Этот документ описывает реализацию языковых средств стеганографии, которая основана на замене слов через IRC канал. Типичной проблемой лингвистической стеганографии является то, что трудно обращать внимание на семантические ошибки в получаемом результате. То есть, предложение может быть несогласовано с контекстом или быть неествественным. Таким образом, мы предлагаем решение, которое предусматривает взаимодействие человека в качестве стеганографического двигателя. Это позволяет строить предложения так, что они идеально подходят для IRC разговора. Чтобы обеспечить непрерывный поток частей сообщения, они шифруются с шифрами потока. Сложным аспектом этой работы является формирование слов замены таблицы, основанных на сессии стегоключа. Это потому, что приемлемое число синонимов должно быть доступно для каждого слова таким образом, чтобы взаимодействующие пользователи были в состоянии выбрать необходимые, подходящие по контексту, синонимы. Поскольку мы имеем дело с IRC каналом, могут быть введены орфографические ошибки и аббревиатуры для получения большего чиса альтернатив. Также наша работа связана с другими стеганографическими системами, такими, как автоматизированные лингвистические стеганографические системы.
Ключевые слова: лингвистическая стеганография, IRC, человеческие взаимоотношения, скрывая информацию
Стеганография это древнее искусство, наука для сокрытия информации вложенной в различные неприметные на первый взгляд сообщения. Уже в 16-ом столетии, существовало огромное количество литературы по стеганографии и методам кодирования информации. Стеганография (Trithemus, 1606), работа Йоханнес Trithemius (1462-1516), является хорошим примером использования стеганографии: на первый взгляд, она ассоциировалась с черной магией, и поэтому была включена в Индекс Librorum Prohibitorum ( "Список запрещенных книг") в Католической Церкви. Учитывая расшифровки ключа, он показывает только с криптографической и стеганографической стороны.
Проблема, в которой Элис и Боб являются заперты в отдельных камерах и им необходимо обговорить план побега так, чтобы не узнала смотритель Венди (противник), которая осуществляет мониторинг их сообщений. Это свидетельствует о том, что в отличие от криптографии, где значение этого сообщения прячется среди мишуры других символов, стеганография пытается скрыть тот факт, что определенное сообщение прячется. Мы имеем в виду законного объекта в сообщении, в качестве прикрытия объектов, а сообщение с встроенной информацией называется стегообъект. В стегосистеме создаются стегообъекты с встроенными сообщениями, используя стегоключ, таким образом, чтобы операция не могла инвертироваться тривиально. В стегосистеме, стегообъекты необходимо иметь возможность отличить от других объектов. Различают три достоинства стегосистем:
– вместительность: доля скрытой информации для покрытия информации;
– надежность: способность системы противостоять изменениям со стороны внешних факторов;
– незначительность: потенциал генерируемого стегообъекта возможно отличить от состояния других стегообъектов.
Хорошо известные современные примеры охватывают объекты аудио, изображений и видео. Они доступны в больших количествах, через Интернет, что делает обнаруживание противника скрытых сообщений сложнее. Самый распространенный способ шифрования в стегосистемах основан на LSB (наименьший значащий бит) замещениях.
Эта работа основывается на идеях, представленных Bergmair и Katzenbeisser, но с иным подходом. Прежде всего, мы не считаем, что противник Венди будет машина, возможно Венди является интеллектуальным пользователем. Таким образом, синонимы не могут быть использованы одним и тем же образом, как и в Bergmair системы, так как они могут быть обнаружены. Вместо этого, мы используем синонимы общеизвесттного тезауруса, которые вписываются в контекст текста. Это достигается путем соответствующего запроса с возможностью выбора синонимов, которые могут заменить выбранное слово. Пользователь должен выбрать синоним, что вписывается в контекст разговора, так, чтобы получился невинный разговор. Это задача, которую очень трудно сделать машине. Каждое слово в определенной части тезауруса представляет информацию, а разница между Боб (в приемнике) и Венди, заключается в том, что Боб может сделать связь между синонимами и информации, а не Венди (она даже не в состоянии обнаружить, существует ли эта информация). Основная идея – как присвоить код для слов, описанных в следующем разделе.
2.1 IRC
Для нашей конкретной реализации языковой стеганографии, мы решили использовать для передачи сообщений IRC канал. Преимущество такого канала заключается в том, что обе стороны, Алиса и Боб общаются непосредственно друг с другом в открытой части канала. Алиса может общаться с другими людьми в общественных местах, в то время как Боб контролирует разговор. Другим преимуществом IRC канала, является то, что они многочисленны, и что с помощью IRC можно общаться анонимно.
2.2 Настройка
Если Алиса хочет послать сообщение Бобу с помощью нашей системы, то мы исходим из следующего: Алиса и Боб знают заранее, какой канал, чтобы присоединиться и псевдоним, который они будут выбирать. Они знают публичные ключи друг друга и, как правило, используют систему, которая показана на рисунке 1.
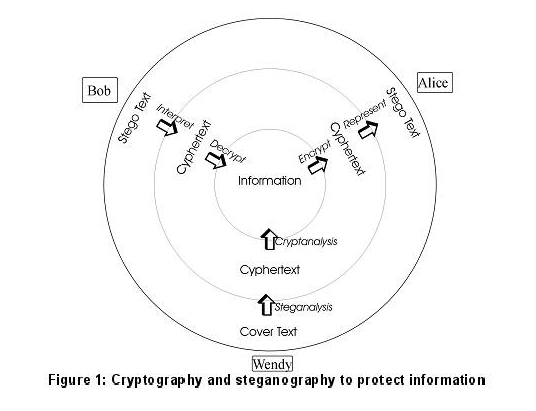
Она функционирует следующим образом: Алиса и Боб входят в тот же чат канала. Алиса отправляет секретное сообщение М в местной очереди, и указывает на то, что она хочет отправить его Бобу. Боб указывает на то, что он хочет получить сообщения от Алисы. В фоновом режиме согласовываетсяа секретный ключ K с использованием метода Диффи-Хелмана. Этот секретный ключ К используется для генерации слов замены таблицы на основе тезауруса, который у Алисы и Боба одинаковый. Секретный ключ K также используется для получения ключа сеанса Sk, используемого для шифрования Это послание М. Шифрование производится с использованием алгоритма шифрования потока (RC4), например, Боб может начать расшифровать сразу же после получения этого самого первого байта, как Алиса начнет общение через канал. Каждый раз, когда она отправляет сообщение, всплывает окно , в котором предлагаются некоторые слова замещения, основанный на замене слов таблицы. Это взаимодействие пользователей, где необходима автоматизация. Боб перехватывает стеготекст, расшифровывает слова с заменой, а затем расшифровывает передаваемое сообщение с использованием RC4 и ключом сессии Sk. Наш подход связан с известной работой, Bergmair и Katzenbeisser (2006). Согласно их подходу, информация может быть скрыта от автоматизированного наблюдателя (Венди), поскольку такой наблюдатель не может решить сложные проблемы искусственного. В нашей схеме, пользователь решает проблему согласования слов по контексту. Таким образом, в результате стеготекст будет неотличим от обычного текста, даже для человека наблюдателя
2.3 Таблица слов замещений
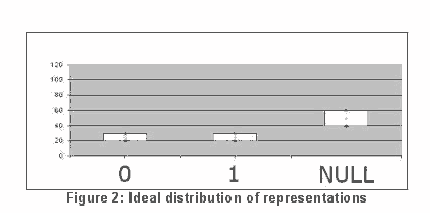
В нашей стегосистеме, каждый бит однозначно установленн для ключевых слов. Это означает, что каждый раз, когда слово, которое представляет собой «1» используются Алисой в IRC канале, будет декодировано как «1» Бобом. Ключевые слова подбираются с тезаурусом. Для этого проекта мы использовали английский тезаурус, включенный в OpenOffice. Выбор ключевых слов, и представление их битами происходит следующим образом: во-первых, все слова с небольшим числом синонимов отфильтровываются из тезауруса, чтобы достаточное количество необходимых синонимов можно было предложить пользователю. Ключ сессии, создается с использованием метода Диффи-Хэлмана, большой поток случайных ключей S генерируется. Затем, S используется для назначения разрядных значений слов, а ценность представляет два бита в С. Бит ценности может быть "0" (в 00 S), "1" (11) или NULL (10 или 01). NULL указывает на то, что это слово не является битным. Заметим, что слово может встречаться несколько раз в списке слов, в некоторых ситуациях. Этим словам будет присвоено разрядное значение. После назначения битов словам, детерминистский алгоритм выполняется распределение ( «0», «1», NULL) лучше, опять же, чтобы избежать ограниченности в выборе синонимов пользователем, что приведет к изменению контекста предложения. Точный алгоритм определения слова замещение таблицы еще в состоянии разработки. Мы разработали стратегию проверки, насколько хорошо работает замещение слов, исходя из количества вариантов замены слова, которые представляют определенный бит. В ( «0», «1», NULL) этом случае, идеальное положение, когда после (25% -25% -50%) распределения (см. Рисунок 2): 25% от синонимов представляют «0», 25% от синонимов представляют собой «1» и 50% от синонимов представляют «NULL». Разработчики сходятся на том, что пользователь имеет достаточно вариантов, чтобы выбрать один синоним, который подходит в контекст.
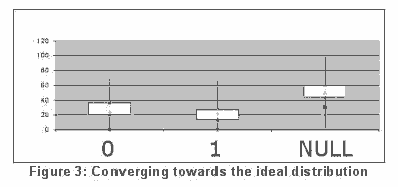
Мы уже разработали прототип алгоритма, который успешно генерирует достаточно хорошую таблицу замен (поле площадью распределения на рис 3), но испытания продолжаются.
Распределение, показанное на рисунке 3 получено следующим образом: во-первых, мы представляем слово в нашем списке, на основании разрядного потока S, о чем говорилось выше. Затем идет алгоритм коррекции.
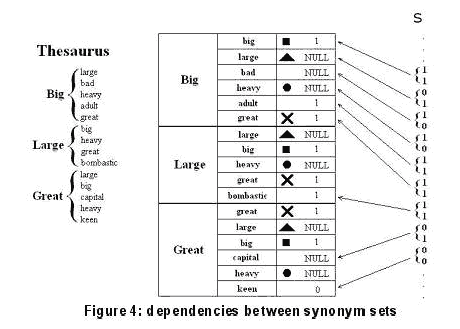
Построение таблицы: это детерминированный алгоритм гарантирует, что доля синонимов с NULL представлением выше 30% для любого данного слова. Основная проблема, заключается в том, что данное слово может встречаться несколько раз в качестве синонимов. Это означает, что любые изменения в представлении имеют прямые и обратные эффекты. Один из примеров можно увидеть на рисунке 4. Если представление «big» изменилось в синоним «большой», это будет иметь последствия на (ранее) синоним список «big» и (позднее) синоним список «великих».
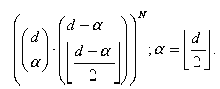
Основным моментом в нашем подходе, который отличается от упомянутой работы Bergmair (2004), заключается в том, что вместо разбалансировки синонимов список основан на методе Хаффмана, мы дисбалансируем список синонимов с помощью объединения с NULL, который Алиса почти всегда имеет возможность выбрать. Предварительные результаты также свидетельствуют о том, что случайная уступка битных строк (в нашем случае «0», «1» и NULL) для наборов слов вместо одного конкретного слова также обеспечивает более широкий набор возможной замены слова таблиц, которые будут созданы. Если это среднее число синонимов для каждого слова и N это количество слов, которые могут быть выбраны для замены, первым из имеющегося количества таблиц.
Эта цифра основана на упрощенном тезаурусе, как показано на рисунке 4. Для наших тестов на OpenOffice тезаурусе, D = 7 и N = 9732, после чего несколько слов с синонимами были отклонены. Это приводит к 210 ^ N возможных таблиц. Если Хаффман - подход с глубиной от 3 бит применяются, а затем 4 возможных набора кодов отображения могут быть присвоены каждому синониму, в результате чего 4 ^ N возможной замены слова таблицы. Более точная оценка для числа возможных таблиц должна быть сделано, но предварительные результаты свидетельствуют о том, что число возможных таблиц в нашем случае остается намного выше, чем в случае Хаффман-кодирования. В обоих случаях число возможных таблиц намного выше, чем число возможных ключей сессии. Таким образом, грубое нападение на таблицу слов замещения менее эффективна чем грубое нападение на ключ сессии. Недостаток нашего подхода заключается в меньшей вместительности. Через замещенные слова, в среднем 1 / 2 бит передаются, а это 7 / 4, в случае если Хаффман-подхода глубиной 3 биты.
2.4 Ограничения
Существуют также некоторые ограничения в использовании IRC с языковым замещением:
• Маленькая вместительность: как упоминалось выше, сумма покрытия текста, которым необходимо передать один бит достаточно высок, поэтому необходимы длительные сессии с большим количеством сообщений.
• Статистический анализ может выявить, что некоторые слова не стандартны для использования человеком.
• Выбрав один синоним, могут возникнуть некоторые грамматические ошибки. Некоторые из этих ошибок можно избежать с помощью технических средств. Из-за низкой вместительности систем, мы предлагаем их только для передачи коротких сообщений.
Цель нашего проекта заключается в том, чтобы построить IRC модуль для лингвистической стеганографии. Мы исследуем несколько IRC клиентов и X-Chat (X-Chat многоплатформенная программа, 2007). X-Chat был выбран потому что многоплатформенная платформе, с открытым исходным кодом, имеет графический интерфейс (с использованием GTK +) и имеет хорошо документированный плагин возможностей. В основном стеганография была написана на C и загружается с помощью плагина для X-Chat. В Диффи-Хэлман ключевых соглашенияч, имеется функция для расширения ключа K в S, и поток RC4 шифра предоставляется открыть SSL криптографические библиотеки (в OpenSSL Project, 2007).
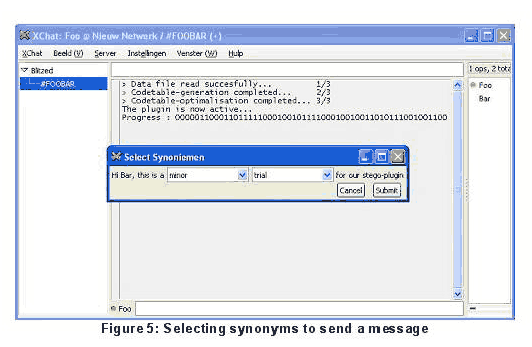
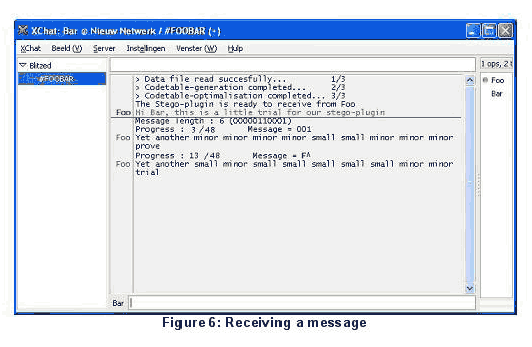
На рисунках 5, 6 проиллюстрировано, как плагин взаимодействует с пользователем при отправке и получении скрытой информации.
Лингвистическая стеганография является одним из наиболее передовых методов, чтобы скрыть информацию в тексте. Мы используем простые замены, чтобы быть уверенными в том, что контекст разговора не претерпел существенных изменений. При этом в автоматическом режиме потребуется
автоматизация текстопроцессорного смысла, что является сложной проблемой в области искусственного интеллекта. При частичном решении этой проблемы существуют полу-автоматические замены процесса. Другие улучшения и возможные направления будущих исследований включают:
а) строгий статистический анализ, который следует делать на некоторых испытуемых, чтобы увидеть, если их слова выбора существенно отличается от испытуемых.
б) чат без плагинов.
Учитывая, что чат регулярно работал без использования плагинов, частота слов может быть адаптирована специально для своих взаимодействий, что необходимо учитывать при создании таблицы слов замены . Кроме того, они должны быть исследованы, на сокращения и орфографические ошибки, которые ослабляют системы. Безопасность этой системы зависит также от структуры в Саури. Необходимо проводить анализ, чтобы обеспечить лучшую оценку количества таблиц, которые могут быть получены. Для защиты от активных злоумышленников, стегосистемы могли бы быть более надежными, добавив исправленные ошибки кода после шифрования.
Эта работа частично финансируется за счет Кандидат грант Института по развитию инноваций посредством науки и техники во Фландрии (IW T-Vlaanderen). Кроме того, при совместном финансировании со стороны IBBT (Междисциплинарный институт Широкополосных технологий), который основан при основан Фламандском Правительство в 2004 году. Авторы хотели бы также поблагодарить Александру Alderweireldt и Тим Thaens за реализацию представленных стегосистем как X-Чат плагина.
Bergmair,R. —Towards linguisticsteganography:A systematicinvestigationofapproaches, systems, and issues“. finalyearthesis, April2004. handed ininpartialfulfillment ofthe degree requirements forthe degree —B.Sc. (Hons.)inComputerStudies“ tothe UniversityofDerby.
BergmairR., KatzenbeisserS. —Towards humaninteractive proofs inthe text-domain“. InKanZhang and Yuliang Zheng, editors, Proceedings ofthe 7thInformationSecurityConference, volume 3225 of Lecture Notes inComputerScience, pages 257œ267. SpringerVerlag, September2004.
BergmairR., KatzenbeisserS. —Content-aware steganography:About lazyprisoners and narrow-minded wardens“. InProceedings ofthe 8thInformationHiding W orkshop, Lecture Notes inComputer Science. SpringerVerlag, 2006.
Chandramouli, R., Memon, N.D. —Analysis ofLSB based image steganographytechniques“. InProceedings of the 2001 InternationalConference onImage Processing (ICIP 2001),pages 1019-1022.
Simmons, G.J. —The prisonners‘problem and the subliminalchannel“. InD. Chaum, editor,Advances in Cryptology- CRYPTO‘83, Lecture Notes inComputerScience, pages 51œ67. Plenum Press, 1984. Trithemius, J. Steganographia. Frankfurt, 1606. The OpenSSLproject. http://www.openssl.org, accessed March13, 2007. Tor:anonymityonline. http://tor.eff.org/,accessed March13, 2007.
X-Chat multiplatform chat program. http://www.xchat.org/,accessed March13, 2007.
© Ларионова К.Е. 2009