|
|
|
Abstract
of the qualification master’s work
«The Development of Computer Subsystem of Coal Coking Parametrs Optimization by means of Genetic Programming»
Content
Introduction
Relevance of Work
Сonnection of Work with Scientific Programms, Plans, Subjects
Aim and Problems of Work
Scientific Novelty
Practical Value of Results
Overview of Existing Methods and Tools
Mathematical Statement of Problem
Choice and Substantiation of the Symbolic Regression Method
Conclusion
Literature
Coking manufacture [1] is a branch of a heavy industry which is carrying out processing of coal by a method of coking. It makes coke (76—77 % of all production of the branch on weight), coking gas (14—15 %) and chemical products (5—6 %).
The level of development a coking industry of country is an important indicator of its industrial development and economic independence because this branch is directly connected with the metallurgical. As to Ukraine coking manufacture is one of leading branches of its economic complex. It is promoted also by Donbass region which is rich with coal and presence of consumers of coke and coking gas – domain, sintering, ferroalloy manufacture, nonferrous metallurgy, thermal power station etc.
Coking process [2] is a complex two-phase process which consists of a heat transfer process, diffusion process and a considerable quantity of various chemical reactions.
The raw materials for coking is a mix – a fusion mixture, consisting not only from coked coals, but also coals of other ranks. For example, a fusion mixture from Donetsk coals has the following structure: gas coals – 20 %, fat – 40 %, coking – 20 %, and imaciated caking – 20 %. Inclusion in a fusion mixture coal of various ranks allows to expand a coking raw-material base, to receive qualitative coke and to provide a high exit of pitch, crude benzol and coking gas.
The main product is a domain coke, which is used as a technological fuel in black and color metallurgy and as an energy fuel – almost in all branches of economics.
The relevance of this work is defined by that the technology of the coal coking process under the given productivity of the coking batteries is an enough standpat and a difficult controlled factor in the sense of the coke’s quality. That’s why it is naturally to suppose that the coal is a real object of influencing to a coke’s quality. So, to gain the coke of certain quality, it is necessary to form a fusion mixture with certain properties [3].
The known dependences between fusion mixture quality indicators, the process parameters and the coking products quality cannot describe fully processes in modern conditions which are characterized by changing of the mixture quality, the operation of the big capacity batteries and increasing the coking periods. Therefore the problem of determination the coking optimal parameters remains unresolved.
This work was carried out throughout 2008-2009 according to scientific directions of Automated control systems pulpit of Donetsk national technical university.
The project’s purpose is optimization of the coal coking process parameters.
To achieve the project’s purpose the consecutive decision of following problems is necessary:
- to develop the mathematical statement of a problem;
- to develop coding of the decisions, the terminal and functional sets, and also the problem-focused operators of the crossing-over and the mutation;
- to develop an algorithm of the optimisation;
- to check up an algorithm overall performance;
- to plan a series of experiments and to formulate the recommendations about optimization of the coal coking process parameters.
Объект исследования – технологический процесс коксования углей.
Предмет исследования – методы, модели, алгоритмы.
Методы исследования – методы системного анализа, эволюционные методы моделирования и оптимизации, основанные на генетическом программировании.
There is developed a new approach for modelling the technological process of coals coking on the basis of a symbolical regress method of the genetic programming, allowing to receive analytical model of process which provides possibility to model technological process of coking with various values of technological parametres.
There is developed a modified genetic algorithm which together with analytical model allows to conduct search of suboptimum values of parametres.
Modelling of coals coking technological process allows to receive estimations of target parametres values of coking process and to define values of technological process parametres. Carrying out the analysis of various variants of parametres’ values gives the chance to develop practical recommendations which provide efficiency of coking process.
Using a modified genetic algorithm together with analytical model as an estimated function allows to receive suboptimum values of coking technological process parametres.
At the moment there are many researches devoted to studying of dependences of parameters in a technological process. Basically the researches were made with use of mathematical models based on the analytical equations, or by means of the statistical methods giving as a result the equation of regression.
After the scientific research has been done, it is found out, that the statistical, determined and expert models were applied to research the relations in the conditions of mass supervision and random factors action in the coke chemistry.
Statistical models
In this case we operate with the indicators estimated for a qualitatively homogeneous phenomenon (sets) in model. Stochastic models are built on the basis of likelihood notions about processes in a modelling object and allow to predict its behaviour by calculation functions of probability’s distribution for the variables characterising investigated properties (at the given (set) functions of probability’s distribution of entrance and revolting variables).
Among connection models it was often used correlation and regression analysis [4,5,6].
Correlation analysis
It is necessary to recognise as the basic feature of the correlation analysis that it sets the fact of connection’s presence and degree of its narrowness only, not opening its reasons.
Problems of the correlation analysis are reduced to measurement of connection’s narrowness between varying parameters, to definition of unknown causal relationships (which causal character, should be found out by means of the theoretical analysis) and to estimation of the factors, making the greatest influence on a productive parameter.
For using the correlation analysis preliminary preparation of data is necessary: groupings, an exception of abnormal data, checking one-dimensional distribution for its normality, elimination multicollinearity and specification the indicators by calculation of correlation pair coefficients.
Regression analysis
Regression analysis tasks – a choice of model type (connection form), an establishment degree of influence of independent variables on dependent and definition calculated values of dependent variable (regression function).
Regression analysis shows, firstly, the quality of model, that is a degree of that, how much given set X explains Y. Secondly, regression analysis calculates values of coefficients B, which define with what force each of X influences on Y.
Independent variables don’t correlate with each other in an ideal regression model. However strong correlated variables is enough frequent phenomenon. It leads to error increasing of the equation, reduction of estimation’s accuracy, decreasing of efficiency of use regression model [7]. Therefore the choice of the independent variables, which are included in regression model, should be very careful.
Regression analysis lacks: adduction the form of mathematical dependence to linear, that leads to a big error;. necessity of checking an adequacy of mathematical model and an estimation of the equation factors’ importance; necessity of careful selection of the independent variables which are included in a regression model; process of searching for the best regression model is hard enough.
Determined models
Determined models [8] are built on a basis of mathematically expressed rules (regularity), which describe physical-chemical processes in the modeling object. For the majority of chemical technology processes presence of streams substances interaction, in which there are chemical transformations, is characteristic. Therefore in a basis of the mathematical description the equations of balances of weights and energy in the streams, written down taking into account their hydrodynamic structure, as a rule, are put.
Using such models requires working out of effective algorithms for decision of mathematical description equations system.
At construction of the determined model a great value has a reasonable combination of demanded complexity of model and admissible simplifications.
Expert models
Construction of expert model is carried out by means of expert estimations’ methods [9]. These are methods of organisation the job with experts and processings the experts’ opinions expressed in the quantitative and-or qualitative form for the purpose of preparation the information for decision-making.
The decision is accepted by means of regular interrogation of the experts who have an experience of a practical job, capable to estimate an importance of the question, to choose one of alternative ways of its decision. These methods are applied in the absence of the necessary information, limitation of decision time on the basis of the formalized methods.
The essence of expert methods is an averaging of experts opinions by various ways. Quality and objectivity of an expert estimation directly depends on a me thod of carrying out of interrogation. The basic lack of the given method is that the expert method completely inherits mistakes of experts.
As the number of experts usually does not exceed 20-30 the formal statistical coordination of experts opinions (established by means of those or other criteria of checking statistical hypotheses) can be match with really available division into groups, that makes the further calculations not having sense.
Overview of existing tools
There is a considerable quantity of programs for approximation performance, which can be applied to the decision of our problem. For example:
1) Discipulus Engineering (package of genetic programming for serious researchers and for the professionals working in the field of modelling/designing)[10]
2) DTREG Enterprise (classification and regression decision trees, neural networks, machine training, genetically generated programs and expressions, klasterization by means of a k-averages method, discriminant analysis and models of logistical regress)[11]
3) Deductor 5 (it is the platform focused on decision problems of the data analysis)[12]
4) MS Excel (allows to solve a regression analysis tasks)[13]
5) AtteStat (statistical data processing)[14]
6) Matlab 6.5 (Curve Fitting Toolbox, Statistics Toolbox, Spline Toolbox, Neural Network Toolbox).
Programs Discipulus, DTREG and Deductor are characterised by the following:
- a high cost, an absence of initial texts;
- an opacity of realization;
- a presence of excessive functions for which it is necessary to pay for;
- an absence of necessary specialized functions.
MS Excel and Statistics Toolbox allow finding only equation of a linear regression. AtteStat and Spline Toolbox allow to build a model as a multinomial. And neural networks do not give the formula of dependence as a result of calculations at all.
Quality of coke depends appreciably on coals’ preparation and correctness of drawing up a coal fusion mixture [2]. On coking factories coal arrives usually from many mines and coal-concentrating factories, and the expert should not only know properties and chemical composition of coals, but also skilfully make a mix from them which gives the best coke. Drawing up coal shiht for coking is made empirically. One of the basic requirements to quality of coke — a high durability and at the same time a sufficient size.
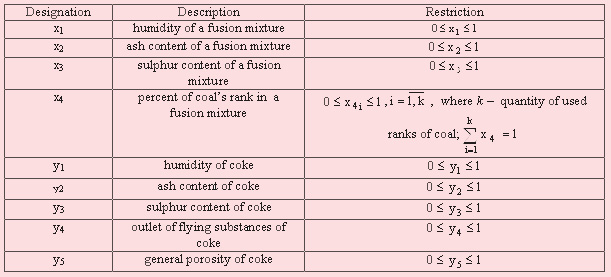
The basic characteristics describing a fusion mixture(entrance parametres of model):
- ash content (7-10%),
- sulphur content (0,5-3%),
- humidity (4-10%),
- coal rank.
The basic characteristics describing coke (target parametres of model):
- ash content (9-12%),
- sulphur content (1,6-2%),
- humidity (2-3%),
- structural durability (65-85%),
- outlet of flying substances (1-2%),
- general porosity (45-55%),
- reactionary ability (0,47-0,82 мл/(г*с)).
The accepted ranks of coal: L – long-falme, G – gas, F – fat, C – coking, I – emaciated, C – caking.
Let the set  represents characteristics of a fusion mixture.
It is required to find a set of approximating functions of a kind: represents characteristics of a fusion mixture.
It is required to find a set of approximating functions of a kind:
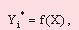 (1)
(1)
where 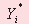 – a calculated value of a dependent variable, i.e. one of the ready coke’s indicators; – a calculated value of a dependent variable, i.e. one of the ready coke’s indicators;
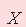 – factors, indicators of a fusion mixture. – factors, indicators of a fusion mixture.
Thus the problem is reduced to an optimising problem – minimisation of a square-law error:
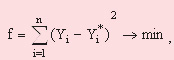 (2)
(2)
where 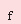 – an error of approximation; – an error of approximation;
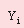 – an aprioristic value of target parameter; – an aprioristic value of target parameter;
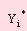 – a calculated value of target parameter; – a calculated value of target parameter;
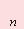 – a size of sample. – a size of sample.
Table 1 – Restrictions on indicators’ values
Method of problem’s decision is a symbolic regression method of genetic programming [15,16] which is offered owing to its advantages in comparison with other methods of modelling. The given method is an evolutionary method, i.e. it is based on process of natural evolution which develops the decisions which represent mathematical formulas.
 Figure 1 – The problem decision by means of Genetic Programming (animation: volume – 123 Кb; size – 183х697; consists of 11 frames; a delay between frames - 50 msec; a delay between the last and the first frames - 200 msec; quantity of repetition's cycles - infinite)
The genetic algorithm differs from other optimising and searching procedures by following features [17]:
1. works not with parametres, and with the coded set of parametres;
2. carries out search from the population of points, instead of from a unique point;
3. uses goal function directly, instead of its increment;
4. uses not determined, and likelihood rules of decisions’ search;
5. each new population consists of viable individuals (chromosomes);
6. each new population is better (in sense of goal function) previous;
the evolution process the subsequent population depends only on the previous.
Organisms should respond 4 major properties to make evolution possible:
1. each individual in population is capable to reproduction;
2. differences of individuals from each other influence the probability of their survival;
3. each descendant inherits features of the parent (the similar comes from similar);
4. resources for ability to live and to reproduce are limited, that generates a competition and struggle for them.
All these properties are provided with operators of genetic algorithm.
Task of a symbolic regression method is the finding of such mathematical expression of functional dependence which approximates the values set by sample with the minimum error.
For individual’s formation (mathematical expression) the functional and terminal sets [17,18] should be defined. It is necessary to notice, that the offered method does not demand use of in advance predetermined form of dependence’s function.
For the given problem the functional set is defined: «+, - *,/, ^ (exponentiation)» and terminal set: values of factors (X) and material constants from an interval [-5,5].
For representation of the individual the treelike structure [17] which example is presented in fig. 2 is used.
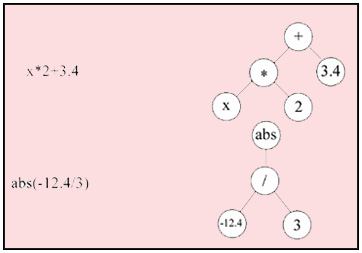
Figure 2 – Treelike coding of individuals
Each node of a tree represents or the terminal (a variable, a constant), or a function symbol. All operators of functional set demand two arguments. If there is a function symbol in the node the node should have descendants – arguments of function, i.e. terminals. End nodes are always terminals.
Adjusted parametres of algorithm: crossover’s probability, mutation’s probability, "elite" percent, quantity of algorithm’s iterations or accuracy of the decision, the size of population.
As fitness function (function of an estimation of the individual’s suitability) in the program it will be used:
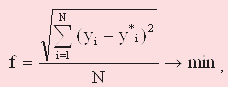 (3)
(3)
The given goal function is continuous and standardised.
Value of suitability of each individual (i.e. its value of a goal function) is defined as a mean-square error of approximation by the given individual-formula of sample’s data.
In the beginning of algorithm’s run it is necessary to initialize population of individuals. For all representations is restriction on the size – on depth of a tree – no more than 20 levels. The most effective value of this parameter will be experimentally defined.
Two methods will be applied to individuals’ initialization [17]. The first - a method of Trees Growth: the tree starts growing from a root, record in the node is chosen in a random way from the set which includes terminal and functional sets. If a function symbol is chosen the process recursively proceeds for its descendants. The second method – Full Method. The tree is built similarly, but at the beginning the node get out of a functional set only while the tree will reach the set depth. Then end nodes are filled from the set of variables and constants.
Use only a Full Method of initialization promotes degeneration of a genetic material and premature convergence [17]. Therefore the combined method is applied. Population shares on 2 equal parts, a maximum depth (for example, 20 and 30) is put for each part. Half of trees from each group is built on Growth Method, another - on Full Method.
Criterion of algorithm‘s end is achievement of the set decision’s accuracy or execution the set quantity of evolution’s iterations.
For individuals-parents’ selection the method of linear ranging [17] will be used since it is applicable without updatings for a problem of minimisation and does not demand scaling for prevention of premature convergence.
The crossover operator for treelike representation will be carried out by subtree exchange. Two individuals are get out in a random way and then a node in one subtree and in other subtree. For subtree exchange it is required to be convinced, that subtrees are interchangeable, differently – continue selection of the node. Subtrees are separated in corresponding nodes, and are put to the place of corresponding subtree in other tree. In fig. 3 forming of the descendant by subtree exchange method is represented.
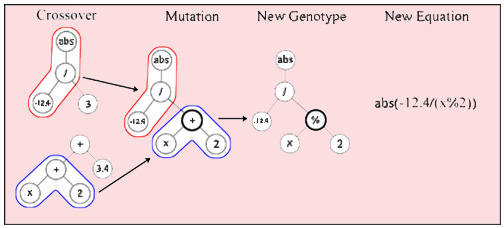
Figure 3 – Performance of the operator crossover and a node’s mutation
Before saving of the individuals-descendants, received as a result of the crossover operator, it is necessary to check the size of descendants, and taking into account this checking to carry out or cancel an exchange.
The mutation can be nodal (1 %), truncating (1 %) and growing (3 %). The preference is given to a growing mutation because this operator possesses the big possibilities [17]. During realization of the mutation operator the size of mutated individuals will be checked also.
Two methods are applicable for formation a new population from the current generation expanded with descendants. The first – an elite scheme consisting in copying of set quantity of individuals with the best values of fitness function in the subsequent population. The second method – the proportional selection based on direct proportionality of individual’s choice probability and its fitness function value.
The principle scheme of algorithm consists of following basic phases (fig. 4):
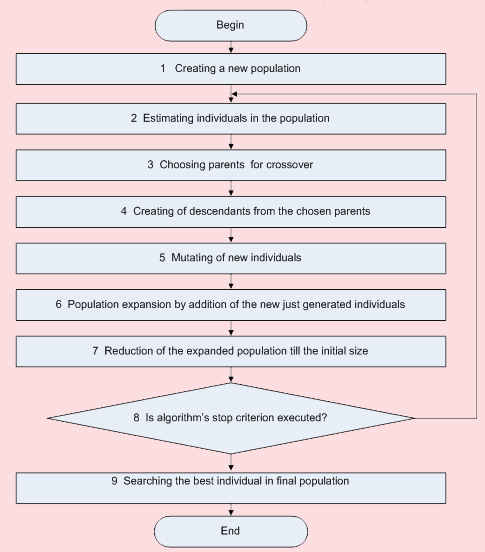
Figure 4 – Basic phases of evolution process of decisions
Program realisation of the problem dwsicion method will be executed in the environment of C ++ Builder 6.0.
In this work the decision of an actual scientific problem – optimisation of colas coking parametres is offered. Scientific search of materials has been executed and reflected in job for getting information about a modern state of developments on a work’s subject. The attention was given to models and methods of modelling and optimisation of coal coking process for the purpose of its optimisation, and also to the tools, allowing to execute approximation on the set sample of data.
As a result of collected information analysis the merits and demerits of applied models, methods and software have been revealed and the direction of own researches is defined. Mathematical statement of a problem is developed, the decision method is chosen– a method of symbolic regression of genetic programming. For a decision method such parametres are defined: coding of the decisions, the problemno-focused operators crossover and mutation, a fitness function.
The further work consists in realisation of the offered a decision method of the given problem, defining of the most effective values of algorithm’s parametres, checking of constructed model adequacy, defining of the suboptimum parametres’ values for producing a qualitative coke.
1. Шубеко П.З. Непрерывный процесс коксования / П.З. Шубеко, Г.И. Еник – М.: “Металлургия”, 1974. – 224 c.
2. Иванов Е.Б. Технология производства кокса / Е.Б. Иванов, Д.А. Мучник – «Вища школа», 1976. – 232 c. – 71-74, 105-112 c.
3. Кауфман А.А. Теория и практика современных процессов коксования: cборник примеров и задач / А.А. Кауфман, В.Д. Глянченко, С.А. Косорогов – Екатеринбург: ГОУ ВПО УГТУ-УПИ, 2005. – 61 c. – 11-19 c.
4. Реакционная способность кокса и методы ее регулирования: материалы междунар. науч. конф. [«Химия, химическая технология и биотехнология на рубеже тысячелетий»], (Томск 11-16 сент. 2006 г.) – Томский гос. политех. ун-т, 2006. – 51 с. – с. 11-16с.
5. Гребенюк А.Ф. Расчеты процессов коксового производства / А.Ф. Гребенюк, А.И Збыковский. – Донецк, 2008 – 188 с.
6. Оптимизация качества каменноугольного пека в условиях ОАО “Авдеевский коксохимический завод”: научно-практ. конф. ["Донбасс 2020: наука и техника - производству"], (Донецк 5-6 фев. 2002 г.) – Д: Донецкий нац. тех. ун-т, 2002.
7. Крыштановский А.О. Ограничения метода регрессионного анализа / А.О. Крыштановский // Социология – Режим доступа к журн.: http://socioline.ru/node/529.
8. Моделирование тепловых свойств кокса: сб. трудов международ. науч. конф. [«Математические методы в технике и технологиях»] – Кострома: КГУ, 2004. - Т.1.
9. Грешилов А.А. Математические методы построения прогнозов / А.А. Грешилов , В.А. Стакун, А.А. Стакун – Москва, 1997. – 106 с. – с. 28-29, 91-93.
10. Dispulus : программ. продукт [Электронный ресурс]. – Режим доступа: http://www.rmltech.com/.
11. DTREG: программ. продукт [Электронный ресурс]. – Режим доступа: http://www.dtreg.com/index.htm.
12. Deductor 5: программ. продукт [Электронный ресурс]. – Режим доступа: http://www.basegroup.ru/.
13. Мучник Д.А. Расчеты и прогнозирование показателей качества металлургического кокса с использованием ПК: учебное пособие / Д.А. Мучник, В.М. Гуляев – Днепродзержинск, 2007. – 225 с.
14. AtteStat: программ. продукт [Электронный ресурс]. – Режим доступа: http://attestatsoft.com/download.htm.
15. Genetic Programming: An Introduction / W. Banzhaf, P. Nordin, R. Keller, F. Francone. – San Francisco, 1998.
16. Koza J. R. Genetic Programming: On the Programming of Computers by Means of Natural Selection / J. R. Koza. – MIT Press, Cambridge, 1992.
17. Скобцов Ю.А. Основы эволюционных вычислений: учебное пособие для вузов/ Ю.А. Скобцов. – Донецкий нац. техн. ун-т. – Донецк: ДонНТУ, 2008.
18. Zelinka I. Symbolic regression – an overview / I. Zelinka. – Tomas Bata University Zlin, 2002.
Top
|

 ||
DonNTU >
DonNTU Master's portal >
||
DonNTU >
DonNTU Master's portal >