Real-Time Ray Tracing with NVIDIA CUDA GPGPU and Intel Quad-Core
Eric Rollins
Источник:http://eric_rollins.home.mindspring.com/ray/cuda.html

Introduction
This page is a continuation of previous work, Real-Time Ray Tracing on the Playstation 3 Cell Processor.
The ray-tracing test case is identical. The code has been modified to utilize the NVIDIA GPU, and multiple
cores using Posix threads.
NVIDIA CUDA GPGPU
In Four-Dimensional Cellular Automata Acceleration Using GPGPU I previously experimented with GPGPU
(General Purpose computation on Graphics Processing Units).
This programming was difficult because it involved essentially "fooling" OpenGL shaders into doing
non-graphics computations. All programing was done through the OpenGL graphics API.
WithCUDA NVIDIA has provided a non-graphics API
for doing general purpose programming on their 8 series GPUs.
It is supported under Windows XP and Linux; drivers and SDK are available
here.
While my example is graphical, only the SDL frame buffer capability of the GPU is being used.
All object rendering computations are done by my CUDA code running on the GPU —
the card doesn't know this is a graphical computation.
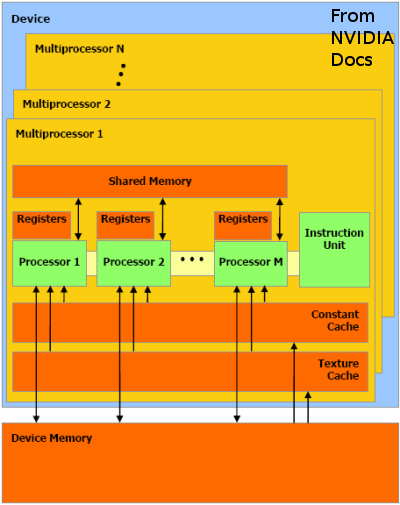
The NVIDIA GPU has multiple multiprocessors: 12 on the GeForce 8800 GTS I tested.
Each multiprocessor has 8 processors, and with them each multiprocessor can support up to 768 concurrent threads.
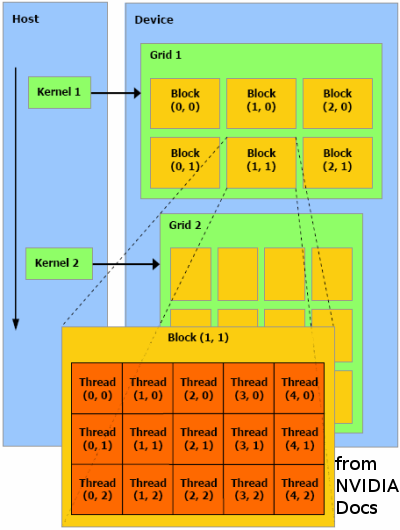
Under CUDA the programmer writes a kernel which is the code executed by a single thread.
Threads are placed in two or three-dimensional groupings called blocks, and blocks in turn are placed
in two-dimensional groupings called grids. The run-time system schedules blocks and grids to run as resources
are available. The general computational model is SIMD: the same kernel instructions are executed by all threads.
The NVIDIA C compiler supports fairly standard C with branches, loops, etc., but no recursion.
Like the SPUs on the PS3 Cell processor, GPU memory is limited and access to host memory is slow.
Data is explicitly moved from the host to the device by the host program. Here data is in device global memory
(shared between all multiprocessors), which is still quite slow. The kernel threads can copy data from global
memory to shared memory (shared between processors in a single multiprocessor), though shared memory
is limited to 16K per multiprocessor.
My Program on CUDA
The previous ray-tracing code has been split into host and device kernel portions.
The device kernel is executed by each thread. The threads are arranged into 16x16 blocks,
and the blocks in turn form a 64x35 grid. Each thread processes a single pixel of the 1024x564 display.
At the beginning of each frame the current world state structure is copied by the host to the global memory
of the device. The 0,0 thread in each block in turn copies this world state structure into shared memory to
provide faster access for all the threads in its block. Note this shared memory is read-only from the threads
point of view — they never update it. At the end of each thread's computation it writes its results
(a single pixel color) to another device global array. When all threads have completed the host program reads
the device global array and writes it to the SDL frame buffer.
With this design CUDA is not a practical way to implement a ray-tracer. The 16K shared memory restriction
makes realistic world models impractical. It appears the
number of threads which can be started simultaneously is constrained by the size of the world state structure:
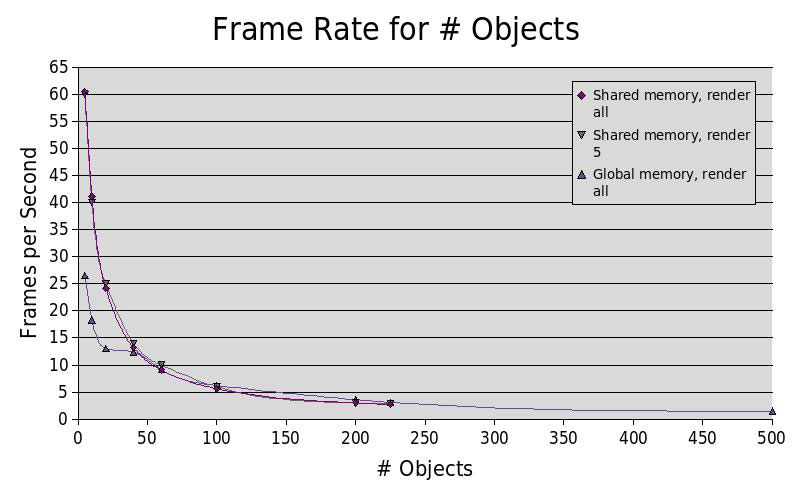
Here we see that with a small number of objects in the world the program runs faster with shared memory. With a large number of objects in the world it is actually faster without shared memory (and shared memory cannot fit more than 225 objects). The Shared memory speedup is independent of whether all the objects are actually rendered. The program bottleneck is not in looping over the objects, but in the speed of access to object data and the number of threads which can be simultaneously started.
Pthreads on Intel Quad-Core
The generic ray-tracer code has been modified to use pthreads. At the beginning of each frame 4 threads
are created and given starting screen line numbers. Like the PS3 cell ray tracer, the first thread will render
the 1,5,9, etc. line, while the second thread renders 2, 6, 10, etc. The main program does a join waiting
for all the threads to complete. The program does not scale linearly with the number of CPUs, indicating
it may be bottle-necking on writing the results to main memory.
It might run faster if it batched its writes like the PS3 version.
Results
The new code is available here
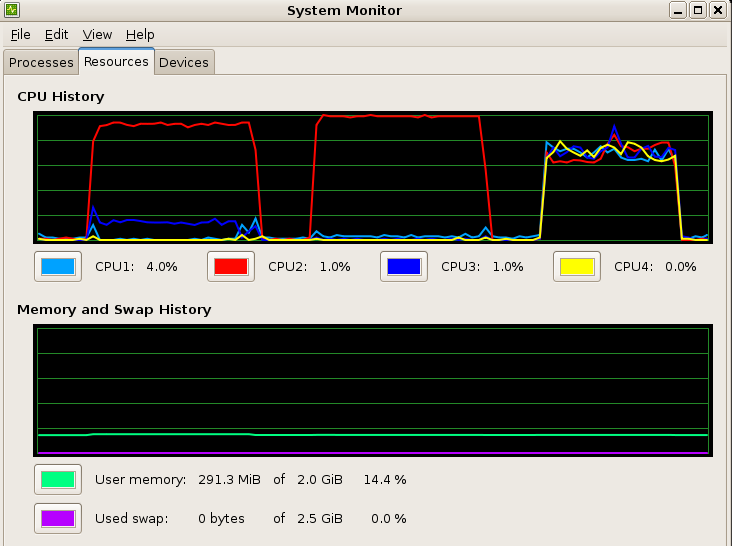
 Below shows CPU and memory utilization during NVIDIA CUDA GPGPU, generic 1 pthread, and generic 4 pthreads tests.
In the CUDA test my ray program used 92% of one CPU and the Xorg X-windows server used 12% of another CPU.
Below shows CPU and memory utilization during NVIDIA CUDA GPGPU, generic 1 pthread, and generic 4 pthreads tests.
In the CUDA test my ray program used 92% of one CPU and the Xorg X-windows server used 12% of another CPU.
Update (7/2007)
I obtained an evaluation copy of the Intel C++ Compiler 10.0, Professional Edition, for Linux.
I was curious to try their SSE auto-vectorization code. With 4 threads it was 21% faster than GCC.
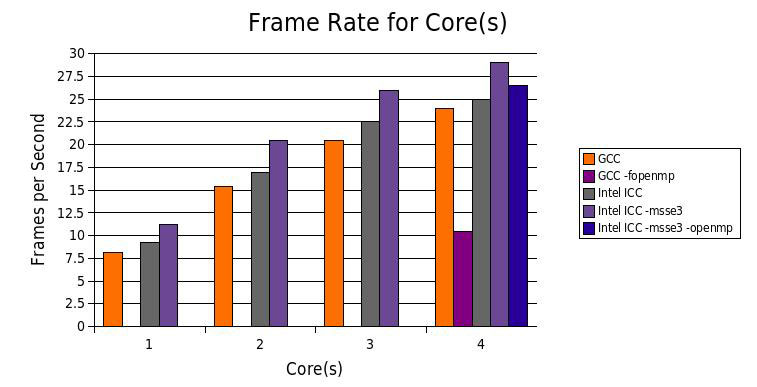
Update (12/2007)
Intel C++ supports OpenMP, a standardized API for shared-memory multiprocessing in C++.
By adding a simple #pragma loops can be split up to automatically run in parallel on multiple cores.
I added a simple change to the per-screen-line rendering loop of the generic ray tracer:
int screenX;
#ifdef USE_OMP
#pragma omp parallel for firstprivate(portPoint)
#endif
for (screenX = 0; screenX < SCREEN_WIDTH; screenX++)
{ ... }
With this change each pixel is rendered by a separate thread, with a maximum of 4 (the number of cores)
running simultaneously. This use of threads is an alternative to the explicit pthread threading tested above,
where a separate thread is used per line of the screen. In this case OpenMP is simpler than explicit threading,
though it yields slightly lower performance.
GCC 4.2 also supports OpenMP, but its performance is much worse than Intel.
Update (1/2009)
I've ported the generic and CUDA ray tracers to Mac OS X running on a MacBook Pro laptop.
It has a 2.4GHz Intel Core 2 Duo processor and a NVIDIA GeForce 9600M GT graphics processor.
The Performance for 1 and 2 software threads is comparable to my older Linux desktop,
and the CUDA is within a factor of 3 of the desktop graphics card
Threads Frames Per Second
1 8.5
2 17.4
GPU 16.7
Eric Rollins
Источник:http://eric_rollins.home.mindspring.com/ray/cuda.html
Introduction
This page is a continuation of previous work, Real-Time Ray Tracing on the Playstation 3 Cell Processor. The ray-tracing test case is identical. The code has been modified to utilize the NVIDIA GPU, and multiple cores using Posix threads.
NVIDIA CUDA GPGPU
In Four-Dimensional Cellular Automata Acceleration Using GPGPU I previously experimented with GPGPU (General Purpose computation on Graphics Processing Units). This programming was difficult because it involved essentially "fooling" OpenGL shaders into doing non-graphics computations. All programing was done through the OpenGL graphics API. WithCUDA NVIDIA has provided a non-graphics API for doing general purpose programming on their 8 series GPUs. It is supported under Windows XP and Linux; drivers and SDK are available here.
While my example is graphical, only the SDL frame buffer capability of the GPU is being used. All object rendering computations are done by my CUDA code running on the GPU — the card doesn't know this is a graphical computation.
The NVIDIA GPU has multiple multiprocessors: 12 on the GeForce 8800 GTS I tested. Each multiprocessor has 8 processors, and with them each multiprocessor can support up to 768 concurrent threads.
Under CUDA the programmer writes a kernel which is the code executed by a single thread. Threads are placed in two or three-dimensional groupings called blocks, and blocks in turn are placed in two-dimensional groupings called grids. The run-time system schedules blocks and grids to run as resources are available. The general computational model is SIMD: the same kernel instructions are executed by all threads. The NVIDIA C compiler supports fairly standard C with branches, loops, etc., but no recursion.
Like the SPUs on the PS3 Cell processor, GPU memory is limited and access to host memory is slow. Data is explicitly moved from the host to the device by the host program. Here data is in device global memory (shared between all multiprocessors), which is still quite slow. The kernel threads can copy data from global memory to shared memory (shared between processors in a single multiprocessor), though shared memory is limited to 16K per multiprocessor.
My Program on CUDA
The previous ray-tracing code has been split into host and device kernel portions. The device kernel is executed by each thread. The threads are arranged into 16x16 blocks, and the blocks in turn form a 64x35 grid. Each thread processes a single pixel of the 1024x564 display. At the beginning of each frame the current world state structure is copied by the host to the global memory of the device. The 0,0 thread in each block in turn copies this world state structure into shared memory to provide faster access for all the threads in its block. Note this shared memory is read-only from the threads point of view — they never update it. At the end of each thread's computation it writes its results (a single pixel color) to another device global array. When all threads have completed the host program reads the device global array and writes it to the SDL frame buffer.
With this design CUDA is not a practical way to implement a ray-tracer. The 16K shared memory restriction makes realistic world models impractical. It appears the number of threads which can be started simultaneously is constrained by the size of the world state structure:
Here we see that with a small number of objects in the world the program runs faster with shared memory. With a large number of objects in the world it is actually faster without shared memory (and shared memory cannot fit more than 225 objects). The Shared memory speedup is independent of whether all the objects are actually rendered. The program bottleneck is not in looping over the objects, but in the speed of access to object data and the number of threads which can be simultaneously started.
Pthreads on Intel Quad-Core
The generic ray-tracer code has been modified to use pthreads. At the beginning of each frame 4 threads are created and given starting screen line numbers. Like the PS3 cell ray tracer, the first thread will render the 1,5,9, etc. line, while the second thread renders 2, 6, 10, etc. The main program does a join waiting for all the threads to complete. The program does not scale linearly with the number of CPUs, indicating it may be bottle-necking on writing the results to main memory. It might run faster if it batched its writes like the PS3 version.
Results
The new code is available here
Below shows CPU and memory utilization during NVIDIA CUDA GPGPU, generic 1 pthread, and generic 4 pthreads tests.
In the CUDA test my ray program used 92% of one CPU and the Xorg X-windows server used 12% of another CPU.
Update (7/2007)
I obtained an evaluation copy of the Intel C++ Compiler 10.0, Professional Edition, for Linux. I was curious to try their SSE auto-vectorization code. With 4 threads it was 21% faster than GCC.
Update (12/2007)
Intel C++ supports OpenMP, a standardized API for shared-memory multiprocessing in C++.
By adding a simple #pragma loops can be split up to automatically run in parallel on multiple cores.
I added a simple change to the per-screen-line rendering loop of the generic ray tracer:
int screenX;
#ifdef USE_OMP
#pragma omp parallel for firstprivate(portPoint)
#endif
for (screenX = 0; screenX < SCREEN_WIDTH; screenX++)
{ ... }
With this change each pixel is rendered by a separate thread, with a maximum of 4 (the number of cores) running simultaneously. This use of threads is an alternative to the explicit pthread threading tested above, where a separate thread is used per line of the screen. In this case OpenMP is simpler than explicit threading, though it yields slightly lower performance.
GCC 4.2 also supports OpenMP, but its performance is much worse than Intel.
Update (1/2009)
I've ported the generic and CUDA ray tracers to Mac OS X running on a MacBook Pro laptop. It has a 2.4GHz Intel Core 2 Duo processor and a NVIDIA GeForce 9600M GT graphics processor. The Performance for 1 and 2 software threads is comparable to my older Linux desktop, and the CUDA is within a factor of 3 of the desktop graphics card
| Threads | Frames Per Second |
| 1 | 8.5 |
| 2 | 17.4 |
| GPU | 16.7 |