|
Для прогнозування стану атмосферного повітря застосовуються різні методи - аналітіко-емпіричні, чисельні, статистичні, комбіновані та інші. Всі ці методи мають свої переваги і недоліки. Наприклад, аналітіко-емпірічні методи мають велику погрішність, а чисельні методи вимагають використання даних про джерела викидів, а ця інформація часто невідома. Тому дослідження процесів забруднення атмосферного повітря і розробка моделей прогнозування є актуальними завданнями екологічного моніторингу [2].
Мета та завдання
Мета магістерської роботи – дослідження процесів забруднення атмосферного повітря за даними автоматизованих постів спостереження за станом атмосферного повітря.
Завдання магістерської роботи:
- аналіз методів і засобів короткострокового прогнозування поширення домішок в атмосферному повітрі;
- аналіз даних про забруднення атмосферного повітря, що поступають від автоматизованих постів спостереження і порівняння їх з даними найближчих стаціонарних постів суб'єктів моніторингу;
- пошук закономірностей поширення домішки в просторово-часових координатах;
- побудова моделі поширення домішки і аналіз її ефективності шляхом апріорної оцінки основних параметрів;
- апробація і впровадження наукових результатів.
Методи досліджень, що використовуватимуться в магістерській роботі, – статистичний, штучних нейронних мереж, спектральний аналіз.
Наукова новизна
Передбачувана наукова новизна роботи полягає в наступному:
- дослідження закономірностей зміни концентрації домішки за даними автоматизованих постів моніторингу Донецько-Макеївського регіону;
- побудова математичної моделі вигляду ARIMA, що оцінює зміну концентрації домішки для оксиду вуглецю (CO), діоксиду сірки (SO2) та діоксиду азоту (NO2);
- прогнозування зміни концентрацій домішок на найближчий період і побудова апріорної оцінки якості моделі прогнозу.
Апробація
Результати роботи доповідалися на V міжнародній конференції студентів, аспірантів та молодих вчених «Комп’ютерний моніторинг та інформаційні технології» (КМІТ-2009) і опубліковані у відповідному збірнику.
Огляд досліджень та розробок за темою
Для вирішення завдання прогнозування забруднення атмосфери на даний момент існує безліч методик.
В Україні, Росії, Білорусії діє методика ОНД-86, яка є загальновизнаним нормативним документом в більшості країн СНД. У ряді західних країн використовуються офіційні програми Агентства захисту ОПС (EPA) [3].
Методика розрахунку концентрацій ОНД-86 орієнтована на розрахунок максимальної концентрації забруднюючої речовини на максимальній відстані від джерела викидів. Дана методика використовує емпіричні коефіцієнти, отримані для країн СНД, що не дозволяє використовувати методику в інших країнах. Велика кількість джерел викидів робить неможливим відновлення цілісної картини забруднення атмосфери регіону. Не зважаючи на вказані недоліки, методика ОНД-86 стала основою більшості вітчизняних програмних продуктів, що використовуються для розрахунку забруднення атмосферного повітря промисловими підприємствами і здобуття дозволів на викиди [4].
У роботах М. Є. Бєрлянда описуються моделі прогнозування забруднення атмосфери, в основу яких покладено загальне рівняння дифузії. Найбільш відомими зарубіжними моделями, що використовують цей підхід, є моделі Гіффорда, Гіффорда-Ханна. При розв’язанні рівняння дифузії для його спрощення і адаптації до конкретних територіально-розподілених об'єктів використовують ряд припущень і гіпотез. Перевага даного підходу – це універсальність отриманих моделей, а недоліки – висока невизначеність вихідних даних, складні процедури оцінювання достовірності моделей, неможливість урахування рельєфних особливостей місцевості [5].
Одна з відомих методик розрахунку забруднення атмосферного повітря, що використовують дані постів контролю, а не дані про джерела викидів, використовує статистичну основу. На даний момент вона є методикою, що офіційно діє на території України, і опублікована в [1] . Подана методика враховує вплив не окремих забруднюючих речовин, а їх сумарну негативну дію. За допомогою механізмів інтерполяції та екстраполяції методика дозволяє здійснювати розрахунок поля концентрації. Таким чином, подана методика дозволяє вирішувати стаціонарну задачу прогнозування.
Аналіз програмних продуктів в області контролю забруднення атмосфери показує, що ефективних спеціалізованих програмних засобів для прогнозу забруднення атмосферного повітря практично не існує. Серед вітчизняних програмних продуктів сьогодні використовуються “ЕОЛ”, “Пленер”, УПРЗА “Еколог”, “Кедр” та ін., серед зарубіжних – продукти сімейства “CalPuff”, “Plume”, “TAPM”, а також програмні продукти, що базуються на моделях EPA [6].
Більшість вітчизняних програмних продуктів мають ряд недоліків. Істотним недоліком є неможливість обліку рельєфних особливостей місцевості. Застосування зарубіжних програмних засобів неможливе через ряд причин, таких як: відмінності в кліматичних умовах, системах постачання екологічній інформації і інших [3].
Отже, можна зазначити, що завдання пошуку нових методів прогнозування забруднення атмосферного повітря і створення на їх основі програмних продуктів нового покоління є актуальним завданням моніторингу довкілля.
Поточні результати
Сьогодні на території Донецько-Макеївського регіону спостерігається встановлення автоматизованих постів контролю забруднення атмосфери. Один з таких постів розташований на території ДонНТУ і функціонує з листопада 2008 року. Даний пост контролює концентрації оксиду вуглецю (CO), діоксиду сірки (SO2) і діоксиду азоту (NO2) в повітрі. Процес виміру включає аналіз атмосферного повітря за допомогою газоаналізатора, до складу якого входять електролітичні датчики CO, SO2 та NO2. Отримана з датчиків інформація усереднюється і з періодичністю 10 хвилин записується в базу даних, що входить до складу програмного комплексу Акіам.
Накопичені дані є часовими рядами спостережень за концентраціями вказаних речовин. На момент написання автореферату кількість наявних даних складає приблизно 20 тисяч спостережень. Дана інформація може бути використана для розробки моделей прогнозу забруднення атмосфери. Для аналізу даних можуть використовуватися наступні методи: аналіз перерваних часових рядів; експоненціальне згладжування і прогнозування; авторегресії і зінтеґрованого ковзного середнього (ARIMA); спектральний аналіз (Фур'є); прогнозування з використанням нейронних мереж та інші. У магістерській роботі передбачається використання останніх трьох методів.
Загальна структура системи прогнозування забруднення атмосферного повітря представлена на рис. 1.

Рисунок 1 – Структура системи прогнозування забруднення атмосфери
(анімація: об'ъєм - 29,3 КБ; розмір - 560x417; кількість кадрів - 9;
затримка між кадрами - 90 мс; затримка між першим та останнім кадром - 150 мс;
кількість циклів повторення - 7 )
На даний момент виконані наступні завдання магістерської роботи: отримані дані з автоматизованого поста системи Акіам і виконана підготовка цих даних до аналізу; проведений аналіз часових рядів за допомогою штучних нейронних мереж і методу ARIMA та здійснено спробу їх прогнозування.
Розглянемо детальніше кожен з методів, які планується використовувати, а також результати проведеного аналізу.
1. Спектральний аналіз
Мета спектрального аналізу – розкласти ряд на функції синусів і косинусів різних частот, для визначення основних функцій, поява яких особливо істотна та значуща. Один із способів полягає в розв’язанні задачі лінійної множинної регресії, де залежна змінна – спостережуваний часовий ряд, а незалежні змінні або регресори – функції синусів всіх можливих (дискретних) частот. Така модель лінійної множинної регресії може записуватися як:
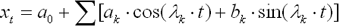  (1) (1)
де: k=1..q; q – загальна кількість всіх синусів і косинусів; ak – коефіцієнти при косинусах; bk – коефіцієнти при синусах; 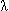 – кругова частота, виражена в радіанах в одиницю часу ( – кругова частота, виражена в радіанах в одиницю часу (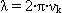 , де , де  – константа 3.1416 та – константа 3.1416 та 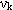 = k/q). = k/q).
Коефіцієнти ak иbk – це коефіцієнти регресії, що показують міру, з якою відповідні функції корелюють з даними. Різних синусоїдальних хвиль стільки ж, скільки даних, тому завжди можливо повністю відтворити ряд за основними функціями.
Методи спектрального аналізу мають важливе значення для визначення прихованих періодичностей в даних. Також вони корисні для перевірки адекватності моделі ARIMA, а саме для аналізу залишків [7].
2. Штучні нейронні мережі
Нейронні мережі є дуже популярними і досить ефективними у вирішенні завдань прогнозування. Нейронні мережі дозволяють моделювати лінійні залежності у випадку великої кількості змінних.
Завдання прогнозування за допомогою штучних нейронних мереж полягає в побудові оптимальної нейронної мережі на основі вихідних даних, її навчанні за різними алгоритмами, донавчанні (при необхідності) і побудові прогнозу.
Відомо, що в більшості випадків для побудови якісної мережі буває досить декілька сотень або тисяч спостережень.
Навчання мережі є підгонкою моделі, яка реалізується мережею, до наявних навчальних даних. Для цього використовується цілий ряд алгоритмів навчання мережі, а саме: алгоритм зворотного поширення, метод спуску по зв'язаних градієнтах, метод Лєвенберга–Маркара, метод Квазі-Ньютона та інші [8].
Перевага нейромережевого підходу – те, що він дозволяє відтворювати складні нелінійні залежності і виконувати прогноз на будь-яке число кроків (сумірне з кількістю початкових даних) [9].
Аналіз даних за допомогою нейронних мереж здійснювався за допомогою модуля Statistica Neural Networks (SNN) пакету STATISTICA 6.0. Для аналізу використовувалися дані про концентрацію оксиду вуглецю (CO). Для побудови нейронних мереж була вибрана топологія MLP(MultiPlayer Perseptron) – багатошаровий персептрон. Далі за початковими даними був побудований ряд мереж, що мають вказану топологію. Оцінка параметрів якості і середньоквадратичної помилки для кожної мережі дозволила вибрати найкращу мережу. Після цього було проведено донавчання найкращої мережі різними методами (Квазі-Ньютона, Лєвенберга-Маркара). В результаті була отримана мережа, архітектура якої показана на рис.2.
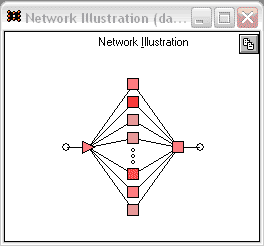
Рисунок 2 – Загальний вигляд архітектури найкращої мережі
Подана мережа має один вихід, один вхід, і 20 перцептронів на проміжному шарі. На рис. 3 наводяться статистичні характеристики найкращої мережі.
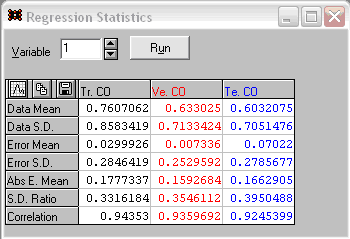
Рисунок 3 – Статистичні характеристики найкращої мережі
Аналіз статистичних характеристик показує, що коефіцієнт кореляції (Correlation) досить високий (наближається до одиниці), а відношення стандартного відхилення помилки прогнозу до стандартного відхилення вихідних даних дорівнює 0,354611 і є ближчим до 0, чим до 1. Це дозволяє зробити висновок стосовно адекватності моделі, що описується мережею.
Після донавчання мережі її статистичні характеристики покращилися (див. рис. 4), що дозволяє зробити висновок про ефективність процесу донавчання.
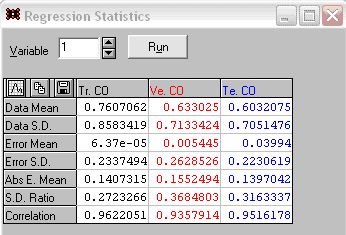
Рисунок 4 – Статистичні характеристики мережі, що донавчили
Спроба побудови прогнозу за допомогою вказаного методу не дала очікуваного результату, що пов'язано із стохастичною природою даних.
Надалі можна використовувати метод штучних нейронних мереж, наприклад, для аналізу залишків, отриманих за допомогою інших моделей.
3. Метод авторегресії і зінтеґрованого ковзного середнього (ARIMA)
Метод базується на використанні процесів авторегресії і ковзного середнього [7]. Є три типи параметрів моделі: параметри авторегресії (p), порядок різниці (d), параметри ковзного середнього (q). У загальноприйнятих позначеннях модель записується як ARIMA (p, d, q) і може бути представлена рівнянням (1):
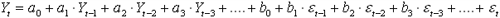 (2) (2)
де: Yt - поточне значення часового ряду; Yt-i - попередні значення часового ряду; a0 - вільний член; a1, a2, a3... (-1<ai<1) - параметри авторегресії; b0 - вільний член ковзного середнього; b1, b2, b3... (-1<bi<1) - параметри ковзного середнього; 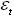 - випадкова компонента на поточному кроці моделювання; - випадкова компонента на поточному кроці моделювання; 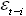 - - випадкова компонента на попередніх кроках моделювання. - - випадкова компонента на попередніх кроках моделювання.
У загальному вигляді процес вибору моделі [10] показаний на рис. 5.
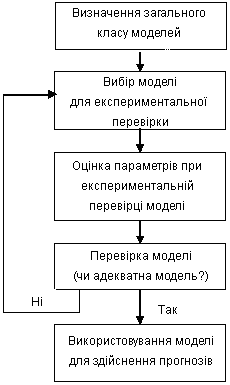
Рисунок 5 – Блок-схема стратегії вибору моделі згідно методу Бокса-Дженкінса
Визначення загального класу моделей починається з побудови діаграм автокореляційної і часткової автокореляційної функцій. Потім робиться спроба ідентифікації моделі виходячи з вигляду побудованих діаграм. Далі проводиться експериментальна перевірка ідентифікованої моделі, після чого проводиться оцінка її параметрів (середнього квадрата залишків, значущості коефіцієнтів та ін.). Наступним етапом є перевірка адекватності моделі, яка здійснюється за допомогою аналізу залишків. Якщо модель виявляється адекватною, її використовують для короткострокового прогнозування, інакше здійснюється пошук альтернативних моделей.
Використовуючи даний підхід, був проведений аналіз початкових даних у середовищі STATISTICA 6.0. Для аналізу використовувалися дані про концентрації діоксиду азоту (NO2), отримані шляхом програмної обробки бази даних Акіам. Графік початкового ряду представлений на рис. 6.
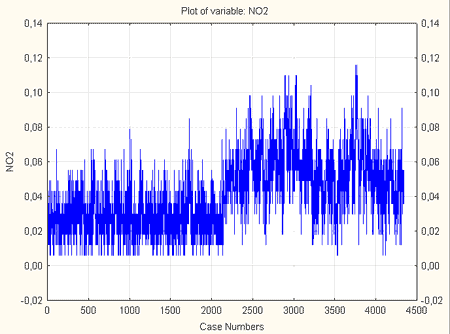
Рисунок 6 – Графік початкового часового ряду NO2
Для поданого ряду були побудовані моделі ARIMA, параметри яких підбиралися в діапазоні 0<=p, q<=2, 0<=d<=1. Результати побудови моделей для початкового ряду концентрацій NO2 наведені в табл. 1.
Таблиця 1 – Ідентифікація моделі динаміки часового ряду NO2
| № | p1 | p2 | d | q1 | q2 | MS residuals | Mx | Dx |
| 1 | 0,9404 | - | 0 | - | - | 0,00025 | 0,002496 | 0,000242 |
| 2 | 0,99878 | - | 0 | 0,81696 | - | 0,00016 | 0,000336 | 0,000160 |
| 3 | 0,52892 | 0,43768 | 0 | - | - | 0,00020 | 0,001409 | 0,000198 |
| 4 | 0,05430 | 0,94339 | 0 | -0,1444 | 0,79214 | 0,00016 | 0,000332 | 0,000160 |
| 5 | - | - | 0 | -0,7373 | - | 0,00093 | 0,024017 | 0,000350 |
| 6 | - | - | 0 | -0,8856 | -0,5616 | 0,00060 | 0,017051 | 0,000313 |
| 7 | - | - | 1 | 0,77300 | 0,06143 | 0,00016 | 0,000031 | 0,000160 |
| 8 | - | - | 1 | 0,82139 | - | 0,00016 | 0,000029 | 0,000160 |
| 9 | -0,4549 | - | 1 | - | - | 0,00020 | 0,000008 | 0,000202 |
| 10 | 0,07519 | - | 1 | 0,84789 | - | 0,00016 | 0,000031 | 0,000160 |
| 11 | -0,5941 | -0,3060 | 1 | - | - | 0,00018 | 0,000009 | 0,000184 |
| 12 | 0,07548 | 0,00084 | 1 | 0,84823 | - | 0,00016 | 0,000031 | 0,000160 |
| 13 | -0,9011 | 0,06010 | 1 | -0,1314 | 0,82604 | 0,00016 | 0,000031 | 0,000159 |
У наведеній таблиці p1, p2 – параметри авто регресії, d – порядок різниці, q1, q2 – параметри ковного середнього, MS residuals – середній квадрат залишків, Mx – середня арифметична залишків, Dx – дисперсія залишків.
Аналіз значущості коефіцієнтів pi, qi, загальної помилки моделі (середнього квадрату залишків), імовірнісних залишків показав, що найбільш оптимальними є моделі вигляду ARIMA(0, 1, 2), ARIMA(0, 1, 1), ARIMA (2, 1, 2), ARIMA(1, 1, 1), з яких було обрано модель ARIMA(1, 1, 1). Часткова автокореляційна функція (ЧАКФ) залишків поданої моделі приведена на рис.7, а автокореляційна функція залишків (АКФ) – на рис.8.
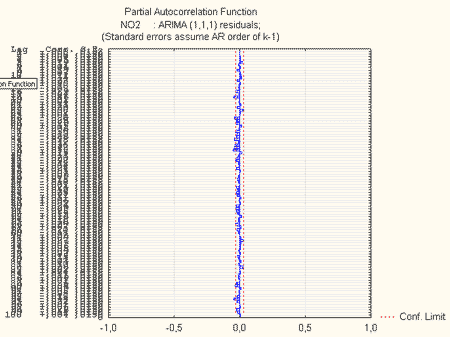
Рисунок 7 – ЧАКФ залишків
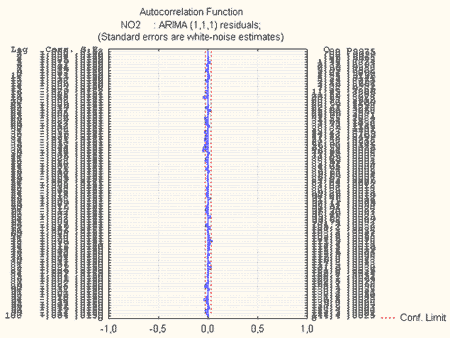
Рисунок 8 – АКФ залишків
З аналізу АКФ і ЧАКФ зрозуміло, що всі лаги не виходять за кордон допустимого інтервалу, позначеного на рис. 7, 8 пунктирною лінією. Це дозволяє зробити висновок про адекватність побудованої моделі.
Крім того, для вказаної моделі був побудований графік залишків на нормальному імовірнісному папері (рис. 9).
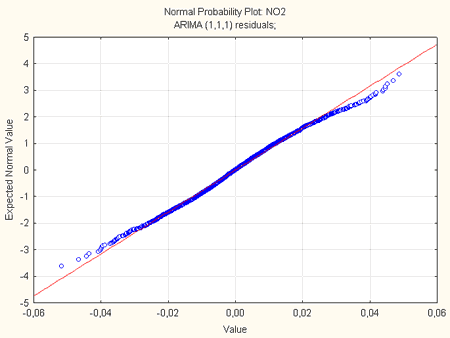
Рисунок 9 – Графік залишків на нормальному імовірнісному папері
З рис.9 випливає, що залишки підкоряються нормальному закону розподілу, що дозволяє зробити висновок про адекватність запропонованої моделі.
Відомо, що моделі виду ARIMA(1, 1, 1) описуються рівняннями вигляду (3).
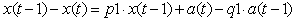 (3) (3)
звідки отримуємо (4).
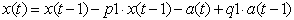 (4) (4)
Остаточне рівняння моделі має вигляд:
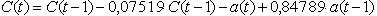 (5) (5)
де: C(t) – концентрація NO2 на даний момент часу, C(t-1) – концентрація в попередні моменти часу, a(t-1) – значення білого шуму в попередній момент часу, a(t) – значення білого шуму на даний момент часу. Параметри a(t) наведені в табл. 1.
Аналогічні дослідження були проведені і для інших спостережуваних речовин – оксиду вуглецю (CO) і діоксиду сірки (SO2).
Заплановані результати
Надалі в роботі планується реалізація наступних етапів:
- продовження пошуку оптимальної моделі прогнозування за допомогою методу ARIMA;
- перевірка адекватності отриманої моделі за допомогою спектрального аналізу, нейронних мереж та інших методів;
- розробка програмного забезпечення, що реалізовуватиме прогностичну модель;
- розробка екологічного порталу м. Макеївка і розміщення на ньому модулю прогнозування забруднення атмосферного повітря.
Висновки
Дана магістерська робота присвячена важливій проблемі прогнозування забруднення атмосферного повітря. В результаті виконання роботи буде отримана модель процесу забруднення атмосфери і розроблено відповідне програмне забезпечення. Особливістю роботи є те, що дані для дослідження знімаються на автоматизованих постах Донецька і Макеївки. Оскільки кліматичні умови в просторі змінюються незначно, модель може бути адаптована і для інших найближчих міст України.
На закінчення слід зазначити, що проблема забруднення атмосферного повітря одна з найгостріших екологічних проблем. Тому прогнозування забруднення атмосфери повинне використовуватися для здійснення зниження викидів і, як наслідку, зменшення забруднення атмосферного повітря.
Література
1. Впровадження нового механізму видачі дозвільних документів з викидів забруднюючих речовин в атмосферне повітря / Під. ред. С.В.Третьякова. — Донецьк: Державне управління екології та природних ресурсів у Донецькій області, Донецька філія Державного закладу «Державний екологічний інститут Мінприроди України», 2006. — 196 с.
2. Сонькин Л.Р. Синоптико-статистический анализ и краткосрочный прогноз загрязнения атмосферы. – Л.: Гидрометеоиздат.1991. – 250с.
3. Современные подходы к проведению расчетов загрязнения атмосферы [Электронный ресурс] : www.mgo.rssi.ru/l_model/air8.html
4. Методика расчета концентраций в атмосферном воздухе вредных веществ, содержащихся в выбросах предприятий. ОНД-86.: Госкомгидромет. 1986. – 68с.
5. Берлянд М.Е. Прогноз и регулирование загрязнения атмосферы. – СПб.: Гидрометеоиздат. 1985. – 272с.
|
