Прогнозирующие модели для профилактического сетевого управления. Сетевое управление: Приложение к созданию сетевого сервера
Автор: Dongxu Shen
Автор перевода: Тищенко А.В.
Краткий обзор
Предупреждающее управление направлено на профилактическое корректирующее воздействие сервисных поломок. Для достижения этого необходимы прогнозирующие модели, с помощью которых потенциальные угрозы могут быть предвидены. Данный подход построен на предыдущих исследованиях, согласно которым функции HTTP изучаются в сетевом сервере. Как и в предыдущей работе, функции HTTP моделируются как два подпроцесса, (обусловленный) общий подпроцесс и (случайный, но постоянный) остаточный подпроцесс.
В данной работе, общая модель дополнена использованием фильтра нижних частот. Далее применяются методики, уменьшающие применение необходимых статистических данных посредством сокращения воздействия изменений на общий процесс. Как и в предыдущей работе, авторегрессивная модель применяется для остаточного процесса. Изучаются ограничения авторегрессивной модели в прогнозе сетевого трафика. Также показано, что дальнейшие зависимости сохраняются в остаточном процессе даже после того, как авторегрессионные слагаемые удалены, что оказывает влияние на возможность прогнозировать будущие результаты наблюдений. И в конечном итоге, анализируется достоверность предположений, в частности общепринятых предположений.
Ключевые слова
Прогнозирование сетевого трафика, моделирование трафика, модель любительской радиостанции, сетевое управление, сетевой сервер.
1. Введение
Надежность сети является центральным аспектом для поставщиков информационных услуг. Неполадки в сети могут, как минимум, служить поводом беспокойства пользователя. Очень часто, неполадки обусловлены существенным финансовым влиянием, в частности, потеря возможности деловой деятельности, или недовольство клиента. Прогнозные сервисные нарушения на всех уровнях дают возможность применять корректирующие действия до сетевых неполадок. Например, профилактический излишний сетевой трафик может высветиться на экране сетевого администратора, который ограничит доступ к непопулярным WEB- сайтам.
Прогнозирование широко распространено даже в таких областях, как прогноз погоды [2] и планирование будущих экономических показателей. [3] Однако, в области сетевого трафика было сделано не так уж и много. Этому посвящена данная статья. Благодаря пакетным данным и нестационарным сетевым трафикам, существуют неотъемлемые ограничения относительно точности прогнозов.
Вопреки данным трудностям, мы решительно настроены развивать использование прогнозных моделей сетевых систем, посредством которым можно внедрять новую волну предупреждающих управленческих методик. В данной области было разработок относительно обнаружения неисправностей. [6, 7]. В данной области было предпринято много усилий. [5, 8].
Данную работу можно рассмотреть как продолжение [8]. Она исследует количество функций гипертекстового протокола (HTTP) в секунду. Данные извлекаются с использованием модели ежедневного трафика, которая ведет учет истинного времени, дня недели, месяца, в то время как авторегрессивная модель призвана определить остаточный процесс. В данной работе применяется тот же набор данных и переменные. Как и в предыдущей работе здесь исследуются отдельные модели непостоянных и постоянных составляющих настоящего процесса. Таким образом, изучаются [8] следующие вопросы:
1. Обеспечение иного способа моделирования тренда, сокращающему объем статистических данных.
2. Для общих моделей применяется фильтр нижних частот с целью получения большего объема данных.
3. Допущения, лежащие в основе остаточного процесса, исследованы более детально, особое внимание уделено Закону нормального допущения.
4. Текущая работа, как и предыдущая, применяют авторегрессивные модели для прогноза. В данной работе проясняются детали ограничения, базирующиеся на авторегрессивнных прогнозах.
5. Показано, что зависимости дальнего действия сохраняются в данных даже после удаления тренда, что усложняет прогноз.
Остальная часть данной работы представлена следующим образом: раздел 2 предоставляет краткий обзор исследуемого вопроса. Раздел 3 моделирует нестационарные режимы. Остаточный процесс рассмотрен в разделе 4. Оценка схемы моделирования представлена в разделе 5. Заключения даны в разделе 6.
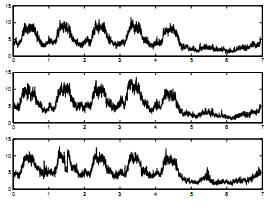
Схема 1. График http режимов за 3 недели. Ось абсцисс: день, Ось ординат: число режимов
2. Обзор исследуемого вопроса.
Применяемый набор данных взят из составленного сетевого сервера крупной компьютерной компании с использованием собранных устройств, предоставленных в разделе 4. Выбранной переменной для модели является количество http режимов, исполняемых сетевым сервером. Данные фиксируются в пятиминутный интервал, в общей сложности 288 интервалов за день.
Рисунок 1 исследует применение http режимов в течение трех недель. Согласно рисунку, можно заметить, что каждую неделю наблюдается вырисовывающийся тренд. Каждое рабочее утро http режимы увеличиваются в количестве по мере прибытия людей на работу. Вскоре http режимы достигают пика в развитии и сохраняются в данной точке большую часть дня. Днем показатель возвращается на более низкие позиции. На выходных коэффициент загруженности остается неизменно низким в течение дня.
http режимы, в целом, являются нестабильными и их значение меняется в определенное время дня и день недели. Однако, предыдущий рисунок показывает, что все та же нестабильная конфигурация сохраняется из недели в неделю (либо меняются медленно). Таким образом, можно наблюдать полный процесс, сохраняющий постоянное значение для каждого определенного времени дня наряду с отклонениями, смоделированными произвольной переменной с нулевым значением. Мы рассматриваем данные значения как обособленные подпроцессы, которые отнесены к общим подпроцессам. Вычитанием общих положений из настоящих данных получаем остаточные процессы, рассматриваемые как постоянные.
Данный схема прогнозирования структурирована следующим образом: во-первых, главный процесс получен из первоначального; во-вторых, остаточный процесс извлечен из данных первичного процесса. В – третьих, прогноз сделан на основе остаточного процесса. И в четвертых, тренд добавлен в последний прогнозный результат. Моделирование, необходимое для осуществления данных шагов, разделено на две части: моделирование непостоянного или трендового подпроцесса и моделирование остаточного подпроцесса.
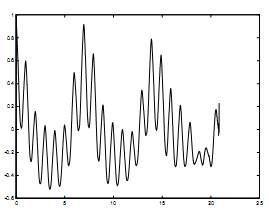
Схема 2. График автокорреляции. Ось абсцисс: день, Ось Ординат: Автокорелляция
3. Модель нестационарности
Недельное отклонение в данных.
Обозначим ![]() процессом
в течение недели. Тогда, t будет
равняться 288*7=2016 числовых величин. Разложим Xt на главный подпроцесс и остаточный подпроцесс, т.е.
процессом
в течение недели. Тогда, t будет
равняться 288*7=2016 числовых величин. Разложим Xt на главный подпроцесс и остаточный подпроцесс, т.е.
![]() (1)
(1)
Где Yt обозначает главный подпроцесс, а XR - остаточный. В каждом случае момента t, Yt является детерминированной, а XR - случайной переменой. Индекс t рассчитывается из i, дня недели, а j, времени дня, таким образом:
t = N × i + j (2)
Где N – число выборки за день.
В [8] изменение построено на ежедневной основе. Причина моделирования процесса на недельном уровне обозначена в схеме 2, где автокорреляция измеряется по трехнедельным данным. Следует обратить внимание, что самая сильная корреляция наблюдается в данных за недельный интервал, что показано на схеме за неделю. Более того, в схеме 3 схематически показан диапазон данных, полученных из формулы Преобразования Фурье за полученные за 20 недель данные. Ось абсцисс представляет количество циклов за неделю. Можно наблюдать два максимума, далеко от первоначальных данных, на 1 и 7 фазе, которые согласовываются с с недельной и дневной фазой. Из данного диапазона данных наблюдается значительное присутствие случайных показателей в недельной фазе. Составляющие на ежедневном уровне 7 (семь фаз в неделю) значительно слабее, что лишь подтверждает версию о наибольшем соответствии условиям недельном пороге.
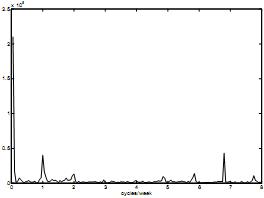
Схема 3. Диапазон данных. Ось абсцисс: фазы/неделя. Ось ординат: диапазонные колебания
Оценивание тренда
Данный раздел посвящен оценке трендовой компоненты Yt в уравнении (1). Предположительно, Yt будет беспрерывным процессом, намного беспрерывнее первоначального процесса Xt.
В отличие от раздела [8], на данной схеме обозначена только 3 непрерывные недели данных за восемь месяцев с целью оценки каждой величины Yt. Данные ограничения объясняются несколькими причинами. Во-первых, мы сократили зависимые величины по ретроспективным данным, что является немаловажным, с момента, когда число ретроспективных данных может быть ограничено благодаря ограничивающим условиям на дисковом пространстве, сетевым изменениям ( что делает данные старевшими), и другим факторам. Во-вторых, сам по себе тренд может меняться с течением времени. Существует множество факторов, влияющих на тренд, как Ир модернизация сетевых настроек, или крупномасштабные изменения в рабочих распределениях внутри компании. Зачастую такие факторы непрогнозируемы. В наших данных, к примеру, функционирование http растет в течении нескольких месяцев. Таким образом, учет данных за более, чем двухнедельный период может во многом повлиять на трендовую модель. Таким образом, введены ограничения по данным за трехнедельный период.
Схема 4 – «Мощность спектральной плотности» за неделю. С момента осмотра целого процесса как наложения двух подпроцессов, тренд можно рассматривать как включающий низкочастотные составляющие, в то время как высокочастотная часть относится к остаточному процессу. Таким образом, используется фильтр нижних частот для отсортировки высокочастотных составляющих, далее отсортированные данные применяются далее для получения тренда. Применяемый здесь фильтр – цифровой низкочастотный фильтр Баиттерволта четвертой степени с нормализованной частотой отсечки 0,2. Подробнее о данном фильтре указано в разделе [10].
Здесь показан алгоритм оценки величины Yt. Пусть импульсная характеристика низкочастотного фильтра будет h(t). Через неделю i, объем данных будет Xi t , а результат после сортировки - Wit . Таким образом,
![]() (3)
(3)
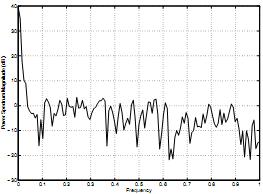
Схема 4. Мощность диапазонной плотности за типичный рабочий день. Ось абсцисс: нормализованная частота, ось ординат: диапазонная амплитуда
Где * обозначает интеграл. Тогда Yt оценивается как
![]() (4)
(4)
Где I – общее число недель. В данной разработке I равняется 3. Тогда в процессе Xt можно вычесть величину Yt , т.е.
XR = Xt − Yt (5)
В разделе 8, трендовая модель объединяет значения за несколько месяцев. В дальнейшем, трендовая модель допускает, что взаимодействие между временем дня и днем недели может быть выражена дополнительным способом. В сущности, модель допускает, что конфигурации разных дней недели могут быть сходными. Мы называем это ежедневная модель тренда.
Наш подход, в котором мы определяем недельную модель, отличается от вышеназванного. Мы утверждаем, что взаимодействие времени дня и дня недели не является аддитивным. Следовательно, имеет смысл применение отдельного периода взаимодействия каждого времени дня и дня недели. В дальнейшем, предположение подобной позиции применимо только по отношению к будням. Очевидно, что выходные намного отличаются моделью от будничных и не могут быть смоделированы подобно им. (В действительности, в работе 8 учитываются только будничные дни). До нынешнего времени ежедневная модель была неприменимой для объяснения аспектных различий между рабочими днями, за исключением их значений. Более точно отражая трендовый процесс, недельная модель имеет недостаток по предоставлению большего количества параметров.
Эффективность двух моделирующих стратегий сравнивается в схеме 5 и в схеме 6 за пять рабочих дней. Остаточный процесс получен применением недельных и ежедневных моделей на одинаковом участке данных (три недели).
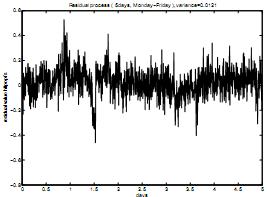
Схема 5. Остаточный процесс после вычета тренда, смоделированного недельной моделью
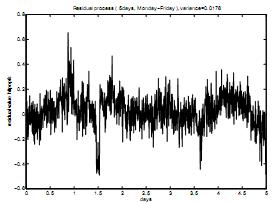
Схема 6. Остаточный процесс после вычета тренда, смоделированного ежедневной моделью.
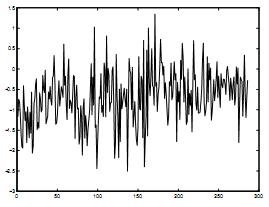
Схема 7. Остаточная модель после вычета тренда. Ось абсцисс: временной индекс в течение дня. Ось ординат: функционирование http после исключения тренда.
Из данного сравнения можно заметить, что недельная модель лучше исключает тренд первоначального процесса, но колебания остаточного процесса меньше, что неудивительно, учитывая предыдущие рассуждения.
4. Моделирование остаточного процесса.
В данном разделе речь идет о моделировании XRt , остаточном процессе. Остаточный процесс оценивается исключением показателя Yt из показателя Xt. На схеме 7 изображены данные за один день после извлечения тренда. На самом деле, данная схема более постоянна по стационарному процессу по отношению к той, где присутствует тренд. Как бы там ни было, данные более изменчивы.
Мы рассматриваем прогнозирование остаточного процесса во времени t + n, что требует оценки его значения и колебаний. Используется авторегрессивная модель. Данная модель является простым и эффективным способом во временном последовательном моделировании. Она также одобрена в некоторых других работах, посвященных анализу сетевого трафика. (например, 6 и 7). Применяющаяся авторегресивнавя модель второго порядка обозначается как AR(2). Таким образом,
![]() (6)
(6)
Где XR обозначает остаточный процесс, φ1 и φ2 - это
два AR(2) параметра, а et –
вектор ошибок, который расценивается как независимый и одинаково распределенный
(н.о.р.) Гауссово случайное поле варьируется нулевым показателем и колебанием σ2ǫ . Когда ![]() и
и ![]() известны,
известны, ![]() прогнозируется как
прогнозируется как
![]() (7)
(7)
Для n-ной степени прогнозирования,
![]() (8)
(8)
Необходимо вернуть извлеченный трендовую составляющую Yt для получения окончательного прогнозируемого значения.
![]() (9)
(9)
5. Определение модели
В данном разделе определяется эффективность модели,
полученной в предыдущих разделах. Центр внимания - ![]() . Действительно, мы
определяем Yt процесс как
детерминистческий. Таким образом, центр определения здесь направлен на
авторегрессивные модели. Применяются характеристики функций авторегрессивной
модели для выборки ограничений прогноза с использованием авторегрессивной
модели. В дополнение к этому, мы детально изучаем вектора ошибок в
авторегрессивной модели, ǫt.
. Действительно, мы
определяем Yt процесс как
детерминистческий. Таким образом, центр определения здесь направлен на
авторегрессивные модели. Применяются характеристики функций авторегрессивной
модели для выборки ограничений прогноза с использованием авторегрессивной
модели. В дополнение к этому, мы детально изучаем вектора ошибок в
авторегрессивной модели, ǫt.
5.1 Характеристическая функция
Здесь изучается точность n этапа прогнозирования. Как и прогнозируется для будущего, колебание прогностического вектора растет, что можно наблюдать в полной мере. Как широко применяющаяся в литературе(например, в №8), модель AR(2) может быть выражена как
![]() (10)
(10)
Где λ1 и λ2 - корни уравнения, 1−φ1B −φ2B2 = 0. Для того, чтобы авторегрессивный процесс был
стабильным, необходимо соблюдать такие требования: |λ1| < 1, |λ2| < 1. С учетом, что
![]() - это
гауссиан, с момента линейной комбинации Гауссовых случайных величин.
- это
гауссиан, с момента линейной комбинации Гауссовых случайных величин.
Определим
![]() (11)
(11)
Далее ![]() выражена как
выражена как
![]() =
= ![]() (12)
(12)
Коэффициент функции G(j) называется характеристической функцией авторегрессивной модели, с помощью которого можно охарактеризовать, насколько можно спрогнозировать будущее на основе текущего значения. Когда значение G(j) невелико, влияние ǫt−j тоже невелико. В дальнейшем, учитывая, что в устойчивой системе G(j) является уменьшающейся в геометрической прогрессии функцией j. Скорость спада обозначена λi. в выходных данных величины λi являются реальными величинами и гораздо меньше, чем одна величина. Как результат – быстро затухающая характеристическая функция G(j), как изображено на схеме 8.
На схеме 8 изображена характеристическая функция с применением величин λi, оцененных из разностей показателей данных одного дня. Как показывает практика, величины λi по большому счету невелики и G(j) мало меняется в течение нескольких дней.
Как показано на схеме, G(j) расположена ниже показателя 0,1уже после пяти этапов (j = 5), что указывает на возможность прогнозировать остаточный процесс как ограниченный.
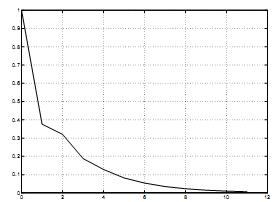
Схема 8. Типичная харатктеристическая функция модели AR(2). Ось абсцисс: j. Ось ординат: G(j).
Ошибка прогнозирования
С целью прогнозирования ![]() можно выразить как
можно выразить как
![]() =
= ![]() (14)
(14)
И ошибка прогнозирования
e(n) = ![]() (15)
(15)
Вектор ошибок является линейной нулевой комбинацией со значением независимой случайной величиной (н.с. в.) Гауссовых случайных величин. Таким образом, данное уравнением также является Гауссианом с нулевым значением, и колебание
![]() (16)
(16)
Для n – этапного прогнозирования из Уравнения 16
дисперсия ошибок определена двумя факторами – дисперсией ошибок одноэтапного
прогнозирования ![]() , па также
характеристической функцией G. Для
авторегрессивного процесса колебание
, па также
характеристической функцией G. Для
авторегрессивного процесса колебание ![]() постоянно. Тогда G(j) определяет как дисперсия ошибок увеличивается по
мере роста этапов n. Из представленной на
схеме 8 характеристической функции можно заметить, что влияние прошлых величин
незначительно уже после пяти этапов. Таким образом, когда мы прогнозируем более
пяти этапов вперед, прогнозируемая величина приближается к нулю, а дисперсия
ошибок увеличивается.
постоянно. Тогда G(j) определяет как дисперсия ошибок увеличивается по
мере роста этапов n. Из представленной на
схеме 8 характеристической функции можно заметить, что влияние прошлых величин
незначительно уже после пяти этапов. Таким образом, когда мы прогнозируем более
пяти этапов вперед, прогнозируемая величина приближается к нулю, а дисперсия
ошибок увеличивается.
Для окончательного вывода по последнему аргументу предоставляется понятие этапов прогнозирования для авторегрессивной модели. Целью является измерить количество этапов в будущем, для которого целесообразно делать прогноз.
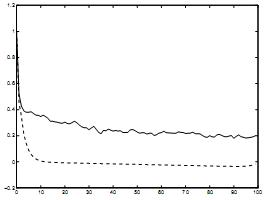
Схема 9. Сравнение автокорреляционной функции. ’-’: остаточный процесс. ’–’: авторегрессионный процесс. Ось абсцисс: промежуток. Ось ординат: автокорреляция.
Отношение между s2(t + n) и ![]() позволяет
определить количество n этапов прогнозирования
за период времени t.
позволяет
определить количество n этапов прогнозирования
за период времени t.
![]()
![]() (17)
(17)
Данное выражение предоставлено в форме «шум - помеха». Здесь – сигнал является прогнозной величиной, а шум – прогнозируемым колебанием. Из понятия «характеристической функции» известно, что так как авторегрессионные прогнозы распространяются в будущее, прогнозируемая величина авторегрессионного процесса уменьшается, а ее колебание увеличивается. Таким образом, snr является уменьшающейся функцией n.
Следующим утверждением является то, что snr можно
применять в качестве правила остановки для авторегрессионного прогнозирования.
Когда snr опускается ниже заданного порога, прогнозирование на основе
авторегрессии по условию не должно продолжаться. Однако, для данного применения
все же можно использовать тренд для получения данных о будущем. Можно
приравнять ![]() к
нулю, и таким образом получим, что
к
нулю, и таким образом получим, что ![]() . Таким образом, для большего значения
n учитывается только трендовая составляющая при составлении прогноза.
. Таким образом, для большего значения
n учитывается только трендовая составляющая при составлении прогноза.
Мы кратко рассматриваем второе издание относительно применения авторегрессивной модели. Это относится к долгосрочной зависимости в данных. Другие источники указывают, что сетевой трафик представляет долгосрочную зависимость (например, № 11). На схеме 9 изображена автокорелляционная функция остаточного процесса в текущим данным и автокорреляционая функция авторегрессивного процесса с использованием параметров, полученных из остаточного процесса.
Как видно, для больших промежутков времени автокорреляция авторегрессионного процесса угасает достаточно быстро, в то время как корреляция данных угасает с гораздо меньшей скоростью, выявляя долгосрочную зависимость. Данный сбой в области измерения зависимых величин является недостатком авторегрессивной модели и влияет на ее возможность прогнозировать остаточный процесс, в особенности для большего значения величины n.
5.3 Вероятность нарушения порога
Важным применением прогностических моделей для профилактического управления является оценка вероятности нарушения порогового значения (например, как в №8). Это осуществляется оцениванием значения и колебания будущего обследования и последующим использованием предположения Гаусианских векторов ошибок.
Для более детального описания составим n этапное
прогнозирование. Случайная величина ![]()
Может быть выражена как ![]() =
= ![]() +
+ ![]() , где ˆX(t+n)
получено из
, где ˆX(t+n)
получено из
![]() (18)
(18)
что является суммированием тренда и прогнозируемой величины остаточного процесса.
Распределение случайной величины ![]() обусловлено распределением
величины
обусловлено распределением
величины ![]() ,
которая стремится к нулевому значению Гауссовой случайной величины. Тогда
величина
,
которая стремится к нулевому значению Гауссовой случайной величины. Тогда
величина ![]() также
является Гауссовой случайной величиной со значением, полученным из уравнения
18, и колебанием из уравнения 16.
также
является Гауссовой случайной величиной со значением, полученным из уравнения
18, и колебанием из уравнения 16.
Допустим, что пороговое значение равно Т, для которого
нам необходимо оценить вероятность, что ![]() > Т. Как и в № 8, преобразуем
величину Т в модуль
> Т. Как и в № 8, преобразуем
величину Т в модуль ![]() , который переходит в зависящий от
времени порог, чье значение равно
, который переходит в зависящий от
времени порог, чье значение равно ![]() за время t+n.
Таким образом, этого достаточно, чтобы определить вероятность, что
за время t+n.
Таким образом, этого достаточно, чтобы определить вероятность, что ![]() >
> ![]() , с учетом значения
, с учетом значения
![]() и его
колебания
и его
колебания ![]() .
Пусть
.
Пусть ![]() определяет
данную вероятность. Тогда
определяет
данную вероятность. Тогда
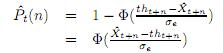 (19)
(19)
Где Ф° - кумулятивная распределительная функция Гаусового распределения N (0,1).
5.4 Распределение вектора ошибки
Предыдущий анализ построен на основе предположения Гаусового распределения для вектора ошибки. Однако, вектор ошибки может быть и не Гауссовым. На схеме 10 изображен график квантилей одноэтапного прогностического распределения ошибок в сравнении с Гауссовым. Прямая линия – это полоса Гаусса, а жирная линия характеризует вектор ошибок. В линейном способе двух распределений замечаются значительные различия, то есть полоса прогнозной ошибки толще линии Гаусса. То есть когда порог уменьшается, Гауссово допущение показывает вероятность нарушения порога. Боле того, из графика квантилей прогнозное распределение ошибок связано с Гауссовым распределением во многих точках, кроме конечной фазы. В действительности можно столкнуться со случаями, когда вероятность порогового нарушения намного больше и пренебрегает маленькими вероятностями. В таком случае сбой в конечной фазе не является главным вопросом. В том смысле, применение Гаусового допущения является приемлемым для распределения ошибок.
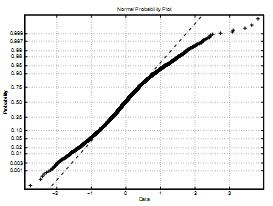
График 10. График квантилей прогнозирования ошибок.
6. Выводы
Профилактическое управление позволяет сетевым провайдерам применить предупреждающие меры в отношении сервисных нарушений. Однако, возможность упреждения требует способности прогнозировать реакцию системы. Данная работа исследует вопросы, относящиеся к прогнозированию в контексте данных WEB-сервера.
Нашей целью было расширение данной деятельности [8] несколькими способами. Данное расширение включает: усиление трендовой модели с помощью применения методик сортировки и рассмотрения тренда в разрезе укороченного временного диапазона; исследование допущений, лежащих в основе стационарной составляющей, включая допущение Гауссового распределения для вектора ошибок в остаточном процессе; анализ ограничений прогнозирования с использованием авторегрессионной модели; было доказано, что долгосрочная зависимость сохраняется в данных даже после того, как тренд и постоянные составляющие удалены, что влечет изменения для прогноза.
Очевидно, что существует много областей, которые должны быть изучены более подробно. Фундаментальное внимание должно быть уделено пакетным данным и нестационарным данным. Модель AR(2) не предназначена для работы с долгосрочной зависимостью. Модель, способная работать с долгосрочной зависимостью улучшит точность прогноза. С другой стороны, мы моделируем тренд как устойчивый непрерывный процесс. Прогнозирование, основанное на остаточном процессе, ограничивает качество прогноза, что связано со способностью авторегрессивной модели и помехами остаточного процесса. Мы можем улучшить прогнозирование с помощью прогнозирования альтернативного тренда, с меньшим числом помех, имеющихся в остаточном процессе. Это требует приспосабливаемой трендовой модели для записи развития тренда. Иногда сетевых управленцев интересует больше прогнозирование тренда.
Благодарность
Выражаем благодарность Шенг Ма за любезный комментарий и поддержание дискуссии.
References
[1]GeorgeE.P.Box,GwilymM.Jenkins, TimeSeriesForecastingandCon-
trol,PrenticeHall,1976.
[2]M.Dutta,ExecutiveEditor, Economics,EconometricsandtheLinks,
NorthHolland,1995.
[3]AndreiS.Monin,WeatherForecastingasaProbleminPhysics,MITPress,
Cambridge,MA1972.
[4]AdrianCochcroft,“WatchingYourWebServers”,SunWorldOnLine,
http://www.sunworld.com/swol-03-1996/swol-03-perf.html.
[5]C.S.Hood,C.Ji,”ProactiveNetworkFaultDetection”,ProceedingsofIN-
FOCOM,Kobe,Japan,1997.
[6]P.Hoogenboom,J.Lepreau,“ComputerSystemPerformanceDetection
UsingTimeSeriesModels”,Proc.oftheSummerUSENIXConference,
pp.15-32,1993.
[7]MarinaThrottan,C.Ji,“AdaptiveThresholdingforProactiveNetwork
ProblemDetection,”ThirdIEEEInternationalWorkshoponSystems
Management,pp.108-116,Newport,RhodeIsland,April,1998.
[8]JosephL.Hellerstein,FanZhang,P.Shahabuddin,“AnApproachtoPre-
dictiveDetectionforServiceManagement,”SymposiumonIntegratedNet-
workManagement,1999.
[9]ThomasKailath, KalmanFiltering:TheoryandPracitce,PrenticeHall,
1993.
[10]BernardWidrow,SamuelD.Strearns, AdaptiveSignalProcessing,Prentice
Hall,1985.
[11]W.E.Leland,M.S.Taqqu,WalterWillinger,D.V.Wilson,“OntheSelf-
SimilarityNatureofEthernetTraffic(ExtendedVersion)”, IEEETrans.
onNetworking,Vol.2,No.1,pp.1-14,Feb.1994.