|
<< Назад в библиотеку
Analytical Modeling of Parallel Programs
Author: Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar
Topic Overview
- Sources of Overhead in Parallel Programs
- Performance Metrics for Parallel Systems
- Effect of Granularity on Performance
- Scalability of Parallel Systems
- Minimum Execution Time and Minimum Cost-Optimal Execution Time
- Asymptotic Analysis of Parallel Programs
- Other Scalability Metrics
Analytical Modeling - Basics
- A sequential algorithm is evaluated by its runtime (in general, asymptotic runtime as a function of input size).
- The asymptotic runtime of a sequential program is identical on any serial platform.
- The parallel runtime of a program depends on the input size, the number of processors, and the communication parameters of the machine.
- An algorithm must therefore be analyzed in the context of the underlying platform.
- A parallel system is a combination of a parallel algorithm and an underlying platform.
- A number of performance measures are intuitive.
- Wall clock time - the time from the start of the first processor to the stopping time of the last processor in a parallel ensemble. But how does this scale when the number of processors is changed of the program is ported to another machine all together?
- How much faster is the parallel version? This begs the obvious followup question - whats the baseline serial version with which we compare? Can we use a suboptimal serial program to make our parallel program look.
- Raw FLOP count - What good are FLOP counts when they dont solve a problem?
Sources of Overhead in Parallel Programs
- If I use two processors, should not my program run twice as fast?
- No - a number of overheads, including wasted computation, communication, idling, and contention cause degradation in performance.
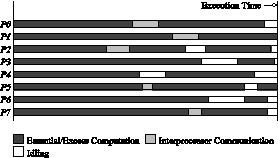
The execution profile of a hypothetical parallel program executing on eight processing elements. Profile indicates times spent performing computation (both essential and excess), communication, and idling.
Sources of Overheads in Parallel Programs
- Interprocess interactions: Processors working on any non-trivial parallel problem will need to talk to each other.
- Idling: Processes may idle because of load imbalance, synchronization, or serial components.
- Excess Computation: This is computation not performed by the serial version. This might be because the serial algorithm is difficult to parallelize, or that some computations are repeated across processors to minimize communication.
Performance Metrics for Parallel Systems: Execution Time
- Serial runtime of a program is the time elapsed between the beginning and the end of its execution on a sequential computer.
- The parallel runtime is the time that elapses from the moment the first processor starts to the moment the last processor finishes execution.
- We denote the serial runtime by and the parallel runtime by TP.
Performance Metrics for Parallel Systems: Total Parallel Overhead
- Let Tall be the total time collectively spent by all the processing elements.
- Ts is the serial time.
- Observe that Tall - Ts is then the total time spend by all processors combined in non-useful work. This is called the total overhead.
- The total time collectively spent by all the processing elements Tall = p Tp (p is the number of processors).
- The overhead function (To) is therefore given by To = p Tp - Ts (1)
Performance Metrics for Parallel Systems: Speedup
- What is the benefit from parallelism?
- Speedup (S) is the ratio of the time taken to solve a problem on a single processor to the time required to solve the same problem on a parallel computer with p identical processing elements.
Performance Metrics: Example
- Consider the problem of adding n numbers by using n processing elements.
- If n is a power of two, we can perform this operation in log n steps by propagating partial sums up a logical binary tree of processors.
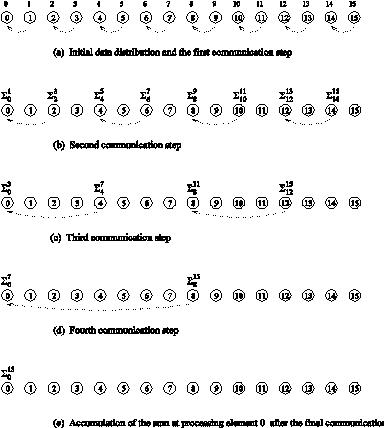
Computing the globalsum of 16 partial sums using 16 processing elements . ?ji denotes the sum of numbers with consecutive labels from i to j.
- If an addition takes constant time, say, tc and communication of a single word takes time ts + tw, we have the parallel time Tp =
 (log n) (log n)
- We know that Ts = (n)
- Speedup S is given by S = (n / log n)
Performance Metrics: Speedup
- For a given problem, there might be many serial algorithms available. These algorithms may have different asymptotic runtimes and may be parallelizable to different degrees.
- For the purpose of computing speedup, we always consider the best sequential program as the baseline.
Performance Metrics: Speedup Example
- Consider the problem of parallel bubble sort.
- The serial time for bubblesort is 150 seconds.
- The parallel time for odd-even sort (efficient parallelization of bubble sort) is 40 seconds.
- The speedup would appear to be 150/40 = 3.75.
- But is this really a fair assessment of the system?
- What if serial quicksort only took 30 seconds? In this case, the speedup is 30/40 = 0.75. This is a more realistic assessment of the system.
Performance Metrics: Speedup Bounds
- Speedup can be as low as 0 (the parallel program never terminates).
- Speedup, in theory, should be upper bounded by p - after all, we can only expect a p-fold speedup if we use times as many resources.
- A speedup greater than p is possible only if each processing element spends less than time TS / p solving the problem.
- In this case, a single processor could be timeslided to achieve a faster serial program, which contradicts our assumption of fastest serial program as basis for speedup.
Performance Metrics: Superlinear Speedups
One reason for superlinearity is that the parallel version does less work than corresponding serial algorithm.
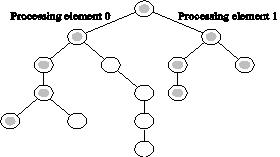
Searching an unstructured tree for a node with a given label, `S', on two processing elements using depth-first traversal. The two-processor version with processor 0 searching the left subtree and processor 1 searching the right subtree expands only the shaded nodes before the solution is found. The corresponding serial formulation expands the entire tree. It is clear that the serial algorithm does more work than the parallel algorithm.
Resource-based superlinearity: The higher aggregate cache/memory bandwidth can result in better cache-hit ratios, and therefore superlinearity.
Example: A processor with 64KB of cache yields an 80% hit ratio. If two processors are used, since the problem size/processor is smaller, the hit ratio goes up to 90%. Of the remaining 10% access, 8% come from local memory and 2% from remote memory.
If DRAM access time is 100 ns, cache access time is 2 ns, and remote memory access time is 400ns, this corresponds to a speedup of 2.43!
Performance Metrics: Efficiency
- Efficiency is a measure of the fraction of time for which a processing element is usefully employed
- Mathematically, it is given by E=S/P (2)
- Following the bounds on speedup, efficiency can be as low as 0 and as high as 1.
|

