

ПРОГРАММНАЯ РЕАЛИЗАЦИЯ ТЕХНОЛОГИИ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ
Автор: Ладыженский Ю.В., Алейкин В.В.
Источник: Ладыженский Ю.В., Алейкин В.В. Программная реализация технологии распознавания текстовой информации / Ладыженский Ю.В., Алейкин В.В. // Інформатика та ком'ютерні технології / Матеріали V міжнародної науково-технічної конференції студентів, аспірантів та молодих науковців – 24-26 листопада 2009 р., Донецьк, ДонНТУ. – 2009, с. 261-264
Введение
Распознавание изображений содержащих текстовую информацию обеспечивает решение многих прикладных задач при идентификации объектов различной природы. Современные методы распознавания символов используются для распознавание текста и маркировки различных объектов. При идентификации изображений наибольшие искажения, влияющие на результат распознавания, вносят аффинные и проективные искажения[1]. Они существенно снижают надежность распознавания известными методами. Существуют три основных подхода для решения задачи распознавания символов: структурный, признаковый и шаблонный[1].
Основаная часть
Шаблонные методы сравнивают изображение со всеми имеющимися в базе шаблонами. Наиболее подходящим шаблоном является тот, у которого будет наименьшее количество точек, отличных от исследуемого изображения. Основной недостаток метода в невозможности распознать шрифт, отличающийся от находящегося в базе. Признаковые методы наиболее распространены. Они основаны на том, что анализируется только набор признаков, определенных в изображении. Недостаток метода в том, что идентификации подвергается не сам символ, а набор его признаков, это может привести к неправильному распознаванию символов. Структурные методы выделяют информацию о топологии символа, расположении структурных элементов символа, что делает не важным размер образа. Недостаток метода - большие затраты времени и памяти, поскольку ведется построение скелета, определение округлостей, угловых и соотношений между линиями, а также определение пробелов[2].
Все указанные методы ограничены в условиях применимости. Поэтому необходимо разработать методы распознавания, базирующихся на применении признаков, инвариантных к аффинным и проективным преобразованиям. В качестве таких признаков предлагается использовать топологические особенности символов, которые извлекаются при помощи методов анализа формы изображения, использующие морфологические операторы[1].
Символы обладают определенными признаками, такими как «залив» и «озеро». «Заливы» примыкают одной стороной к символу, а другой - к границе образа. «Озера» не примыкают к границе образа, они находятся внутри символа. Например, у символа ‘B’ существует два «озера» (Рис. 1а), а у символа «N» - два «залива» (Рис. 1б).

Рисунок 1 - Выделение морфологических признаков
Для более полного определения описанных признаков введем вектор Х, состоящий из признаков, характеризующий количество: х1 – верхний залив, х2 – правый залив, х3 – нижний залив, х4 –левый залив, х5 – озеро. Используя такой вектор признаков, можно легко выделить группу символов, которые имеют эти признаки и далее, если таких символов больше одного – применить метод шаблонного сопоставления или любой другой[1].
Для определения областей заливов и озер необходимо использовать сочетание морфологических операторов наращивание, эрозия, размыкание и замыкание. Два последних оператора определяются в виде: X○B=(X-B)+B; X●B=(X+B)–B.
Где Х – исходное множество, B – структурирующий элемент (СЭ), ‘-’ – эрозия, ‘+’ – наращивание.
Заключение
Для распознавания с использованием описанного метода была реализована программная система, которая позволяет нарисовать образ символа в специальном окне для рисования и распознать этот образ, при этом выведя полную информацию по распознаванию. При вводе символа ‘U’ (Рис. 2а) и нажатии на кнопке «Analysis» в области «Results of recognition» будет показан слева красный символ – характеризующий входной образ, полученный путем масштабирования рисуемого, а справа синий символ – образ из БД для сопоставления. Первый этап распознавания образа производиться по методу морфологического анализа символа – на распознаваемом символе выделяются заливы и озера. На рассматриваемом символе был выделен один залив, расположенный сверху символа. Вектор признаков будет иметь вид [10000]. Такой вектор соответствует символам ‘U’, ‘Y’ и ‘V’. Второй этап анализа состоит в шаблонном сопоставлении входного образа с образами из БД для получения наиболее похожего символа из найденных на первом этапе. В данном случае вероятность, что образ соответствует символу ‘U’ равняется 86%, что можно увидеть в области «Results of analysis». Используя этот же подход, при введении символа ‘H’ (Рис. 2б) получаем вектор признаков [10100], и найденный образ соответствует шаблонному символу ‘H’ с вероятностью 93%. Разработанная программа позволяет ввести подряд несколько символов, при этом программа будет распознавать их по отдельности, описанным методом, результат можно увидеть в области «Results of recognition».
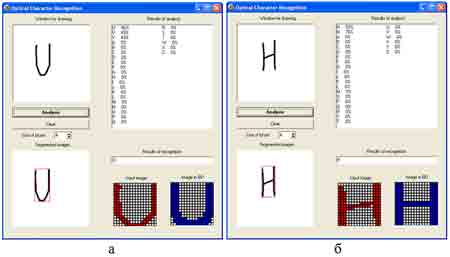
Рисунок 2 - Результаты работы демо-версии программы
Использованная литература
1. Шапиро Л., Стокман Дж. Компьютерное зрение; Пер с англ. – М.: БИНОМ. Лаборатория знаний, 2009. – 752с., 8с. ил.: ил.
2. Форсат, Дэвид А., Понс, Жан. Компьютерное зрение. Современный подход. : Пер. с англ. – М. : Издательский дом «Вильямс», 2004. -928с. % ид.- Парал. тит. англ.

© Магістр ДонНТУ Алейкин Владислав Валерьевич