Столяр Олександра Ігорівна
Факультет: комп'ютерних інформаційних технологій і автоматики
Кафедра: автоматизованих систем управління
Спеціальність: інформаційні управляючі системи
| RUS | ENG | ДонНТУ | Портал магістрів |
 |
|
Розробка комп’ютерної підсистеми прогнозування доходу телекомунікаційного підприємства на основі даних біллінгової системи |
|
Науковий керівник:
|
Автореферат
кваліфікаційної роботи магістра
Зміст
- Вступ
- Актуальність теми
- Зв‘язок роботи з науковими програмами, планами, темами
- Мета та задачі розробки й дослідження
- Очікувана наукова новизна
- Практичне значення роботи
- Огляд досліджень і розробок по темі
- Основний зміст роботи
- Висновки
- Список літератури
Кількість видів телекомунікаційних послуг постійно зростає, а їх об‘єми вар‘юются від одного клієнта до іншого, змінюютться в часі, залежат від сезонних змін тощо. Взаємозв‘язки між об‘ємами послуг різнихвидів неочевидні: чиіснують сховані зв‘язки між послугами, яка “сила” цих зв‘язків і до чого призведуть мождливі зміни об‘ємів наданих послуг? Відповіді на ці й подібні питання мають практичне значення, що дозволяє прогнозувати зміни об‘ємів і, відповідно, єкономічні єфекти, властиві тій чи іншій ситуації, щоскладається на ринку телекомунікаційних послуг [1].
Вирішення проблеми розробки моделей виявлення закономірностей в телекомунікаційному трафіку, що дозволяє раціонально перерозподіляти ресурси оператора, є актуальною. Телекомунікаційним компаніям зі збором і дослідженням даних про клієнтів допомагає система біллінга [2].
Застосовуючи до телекомунікаційного бізнесу біллінг представляє собою автоматизовану систему розрахунку за надані компанією послуги, їх тарифікації та виставлення рахунків оплати, яка забезпечує оператору зв‘язку значні ресурсні можливості. Інформація про абонента з‘являєтться в спеціалній клієнтскій базі від моменту його підключення до телефонної мережі. Окрім соціально-демографічних даних користувача (стать, вік, місце проживання) біллінгова система може надати дані про платежі, активність користування зв‘язком, тарифний план, наявніст тих чи інших послуг, нарахуваннях зарозрахунковий період тощо [3].
Інформація, що міститься в клієнтскій базі, аналізуєтся йсистематизується за різними критеріями з використанням методів математичного аналізу. Спеціалісти можуть зробити вигрузку необхідних даних під час планування маркетингових ініціатив або розрахувати єфективність уже існуючих програм. Таким чином, біллінгова система надає можливівсть прогнозувати, відсліджувати, корегувати й, у кінці оцінювати будь-які маркетингові продукти [4].
Існує внутрішньокорпоративна система статистики, яка включає в себе фінансову та маркетингову звітності. Ця загальна статистика складається за оркемими параметрами як регулярно, так і занеобхідністю. На її основі формуються пропозиції масовому клієнту, оскільки за допомогою такої звітності багато чого можназмоделювати та спрогнозувати.
Використовуючи дані біллінгу, співробітники спеціалізованого маркетингового відділу можуть виділити одного конкретного клієнта або групу клієнтів, об‘єднаних за яким-небудпараметром, для запропонування їм немасового продукту. Це дозволяє компанії вирішити дві задачі. По-перше, щоб спрогнозувати профіль споживання нової послуги більш численною аудиторією, на деякий час нею пропонують користуватися малій кількостіклієнтів. У даному випадку за ними просто стежать (слідкують, скільки абонентів погодилися на підключення, як змінюється попит на послуги), щоб зрозуміти, як працює нова пропозиція [5].
Крім того, обробка абонентської бази надає можливість перевірити гіпотези маркетологів щодо залежності між профелем споживання зв‘язку та додатковими послугами, які можут бути цікавими користувачеві. Таким чином, компанія може напряму запропонувати абонентові послугу, орієнтовану або конкретно на нього, або на достатньо вузький сегмент споживачів.
У системі може бути встановлена нескінченна кількість тарифів і тарифних планів. Кожна послуга може мати декілька різних тарифів. Кожному клієнтові може бути призначений індивідуальний тарифний план. Крім того, окремий тарифний план може бути призначений на кожний окремий екземпляр заказаної клієнтом послуги, зв‘язаний із визначеним ресурсом, яким користується клієнт .
Такий підхід дозволяє задовольнити потреби операторів, які мають велику кількість ресурсів різних типів. Таких як операторів телефонних фіксованих мереж, мереж стільникового радіотелефонного зв‘язку, мереж рухомого радіотелефонного зв‘язку, мереж персонального радіо виклику, мереж передачі даних, мереж доступу до Інтернет, змішаних й інших мереж [6].
За допомогою одного й того ж наданого ресурсу можна надавати декілька видів послуг, які можуть тарифікуватися по-різному. Наприклад, підключений телефонний апарат і відповідна телефонна лінія можуть використовуватися для надання місцевого, між городнього та міжнародного з‘єднання. Згідно з цим можуть розрізнятися й тарифи на послуги. Оплата ж усіх цих послуг здійснюється за єдиним рахунком, що дозволяє підвищити ефективність роботи системи.
Для того, щоб ефективно оцінити фінансовий результат, який потягне за собою зміни існуючих тарифів або впровадження нових тарифних пакетів, нам необхідно знати (спрогнозувати) декілька параметрів. По-перше, зміна кількості користувачів у даному тарифі – скільки абонентів перейде на новий тариф, скільки залишиться в існуючому тарифному пакеті. І, по-друге, динаміку зміни об‘єму послуг, які споживаються абонентом у даному тарифі. Необхідність прогнозування даних параметрів очевидна, оскільки будь-які зміни в тарифах призведуть до фінансових результатів: грошових втрат або росту доходу [7].
3. Зв‘язок роботи з науковими програмами, планами, темами
Кваліфікаційна робота магістра виконувалася протягом 2008-2009 рр. у відповідності до наукових напрямків кафедри «Автоматизовані системи управління» Донецького національного технічного університету.
4. Мета та задачі розробки й дослідження
Метою магістерської роботи є створення комп‘ютеризованої підсистеми прогнозування доходів телекомунікаційного підприємства на основі даних біллінгової системи (системи щомісячного розрахунку з абонентами за надані послуги) в умовах ЗАТ «Фарлеп – Телеком - Холдинг».
Ідеєю роботи є використання сучасних систем обробки даних і систем інтелектуального аналізу даних, класичних статистичних методів прогнозування та їх модифікації.
Для реалізації ідеї та досягнення мети магістерської роботи поставлені наступні задачі:
- проаналізувати методичні та теоретичні матеріали з математичної статистики, статистичним методам, нечіткої логіки та теорії нейронних мереж;
- проаналізувати системи обробки даних і вибрати інструментарій для досягнення поставленої мети магістерської роботи;
- розробити програму для отримання прогнозів, керуючись вивченим теоретичним матеріалом.
Предмет розробки й досліджень: статистичні дані, надані біллінговою системою.
Об‘єкт розробки й досліджень: динаміка зміни споживання абонентами послуг зв‘язку, а також динаміка переходів клієнтів із одного тарифу в інший [9,10].
Методологія і методи досліджень. У процесі дослідження буде використовуватися формальний апарат теорії нечіткої логіки, а також теорії нейромереж
Очікувана наукова новизна полягає у використаному методі прогнозування. У якості основного метода планування й прогнозування доходів я вважаю доцільним використання модифікованого метода, що поєднує в собі теорію нечіткої логіки та нейронних мереж. Для підвищення об‘єктивності прогнозування використовуються технічні індикатори, що представляють собою математичні моделі аналізу часових рядів різного рівня складності. Звичайно, існують методи прогнозу, засновані на використанні більш витончених математичних теорій. Проте вони не набули широкого застосування, й не через складність розуміння, а тому, що не дали на практиці помітної переваги порівняно з більш простими та традиційними методами.
Дуже багато практиків стверджує, що основа успіху – в чіткому та правильному використанні простих методів, а ускладнення прогнозу призводить до неправильної впевненості й, у результаті, до збитків. Обрана методика дозволить об‘єднати переваги всіх методів, що входять до її складу, та побудувати найбільш точну й ефективну прогнозну модель із найменшою похибкою прогнозу даних.
- досліджено й систематизовано теоретичні відомості, що стосуються питань статистики;
- відібрано та проаналізовано класичні, найбільш популярні статистичні методи прогнозування;
- досліджено сучасні методи прогнозування, що базуються на нейронних мережах;
- досліджено існуючий програмний пакет Matlab Simulink;
- практична значимість роботи полягає в розробці програми, що здійснює прогноз доходу телекомунікаційного підприємства на основі даних біллінгової системи.
7. Огляд досліджень і розробок по темі
На локальному рівні (в межах ДонНТУ) портал магістрів може надати інформацію про 15 подібних робіт, у яких вирішуються різноманітні задачі прогнозування, проте конкретно задача прогнозування доходів не розглядається.
Під час розробки алгоритму вирішення задачі враховувалися такі вимоги як: відсутність інформації про можливі маршрути проходження трафіка, швидкі зміни ділової середи ринку зв‘язку, пов‘язані з розвитком конкуренції, інформаційних технологій, можливість багатоваріантного моделювання виробничих ситуацій. На рисунку 7.1 запропонована схема взаємодії оператора й абонента.
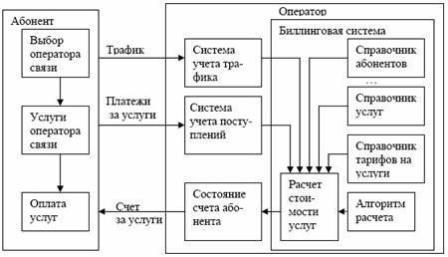
Рисунок 7.1 - Схема взаємодії оператора й абонента з використанням біллінгової системи
На національному рівні (в межах України) та на глобальному рівні було розроблено й досліджено такі методи:
Регресійно-когнітивне моделювання
Даний розділ присвячений дослідженню нового класу регресійно-когнитивних моделей (РКМ). Когнітивний підхід до підтримки прийняття управлінських рішень орієнтований на те, щоб активізувати інтелектуальні процеси експерта й допомогти йому зафіксувати своє уявлення про проблемну ситуацію у вигляді формальної моделі.
У якості такої моделі зазвичай використовується так звана когнітивна карта ситуації (А.Кулинич, Ф. Робертс, Д. Хейс), яка представляє відомі експертові основні закони та закономірності ситуації, що спостерігається, у вигляді орієнтовного знакового графу, в якому вершини графу – це фактори (характеристики ситуації), а дуги між ними – причинно-наслідкові зв‘язки [8].
Графова модель такої карти характеризується наявністю вершин-факторів та дуг, позначених знаками «+» та «–». Така розмітка визначає позитивні та негативні зв‘язки між факторами. Приклад когнітивної карти деякої ситуації для ринку телекомунікаційних послуг представлений на рисунке 7.2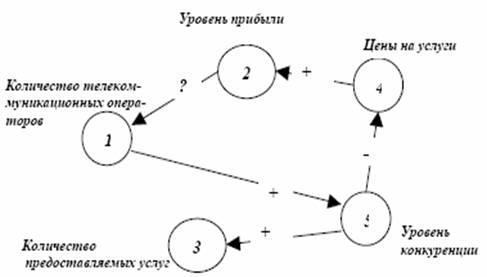
Рисунок 7.2 - Приклад когнітивної карти ситуації
Враховуючи ці фактори створюється модель досліджуваної ситуації як сукупність гіпотез, здатних пояснити розвиток системи. Крім того, створюються гіпотези, здатні пояснити механізми впливу між тими або іншими факторами системи та встановити причинно-наслідкові зв‘язки між ними [8].
Такі взаємозв‘язки, як правило, не очевидні, тому виникає питання: чи існують сховані зв‘язки між цими факторами. Для аналізу та прогнозування взаємовпливу телекомунікаційних факторів пропонується використовувати методологію регресійно-когнітивного моделювання, яка доповнює когнітивний граф ситуації механізмами регресійного аналізу. Увесь процес регресійно-когнітивного моделювання можна поділити на декілька етапів, які представлені на рисунку 7.3.
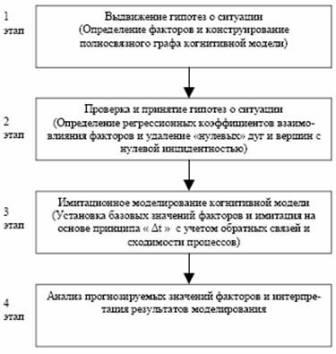
Рисунок 7.3 - Этапи регресійно-когнітивного моделювання
На першому етапі регресійно-когнітивного моделювання виконується представлення всіх існуючих факторів у вигляді когнітивної карти, яка повинна відображати загальне уявлення про ситуацію у вигляді певних семантичних категорій, під яким розуміються ознаки, факти, подія, поняття, що стосуються конкретної ситуації.
На наступному етапі на основі цих даних проводиться кількісний аналіз взаємного впливу у сконструйованому повнозв‘язному графі. Для цього створюється регресійна модель для кожного з набора факторів, що ми маємо.
Третій етап демонструє динаміку розвитку РКМ, показуючи хронологічну «боротьбу» тенденцій для сигнальної форми графа; вводить величину дельта t– інтервал дискретизації, властивий системі (так званий принцип «?t» в імітаційному моделюванні).
Загальна постановка задачі цільового управління в межах РКМ пов‘язана з виділенням цільової вершини – фактора, значення якого бажано підвищити, знизити або «вписати» в певний діапазон значень. При цьому структура РКГ залишається незмінною, а задача пошуку полягає в такому підборі коефіцієнтів – дуг графа, при якому реалізується бажана мета.
Методологія пошуку розв‘язку в поєднанні з РКМ у першу чергу корисна для моделювання варіанта рішення, що приймається, тактики або стратегії керування. Така модель пошуку розв‘язання зі сукупністю з моделями РКМ дозволить знайти оптимальний варіант вирішення переходу від реального значення будь-якого фактора до бажаного, який може бути використаний під час прийняття відповідного рішення.
Метод имітаційного моделювання
Бізнес процеси телекомунікаційних організацій класифіковані за трьома категоріями. До першої категорії належать бізнес-процеси, пов‘язані з безпосереднім наданням телекомунікаційних послуг абонентам й іншим операторам. До другої категорії належать бізнес-процеси з організації системи розрахунків із клієнтами за надані послуги. До третьої – бізнес-процеси з надання послуг, що виходять за межі профільної діяльності (інформаційно-довідкові, сервісні тощо).
У сучасних умовах управлінське моделювання бізнес-процесів стає не стільки процесом збору, аналізу, обробки величезних масивів інформації для виявлення ефективного управлінського сценарію, скільки процесом формування й аналізу проблемного поля з потенціальних ризиків із метою підвищення ефективності керування.
Одним із універсальних методів проведення «експеримента» на предмет прийняття раціонального рішення є імітаційне моделювання, в процесі якого формується статистика можливих вихідних параметрів діяльності [10].
Застосування даного метода дозволяє використовувати біллінгову систему для підвищення обґрунтованості управлінських рішень у телекомунікаційній компанії, для розробки тарифних планів, для планування та бюджетування; надасть можливість проаналізувати ситуацію на новому наборі абонентів, послуг, зміненій схемі маршрутизації викликів. Далі на рисунку 7.4 приведен алгоритм формування тарифів за послуги організації.
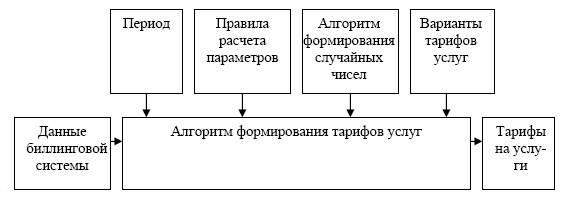
Рисунок 7.4 - Алгоритм формування тарифів за послуги організації
У реальному житті – більш складні задачі; складність прийняття рішення може бути обумовлена факторами обмеженості з‘єднувальних ліній та факторами «тяжіння» трафіка.
Перед впровадженням подібних тарифів необхідно провести спеціальне дослідження, що дозволить правильно підібрати значення тарифів і досягти оптимального розподілення навантаження. Інтеграція імітаційної моделі та системи біллінга дозволила реалізувати задачу раціональних взаєморозрахунків операторів і клієнтів.
За допомогою метода функціонального моделювання було проведено дослідження процесів, що відбуваються в системі, виявлені їх недоліки та побудована модель системи моделювання тарифних планів телекомунікаційної організації. Навантаження оператора пад час взаємного використання ресурсів для пропуску трафіка можна представити у вигляді формули 7.1:
| (7.1) |
де У - навантаження,
![]() - математичне очікування показника навантаження,
- математичне очікування показника навантаження,
![]() - середньоквадратичне відхилення показника навантаження,
- середньоквадратичне відхилення показника навантаження,
Випадкове число (-1,1) , i = 1…24
Імітаційна модель надходження трафіка й процесу тарифікації представлена на рисунку 7.5
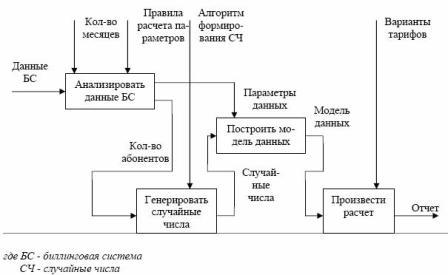
Рисунок 7.5 - Імітаційна модель надходження трафіка й процесу тарифікації
Дана модель була розроблена з використанням технології структурного аналізу та проектування, що дозволяю описувати бізнес-процес у вигляді ієрархічної системи взаємозв‘язаних функцій. Така модель відображає функціональну структуру об‘єкту, дії, що ним виконуються, та зв‘язки між цими діями. Блоки – дії, дуги – об‘єкти, які обробляє система [10].
Собівартість транзитного трафіка визначається як відношення різниці між витратами на пропуск трафіка, враховуючи транзитний і не враховуючи транзитний, до кількості хвилин транзитного трафіка.
Аналогічним чином можна розрахувати й зменшення витрат на пропуск трафіка під час його пере маршрутизації через «дешевші» вузли.
На основі аналізу трафіка можна зробити висновки про безпосередню діяльність організації на майбутні періоди, розробити тарифні плани, які реалізують модель ефективності.
У результаті змін вхідних даних моделі надходження трафіка та процеса тарифікації існує можливість розробити методику планування діяльності організації на засадах прогнозування доходів та витрат організації.
За допомогою подібної моделі можна вирішити задачу підвищення доходів організації та вирівняння навантаження мережі. Така модель використовується для розробки модуля планування тарифних планів. Вихідні дані використовуються для обґрунтування управлінських рішень з визначення оптимальної тарифної політики та стратегії розвитку підприємства.
Нейронні мережі для вирішення задач прогнозування
Штучна нейронна мережа – набір нейронів, з‘єднаних між собою. Штучний нейрон за своїми властивостями нагадує біологічний нейрон [11].
На вхід штучного нейрона поступає деяка кількість сигналів x1, x2,…, xn, кожний із яких є виходом іншого нейрона. Кожний вхід помножується на відповідну вагу w1, w2,…, wn, і поступає до блоку підсумовування, позначеного ?. Цей блок, що відповідає тілу біологічного елемента, додає зважені входи алгебраїчно, створюючи вихід – NET.
Найпростішою нейронною мережею вважається персептрон, який зображений на рисунку 7.6. За своєю структурою він аналогічний нейрону, але на його виходах знаходиться деякий аналізатор. І в залежності від значення сформованої суми, вихідне значення аналізатора буде рівно "1", якщо сума більше порогового значення і "0", якщо менше.

Рисунок 7.6 - Персептрон – найпростіша нейронна мережа
Сьогодні персептрон є однією з найпопулярніших реалізацій нейронних мереж. Причиною його популярності є відносна простота реалізації на фоні універсальності та широкого кола задач, які можуть вирішувати персептрони.
Для вирішення більш складних задач використовують багатошарові нейроні мережі. Але для навчання багатошарових нейронних мереж необхідні більш складні алгоритми навчання. Схема такої багатошарової нейронної мережі зображена на рисунку 7.7.
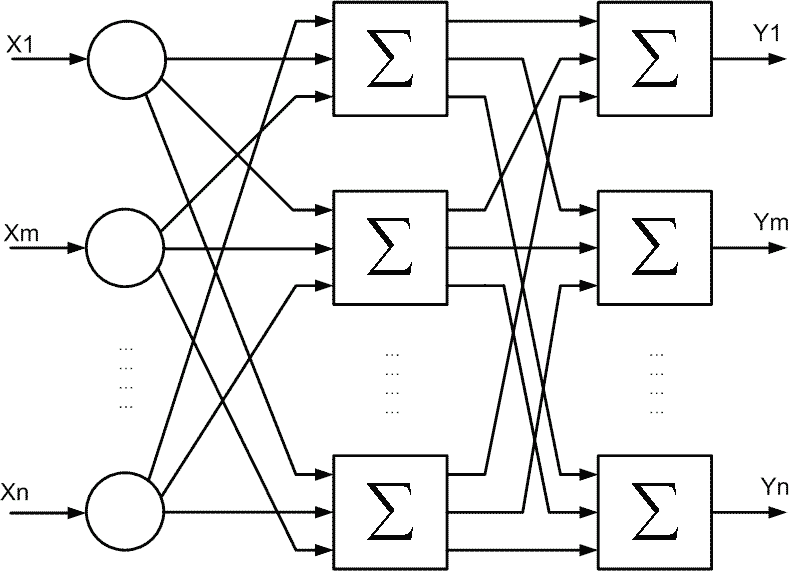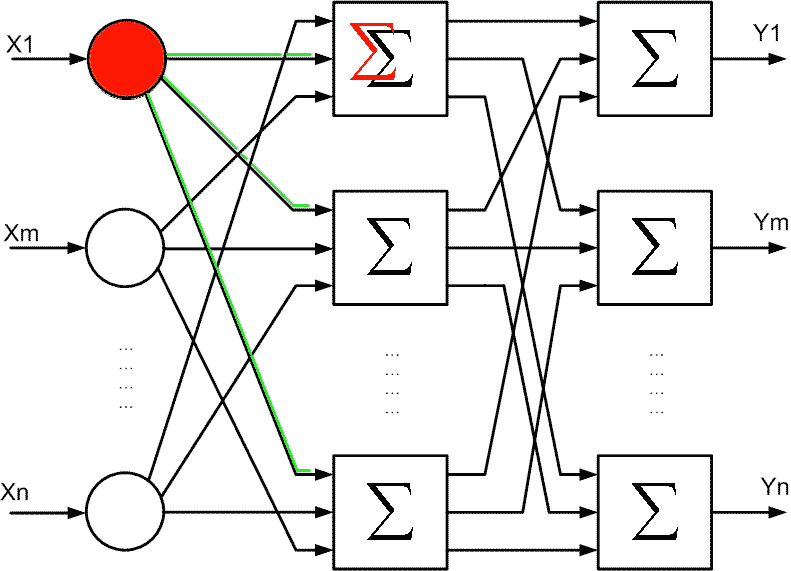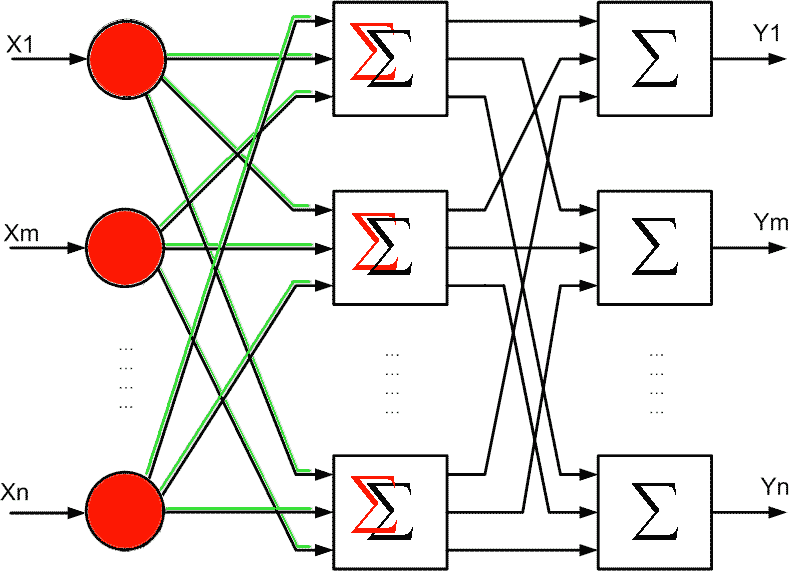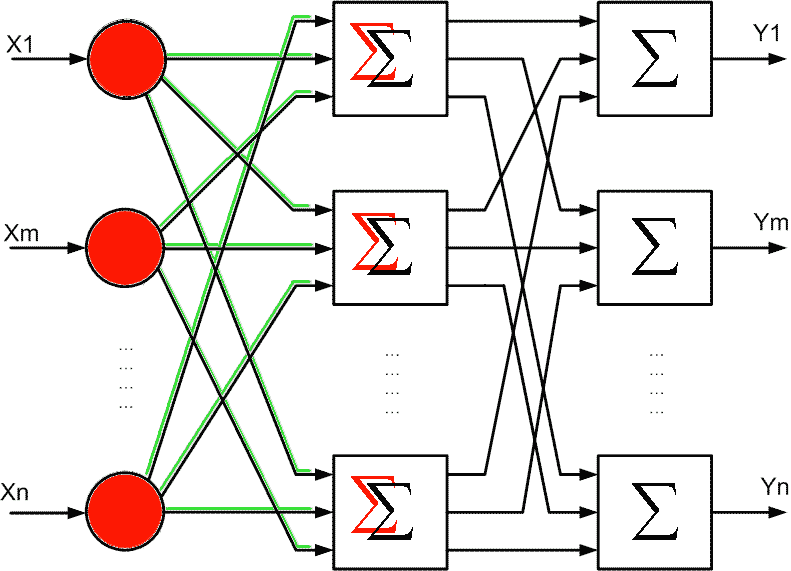
Рисунок 7.7 - Схема багатошарової нейронної мережі
(анімація: обсяг – 27,4 КБ; размір – 791x571; кількість кадрів – 4; затримка між кадрами – 2000 мс; затримка між останнім та першим кадрами – 2000 мс; кількість циклів повторення – безперервний цикл повторення)
Штучна нейронна мережа навчається за допомогою деякого процесу, що модифікує її ваги. Якщо навчання успішне, то подання мережі множину вхідних сигналів призводить до появи бажаної множини вихідних сигналів. Існує два класи методів навчання: детерміністичний та стохастичний [12].
Детерміністичний метод навчання крок за кроком здійснює процедуру корекції вагів мережі, основану на використанні їх поточних значень, а також величин входів, фактичних виходів та бажаних виходів.
Стохастичні методи навчання виконують псевдо випадкові зміни величин вагів, зберігаючи ті зміни, які призводять до покращень.
Прогнозування – це передбачення майбутніх подій. Метою прогнозування є зменшення ризику під час прийняття рішення. У більшості випадків прогноз виходить помилковим, при чому похибка залежить від системи прогнозування і методів прогнозування. Для зменшення похибки слід збільшити кількість ресурсів, наданих для прогнозу. При деякому рівні похибки можна досягти мінімального рівня ресурсів для прогнозу. Основною проблемою прогнозування є виявлення неточності прогнозу. Зазвичай рішення, що приймається на сонові прогнозу повинно враховувати похибку, про яку повідомляє система прогнозування. Таким чином, система прогнозування повинна забезпечувати визначення прогнозу та похибку прогнозування.
Більшість задач прогнозування можна звести до передбачення часового ряду, яка в сою чергу зводиться до типової задачі нейроаналізу – апроксимації функції багатьох змінних за заданим набором прикладів – за допомогою процедури занурення ряду в багатомірний простір (Weigend, 1994). Згідно з теоремою Такенна «Якщо часовий ряд породжується динамічною системою, тобто значення D0 є довільна функція стану такої системи, існує така глибина занурення d, яка забезпечує однозначне передбачення наступного значення часового ряду» (Sauer, 1991). Таким чином, обравши достатньо велике d, можна гарантувати однозначну залежність майбутнього значення ряду від його попередніх значень: Xt=?(Xt-d) , тобто передбачення часового ряду зводиться до задачі інтерполяції функції багатьох змінних. Нейромережу далі можна використовувати для відновлення цієї невідомої функції з набору прикладів, заданих історією даного часового ряду [12].
Результатом прогнозу на НМ є клас, до якого належить змінна, а не її конкретне значення. Формування класів повинно проводитися в залежності від того, яка мета прогнозування. Загальний підхід полягає в тому, що область визначення змінної, що прогнозується, розбивається на класи у відповідності з необхідною точністю прогнозування. Класи можуть представляти якісний або кількісний погляд на зміну змінної величини.
Прогнозування на нейронних мережах має декілька недоліків. Як правило, необхідно близько 100 спостережень для створення потрібної моделі. Це достатньо велика кількість даних й існую багато випадків, коли така кількість історичних даних недоступна.
Проте слід зазначити, що можлива побудова задовільної моделі на нейронних мережах навіть в умовах браку даних. Модель може уточнюватися по мірі того, як свіжі дані стають доступними.
Застосування нечіткої логіки для вирішення задач прогнозування
Прогнозування матеріальних потоків промислових підприємств запропоновано здійснювати на базі нечіткої логіки, використовуючи нечіткі знання та генетичні алгоритми. На рисунку 7.8 зображена логічна схема потоків промислового підприємства.
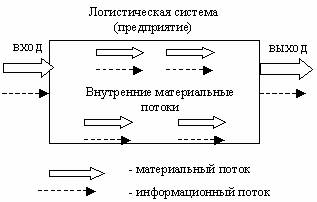
Рисунок 7.8 - Логічна схема потоків промислового підприємства
Одним із направлень вдосконалення роботи сучасних промислових підприємств є логістичний підхід до прогнозування та керування матеріальними потоками підприємства. Взагалі, матеріальний поток підприємства представляє собою динамічне й непереривне явище. Для спрощення розробки моделі прогнозування та керування, виходячи з логістичної концепції, матеріальний поток розглядається на короткому часовому відрізку, що дозволяє його характеризувати як часову статистичну величину.
Складності побудови моделей матеріальних потоків полягає в тому, що між факторами, що впливають, як зовнішніми, так і внутрішніми, існує певний зв‘язок, який часто складно виявити. Матеріальний потік підприємства складається з:
- вхідного матеріального потоку у вигляді спожитої сировини, матеріалів, комплектуючих виробів тощо;
- внутрішнього матеріального потоку між окремими логістичними ланками системи;
- вихідного матеріального потоку у вигляді готової продукції, товарів, послуг.
Нечіткі множини дають можливість формалізувати величини, що мають якісну основу, виявити причинно-наслідкові зв‘язки між параметрами та величинами, що мають на них вплив, та сформулювати нечіткий прогноз в умовах невизначеності параметрів прогнозування.Алгоритм побудови математичної моделі, який зображений на рисунку 7.9, базується на використанні теорії нечіткої логіки.
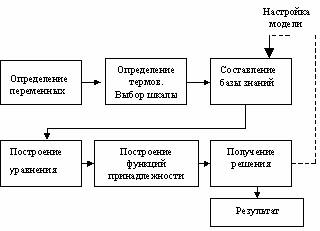
Рисунок 7.9 - Алгоритм побудови математичної моделі
У відповідності до методів нечіткої логіки виділяють основні етапи моделювання:
- Постановка задачі та побудова дерева виводу, фаззифікація. Розглядається об‘єкт типу
| (7.2) |
- За допомогою експертів формується сукупність параметрів, що впливають на величину, що прогнозується. Для кожного з параметрів визначають лінгвістичні терми, що дають оцінку даному параметру. Граф (дерево рішень) відображає класифікацію факторів (x1,x2,:xn), які впливають на показник прогнозу (y). На цьому ж етапі здійснюється фаззифікація, тобто вибір нечітких термів для лінгвістичної оцінки факторів впливу.
- Побудова бази нечітких знань. Сюди заносяться результати майбутнього експеримента.
- Побудова функції приналежності лінгвістичних змінних, які задаються в параметричній формі [1]
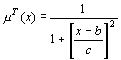 |
(7.3) |
- Формування нечіткого логічного виводу.
- Отримання результатів моделювання, яке полягає в перетворенні нечіткої множини в чітке число (дефаззифікація). Процедура дефаззифікації є процедурою отримання рішення. При чому величина Y розраховується:
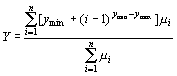 |
(7.4) |
ymin, ymax - шкала виміру;
?i - значення функції приналежності.
- Настройка нечіткої моделі шляхом розширення об‘єму бази знань та настройки функції приналежності.
Для побудови моделі необхідно усі параметри інформаційної бази привести до одного вигляду – якісному або кількісному.
База нечітких знань є носієм експертної інформації про причинно-наслідкові зв‘язки між вхідними та вихідними даними. База знань детермінує систему логічних виводів типу «якщо-то; якщо-або», які зв‘язують значення вхідних параметрів Х1,:Хn із вихідним параметром Y.
Формування бази нечітких знань починається з процедури формування початкової вибірки, мета якої – підготовка необхідного масиву статистичних даних дослідного об‘єкту.
Чіткий прогноз матеріальних потоків сучасних підприємств ускладнений через ряд причин об‘єктивного та суб‘єктивного характеру. Є доцільним прогнозування матеріальних потоків здійснювати на базі методів нечіткої логіки, використовуючи нечіткі знання.
Нечіткі числа, які отримуємо в результаті «не дуже точних вимірювань», дуже схожі на розподілення теорії ймовірностей, але порівняно з цими методами, методи нечіткої логіки дозволяють різко зменшити об‘єм вирахувань, і, в свою чергу, призводить до збільшення швидкості роботи нечітких систем.
Недоліками нечітких систем є:
- відсутність стандартної методики проектування та розрахунку нечітких систем;
- неможливість математичного аналізу нечітких систем існуючими методами;
- застосування нечіткого підходу порівняно з імовірнісними не призводить до підвищення точності розрахунків;
- збільшення вхідних змінних збільшує складність розрахунків експоненціально;
- як наслідок попереднього пункту, збільшується база правил, що призводить до складного її сприйняття.
Прогнозування з використанням генетичних алгоритмів
Вперше ідея використання генетичних алгоритмів для навчання (machine learning) була запропонована в 1970-ті роки. У другій половині 1980-х до цієї ідеї повернулися у зв‘язку з навчанням нейронних мереж. Вони дозволяють вирішувати задачі прогнозування (останнім часом найбільш широко генетичні алгоритми використовуються для банківських прогнозів), класифікації, пошуку оптимальних варіантів, і абсолютно незамінні в тих випадках, коли у звичайних умовах рішення задачі основане на інтуїції або досвіді, а не на чіткому (в математичному контексті) її опису. Використання механізмів генетичної еволюції для навчання нейронних мереж здається природнім, оскільки моделі нейронних мереж розробляються аналогічно мозкові та реалізують деякі його особливості, що з‘явилися в результаті біологічної еволюції [13].
Основні компоненти генетичних алгоритмів – це стратегії репродукцій, мутацій і відбір «індивідуальних» нейронних мереж (аналогічно відбору індивідуальних особин). Важливим недоліком генетичних алгоритмів є складність для розуміння та програмної реалізації. Однак перевагою є ефективність у пошуку глобальних мінімумів адаптивних рельєфів, оскільки в них досліджуються великі області допустимих значень параметрів нейтронних мереж. Інша причина того, що генетичні алгоритми не застрягають у локальних мінімумах – випадкові мутації.
Швидкість сходження градієнтних алгоритмів у середньому вища, ніж генетичних алгоритмів. Генетичні алгоритми дають можливість оперувати дискретними значеннями параметрів нейронних мереж. Це спрощує розробку цифрових апаратних реалізацій нейронних мереж. Під час навчання на комп’ютері нейронних мереж, які не орієнтовані на апаратну реалізацію, можливість використання дискретних значень параметрів у деяких випадках може призводити до скорочення загального часу навчання [14].
Перший розділ. Огляд поставленої задачі: Прогнозування доходу підприємства (телефонної компанії) на основі аналізу даних, наданих біллінговою системою. У даному розділі будуть описані методи розв‘язання, а також математична постановка задачі та висновки. Тут також необхідно визначити параметри, на основі яких може проводитись прогнозування.
Математична постановка задачі. Дохід є основним фактором економічного та соціального розвитку підприємства. Тому економічно обґрунтоване планування доходу на підприємствах має дуже велике значення.
Для розв‘язання нашої задачі ми беремо так званий валовий дохід: без відрахувань на податок, заробітну плату робітникам, без відрахувань на постійні або одноразові витрати. Ми додаємо всі грошові засоби, що поступають на рахунок підприємства від абонентів за спожиті ними послуги зв‘язку. Далі цю суму будемо називати «доходом». Таким чином, формула підрахунку доходу телекомунікаційної компанії має наступний вигляд:
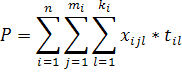 |
(8.1) |
n – кількість тарифів;
mi – число абонентів, які користуються тарифом i;
xijl – кількість послуг, отриманих абонентом j за тарифом i за послугу l;
til – ціна послуги l у тарифі i.
Задача прогнозування доходу полягає, головним чином, у прогнозуванні декількох параметрів, за допомогою яких потім розраховується й сам дохід. Оскільки ki – кількість послуг в i–ому тарифі, n – кількість тарифів і til – ціна послуги l у тарифі i, - ми встановлюємо самі, то ці параметри вважаємо відомими. Таким чином, наша задача зводиться до визначення (прогнозування) mi и xijl
Із одного боку, mi – число абонентів, які користуються тарифом i. Пропонуючи нові послуги або нові тарифи існуючих послуг, ми повинні спрогнозувати, скільки нових абонентів буде заохочено, скільки абонентів перейде на новий тариф, і яка кількість клієнтів буде користуватися новими послугами за новими тарифами.
А з іншого боку, ми маємо xijl – кількість послуг, отриманих абонентом j за тарифом i за послугу l. Фактично, нам необхідно спрогнозувати яку кількість тих чи інших послуг зв‘язку (існуючих за новими тарифами або нововведених послуг) буде споживатися кожним із абонентів.
Очевидно, що невеликий об‘єм даних набагато легше обробляти аналітично. Виходячи з цього, можемо зробити висновок, що бажано розбивати величезний масив даних, що надається біллінговою системою, наприклад, на групи абонентів всередині тарифу (наприклад, за об‘ємом спожитих послуг).
Спираючись на дані біллінгової системи, ми, у першу чергу, можемо визначити лояльність різних груп абонентів, спрогнозувати їхню поведінку: надання переваги тим чи іншим послугам, тарифам, тривалість користування наданими послугами, можливість переходу з одного тарифного плану в інший тощо.
Другий розділ. Розробка метода прогнозування доходу. Метод прогнозування споживання послуг – на основі аналізу часових рядів із використанням нейромереж. Метод прогнозування динаміки зміни кількості користувачів у кожному тарифі – на основі теорії нечіткої логіки.
Третій розділ. Розробка моделі роботи системи для перевірки методів прогнозування Дослідження й аналіз роботи методів прогнозування. Оцінка роботи методів прогнозування на основі порівняння результатів із реальними даними.
Четвертий розділ. Розробка інформаційного та програмного забезпечення підсистеми прогнозування доходу підприємства на основі даних біллінгової системи.
Сучасні тенденції розвитку ринка телекомунікацій, пов‘язані з постійно та швидко зростаючим різноманіттям видів наданих послуг зв‘язку та їхніх об‘ємів, ставлять перед операторами зв‘язку все більш складні задачі з організації процесу надання цих послуг своїм клієнтам. До таких задач відносять і забезпечення системою розрахунку та тарифікації наданих послуг, виставлення рахунків та врахування оплати (що складає основу біллінгових систем або АСР – автоматичних систем розрахунку); забезпечення врахуванням потреб клієнтів у різного виду послугах; підтримка різних способів оплати тощо.
Були вирішені наступні задачі:
- Визначена необхідність у ефективному керуванні телекомунікаційним трафіком із метою збільшення доходів оператора зв‘язку.
- Проведений аналіз існуючих біллінгових систем, досліджені можливості збору та зберігання інформації про трафік.
- Було зроблено порівняльний аналіз алгоритмів виявлення схованих закономірностей та запропонований найбільш перспективний для аналізу та прогнозування телекомунікаційного трафіка.
- Биллинг неголосовых услуг [Электронный ресурс] / А. Голышко. – Режим доступа: www.connect.ru/article.asp?id=6170
- Современные CRM/PRM-системы и web-технологии в бизнесе телекоммуникационных компаний [Электронный ресурс] / А. Гургенидзе. – Режим доступа: www.connect.ru/article.asp?id=6617
- Naumen Telecom: Комплекс OSS/BSS для российских компаний (ТССС). [Электронный ресурс] – Режим доступа: www.naumen.ru/go/company/press/TCCC_08_Telecom
- Трубникова, Е.И. Способы управления социально-экономическими системами / Т.В. Полулях, Е.И. Трубникова // Инфокоммуникационные технологии, 2007, том 5, № 1, с. 72-77.
- Трубникова, Е.И., Биллинг как средство принятия управленческих решений при формировании тарифных планов телекоммуникационной компании. / Е.И. Трубникова, А.В. Добрянин // Проблемы Материалы XIII Юбилейной Российской научной конференции профессорско-преподавательского состава, научных работников и аспирантов, 30 янв.– 4 фев. 2006г. – Самара: Поволжская Государственная Академия Телекоммуникаций и Информатики, 2006, с. 208-209.
- Zachman J. A Framework for Information System Architecture // IBM System Journal, 1987, vol. 26, № 3, pp. 276-292.
- Zachman J. Enterprise Architecture: The Past and The Future // DM Direct, April 2000.
- Разработка моделей выявления взаимозависимых факторов в телекоммуникационном графике на основе регрессионно-когнитивных графов диссертация кандидата технических наук [Электронный ресурс] / А.В. Мелик-Шахназаров. – Режим доступа: http://www.dissforall.com/_catalog/t8/_science/39/210263.html
- Инновационное управление телекоммуникационной организацией на основе метода имитационного моделирования [Электронный ресурс] / Е.И. Трубникова. – Режим доступа: http://www.nimb.nnov.ru/_data/files/ARD_Trubnikova.pdf
- Трубникова, Е.И. Применение имитационного моделирования в процессе бюджетирования. / Е.И. Трубникова // Роль высших учебных заведений в инновационном развитии экономики регионов: Международная науч.-практ. конф., 10-12 окт. 2006г. – Самара: Самар. гос. экон. акад., 2006. – с. 217-220.
- Бутенко А.А. и др. Обучение нейронной сети при помощи алгоритма фильтра Калмана. // Труды VIII Всероссийской конференции «Нейрокомпьютеры и их применение »: Сб. докл., 2002. – с. 1120-1125.
- Решение задач прогнозирования с помощью нейронных сетей [Электронный ресурс] / Акулов П. В. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/akulov/diss/index.htm
- Вороновский Г.К., и др. Генетические алгоритмы, нейронные сети и проблемы виртуальной реальности. – Х.: ОСНОВА, 1997. – 112 с.
- Батищев Д.И. Генетические алгоритмы решения экстремальных задач. – Воронеж: ВГУ, 1994. – 135 с.
Важливе зауваження: під час написання даного автореферату магістерська робота ще не завершена. Повне закінчення роботи - грудень 2009року. Повний текст роботи та матеріали по темі можуть бути отримані в автора або його керівника після зазначеної дати.