Совместно используемая память машины MIMD
На рисунке 1 уже покан один подкласс этого типа машин. Фактически, векторная машина с одним процессора, обсужденная там, была частным случаем более общего типа. Иллюстрация показывает, что больше чем один FPU и/или VPU могут быть возможными в одной системе.
Главной проблемой, с которой сталкиваются в системах совместно используемой памяти, является проблема связи центральных процессоров друг с другом и с памятью. Поскольку больше центральных процессоров добавлено, коллективная полоса пропускания к памяти идеально должна увеличиться линейно на числом процессоров, в то время как каждый процессор должен предпочтительно общаться непосредственно со всеми другими без намного более медленной альтернативы необходимости использовать память в промежуточной стадии. К сожалению, полная взаимосвязь является весьма дорогостоящей, возрастая на с O(n²), увеличивая число процессоров на O(n). Так, попробовали различные альтернативы. Рисунок 4 показывает некоторые из структур взаимосвязи, которые используются (и использовались).
Как может быть замечено из рисунка, кроссбар использует n² связи, Ω-сеть использует nlog2n связей в то время как, с центральной шиной, есть только одна связь. Это отражено в использовании каждого пути связи для различных типов взаимосвязей: для кроссбара каждый информационный канал является прямым и не должен быть разделен с другими элементами. В случае Ω-сети есть logn переключающихся стадий, и так многим элементам данных, вероятно, придется конкурировать за любой путь. Для центральной шины данных все данные должны разделить ту же самую шину, таким образом n элементов данных могут конкурировать в любое время.
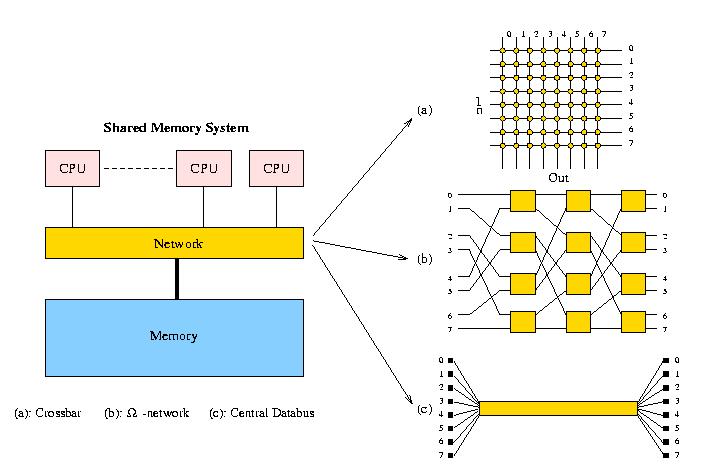
Рисунок 4: Некоторые примеры структур взаимосвязей, используемых в совместно используемой памяти системы MIMD.
Шинная связь - наименее дорогое решение, но у него есть очевидный недостаток, заключающийся в том, что может произойти шинная конкуренция, таким образом замедляя вычисления. Были разработаны различные запутанные стратегии, использующие кеш, ассоциированные с центральными процессорами, для того чтобы минимизировать шинный трафик. Это приводит однако к более сложной шинной структуре, которая увеличивает затраты. Практически оказалось очень сложным проектировать шины, которые были бы достаточно быстры, особенно там, где скорость процессоров увеличивалась очень быстро, и это налагает верхнюю границу на число процессоров таким образом, что число процессоров не превышает 10-20. В 1992 был определен новый стандарт (IEEE P896) для быстрой шины для соединения или внутренних компонентов системы, или с внешними системами. Эта шина, названная Масштабируемым Последовательным Интерфейсом (SCI), должна обеспечить двухточечную полосу пропускания 200-1000 Mbyte/s. Это фактически используется в системах Образца HP, но также и в пределах кластера рабочих станций как предлагающийся SCALI. SCI намного больше чем простая шина, и она может действовать как структура сети аппаратных средств для распределенного вычисления, см. [20].
Многоступенчатый кроссбар - это сеть с логарифмической сложностью, и у нее есть структура, которая расположена где-нибудь между шиной и кроссбаром относительно потенциальной способности и затрат. Ω-сеть изображена на рисунке 4 как пример. Коммерчески доступные машины как IBM eServer p690, SGI Origin3000, и последний Cenju-4 используют такую структуру сети, но много экспериментальных машин также использовали ее или подобный вид взаимосвязи. BBN TC2000, который действовал как виртуальная система MIMD с совместно используемой памятью, использовал аналогичный тип сети (Сеть-бабочка), и весьма возможно, что новые машины могут использовать такую структуру, тем более, что число процессоров растет. Для большого количества процессоров nlog2n связи быстро становятся более привлекательными чем n² используемые в кроссбарах. Конечно, переключатели на промежуточных уровнях должны быть достаточно быстрыми, чтобы справиться с требуемой полосой пропускания. Очевидно, не только структура, но также и ширина связей между процессорами важны: у сети, используя 16-битовые параллельные связи будет полоса пропускания, которая в 16 раз выше чем сеть с той же самой топологией, осуществленной с последовательными связями.
Во всех современных мультипроцессорных векторпроцессорах используются кроссбары. Это все еще выполнимо, потому что максимальное число процессоров в системе является все еще довольно маленьким (32 самое большее теперь). Когда число процессоров увеличилось бы, однако, могли бы возникнуть технологические проблемы. Не только становится труднее построить кроссбар достаточной скорости для больших чисел процессоров, процессоры сами увеличиваются в скорости индивидуально, удваивая проблемы создания скорости соединений кроссбара, требуемой процессорами.
Какая бы сеть не использовадась, тип процессоров в принципе мог быть произвольным для любой топологии. Практически, однако, шинно-структурированные машины не имеют векторных процессоров, поскольку скорости их чрезвычайно не сочетались бы с любой шиной, которая могла быть построен с разумными затратами. Все доступные шинно-ориентируемые системы используют процессоры RISC. Локальный кэш процессоров может иногда облегчать проблему полосы пропускания, если доступ к данным может быть удовлетворен кэш-памятью, таким образом избегая ссылок на память.
Системы, обсужденные в этом подразделе, имеют тип MIMD, и поэтому различные задачи могут протекать на различных процессорах одновременно. Во многих случаях требуется синхронизация между задачами, и снова структура взаимосвязи здесь очень важна. Большинство векторных процессоров использует специальные регистры коммуникации в пределах центральных процессоров, с помощью которых они могут общаться непосредственно с другими центральными процессорами, с которыми они должны синхронизироваться. Системы могут также синхронизироваться через совместно используемую память. Вообще, это является намного медленнее, но может все еще быть приемлемым, когда синхронизация происходит относительно редко. Конечно в основанных на шинах системах коммуникации также должны быть сделан через шины. Эти шины главным образом отделены от шины данных, чтобы гарантировать максимальную скорость для синхронизации.