(1.1)
Источник информации: библиотека учебных пособий Санкт-Петербургского государственного университета телекоммуникаций М.А.Бонч-Бруевича http://dvo.sut.ru
В данной главе проводится анализ существующих методов обработки (анализа) изображений с целью их распознавания и рассмотрены пути построения устройств оптико-электронной обработки изображений.
Распознавание можно трактовать как максимальное сжатие объема информации или устранение избыточности обрабатываем ых изображений. При решении этой задачи возникают две трудности: алгоритмическая и техническая (реализационная). Алгоритм сжатия должен быть достаточно надежным и вместе с тем по возможности экономным. В части опознания “абстрактных изображений” обучающиеся автоматы, использующие предложенные алгоритмы, порою дают больший эффект, чем человек. Поиск эффективных алгоритмов идет в настоящее время по пути исследования механизмов работы мозга, а также разработки и исследования различных программ распознавания. Наибольшие успехи достигнуты здесь в части процедур обучения автоматов в рамках выбранного класса алгоритмов опознавания [1].
Техническая трудность обусловлена, прежде всего, сравнительно малой скоростью и недостаточной емкостью памяти ЭВМ. Кроме того, обладая одномерным входом, они плохо приспособлены для ввода и обработки многомерных массивов информации.
В настоящее время определилось три основных направления развития методов распознавания изображений, это
Задача автоматического распознавания сводится к отысканию некоторой функции, отображающей множество образов (изображений) во множество, элементами которого являются классы образов. Процесс определения такой функции целесообразно проводить в три этапа [1]:
Первые два этапа – предварительная обработка изображений и выделение признаков с помощью ЭВМ представляет определенные трудности. Они связаны с вводом изображения, так как ЭВМ являются машинами последовательного действия, выполняющими в каждый момент времени только одну или максимум несколько арифметических операций; с избыточностью изображения, определяемого наличием мешающего фона, неопределенностью положения, ориентации, масштаба в связи с чем приобретают большое значение различные методы фильтрации изображений, нормировка, получение инвариантов и т.п. и, наконец, процедура формирования признаков, параметров первичного описания, которая представляет собой переход от двумерной функции (изображения) к системе чисел (признаков) и которую можно интерпретировать как задание некоторого функционала. Функциональные преобразования, связанные с решением интегральных уравнений так же вызывают большие технические трудности реализации их на ЭВМ [1-3], связанные с большой емкостью математических вычислений.
Третий этап решения задачи распознавания – классификация и обучение, связанный с реализацией алгоритмов и выполнения комплекса простых арифметических или логических операций может с успехом решаться на ЭВМ.
Таким образом, при распознавании изображений на ЭВМ возникают главным образом трудности, связанные с вводом изображений в машинное поле, с предварительной обработкой и выбором признаков, что занимает значительное время. Опыт решения задачи обработки на ЭВМ сложных изображений, какими, например, являются теневые картины и интерферограммы, показывает, на сколько сложен и трудоемок процесс фильтрации и коррекции искажений таких изображений [4]. Кроме того цифровой обработке присущи ошибки за счет дискретизации и амплитудного квантования, но они могут быть сведены до очень маленьких величин за счет повышения частоты дискретизации и увеличения числа уровней квантования. На практике точность ЭВМ ограничивается устройством считывания. Существующие системы могут обеспечивать точность считывания порядка 0,01% [2]. Но при решении задач распознавания обычно нет необходимости получения высокой точности выполняемых операций. Для каждой отдельной задачи распознавания имеется своя определенная специфика обработки изображений и выбора признаков, поэтому использование мощных, универсальных, дорогостоящих ЭВМ при решении многих задач становится не рентабельно. В связи с этим стало развиваться направление создания специализированных вычислительных устройств (процессоров), отвечающих требованиям данной конкретной задачи.
Одним из направлений создания таких процессоров являются телевизионные вычислительные устройства [5].
Как уже было сказано, для автоматического распознавания изображений необходимо проводить предварительную обработку изображений с целью сжатия информации и выделения признаков, причем измерение этих признаков должно быть просто реализуемо телевизионными методами, которые характеризуются способом преобразования изображения в видеосигнал, квантования и дискретизации видеосигнала, формирования признаков для распознавания и селекции объектов или их информативных фрагментов. При решении задач распознавания телевизионными системами можно выделить две группы задач. Первая - когда информация заключена в интегральных свойствах всего изображения (текстуры - облачный покров, интерферограммы и теневые картины и пр.). Такие задачи решаются путем анализа статистических свойств совокупности объектов, находящихся одновременно в поле зрения телевизионного датчика, без учета индивидуальных локальных свойств каждого из них в отдельности. Для сжатия информации таких изображений используют гистограммы распределения информативных параметров, наиболее связанных с применяемым методом разложения изображений. Например, при построчном разложении такими параметрами могут быть длины хорд объектов на определенном уровне оптической плотности при различных углах сканирования, число точек пересечения контуров объектов на строке и др. Вторая группа - распознавание отдельных объектов (или фрагментов) по заданным оптико-геометрическим параметрам и выделения их на фоне совокупности объектов, их подсчет, что является другим методом сокращенного описания изображений.
При анализе изображений типа “текстура” весьма информативными являются параметры, характеризующие распределение хорд по размерам, а изменяя положение изображения относительно растра, можно оценивать изотропность его структуры.
Таким образом, в процессе распознавания на различных этапах работы телевизионного вычислительного устройства выполняются различные логические операции, включающие преобразование и фильтрацию потока входной информации, сравнение, сопоставление, вычисление и др. Поэтому каждое отдельное устройство строится исходя из требований решения задачи.
В работе [6] рассматривается использование телевизионн ого вычислительного устройства совместно с управляющей ЭВМ для обработки интерферограмм и теневых картин. Описанная вычислительная система позволяет автоматически вводить оптическую информацию, содержащуюся на снимках в оперативную память ЭВМ и производить вычисления параметров светового потока. Система позволяет измерять координаты точки с заданным значением оптической плотности почернения на анализируемом сечении снимка, а также автоматически выбирать сечение, на котором производится анализ интерферограммы или теневой картины. Использование телевизионного сканирующего датчика совместно с управляющей ЭВМ позволяет корректировать ошибки, связанные с геометрическими искажениями. Точность определения координат в такой системе составляет 0,05 мм, максимальная регистрируемая оптическая плотность 1,5, при погрешности ее измерения 3%.
Что касается времени обработки изображений, телевизионными методами, то оно определяется в основном временем ввода. Так, например, при тактовой частоте шаговой развертки 1кГц изображение из 128x128 элементов квантования на 64 уровня яркости вводится за 1 минуту [6]. Таким образом, время обработки данным методом составляет в настоящее время единицы минут.
В последнее время значительно возрос интерес к оптическим методам обработки информации. Оптические методы и системы обладают рядом специфических особенностей, которые очень выгодно отличают их от других методов и систем обработки информации:
Все перечисленные возможности дают предпосылки для создания оптических и оптико-электронных систем и методов обработки информации, обладающих колоссальной емкостью и скоростью обработки, позволяющих обрабатывать огромные массивы информации, производительность которых в основном лимитируется только скоростью ввода и съема данных [7].
Используемые в настоящее время методы оптической обработки информации условно можно разделить на две группы:
Особую роль в оптической технике обработки информации играют голографические методы обработки информации, в основе которых лежит метод восстановления волнового фронта. Использование голографии позволяет на много порядков увеличить информационную емкость запоминающих устройств, осуществлять согласованную и Винеровскую фильтрацию изображений, улучшение изображений, кодирование изображений и т.п.
Таким образом, использование методов оптической обработки информации позволяет наметить новые пути создания высокопроизводительных аналоговых вычислительных машин, запоминающих устройств большой емкости, систем обнаружения сигналов и изображений в шумах и, наконец, распознающих систем.
Весьма отчетливо преимущества оптических методов проявляются в задачах автоматического распознавания зрительных образов, заключающихся в классификации изображений как известной, так и случайной формы в присутствии других изображений или шумов.
Попытки решения этой задачи чисто электронными методами приводят к созданию систем с малым быстродействием, позволяющих решать далеко не все классы задач. Зрительные образы со сложной структурой идентифицировать чисто электронными методами в настоящее время почти не удается.
В связи с этим представляется перспективным создание оптико-электронных систем, сочетающих в себе преимущества оптических методов обработки (двумерность, быстродействие) с достоинствами электронных (и в частности цифровых) систем (простота выполнения логических операций, универсальность, высокая точность в случае систем дискретного действия).
Заметим, что оптические аналоговые методы обработки при решении задач распознавания изображений наиболее целесообразно применять на входе системы с целью предварительной обработки изображений (фильтрация, оконтуривание и т.п.) и с целью формирования первичных параметров описания входного образа (“первичных признаков”).
С помощью специализированных аналоговых средств ряд операций над распознаваемыми объектами может быть осуществлен более эффективно, чем с помощью ЭВМ [8]. К ним относятся многие операции предварительного преобразования распознаваемых объектов, выделения и формирования признаков, хранения эталонов и сравнения с ними и ряд других. Реализацию же алгоритмов обучения и распознавания во многих случаях проще произвести с помощью ЭВМ, так как последние сводятся к набору большого числа арифметических или логических операций. При распознавании многомерных объектов, зависящих от двух и более переменных, к которым относятся зрительные образы (изображения), целесообразно использовать оптические аналоговые устройства. Большие перспективы для распознавания многомер ных объектов появились в связи с появлением когерентных источников света и открытием принципа голографической записи информации.
Использование методов оптической обработки информации позволяет наметить пути создания высокопроизводительных аналоговых вычислительных машин.
Преимущества этих машин по сравнению с ЭВМ должны особенно заметно выступать в тех задачах, где не требуется очень высокая точность выполнения операций обработки изображений.
Примером таких задач являются задачи распознавания.
Попытки решения задач распознавания зрительных образов чисто электронными методами приводят, как известно, к созданию громоздких систем с малым быстродействием.
Количественное сравнение преимуществ и недостатков цифровых и аналоговых оптических методов обработки в общем виде представляет весьма трудную задачу.
Проведем сравнение ЭВМ и оптического процессора по двум основным показателям - точности и времени выполнения операций, например, при вычислении линейных функционалов, встречающихся при решении задач распознавания.
В работах [8, 9] приводятся данные о точностных параметрах аналоговых оптических процессоров при вычислении линейных функционалов типа
![]()
(1.1)
где: f(x,y) - функция, описывающая обрабатываемые изображения ; j i(x, y) - некоторые выбранные функции двух переменных, причем для выбора функций j i(x, y) могут быть использованы различные системы; S – область задания аргументов x, y ; i= 0,1,2...N . Эти признаки помехоустойчивы, а также позволяют путем соответствующего выбора функций j i(x, y) и совокупности некоторых арифметических операций перейти к инвариантам относительно смещений, поворотов и изменений масштаба. В когерентном свете, благодаря возможности исключения постоянной составляющей, можно добиться большой стабильности величины mi и большой чувствительности измерения моментов высокого порядка. Операция (1.1) реализуется любым оптическим коррелятором, в то время как реализация двумерных моментов на ЭВМ встречает серьезные затруднения, так как требует перехода к формулам механических квадратур, содержащим очень большое число слагаемых (сотни и тысячи).
Данная операция может быть, например, реализована в устройстве, предложенном в [10] представляющем оптико-электронный аналоговый процессор. Точность вычисления величины mi с помощью подобного устройства составляет в лучшем случае десятые доли процентов.
Сравним теперь аналоговые оптические процессоры с ЭВМ по быстродействию при условии, что точность выполнения операций имеет один и тот же порядок.
Общее время выполнения операций складывается из времени ввода информации в машину, времени вычисления и времени съема:
Tвып.оп. = Тввода + Т выч+ Тсъема
(1.2)
Ввод информации в ЭВМ всегда производится последовательно, в то время как в оптических процессорах ввод может производиться как последовательно, так и параллельно. В последнем случае временем Тввода практически можно пренебречь. Последовательный ввод информации может производиться с одинаковой скоростью в обоих случаях, если информация вводится в оперативное ЗУ ЭВМ; если же используются внешние ЗУ ЭВМ, то время Тввода возрастет в несколько раз.
Вычисления в оптическом процессоре происходят практически мгновенно. В ЭВМ время вычислений определяется количеством требуемых машинных операций Q.
Для рассмотренного примера количество операций Q=N2, сложений и умножений. При погрешностях 10% и 1% Q составляет для нашего примера соответственно 6 · 104 и 6 · 106.
Для мощной ЭВМ (tслож = 0,65 мксек, tумн = 2 мксек), требуемое время вычислений составит Твычисл = Q (tсл + tумн) @ 0,2 сек при погрешности 10% и Твычисл@ 20 сек при погрешности вычислений 1%. Это минимальный выигрыш во времени, т.к. учтено только время вычисления и не учтено время ввода информации и съема данных.
Если ввод изображения в оптический процессор производится параллельно, то выигрыш времени на операции ввода определится величиной
Тввода =(tсч. + tкод.) N2, (1.3)
соответствующей времени ввода в ЭВМ. Здесь: tсч. - время считывания одного элемента растра, tкод. - время квантования одной аналоговой величины и кодирования ее АЦП машины. В случае ЭВМ tкод. @ 20 мксек.
Следовательно, Тввода > 1,3 сек. При использовании фототелеграфных аппаратов для ввода изображений Тввода возрастет до нескольких минут за счет большой величины tсч. Величина Тввода порядка 1,3 сек может быть достигнута путем использования телевизионных считывающих устройств, в которых tсч. может достигнуть порядка 0,1 мксек.
Таким образом, в рассматриваемом примере при точности порядка 10% выигрыш по быстродействию при последовательном вводе в оптический процессор составит порядка 0,2 сек, а при параллельном – не менее 1,5 сек. При точности же порядка 1% минимальный выигрыш составит около 20 сек.
Необходимо подчеркнуть, что приведенные выше количественные оценки носят сугубо ориентировачный характер и могут использоваться лишь для предварительного сравнения оптических процессоров с ЭВМ.
Другим характерным примером, характеризующим высокое быстродействие когерентно-оптических процессоров по сравнению с ЭВМ, может служить двумерное преобразование Фурье [3]. Так, например, двумерное преобразование Фурье изображения на 70 мм пленке с разрешением 100 линий на 1 мм (2 · 108 точек) когерентно-оптическая система выполняет практически мгновенно. Если развертывающее устройство ЭВМ считывает одну точку за 30 мксек, то только для считывания входного изображения потребуется более часа. При использовании алгоритма быстрого преобразования Фурье (алгоритм Кули-Таки), емкости памяти 4 · 108 слов и времени одной операции 30 мксек на выполнение двумерного преобразования Фурье потребуется около 1 часа.
В заключении следует отметить, что использование аналоговых оптико-электронных процессоров целесообразно при решении определенного круга задач, когда необходимы минимальные затраты времени на обработку и не предъявляются высокие требования к точности вычислений, как это имеет место и для поставленной задачи. Когда требуется получить большую точность вычислений, то преимущество остается за ЭВМ.
Необходимо также отметить, что перспективным является создание оптико-электронных (гибридных) систем, сочетающих в себе преимущества оптических методов обработки (двумерность, быстродействие) с достоинствами электронных цифровых (простота выполнения логических операций, универсальность, высокая точность) [11].
Как уже говорилось в предыдущем параграфе обработка и распознавание изображений представляет собой весьма трудоемкий процесс, поэтому решению вопроса автоматизации этого процесса уделяется большое внимание. В ряде задач обработку изображений необходимо осуществлять в реальном или квазиреальном масштабе времени. Важно подчеркнуть, что методы обработки и распознавания изображений, основанные на использовании ЭВМ и телевизионных вычислительных систем, не позволяют во многих случаях решать эти задачи с требуемым быстродействием, и подчас единственным методом, удовлетворяющим требованиям по быстродействию, является метод параллельной обработки с использованием аналоговой оптики [12].
При этом вопрос об оптимальных границах применения методов оптической обработки для решения задач распознавания изображений необходимо решать отдельно для каждой конкретной задачи. Тем не менее, можно сформулировать некоторые общие принципы применения оптических методов при построении систем распознавания изображений.
Рассмотрим в общем случае структуру системы распознавания изображений (рис.1.1) и проанализируем основные методы, используемые в распознавании с точки зрения пригодности средств когерентной оптики и голографии для их реализации [13].

Рис. 1.1. Функциональная схема системы распознавания изображений
Система распознавания состоит из устройства восприятия, которое обеспечивает ввод информации в машину, устройства предварительной обработки, обеспечивающего частичное сжатие информации, анализирующего устройства, формирующего функционалы (меры близости, коэффициенты разложения, выборки и т.п.), классификатора или решающего устройства, обрабатывающего, формирующего и выдающего решение, и блока обучения, обеспечивающего необходимые регулировки в процессе обучения в соответствии с выбранной программой. Анализирующее устройство и классификатор могут иметь отдельные блоки памяти. При иерархическом построении система может содержать несколько блоков анализа и классификации, используемых на различных этапах распознавания. Следует отметить, что “удельный вес” отдельных блоков системы может быть весьма разным. Последнее зависит от характера изображений, априорной информации, удачности выбора первичных параметров и класса решающих правил. Кроме того, возможно выполнение одними и теми же блоками нескольких функций.
Аналоговые когерентно-оптические устройства могут быть использованы для реализации любой части системы, показанной на рис.1.1. Однако, наибольший эффект может быть достигнут при реализации ряда информационно емких операций, не требующих большой точности, так как точность оптических аналоговых устройств обычно не превышает 0,5-1%. При решении задач распознавания изображений, описываемых функциями двух переменных, наиболее трудоемкими являются операции предварительной обработки и формирования признаков, требующих преобразования двумерных информационных массивов.
Для эффективного решения задачи классификации необходима информация о классах , позволяющая построить модель классов. Если модель известна, то можно заранее определить требуемое правило решения и сконструировать автомат, реализующий это правило. При этом мы получаем необучающуюся систему распознавания. Однако во многих случаях требуемая априорная информация о классах отсутствует, и это приводит к необходимости использования принципа обучения (“обучение на примерах”). Этот принцип состоит в том, что машине предъявляется реализация отдельных классов (обучающая выборка или последовательность) и она сама вырабатывает правило решения, выбирая его из некоторого класса правил, заложенных в нее при конструировании. При этом машина обучается правильно классифицировать реализации обучающей выборки. Если выборка достаточно представительна, то можно добиться того, что после обучения машина будет редко ошибаться при классификации других реализаций, не использовавшихся при обучении.
Если в процессе обучения машине сообщается принадлежность реализаций к отдельным классам, то говорят, что система обучаемая (“обучение с учителем”, “обучение с поощрением”), если не сообщается, то самообучающаяся. Процесс самообучения является более высокой ступенью в задачах распознавания, ибо предусматривает способность автоматического упорядочения обучающей выборки по классам (“выработку понятий”). Ввиду недостаточного развития этого важного направления, мы в дальнейшем не будем его касаться.
В процессе обучения машина накапливает информацию о классах в форме, удобной для классификации (в частности, она может просто запоминать сами реализации обучающей выборки и их принадлежность), и одновременно вырабатывает правило решения. Таким образом, здесь как бы сливаются воедино процессы построения модели классов и выработки правила решения. Проверка эффективности обучения производится на экзаменационной выборке.
Следует также отметить, что модели классов задаются обычно в одной из следующих форм:
Следует отметить, что процесс обучения может состоять в получении оценок для упомянутых выше неопределенных параметров или распределений. Таким образом, резкой границы между двумя рассматриваемыми методами распознавания не существует.
Выбор той или иной модели определяется особенностями классов распознаваемых изображений, а также соображениями достоверности правильной классификации и простоты реализации. При наличии достаточно полной модели классов решающее правило может быть относительно легко найдено. Так, например, в случае детерминистской и квазидетерминистской моделей естественно сначала определить близость опознаваемого изображения (f) до эталонных (fiэ). Для этого формируются некоторые функционалы - меры близости r(f ; fiэ). Наиболее часто используются следующие меры:
![]()
(1.4)

(1.5)
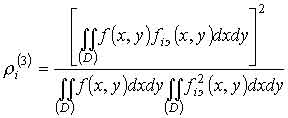
(1.6)
Первые две меры характеризуют уклонение от эталона, а третья является коэффициентом взаимной корреляции. Если используются подвижные эталоны, зависящие от параметров {aiэ}, то в качестве мер близости естественно задавать минимальные значения ri(1) и ri(2), но максимальное значение ri(3), достигается путем вариации этих параметров. Естественно, что меры (1.4)-(1.6) могут определяться не только в функциональном пространстве F первичного описания, где изображения задаются функциями f распределения яркости, амплитуды или фазы света, но и в векторном пространстве X первичного описания, когда изображения описываются семейством параметров {xk}- “первичных признаков”.
Формирование первичных признаков
Выбор в качестве первичных признаков распознаваемого изображения тех или иных физических величин определяется:
В каждой конкретной задаче важен правильный выбор “наиболее информативных признаков” распознаваемого изображения, так как он определяет лучшую конструкцию устройства и более широкие перспективы его использования.
В самом общем случае признаками распознаваемого изображения является набор чисел, которые согласно классическому представлению, являются координатами вектора объекта (изображения) в n-мерном пространстве признаков (n - число признаков). Переход от двумерной функции (изображения) к системе чисел (признаков) можно интерпретировать как задание некоторого функционала.
Считая этот функционал линейным, можно аналитически записать процесс извлечения признаков в виде скалярного произведения
xk = (f , jk)
(1.7)
где: jk - некоторая система функций; f - изображение; xk - количественная мера признака (число).
Такое описание процесса извлечения признаков было впервые дано А.А.Харкевичем [48].
Определяя (2.9) как
![]()
(1.8)
очевидно, что выбор признаков сводится к выбору системы функций jk(x,y), (k = 1,2,...N).
Выражение (1.8) формально совпадает с определением обобщенных моментов [15, 16] функции f относительно системы весовых функций jk. Частными случаями (1.8) являются: дискретные выборки (“рецепторное поле”), коэффициенты обобщенного ряда Фурье (случай ортогональных функций jk), степенные моменты (jjk = xjyk), выходы бинарных фильтров (jk=1, при (x,y)ОGk![]() ), коэффициенты разложения в обобщенный ряд Карунена-Лоэва [17] и т.п.
), коэффициенты разложения в обобщенный ряд Карунена-Лоэва [17] и т.п.
Следует отметить, что почти все известные методы получения признаков [15] фактически являются частными случаями метода обобщенных моментов.
Для задач распознавания случайных изображений в некоторых случаях может быть использован метод допустимых преобразований, позволяющий определить универсальное понятие сходства распознаваемого изображения и эталона. В этом случае предполагается, что изменения претерпевают эталонные изображения в определенной заданной области. Эта область эталонов, представляющая собой множество образов, получается из основного эталона с помощью определенных допустимых линейных преобразований. Этот метод учитывает две характерные трудности большинства задач по распознаванию – большое разнообразие образов и наличие случайных помех. Разнообразие распознаваемых образов учитывается путем описания множества эталонных образов в виде функции E (k,b), линейно зависящей от мешающих параметров k и b. Помехоустойчивость метода обусловлена тем, что при распознавании не требуется точного совпадения распознаваемого изображения с одним из эталонов, так как алгоритм распознавания сводится к отысканию максимума некоторой функции, выражающей сходство изображения и эталона по параметрам, от которых зависит эталон. Однако даже при сравнительно небольшом числе параметров отыскание максимума сходства представляет большие вычислительные трудности и требует метода динамического программирования.
Следует заметить, что этот метод по своей сущности близок к методу, основанному на использовании большого числа эталонных изображений. Действительно, можно трактовать совокупность эталонных изображений класса как множество “дискретных значений” некоторого динамического эталона, с которым производится сравнение распознаваемого образа.
Если классы распознаваемых изображений имеют характерные фрагменты qk(x', y'), то целесообразно их использование для формирования признаков:
![]()
(1.9)
где fk(x, y) = qk(x', y').
Обозначим области, занимаемые характерными фрагментами изображений, через Sk и будем использовать бинарные функции qk(x', y') вида
![]()
(1.10)
для формирования признаков:
![]()
(1.11)
Заметим, что этот важный вид признаков весьма просто реализуется в оптике путем использования диафрагм с фигурными окнами (для реализации mk достаточно спроектировать изображение на диафрагму с окном, соответствующим области Sk и проинтегрировать с помощью фотоприемника проходящий через окно световой поток).
Выбор области задания фрагментов (Sk) определяется эвристически, а способы реализации описаны в [18].
Общим соображением при выборе Sk является следующее: желательно выбирать такие подмножества фрагментов, которые с одной стороны хорошо описывают данный класс, а с другой стороны – редко встречаются в изображениях остальных классов.
Для получения признаков могут быть использованы коэффициенты разложения по полным ортогональным системам функций {j ik} [18, 19]. К ним следует отнести тригонометрические многочлены, полиномы Лежандра, полиномы Чебышева, а также функции Радемахера, Хаара, Уолша и некоторые другие. Также могут быть использованы для формирования признаков квазиортогональные системы функций, например, двумерные бинарные случайные функции. Такие функции обладают с точки зрения формирования признаков одним существенным преимуществом по сравнению с функциями Уолша, Радемахера, Хаара и др., которые характеризуются увеличением частоты элементов структуры с ростом номера реализации функции (т.е. изображение становится все более и более мелкоструктурным). Поэтому, с одной стороны при использовании функций Уолша структура изображения оказывается не связанной со структурой оптической маски с записью реализации используемой системы функций, а с другой стороны при необходимости большого числа признаков реализации функций типа Уолша высоких порядков не обеспечат достоверное измерение признаков вида (1.9), поскольку различие между величинами соседних признаков будет соизмеримо с ошибками измерения в оптике.
В то же время использование случайных бинарных функций позволяет выбрать частоту дискрета в соответствии с размером элементов изображения и избежать указанных трудностей.
Важным достоинством этих систем является универсальность получаемой системы признаков, основанная на полноте систем функций (при увеличении числа признаков точность описания изображений неограниченно возрастает). Однако за это качество приходится расплачиваться неэкономичностью описания - требуемое число признаков может быть весьма значительным (до нескольких десятков). В этом смысле признаки типа коэффициентов разложения по полным системам {j ik} противоположны “фрагментам” (1.11). Признаки типа “фрагментов” не образуют полной системы, не универсальны, но зато могут давать чрезвычайно экономное описание.
Формирование пространственно-частотного спектра (ПЧС) и его обработка
В ряде работ [20, 21], посвященных проблеме автоматического распознавания изображений, отмечается полезность применения спектрального описания изображений.
Под двумерным пространственным спектром изображения f(x,y) понимается комплексная в общем случае функция F(u, v), связанная с f(x,y) следующим соотношением:

(1.12)
Такое описание изображений обладает существенными преимуществами, полезными при распознавании.

(1.14)
Несмотря на то, что преимущества, вытекающие из использования пространственных спектров изображений, при их распознавании были выявлены давно, трудности, связанные с вычислением спектров на ЭВМ, не позволили использовать спектральное описание для распознавания двумерных изображений. Однако с развитием аналоговой оптической обработки появились работы, посвященные использованию пространственных спектров при распознавании образов [20,21].
Рассмотрим подробнее метод дискретизации. Это метод основан на систематическом изучении свойств пространственных спектров и их связи с исходным фотографическим изображением, т.е. тех свойств, пространственных спектров, которые соответствуют важным с точки зрения конкретной задачи распознавания свойствам исходных фотографических изображений. Изучив такие свойства пространственных спектров, можно выбрать способ (геометрию) дискретизации, сохраняющий необходимую нам информацию и уменьшающий объем информации, подлежащей передаче в решающее устройство. Дискретиз ация пространственного спектра сводится к измерению количества света в пределах заданных участков пространственного спектра. Это можно осуществить с помощью набора дискретизирующих окон, покрывающих в совокупности весь пространственный спектр. Каждое окно помещается в частотную плоскость и свет, проходящий через окно, измеряется и преобразуется в число. Набор таких чисел (дискретизационный знак) поступает в решающее устройство. В работе [20] описывается ряд наборов спектральных окон различной конфигурации (геометрий-дискретизации), пригодный в основном для выявления регулярностей (периодичность одномерная и двумерная, линейная структура) в изображении.
Интегрируя световую энергию вдоль окружности с центром на оптической оси, мы получаем полный вклад одной частотной составляющей спектра независимо от направления.
В действительности, окна в виде концентрических колец имеют конечную ширину и учитывают вклад не одной, а нескольких частотных составляющих. Причем конечная ширина окна выгодна тем, что уменьшает чувствительность выборки к незначительным изменениям в изображении (за счет шумов). Набор таких окон (рис. 1.2 а-в) позволяет получить набор величин,
 ,
,
j=1,2,..., ![]() ,
, ![]()
(1.15)
по которым можно судить о наличии одно- или двумерной периодичности в изображении.
Радиальная линия в частотной плоскости соответствует единственному направлению в изображении, которое включает все частотные компоненты. Набор величин

(1.16)
характеризует все направления, если qj(j=1,2,...,n) покрывают сектор от 0 до 3600. На практике используется дискретизирующее окно клинообразной формы. Такое окно определяет вклад от небольшого числа смежных направлений и обладает тем преимуществом, что уменьшает число необходимых выборок и снижает влияние небольших изменений. Набор дискретизирующих окон клинообразной формы позволяет получить описание амплитудного спектра вдоль радиального направления. Этот метод дискретизации нечувствителен к масштабу изображения.
Заметим, что по существу “метод дискретизации” спектра представляет собой частный случай метода обобщенных моментов амплитудного спектра.
Таким образом, представляется целесообразным применение спектрального описания изображений при их распознавании по методу обобщенных моментов. При этом важнейшим преимуществом спектрального описания является его инвариантность к сдвигу.

Рис. 1.2. Набор оптических окон, используемых при обработке пространственно-частотных спектров
Как уже говорилось, успешное решение задачи автоматической классификации изображений определяется в основном выбором системы информативных признаков. В оптико-электронных системах [10-22] искомые признаки можно выделять с помощью двумерных функций-масок [13], устанавливаемых либо в оптическом звене оптико-электронного классификатора, либо формируемых электрическим путем в тракте обработки видеосигнала в оптико-телевизионных системах. Выбор соответствующих масок производится, как правило, на основе выявленных структурных особенностей классифицируемых изображений [21]. В случае классификации изображений “текстур” выбор подходящих масок затруднен вследствие того, что особенности “текстур” скрыты в их статических характеристиках.
В данном параграфе рассматриваются бинарные случайные маски, которые предлагается использовать для выделения признаков изображений “текстур”. В основу формирования бинарных случайных масок положен принцип согласования их пространственных спектров со спектрами распознаваемых изображений “текстур”.
Простейший тип бинарной маски – изображение регулярной решетки. Такая маска воздействует на классифицируемое изображение как фильтр пространственных частот, передаточная характеристика которого может быть представлена в виде [23]:

(1.17)
где z – комплексная переменная, n и k – целые числа.
Если допустить, что n = f (x), а k = f (y), причем f (x ) и f (y) – некоторые случайные функции, то выражение (1.17) будет характеризовать передаточную функцию случайной маски. Спектральные особенности такой маски характеризуются статистикой расстояний между ее элементами. Для маски со счетным числом элементов и изотропными свойствами можно определить среднее расстояние:

(1.18)
где m – число элементов маски, ds- расстояние между любой s парой элементов, C – знак сочетания.
Для определения полосы пространственных частот случайных масок предлагается априорно выделить из представленного к обработке массива изображений теневых картин изображения с предельными пространственными частотами. В них находятся средние расстояния между элементами структуры изображения, и для дальнейшего определения основных статистических параметров случайных масок предлагается, с точки зрения упрощения методики дальнейшего анализа, использовать периодические маски. Причем пространственные частоты этих масок должны соответствовать предельным пространственным частотам обрабатываемых изображений текстур. В качестве примеров таких масок с предельными пространственными частотами рассмотрим 9- и 16-элементные периодические маски (М9 и М16) (Рис. 1.3 а, б).

Рис.1.3. Изображение 9-элементной (а) и 16-элементной (б) периодических масок
Для периодических масок расстояния по соответствующим осям

(1.19)
Рассмотрим распределение ds расстояний между любой s парой элементов для изображений периодических масок. В табл. 1 приведены распределения ds (значения ![]() определяются расстоянием перехода с одной строки на другую) для изображений М9 и М16 периодических масок. (Направление обхода элементов показано пунктиром на рис. 1.3).
определяются расстоянием перехода с одной строки на другую) для изображений М9 и М16 периодических масок. (Направление обхода элементов показано пунктиром на рис. 1.3).

Рис.1.4. Распределения ds 9-элементной (а) и 16-элементной (б) периодических масок
Гистограммы распределения ds в масках М9 и М16 показаны на рис. 1.4. Заметим, что линии АС, соединяющие концы гистограмм, имеют одинаковый наклон, который для выбранных масштабов составляет угол 300 к оси абсцисс, что можно объяснить схожими топологическими свойствами обоих изображений.
Для изображений с другими топологическими свойствами, где, например, больше расстояний типа ![]() (см. рис. 1.3 а), гистограмма расстояний для маски М9 (рис. 1.5), начиная со значения 2 по оси абсцисс, поднимается выше и в силу интегрального характера оценок ds величина угла a между осью абсцисс и линией, соединяющей концы гистограмм, изменится, т.е. по величине угла a можно судить о степени близости топологических свойств произвольного изображения к структуре периодической маски.
(см. рис. 1.3 а), гистограмма расстояний для маски М9 (рис. 1.5), начиная со значения 2 по оси абсцисс, поднимается выше и в силу интегрального характера оценок ds величина угла a между осью абсцисс и линией, соединяющей концы гистограмм, изменится, т.е. по величине угла a можно судить о степени близости топологических свойств произвольного изображения к структуре периодической маски.

Рис.1.5. Гистограммы распределения ds 9- и 16-элементных периодических масок
Другое свойство периодических масок определится, если, воспользовавшись данными табл. 1 найти из распределений ds значения ![]() для масок М9 и М16. Тогда соответственно
для масок М9 и М16. Тогда соответственно ![]() ;
; ![]() . Если из точек, соответствующих
. Если из точек, соответствующих ![]() оси абсцисс, восстановить перпендикуляры до пересечения с линиями АС, то оказывается, что
оси абсцисс, восстановить перпендикуляры до пересечения с линиями АС, то оказывается, что
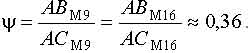
(1.20)
Таким образом, угол a и значение y могут быть использованы в качестве признаков, характеризующих топологические свойства периодических масок.
Предположим, что такие соотношения существуют и для изображений с другими топологическими свойствами. Рассмотрим анизотропные периодические маски. Они легко образуются из уже рассмотренных
масок, если принять dx = kdy
. При
k = 2 получим a = 16°, y = 0,41. Значения ![]() при этом вычислялись по формуле (1.19), а угол a как
при этом вычислялись по формуле (1.19), а угол a как

(1.21)
где a, b – масштабные коэффициенты, N – количество заданных расстояний,
dmax и dmin – максимальное и минимальное расстояния между элементами изображения.
Рассмотрим также изображение, полученное из периодических масок, для которого dmin = 0,5. Проделав все расчеты, можно убедиться, что линия АС имеет тот же наклон к оси абсцисс a = 30°, , a y
» 0,36. Таким образом, можно сделать вывод, что представление бинарных изображений масок в пространстве a , y позволяет разделить их на два класса – изотропные, для которых ![]() ; y » 0,036, и анизотропные, для которых
; y » 0,036, и анизотропные, для которых ![]() ; y » 0,41.
; y » 0,41.
Таким образом, если изображению произвольной случайной маски соответствуют такие a и y , при которых  , то изображение имеет изотропную структуру и наоборот, если
, то изображение имеет изотропную структуру и наоборот, если  , изображение анизотропно.
, изображение анизотропно.
Изображение случайной маски удобно синтезировать случайной импульсной последовательностью [24] со средним интервалом между импульсами ![]() и дисперсией s2, в которую замешан периодический импульсный сигнал с длительностью импульса
и дисперсией s2, в которую замешан периодический импульсный сигнал с длительностью импульса ![]() и скважностью 2.
и скважностью 2.
Для нахождения точки В гистограммы (рис. 4), учитывая только случайную составляющую сигнала, можно положить
![]()
(1.22)
Тогда, в соответствии с выражением (1.19)

(1.23)
с учетом периодической последовательности

(1.24)
где n – число импульсов в периодической последовательности.
Пусть также ![]() удовлетворяет условию
удовлетворяет условию
![]()
(1.25)
Это означает, что расстояние между соседними двумя элементами случайной маски не превышает длительности строки. Тогда

(1.26)
Можно показать, что при определенных значениях ![]() , когда число импульсов в периодическом сигнале много меньше числа импульсов в случайной последовательности, стандартное отклонение
, когда число импульсов в периодическом сигнале много меньше числа импульсов в случайной последовательности, стандартное отклонение ![]() . Это означает, что для формирования случайных масок можно использовать случайные импульсные последовательности, распределение интервалов между импульсами в которых подчиняется закону Пуассона.
. Это означает, что для формирования случайных масок можно использовать случайные импульсные последовательности, распределение интервалов между импульсами в которых подчиняется закону Пуассона.
Таким образом, задавая параметры случайной импульсной последовательности ![]() , s и m, можно синтезировать случайную маску, статистические характеристики которой будут соответствовать характеристикам рассматриваемого класса изображений “текстур” [25,26].
, s и m, можно синтезировать случайную маску, статистические характеристики которой будут соответствовать характеристикам рассматриваемого класса изображений “текстур” [25,26].
Анализ оптических методов обработки двумерной информации показал преимущество этих методов по сравнению с электронными методами (обработка в ЭВМ и телевизионные методы). Рассмотренные методы реализации аналоговой оптической обработки изображений при построении корреляторов, при формировании обобщенных моментов, при использовании метода дискретизации ПЧС для определения “первичных признаков” обрабатываемых изображений показали простоту их реализации и преимущества перед ЭВМ.
Рассмотренный метод формирования первичных признаков при обработке изображений “текстур” с использованием бинарных случайных функций (масок) и рассмотренная методика формирования бинарных случайных масок с использованием ЭВМ, позволяющая согласовать их пространственные частоты с пространственными частотами обрабатываемых изображений на практике дали высокие результаты при распознавании этого вида изображений.