знакомства с основами логического программирования. SWI-Prolog распространяется под лицензией GPL, что обеспечивает возможность его использования без нарушений чьих-либо коммерческих интересов. Эта версия языка Prolog доступна как пользователям ОС Linux, так и пользователям Windows. Теперь можно перейти собственно к описанию синтаксиса языка.
В отличие от других языков программирования Prolog не является универсальным языком программирования. Он ориентирован на решение задач с использованием исчисления предикатов. Напомним, что предикатом в логике называется понятие, определяющее предмет суждения (субъект) и раскрывающее его содержание.
Целью разработки языка Prolog было предоставить возможность задания спецификаций решения и позволить компьютеру вывести из них последовательность выполнения для этого решения, а не задание алгоритма решения задачи, как в большинстве изученных нами языков.
Язык Prolog, как интерпретатор, приглашает пользователя вводить информацию.
Пользователь набирает запрос или имя функции. Выводится значение (истина —
yes,
или ложь — no)
этого запроса, а также возможные значения переменных запроса, присвоение которых
делает запрос истинным (то есть унифицирует запрос). Если ввести символ ";",
тогда отображается следующий набор значений переменных, унифицирующий запрос,
и так до тех пор, пока не исчерпается весь набор возможных подстановок, после
чего Prolog печатает no и ждет следующего
запроса. Возврат каретки воспринимается как прекращение поиска дополнительных
решений.
Хотя выполнение программы на языке Prolog основывается на спецификации предикатов, оно напоминает выполнение программ на аппликативных языках LISP или ML Разработка правил языка Prolog требует того же рекурсивного мышления, что и разработка программ на этих аппликативных языках.
Язык Prolog имеет простые синтаксис и семантику. Поскольку он ищет отношения между некоторыми рядами объектов, основными структурами данных являются переменная и список. Правило ведет себя подобно процедуре, за исключением того, что концепция унификации более сложна, чем относительно простой процесс подстановки параметров в выражения.
Язык Prolog изначально призван оперировать не с числами, а с нечисловыми объектами и отношениями между ними. Например мы можем, что называется, "совершенно не стеснясь в выражениях", задать любое отношение из жизни:
street( saint-petersburg, nevskii).
street( moscow, arbat).
Как вы уже поняли отношение street( , ) задает отношение принадлежности
улицы к городу. Теперь мы можем задать системе Prolog вопрос, в каком городе
находится, к примеру, Невский проспект (nevskii). Причем сделаем мы это вполне ясным образом:
?- street( X, nevskii).
Система Prolog конкретизирует переменную X и выдаст ответ
X = saint-petersburg.
Но это еще не все: если Невский проспект есть и в каком-нибудь Бобруйске, и это отношение мы так же задали:
street( bobruisk, nevskii).
То в ответе на наш вопрос система Prolog укажет оба города:
X = saint-petersburg;
X = bobruisk;
Таким образом, не написав никакой формализации определения объектов "город", "улица" и принадлежности одного другому мы смогли получить ответ на вопрос об отношении между этими объектами. Если бы мы захотели написать программу, реализующую то же самое на каком-нибудь "традиционном" языке программирования, мы бы не смогли обойтись без таких конструкций, как цикл и условный оператор.
Подведём небольшой итог: в системе Prolog мы можем задавать любые отношения между объектами, а потом и вопросы с неопределенными переменными и отношениями, введенными ранее в программе, и система Prolog будет конкретизировать переменные и выдавать все возможные значения при использовании которых, вместо переменных наш запрос будет верным. Программа на языке Prolog состоит из предложений, которые относятся к трем типам: факты, правила и вопросы.
Далее перечислим некоторые другие основополагающие факты, связанные с программированием на языке Prolog:
После того, как вы получили самые минимальные знания о Prolog, самое время попробовать что-то на практике. Напомним, что мы рассматриваем интерпретатор "SWI-Prolog".
Интерактивная среда разработки "SWI-Prolog" была разработана в Swedish Institute of Computer Science, отсюда происходит и название этой версии. В этой части мы в двух словах расскажем, как пользоваться этим интерпретатором.
Открыв окно интерпретатора, вы увидите несколько строк о данном продукте, а после них и своеобразное приглашение задать вопрос Prolog-системе.
| ?-
Чтобы выйти из программы, наберите
halt.
Не забудьте про точку. Но сейчас нас интересует, как же данный интерпретатор работает с программой на Prolog. Будем считать, что программа на Prolog у нас уже имеется (например, это наши утверждения о принадлежности улиц городам). Программу можно набрать в любом текстовом редакторе, не добавляющем в файл информацию о каком-либо форматировании. Итак, в нашем распоряжении есть файл с разрешением pl, открытый интерпретатор: выбираем пункт меню File à Consult и загружаем файл в систему. Перед нами появится сообщение, которое сообщает нам о результатах загрузки файла в Prolog-систему примерно такого вида:
% c:/Prolog/FirstProjects/first.pl compiled 0.00 sec, 1,516 bytes
Также сообщение может содержать информацию об ошибках (error) и предупреждениях (warning).
Интерпретатор "SWI-Prolog" принимает программы, которые содержат ряд определений (фактов и правил), а после этого разрешает пользователю создавать запросы, основанные на данных определениях. Примеры запросов мы рассматривали выше. Попробуйте создать файл, загрузить его в интерпретатор и задать какой-нибудь вопрос. Если вы сразу загрузите файл с содержанием:
street( saint-petersburg, nevskii).
street( moscow, arbat).
street( bobruisk, nevskii).
то возможно захотите попробовать те самые "умные" возможности и зададите вопрос:
?- street( X, nevskii).
Однако послав запрос (нажав "Enter"), для начала вы получите только один ответ:
X = saint-petersburg ;
Чтобы получить следующий ответ, нажмите клавишу "n" и увидите:
X = bobruisk ;
Нажав клавишу "n" снова, вы получите ответ no и приглашение ввести новый запрос.
Показав общие принципы работы с интерпретатором "SWI-Prolog", перейдем снова к синтаксису языка. Вы же при возникновении вопросов, связанных с работой "SWI-Prolog", читайте документацию, приложенную к программе и выложенную на официальном сайте проекта (www.swi-prolog.org).
Теперь давайте научимся определять не только простые отношения, но и более
сложные — рекурсивные. Давайте добавим к нашей программе о родственных связях
еще одно отношение — predecessor (предок). Определим его через отношение
parent (родитель). Все отношение можно выразить
с помощью двух правил. Первое правило будет определять непосредственных (ближайших)
предков, а второе — отдаленных. Говорят, что некоторый X
является отдаленным предком некоторого Z, если между X и Z существует цепочка
людей, связанных между собой отношением родитель-ребенок. Первое правило простое
и его можно сформулировать так:
Для всех X и Z, X — предок Z, если X — родитель Z.
Это непосредственно переводится на Prolog как
predecessor( X, Z) :- parent( X, Z).
Второе правило сложнее, поскольку построение цепочки отношений parent
может вызвать некоторые трудности. Один из способов определения отдаленных
родственников мог бы заключаться в том, чтобы отношение predecessor
определялось бы множеством предложений:
predecessor( X, Z) :- parent( X, Z).
predecessor( X, Z) :- parent( X, Y), parent( Y, Z).
predecessor( X, Z) :- parent( X, Y1), parent( Yl, Y2), parent( Y2, Z).
predecessor( X, Z) :- parent( X, Y1), parent( Y1, Y2), parent( Y2, Y3), parent( Y3, Z).
. . .
Эта программа длинна и, что более важно, работает только в определенных пределах. Она будет обнаруживать предков лишь до определенной глубины фамильного дерева, поскольку длина цепочки людей между предком и потомком ограничена длиной наших предложений в определении отношения.
Существует, однако, корректная и элегантная формулировка отношения predecessor
— корректная в том смысле, что будет работать для предков произвольной отдаленности.
Ключевая идея здесь — определить отношение predecessor через него самого:
Для всех X и Z,
X — предок Z, если существует Y, такой, что X — родитель Y и Y — предок Z.
Предложение Prolog, имеющее тот же смысл, записывается так:
predecessor( X, Z) :- parent( X, Y), predecessor( Y, Z).
Теперь мы построили полную программу для отношения predecessor, содержащую два правила: одно для ближайших предков и другое для отдаленных предков. Здесь приводятся они оба вместе:
predecessor( X, Z) :- parent( X, Z).
predecessor( X, Z) :- parent( X, Y), predecessor( Y, Z).
Ключевым моментом в данной формулировке было использование самого отношения
predecessor в его определении. Такое определение может
озадачить — допустимо ли при определении какого-либо понятия
использовать его же, ведь оно определено еще не полностью. Такие определения
называются рекурсивными. Логически они совершенно корректны и понятны.
Но будет ли в состоянии Prolog-система использовать
рекурсивные правила? Оказывается, что Prolog-система очень легко может обрабатывать рекурсивные определения.
На самом деле, рекурсия — один из фундаментальных приемов программирования
на Prolog. Без рекурсии с его помощью невозможно решать
задачи сколько-нибудь ощутимой сложности.
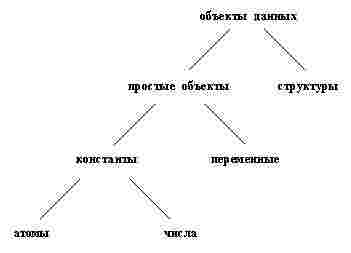
Выше мы уже употребили слово переменная, которое, конечно, известно любому программисту. О некоторых особенностях переменных и других простых объектов данных в системе Prolog мы сейчас и поговорим.
Система Prolog распознает тип объекта по его синтаксической форме. Это возможно благодаря тому, что в синтаксисе языка Prolog определены разные формы для объектов данных каждого типа. Различие между атомами и переменными в том, что переменные начинаются с прописных букв, а атомы — со строчных букв. Системе Prolog не требуется сообщать какую-либо дополнительную информацию (наподобие объявления типа данных) для того, чтобы она распознала тип объекта.
Начнем рассматривать приведенную ниже схему снизу: с атомов и чисел. Атомы представляют собой строки, состоящие из следующих символов:
A, B,…Z;a, b, …, z;0, 1, 2, …, 9;"+", "-", "*", "/", "<", ">", "=", ":", ".", "&",
"_", "~".
Атомы могут формироваться тремя перечисленными ниже способами:
anna, x_25, alpha_beta_procedure, miss_Jones.<--->, ===>, ..., ::= (При использовании атомов в
этой форме необходимо соблюдать осторожность, поскольку некоторые строки специальных
символов уже имеют предопределенное значение; в качестве примера можно привести
":-").‘Tom’,
‘South_America’.Числа в Prolog бывают целыми и вещественными. Синтаксис
целых чисел прост, как это видно из следующих примеров: 1, 1313, 0, -97. Не все целые
числа могут быть представлены в машине, поэтому диапазон целых чисел ограничен
интервалом между некоторыми минимальным и максимальным числами, определяемыми
конкретной реализацией Prolog. Обычно реализация допускает диапазон хотя бы
от -16383 до 16383, а часто, и значительно более широкий.
Синтаксис вещественных чисел виден из следующих примеров: 3.14, -0.0035, 100.2. При обычном программировании на
Prolog вещественные числа используются редко. Причина этого
кроется в том, что Prolog — это язык, предназначенный в первую очередь для
обработки символьной, а не числовой информации, в противоположность языкам
типа Фортрана, ориентированным на числовую обработку. При символьной обработке
часто используются целые числа, например, для подсчета количества элементов
списка; нужда же в вещественных числах невелика.
Кроме отсутствия необходимости в использовании вещественных чисел в обычных применениях Prolog, существует и другая причина избегать их. Мы всегда стремимся поддерживать наши программы в таком виде, чтобы их смысл был предельно ясен. Введение вещественных чисел в некоторой степени нарушает эту ясность из-за ошибок вычислений, связанных с округлением во время выполнения арифметических действий.
Теперь рассмотрим правила записи имен переменных: имена переменных — это
строки, состоящие из букв, цифр и символов подчеркивания. Начинаться имена
переменных должны с прописной буквы или символа подчеркивания: X, Result, Answer1, _x.
Область определения одной переменной представляет собой одно предложение,
то есть если одно и то же имя встречается в нескольких предложениях, то в каждом
из них оно означает разные переменные. В свою очередь каждое вхождение некоторой
переменной в одном и том же предложении соответствует одной и той же переменной.
Для констант же ситуация иная: один и тот же атом всегда обозначает во всех
предложениях, а, следовательно, и во всей программе, один и тот же объект.
От рассмотрения атомов, чисел и переменных перейдем к рассмотрению структур.
Структурированными объектами (или структурами) называются объекты, которые имеют несколько компонентов. Сами компоненты, в свою очередь, также могут быть структурами. Например, дата может рассматриваться как структура с тремя компонентами: число, месяц, год. Несмотря на то, что структуры состоят из нескольких компонентов, они рассматриваются в программе как целостные объекты. Для соединения компонентов в целостный объект необходимо выбрать функтор. В данном примере подходящим функтором является date. Например, дату "5 декабря 2005 года" можно записать следующим образом:
date( 5, december, 2005)
В этом примере все компоненты (два целых числа и один атом) являются константами. Компоненты могут также представлять собой переменные или другие структуры. Объект, который обозначает любое число декабря, можно представить в виде следующей структуры:
date( Day, december, 2005)
Обратите внимание на то, что Day является переменной и может конкретизироваться значением любого
объекта на каком-либо из следующих этапов выполнения программы.
Этот метод структурирования данных является простым и мощным. Он является одной из причин того, почему Prolog можно так естественно применять для решения проблем, связанных с символическими манипуляциями.
Подведем небольшие итоги: простые объекты в языке Prolog — это атомы, переменные и числа. Для представления объектов, имеющих несколько компонентов, используются структуры. Структуры создаются с помощью функторов, каждый из которых определяется своим именем и арностью. При этом, тип объекта распознается системой Prolog исключительно по его синтаксической форме.
Prolog рассчитан главным образом на обработку символьной информации, при которой потребность в арифметических вычислениях относительно мала. Поэтому и средства для таких вычислений довольно просты. Для осуществления основных арифметических действий можно воспользоваться несколькими предопределенными операторами.
+ —
сложение– —
вычитание* —
умножение/ —
деление** —
возведение в степень// —
целочисленное деление mod —
деление по модулю, вычисление остатка от целочисленного деленияОбратите внимание на то, что это и есть тот исключительный случай, в котором оператор может фактически вызвать на выполнение операцию. Но даже в таких случаях для осуществления арифметических действий требуется дополнительное указание. Например, следующий вопрос представляет собой наивную попытку потребовать выполнения арифметического вычисления:
?- X = 1 + 2
Система Prolog "послушно" ответит:
X = 1 + 2
а не X = 3, как следовало ожидать. Причина
этого проста — выражение 1 + 2 просто обозначает
терм Prolog, в котором знак + является функтором, а 1 и 2 — его параметрами. В приведенной
выше цели нет ничего, что могло бы вынудить систему Prolog фактически активизировать
операцию сложения. Для определения этой проблемы предусмотрена специальная
предопределенная операция is.
Операция is
вынуждает систему выполнить вычисление, поэтому правильный способ вызова арифметической
операции состоит в следующем:
?- X is 1 + 2
В этом случае будет получен ответ:
X = 3
При этом операция сложения была выполнена с помощью специальной процедуры,
которая связана с операцией is. Подобные процедуры
принято называть встроенными процедурами.
Кроме того, в Prolog предусмотрены такие стандартные функции, как sin(x), cos(x), atan(x), log(x), exp(x) и т.д. Эти функции могут
находиться справа от знака операции is.
Кроме того, при выполнении арифметических операций возникает необходимость
сравнивать числовые значения. Например, с помощью следующей цели может быть
выполнена проверка того, больше ли произведение чисел 277 и 37
по сравнению с числом 10000:
?- 277 * 37 > 10000.
yes
Обратите внимание на то, что операция ">", как и операция is,
вынуждает систему вычислять арифметические выражения.
Ниже перечислены операции сравнения:
X > Y. — X больше Y.X < Y. — X меньше Y.X >= Y. — X больше или равен Y.X =< Y. — X меньше или равен Y.X =:= Y. — Значения X и Y равны. X =\= Y. — Значения X и Y не равны.Одной из наиболее полезных, но, тем не менее, простых, структур считается
список. Списки широко используются в нечисловом программировании, поскольку
они представляют собой последовательности, состоящие из любого количества
элементов. Например, можно задать последовательность элементов: moscow, saint-petersburg, novgorod,
novosibirsk:
[ moscow, saint-petersburg, novgorod, novosibirsk]
При этом приведенная выше строка — всего лишь внешняя сторона списка. Как
и все структуры, списки представляются системой Prolog в виде дерева, вершиной которого является первый элемент
списка. Кстати, список может быть пустым — тогда он записывается в виде атома
[], в остальных же случаях список можно
рассматривать как объект, состоящий из двух компонентов: головы списка (первый
компонент), хвост (остальная часть списка).
В общем случае, головой может быть что угодно (любой объект
Prolog, например, дерево или переменная); хвост
же должен быть списком. Голова (Head) соединяется с
хвостом (Tail)
при помощи специального функтора:
.( Head, Tail)
Поскольку Tail — это список, он либо пуст, либо имеет свои собственную
голову и хвост. Таким образом, выбранного способа представления списков достаточно
для представления списков любой длины. Наш список представляется следующим
образом:
.( moscow, .(saint-petersburg, .( novgorod, .(novosibirsk, []))))
Мы ввели новую структуру, однако сама по себе большой ценности она не представляет. Важно то, что над ней можно проводить некоторые операции, среди которых:
Описание этих операций на языке Prolog достаточно понятно для тех, кто знаком с рассматриваемой структурой, поэтому здесь мы приведем в качестве примера лишь операцию принадлежности к списку.
Мы представим отношение принадлежности как member( X, L), где Х — объект, а L — список. Цель member( X, L) истинна, если элемент Х встречается в L. Например, верно что member( b, [а, b, с] ) и, наоборот, не верно, что member( b, [а, [b, с] ] ), но member( [b, с], [а, [b, с]] )
истинно. Поэтому программа проверки отношения принадлежности к списку может
быть основана на приведенных ниже рассуждениях.
X входит в состав L, если истинно одно из утверждений:
1) Х есть голова L, либо
2) Х принадлежит хвосту L.
Эту программу можно записать в виде двух предложений, первое из которых есть простой факт, а второе — правило:
member( X, [X | Tail] ).
member( X, [Head | Tail] ) :- member( X, Tail).
Конечно, операции конкатенации списков, а также добавления и удаления элементов из списка задаются несколько сложнее, но их описание уже выходит за формат нашей статьи. Поэтому теперь от различных структур данных мы переходим к другому, не менее интересному вопросу — вводу и выводу.
Метод взаимодействия пользователя и программы, который применялся до сих пор, предусматривал ввод пользователем вопросов к программе и получение ответов программы в виде результатов конкретизации переменных. Так метод обмена данных является простым и достаточным для обеспечения ввода и вывода информации. Тем не менее, он часто является не совсем приемлемым, поскольку не обладает достаточной гибкостью. Поэтому этот основной метод обмена данными необходимо дополнить в следующих областях:
На рисунке показано общая ситуация, в которой программа Prolog осуществляет обмен данными с несколькими файлами.
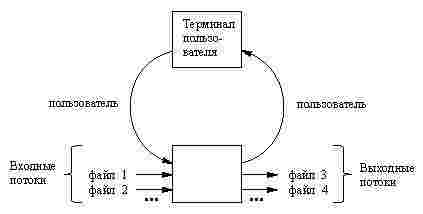
В принципе, программа может считывать данные их нескольких входных файлов,
называемых также входными потоками, и выводить данные в несколько выходных
файлов, которые называются выходными потоками. Данные, поступающие с пользовательского
терминала, рассматриваются как ещё один входной поток. Аналогичным образом,
данные, выводимые на терминал, представляют собой один из выходных потоков.
Эти потоки не фиксируются на жестком диске, но связаны с информационными структурами,
аналогичными файлам и известными под именем user.
Имена других файлов могут быть выбраны программистом с учетом правил именования файлов в используемой компьютерной системе.
В любой момент времени в ходе выполнения программы Prolog "активны" только
два файла: один для ввода, а другой для вывода. Эти два файла, соответственно,
называются текущим входным потоком и текущим выходным потоком. В начале выполнения
программы эти два потока соответствуют пользовательскому терминалу. Текущий
входной поток можно перевести в другой файл, Filename,
с помощью следующей цели:
see( Filename)
Эта цель достигается (если только не обнаружится какая-либо ошибка, связанная
с переменной Filename)
и вызывает в качестве побочного эффекта то, что ввод переключается с предыдущего
входного потока на файл Filename.
Поэтому типичным примером использования предиката see является приведенная ниже последовательность
целей, которая обеспечивает чтение определенных данных из файла file1, а затем повторное переключение на терминал:
. . .
see( file1),
read_from_file( Information),
see( user),
. . .
Текущий выходной поток можно изменить с помощью цели, заданной в следующей форме:
tell( Filename)
Ниже приведена последовательность целей для вывода некоторой информации в
файл file3, а затем перенаправления последующего вывода снова
на терминал:
. . .
tell( file3),
write_from_file( Information),
tell( user),
. . .
Цель seen закрывает текущий входной файл, а цель told
закрывает текущий выходной файл.
Файлы могут обрабатываться в языке Prolog
двумя основными способами, в зависимости от формы представления в них
информации. Один из способов состоит в том, что основным элементом файла является
символ. В соответствии с этим один запрос на ввод и вывод вызывает чтение
или запись единственного символа. В этой главе предполагается, что для этого
служат встроенные предикаты get, get0 и put.
Еще один способ обработки файлов состоит в том, что в качестве основных
структурных блоков файла рассматриваются более крупные информационные
единицы. Вполне естественно, что в качестве такой более крупной единицы, принят
терм потока или в текущий выходной поток передается, соответственно, целый
терм. Предикатами для передачи термов являются read и write. Разумеется,
в этом случае информация в файле должна находиться в форме, совместимой с
синтаксисом термов.
Встроенный предикат read используется для чтения термов
из текущего входного потока, а цель read( X)
вызывает чтение следующего терма, T, и согласование этого терма с X. Если
X представляет собой переменную,
то в результате X становится конкретизированной
значением T, а если согласование оканчивается неудачей,
цель read( X) не достигается.
Предикат read является детерминированным,
поэтому в случае неудачи не выполняется перебор с возвратами для ввода другого
терма. За каждым термом во входном файле должны следовать точка и пробел (или
символ с обозначением конца строки).
Если предикат read( X) вызывается на выполнение после достижения
конца текущего входного файла, то переменная X становится конкретизированной
значением атома end_of_file.
Встроенный предикат write выводит терм,
поэтому цель write( X)
выводит терм X в текущий выходной файл. Терм X выводится в такой же стандартной синтаксической
форме, в которой Prolog обычно отображает значения переменных. Полезным средством языка
Prolog является то, что процедура write "умеет" отображать любые термы, независимо от того, насколько
они могут быть сложными.
Символ записывается в текущий поток с помощью следующей цели:
put(C)
где С
— код ASCII (число от 0 до 127) выводимого символа. Например, вопрос
?- put(65), put(66), put(67)
вызывает вывод следующих данных:
ABC
где 65 — код ASCII символа "A", 66 — символа "B" и 67
— символа "C".
Отдельный символ может быть считан из текущего входного потока с помощью цели:
get0(C)
Эта цель вызывает чтение текущего символа из входного потока и конкретизацию
переменной С значением кода ASCII этого символа. Вариантом предиката get0
является get, который используется для чтения непробельных символов (символов отличных от знака пробела,
знака табуляции т.п.) Поэтому цель
get(C)
вызывает пропуск всех непечатаемых символов (в частности пробелов) от текущей позиции ввода во входном потоке вплоть до первого печатаемого символа. После этого, как обычно, считывается данный символ, и переменная C конкретизируется значением его кода ASCII.
В любой реализации Prolog обычно предусмотрен набор встроенных процедур (также называемых дополнительными встроенными предикатами), позволяющих осуществить ряд других полезных операций, которые невозможны в базовой версии языка Prolog: это и предикаты проверки типа терма, предикаты для создания или декомпозиции терма, операции сравнения над термами — список можно продолжать и дальше. Но, к сожалению, формат статьи не даёт нам возможность подробнее остановиться на этих предикатах и поэтому на этом мы закончим описание базового синтаксиса языка Prolog, предварительно дав некоторые рекомендации по принципам программирования на языке Prolog.
Как и любая программа на любом другом языке, ваша программа на языке Prolog, должна быть правильной, эффективной, простой и читабельной, легко модифицируемой, хорошо документированной.
Также общеизвестно, однако не всегда выполняемо, то, что сначала лучше продумать задачу, подлежащую решению, и лишь потом приступать к написанию текста программы на конкретном языке программирования. Во-первых, следует сформулировать способ решения задачи, во-вторых приступить к его перенесению на язык программирования. На втором шаге неплохо использовать принцип пошаговой детализации. В соответствии с этим принципом окончательная программа получается после серии трансформаций или "детализаций" решения. Надо осознавать, что детализация касается не только процедур, но и структур данных. На начальных шагах работают обычно с более абстрактными, более крупными информационными единицами, детальная структура которых уточняется впоследствии.
В случае языка Prolog мы можем говорить о пошаговой детализации отношений. Если существо задачи требует мышления в алгоритмических терминах, то мы можем также говорить и о детализации алгоритмов, приняв процедурную точку зрения на Prolog.
Одной из характерных особенностей языка Prolog является то, что в нем допускается как процедурный, так и декларативный стиль мышления при составлении программы. Какой из этих подходов окажется более эффективным и практичным, зависит от конкретной задачи. Обычно построение декларативного решения задачи требует меньших усилий, но может привести к неэффективной программе, поэтому выбирать приходится каждый раз.
Программируя на языке Prolog, нельзя забывать о его встроенных средствах, которые в случае грамотного использования, позволяют значительно упростить программу. Прежде всего, речь идёт об использовании рекурсии. Одна из причин того, что рекурсия так естественна для определения отношений на Prolog, состоит в том, что объекты данных часто сами имеют рекурсивную структуру. К таким объектам относятся списки и деревья. Список либо пуст (граничный случай), либо имеет голову и хвост, который сам является списком (общий случай). Двоичное дерево либо пусто (граничный случай), либо у него есть корень и два поддерева, которые сами являются двоичными деревьями (общий случай). Поэтому для обработки всего непустого дерева необходимо сначала что-то сделать с его корнем, а затем обработать поддеревья.
Часто бывает полезно обобщить исходную задачу таким образом, чтобы полученная более общая задача допускала рекурсивную формулировку. Исходная задача решается, тогда как частный случай ее более общего варианта. Обобщение отношения обычно требует введения одного или более дополнительных аргументов. Главная проблема состоит в отыскании подходящего обобщения, что может потребовать более тщательного изучения задачи.
В поиске идей для решения задачи часто бывает полезным обратиться к ее графическому представлению. Рисунок может помочь выявить в задаче некоторые существенные отношения. После этого останется только описать на языке программирования то, что мы видим на рисунке (вспомним, каким простым способом задаются отношения между объектами на Prolog).
Использование графического представления при решении задач полезно всегда, однако похоже, что в Prolog оно работает особенно хорошо. Происходит это по следующим причинам:
Разумеется, при программировании на Prolog, как и при программировании на любом другом языке, следует придерживаться определенных правил и стилистических соглашений для уменьшения вероятности ошибок, повышения удобства программ для чтения, отладки и модификации. На этом закончим рассказ о синтаксисе языка Prolog и прейдем к рассмотрению некоторых интересных примеров.
В этой части мы рассмотрим пример использования языка Prolog в системе, оперирующей базой данных, например, в словаре. Во-первых, коротко опишем структуру такого словаря.
Вся хранимая информация в словаре является по сути своей реляционной базой данных (РБД). Например, есть список словарных статей. У каждой статьи есть свой уникальный код (primary key в терминологии РБД). Это целое число, которое однозначно идентифицирует статью в лексиконе. Более того, так как этот код присваивается статье при ее создании и не зависит от индекса статьи в списке, то оказывается возможным в ходе компиляции, например, продукционного правила запомнить ключ статьи — и в ходе выполнения правила оперировать именно ключами статей.
Аналогичный подход применяется для хранения любой другой информации в словаре. Грамматические координаты представляют собой именованные списки значений. Координатная пара — это имя координаты и имя состояния. В словаре координатная пара представляется двумя целыми числами — индексом координаты и индексом состояния. В данном случае вместо абстрактных ключей используется физический индекс элемента во внутреннем списке. Это упрощает работу и ускоряет доступ, но накладывает ограничения: после компиляции словаря нельзя менять списки с описаниями координат.
При работе грамматического конвейера использование ключей вместо самих описаний (например, вместо строковых констант) позволяет значительно увеличить эффективность — сравнение целых чисел в любом случае быстрее сравнения текстовых строк. Все это, однако, внутреннее устройство, которое внешне ничем себя не выдает. Манипуляции с записями во внутренних таблицах происходят под управлением алгоритмов, которые конструкции языка Prolog переводят в запросы к БД.
Но есть часть системы — Prolog-автомат — которая и внутренне и внешне является настоящей СУБД. Может
показаться странным использование достаточно экзотичного языка вместо индустриального
стандарта SQL. Тому есть простое объяснение. Prolog прост и в смысле описания (в принципе, это пара десятков страниц
с примерами), и в смысле реализации. Движок SQL-базы данных очень сложен,
начиная от парсера выражений (синтаксис SQL достаточно
витиеват и разнообразен), и заканчивая необходимостью писать
планировщик-оптимизатор запросов, который будет строить алгоритм доступа
к данным для каждого поступающего SELECT, UPDATE и DELETE. Кроме этого,
средства процедурного программирования — различные языки (например, PL/SQL
или TSQL) — сами являются предметом отдельного изучения со своим синтаксисом
и идеологией.
Prolog предлагает однородные средства как описания
данных, так и доступа к ним. SQL таблицам прямо соответствуют предикаты. SQL
отображения (VIEW) без каких-либо усложнений языка реализуются также через предикаты-теоремы ( :-
). Процедуры для работы с множествами записей в Prolog реализуются
просто через AND-связку команд-предикатов.
Рассмотрим элементарный пример. Допустим, есть таблица сущностей ENTITY с полями:
id |
desc |
id_type |
Primary_key |
Описание сущности |
Код типа — Foreign key на стоблец id таблицы ENTITY_TYPE |
Есть также справочник типов сущностей ENTITY_TYPE:
id |
desc |
Primary_key |
Описание типа — строка с произвольным текстом |
Пусть справочник типов содержит записи:
id |
desc |
1 |
subject |
2 |
object |
3 |
action |
Чтобы получить список сущностей, относящихся к типу action, в общем
случае на SQL надо написать:
SELECT E.desc
FROM ENTITY E, ENTYTY_TYPE T
WHERE T.desc = 'action' AND E.id_type = T.id;
На Prolog этот запрос выглядит так:
subject( Sbj) :- entity_type( Id_type, "action"), entity( _, Sbj, Id_type)?
Различия невелики, она даже скорее формальны. К примеру, для подсчета записей
о сущностях типа action потребуется минимальные дополнения
в оба кода: SELECT
COUNT(E.desc) ... и
count( subject(_), C )?
В данном случае count/2 — это встроенный предикат расширенного Prolog, который
функционально аналогичен оператору COUNT языка SQL.
Разумеется, язык SQL предлагает некоторые мощные средства обеспечения целостности
данных, которые отсутствуют в стандартном Prolog.
Primary keys
и foreign keys
— удобные и эффективные способы гарантировать, что в БД не появятся записи,
ссылающиеся на отсутствующие данные в других таблицах. Чтобы компенсировать
этот изъян Prolog, в него были введены некоторые средства. В частности, с
помощью встроенных предикатов можно объявлять требования к таблицам, то есть
предикатам-записям одинаковой структуры и с одинаковым корневым атомом.
В качестве продолжения рассмотрим язык Prolog, как язык для построения экспертной системы.
Экспертная система – это программа, которая ведет себя подобно эксперту в некоторой, обычно узкой, прикладной области. Типичные применения экспертных систем включают в себя такие задачи, как медицинская диагностика, локализация неисправностей в оборудовании и интерпретация результатов измерений. Экспертные системы должны решать задачи, требующие для своего решения экспертных знаний в некоторой конкретной области. В той или иной форме экспертные системы должны обладать этими знаниями. Поэтому их также называют системами, основанными на знаниях. Однако не всякую систему, основанную на знаниях, можно рассматривать как экспертную. Экспертная система должна также уметь каким-то образом объяснять свое поведение и свои решения пользователю, так же, как это делает эксперт-человек. Это особенно необходимо в областях, для которых характерна неопределенность, неточность информации (например, в медицинской диагностике). Часто к экспертным системам предъявляют дополнительное требование — способность иметь дело с неопределенностью и неполнотой. В самом общем случае для того, чтобы построить экспертную систему, мы должны разработать механизмы выполнения следующих функций системы:
Рассмотрим структуру возможной экспертной системы. При разработке экспертной системы принято делить ее на три основных модуля:
База знаний содержит знания, относящиеся к конкретной прикладной области, в том числе отдельные факты, правила, описывающие отношения или явления, а также, возможно, методы, эвристики и различные идеи, относящиеся к решению задач в этой прикладной области. Машина логического вывода умеет активно использовать информацию, содержащуюся в базе знаний. Интерфейс с пользователем отвечает за бесперебойный обмен информацией между пользователем и системой; он также дает пользователю возможность наблюдать за процессом решения задач, протекающим в машине логического вывода. Принято рассматривать машину вывода и интерфейс как один крупный модуль, обычно называемый оболочкой экспертной системы, или, для краткости, просто оболочкой.
Разработаем относительно простую оболочку, при помощи которой, несмотря на ее простоту, мы сможем проиллюстрировать основные идеи и методы в области экспертных систем. Мы будем придерживаться следующего плана:
В качестве кандидата на использование в экспертной системе
можно рассматривать, в принципе, любой непротиворечивый формализм, в рамках
которого можно описывать знания о некоторой проблемной области.
Однако самым популярным формальным языком представления знаний является язык правил типа "if-else"
(или кратко: "if-else"-правил),
называемых также продукциями. Каждое такое правило есть, вообще говоря,
некоторое условное утверждение, но возможны и различные другие интерпретации.
Кроме того, они обладают следующими привлекательными свойствами:
Правила, содержащиеся в базе знаний, имеют вид
RuleName :: if Condition then Conclusion.
Где Conclusion (Заключение) — это простое утверждение, а
Condition (Условие) — это набор простых утверждений,
соединенных между собой операторами и и или.
Мы также разрешим в части условия использовать оператор не, хотя и с некоторыми оговорками.
Теперь перейдем к разработке оболочки. Если мы посмотрим на правила в том виде, в каком мы их договорились задавать, мы сразу увидим, что они по своему смыслу эквивалентны правилам Prolog. Однако, с точки зрения синтаксиса Prolog, эти правила в том виде, как они написаны, соответствуют всего лишь фактам. Для того, чтобы заставить их работать, самое простое, что может прийти в голову, это переписать их в виде настоящих Prolog-правил. Тогда программа сможет отвечать на запросы, руководствуясь фактами, находящимися в нашей базе данных. Но в этом случае, хотя Prolog-система и отвечает на вопросы, используя для этого нашу базу знаний, нельзя сказать, что ее поведение вполне соответствует поведению эксперта. Это происходит по крайней мере по двум причинам:
Для того чтобы исправить эти два недостатка, мы нуждаемся в более совершенном
способе взаимодействия между пользователем и системой во время и после завершения
процесса рассуждений. Наш интерпретатор должен принимать вопрос и искать на
него ответ. Язык правил допускает, чтобы в условной части правила была and/or-комбинация условий. Вопрос на входе интерпретатора
может быть такой же комбинацией подвопросов. Обобщим эти рассуждения: итак,
ответ на заданный вопрос можно найти несколькими способами в соответствии
со следующими принципами:
Для того чтобы найти ответ Answer на вопрос Q, используйте одну из следующих возможностей:
Q найден в базе знаний в виде факта, то Answer — это Q is true"if Condition then Q", то для получения ответа Answer рассмотрите ConditionQ можно задавать пользователю, спросите пользователя об истинности QQ имеет вид Q1 and Q2, то рассмотрите Q1, а затем, если Q1
ложно, то положите Answer равным Q is false,
в противном случае рассмотрите Q2 и получите Answer как соответствующую комбинацию ответов
на вопросы Q1 и Q2Q имеет вид Q1 or Q2, то рассмотрите Q1, а затем если Q1 истинно,
то положите Answer равным Q1, в противном случае рассмотрите и получите
Answer как соответствующую комбинацию ответов
на вопросы Q1 и Q2.Далее можно заняться формированием ответов на вопросы следующих типов:
why)how)Разумеется, в данной статье рассматривать реализацию командного интерпретатора экспертной системы мы не будем — ограничимся лишь приведением списка основных процедур этого интерпретатора:
explore( Goal, Trace, Answer). Находит
ответ Answer
на вопрос Goal.useranswer( Goal, Trace,
Answer). Вырабатывает решения для запрашиваемой цели Goal, задавая пользователю вопросы,
касающиеся цели Goal, и отвечая на вопросы "Why?"present( Answer).
Показывает полученные результаты и отвечает на вопросы "How?"expert.
Эта управляющая процедура создана для правильного ввода в действие перечисленных
выше процедур.Подробное описание процесса создания этих процедур вы сможете найти в книге И.Братко "Алгоритмы искусственного интеллекта на языке Prolog" [1] в главе, посвященной экспертным системам. Мы же завершим на этом рассмотрение этого довольно абстрактного примера использования языка Prolog.
Множество появляющихся направлений в интернет-бизнесе приносит пользу в виде развития логических языков программирования. Обмен данными между системами, совершенно отличающимися друг от друга, а также изощренность таких систем приводит к тому, что использование "обычных" языков программирования становится слишком сложным для решения поставленных задач. На помощь "приходят" приходят такие языки, как Prolog. Чтобы проиллюстрировать возможности языка Prolog, рассмотрим интернет-проект http://www.yourbet.com и применение Prolog для решения проблем поставленных проектом.
Проект http://www.yourbet.com представляет собой online-букмекер. Он предоставляет такие услуги, как online видео и аудио трансляции, отображение в режиме реального времени текущих результатов скачек и заключение букмекерских пари. Он предоставляет доступ к 60 ипподромам таких стран, как США, Канада и Австралия. Получить доступ к сервису можно или через web браузер, или скачав специальное приложение, которое доступно для скачивания на сайте.
Для быстрого обмена данными и доступа к базе данных используется связка "Java плюс Prolog". Следует отметить, что использование одновременно процедурного и логического языков программирования в разработке проекта сложно для программиста, так как стили мышления на этих двух типах языков различаются очень сильно. Но Java в данной связке используется только, как инструмент, для преобразования информации в такой вид, который будет "удобен для понимания" модулем, написанном на Prolog.
Система установленная на сервере, должна уметь обрабатывать входящую информацию в режиме online. То есть, получая данные с ипподрома обновлять соответствующий контент на сайте. При этом, делая это так, чтобы пользователь системы мог в любой время получить доступ к интересующей его информации.
Рассмотрим основы реализации такой системы. Сам процесс обработки информации можно поделить на пять частей:
Особо отмечается, что шаги с третьего по пятый реализованы на Prolog. Однако не будем вдаваться в подробности, связанные с XML-преобразованиями, а приведем пример преобразования XML в стандартный для Prolog вид. Утверждается, что эти преобразования тривиальны, в чем вы можете убедиться сами. Например, в XML некоторый отрывок из сообщения выглядит так:
<odds track=’AQUEDUCT’ race=’3’ type=’WIN’>
<entry horse=’1’ value=’3-2’/>
<entry horse=’2’ value=’5-1’/>
</odds>
что эквивалентно следующей структуре на Prolog:
odds([track(‘AQUEDUCT’),race(3),type(‘WIN’)],[
entry([horse(1),value(‘3-2’)],[]),
entry([horse(1),value(‘3-2’)],[])
])
Далее, когда полученные сообщения "понятны" интерпретатору Prolog, вопрос — в создании некоторой экспертной системы. О них мы рассказывали в предыдущей части статьи, поэтому перейдем к некоторым выводам.
Трудно себе представить успешный интернет-бизнес, который не требует выполнение таких задач, как обмен большим количеством информации, которая может быть при этом разной по своей "природе", и последующей фильтрации данной информации. Учитывая суть поставленной задачи, а также сложность реализации её на процедурных языках программирования, программист для ее решения применяет логический язык программирования, например, такой как Prolog.
Проект http://www.yourbet.com применил технологии так называемого "искусственного интеллекта" и общей архитектуры, чтобы развить подход к решению проблемы, который связывает Prolog и технологии обмена данными вместе. Такой подход позволяет эффективно решать данные проблемы в контексте пользовательских программ.
Таким образом, можно сделать вывод, что при надобности Prolog можно использовать в самых различных областях, разумеется, прежде всего, в качестве языка для написания некоторого "интеллектуального" ядра, обрабатывающего информацию и выдающего ответы на запросы по этой информации.
В качестве заключения хотелось бы отметить, что за прошедшие со дня создания языка годы Prolog хотя и "не достиг высоких целей логического программирования" [2], но, тем не менее, является мощным, продуктивным и практически пригодным формализмом программирования. Вопрос о том, куда Prolog двинется дальше, и станет ли он стандартным языком разработки в какой-нибудь узкой, но перспективной области остается открытым. Конечно, Prolog имеет немалые возможности, но для его грамотного освоения требуется отучиться от мышления свойственному "традиционному" программированию, а это не так легко. Возможно, в ближайшее время появится новый язык логического программирования, который, благодаря успешному пиару, станет стандартом в области разработок "интеллектуальных" систем. Возможно, таким языком станет модернизированный Prolog. Пока же массовый рынок не требует таких разработок, и языком Prolog больше интересуются в учебных целях.