УДК 681.327.12.001.362
В работе рассмотрены наиболее распространенные методы иденти- фикации лиц. Основное внимание уделялось временным характеристи- кам работы алгоритмов, а также их качеству идентификации. Цель дан- ной работы состоит в определении наиболее перспективного алгоритма для последующей его реализации в виде аппаратно-программного ком- плекса.
Процесс автоматической идентификации лиц предполагает создание аппаратно-программного средства, способного при минимальном вме- шательстве человека проводит качественную идентификацию, исполь- зуя толькоизображение лица человека. Актуальность этой задачи, а также ее предпочтительность по сравнению с другими средствами иден- тификации личности (например идентификация по отпечаткам пальцев или по сетчатке глаза) заключается в том, что нет необходимости непо- средственного контакта системыи человека. Лицо человека само по себе содержит уникальную информацию для проведения безошибочной идентификации. Основная трудность, с которой пытаются справиться предложенные алгоритмы состоит в том, что задача идентификации человека по лицу принадлежит к классу трудноформализируемых задач, для решения которых и используются современные методы искусствен- ного интеллекта.
В работе [1] рассмотрен подход, основанный на геометрических ха- рактеристиках лица. В этой работе использовалась база данных лиц, состоящая из 188 фотографий (по четыре фотографии для каждого из 47 человек), изображения (фотографии) которых получались при помощи специальной ССD-камеры. Расстояние от объекта до камеры во время съемки не было четко фиксировано, поэтому изменение в масштабе составляло до 30%. Авторы этого метода ставили следующие требования к алгоритму:
Первым ключевым моментом, который определяет качество работы алгоритма в целом, является предобработка или нормирование изобра- жения с целью улучшения яркостно-контрастныххарактеристик. Извлеченные характеристические точки должны быть нормированы для обеспечения инвариантности по отношению к позиции (расположению) лица, масштабу и углу поворота. Другим ключевым моментом является процедура определения набора характеристических точек. Рассматри- ваемый геометрический метод опирается на свойство билатеральной симметрии лица. Используется множество отношений расстояний меж- ду такими характеристическими точками лица как глаза, кончик носа, центр рта. Алгоритм определения характеристических точек базируется на интегральной проекции изображения. Проекционный анализ прово- дится над бинарным изображением, полученным путем применения оператора Лапласа . Применяя вышеуказанный алгоритм были получе- ны характеристические точки расположения глаз, носа, бровей, рта, а также был определен контур лица, на основании чего было выделено 35 геометрических признаков.
Применяя к описанным подобнымобразом лицам классифика- тор Байеса авторы этого метода добились 90%-ного распознавания на базе данных 47 человек.
В работе [2] также предложен геометрический метод идентификации
лиц, основанный на геометрическом расстоянии между ключевыми точками. Схожесть лиц, согласно этому методу, оценивается в несколь- ко этапов, действуя по принципу “от грубого к точному”. Сначала опре- деляется множество ключевых точек для каждого лица, затем отбирает- ся приблизительно kl изображений, близких по геометрическим характе- ристикам к классифицируемому лицу; kl определяется так:
![]() (1)
(1)
где N — количество портретов, содержащихся в базе данных.
После этого выполняется этап нормализации изображения для по- следующего вычисления корреляции между центральными лицевыми частями kl изображений и лицевой частью идентифицируемого изобра- жения. Результатом будет получение k2 изображений из kl отобранных:
![]() (2)
(2)
Ключевые точки определяются автоматически, но для проведения более точной идентификации возможен также ручной отбор точек. В экспериментах, проводимых авторами данного геометрического метода использовалось множество из 37 ключевых точек. Пример полученных геометрических точек представлен на рис.1
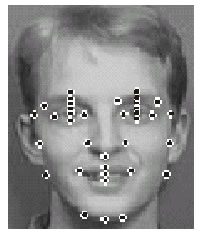
Рис. 1 Пример множества геометрических ключевых точек.
Для задачи идентификации необходимо выполнить этап объедине- ния точек в сегменты, периметры и площади различных фигур — опре- деление репрезентативного набора характеристик. Далее этот набор может быть оптимизирован для достижения более высокого качества идентификации. Сам процесс идентификации заключается в определе- нии “cамого близкого” изображения по отношению к идентифицируе- мому изображению с использованием Евклидовой метрики. Гипотеза, выдвинутая авторами этой работы, следующая — если два изображения содержат практически одинаковую информацию, то они должны содер- жать множество пикселей с близкими значениями интенсивности.
Изображение А можно представить как дискретную поверхность:
![]()
Расстояние от каждого пикселя одного изображения к ближайшим пикселям другого изображения отражает, такназываемое, локальное отличие. Вычисляя множество локальных отличий и аккумулируя их в глобальное значение отличия, формируется окончательная оценка схо- жести изображений. Глобальное значение отличия двух изображений А и С может быть определено по следующей формуле:
 (4)
(4)
![]() (5)
(5)
и W — квадратное окно наблюдения размера (2w+1)x(2w+1) центрированное в точке (i,j) изображения С.
Эксперименты по определения качества распознавания проводились
на базе данных лиц, составленной Olivetti Research Lab. Качество распо-
знавания составило 98,5%.
Использование скрытых марковских моделей для идентификации лиц было выполнено в работе [3]. Скрытые марковские модели (СММ) – это множество статистических моделей, используемых для описания статистических свойств сигналов.
Можно выделить следующие элементы СММ :
N — количество состояний модели . Если S — множество со- стояний, следовательно S = {S1,S2,…,SN}. Состояние модели в момент времени t обозначается qt (qtrS), 1tT, где T — длина последовательности наблюдений (количество фрей- мов).
M — количество различных наблюдаемых символов. Если V — множество всех возможных наблюдаемых символов , тогда V = {v1,v2,…,vM}.
A — вероятностная матрица перехода состояний , т.к. А= {aij},
где aij = P[qt = Sj|qt-1 = Si] 1i , j N , 0 ai,j 1
 (6)
(6)
B — матрица вероятностей наблюдаемых символов, B={bj(k)},
где
![]() (7)
(7)
Оt — наблюдаемый символ в момент времени t
П — распределение начального состояния,
П = {ti}, где
![]() (8)
(8)
Используя сокращенную нотацию, СММ обозначается как триплет:
![]() (9)
(9)
Для фронтального изображения лица наиболее важные регионы (во- лосы, лоб, глаза, нос, рот) следуют сверху вниз, даже если изображение подверглось небольшому вращению. Каждый из этих лицевых регионов соответствует состоянию СММ.
Любое изображение шириной W и высотой H разделяется на пере- крывающиеся блоки высотой L и шириной W. Величина перекрывания последовательных блоков равна P (рис.2).

Рис.2 Извлечение перекрывающихся блоков для распознавания лиц
Количество извлекаемых блоков равно количеству векторов наблюдения T и определяется:
 (10)
(10)
Выбор параметров P и L существенно влияет на процент правильно- го распознавания. Векторы наблюдения состоят из значений пикселей каждого извлекаемого блока. Использование значений пикселей несет в себе два недостатка: значение пикселей не дает помехоустойчивые особенности, т.к. они очень чувствительны к шуму, к вращению изо- бражения, к изменениям в освещенности; большая размерность векто- ров влечет за собой высокую вычислительную стоимость. Для разреше- ния этой проблемы используетсядискретное косинус-преобразование (ДКП) с целью извлечения характеристических точек из каждого блока.
Набор из пяти блоков используется для обучения СММ. Характери- стические коэффициенты, извлекаемые из каждого блока, задействова- ны для формирования векторов наблюдений. Векторы наблюдений, ассоциируемые с каждым состоянием СММ, используются для получе- ния первоначальных оценок матрицы вероятностей символов наблюде- ния. Далее параметры модели переоцениваются для максимума P(O|A). Итерационный процесс продолжается до тех пор, пока не будет достиг- нута сходимость, т.е. разность между текущим значением и значением на предыдущей итерации не будет меньше некоторого порога. После формирования векторов наблюдений вычисляются вероятности векто- ров наблюдений для каждого состояния СММ.
Изображение t классифицируется как лицо k если :
![]() (11)
(11)
Данный метод распознавание лиц тестировался на базе данных лиц Olivetti Research Lab. Система достигла 84% уровня верного распозна- вания лиц.
Довольно перспективная технология распознавания лиц с использо- ванием сверточной нейронной сети (СНС) рассмотрена в работе [4] . СНС использует три основных идеи: локальные рецепторные поля, разделяемые веса, пространственная подвыборка. Эта сеть эффективно может использоваться не только для распознавания лиц, но также и для распознавания символов и речи.
Типичная СНС представлена на рис.3. Эта сеть состоит из набора слоев, каждый из которых содержит одну или более плоскостей.

Рис.3 Сверточная нейронная сеть
Центрированное и нормированное изображение поступает на вход- ной слой. Каждый нейрон в плоскости получает входной сигнал из области, которая находится “по соседству” на плоскости предыдущего слоя. Веса нейронов устанавливаются одинаковыми. Каждая плоскость может рассматриваться как карта особенностей или карта значений. Множествоплоскостей всегда присутствует в каждом слое, поэтому слои называются сверточными. Следовательно, сверточные слои — это такие слои, которые следуют один за другим, при этом используются операторы усреднения и подвыборки (если фактор подвыборки равняет- ся 2 : yij = [x2i,2j + x2i+1,2j + x2i,2j+1 + x2i+1,2j+1]/4 , где yij- выход плоскости подвыборки в точке с координатами i,j и хij — выход в предыдущей плос- кости). Обучается сеть стандартным градиентным методом обучения. В зависимости от выбора стратегии соединений возможна вариация коли- чества весов СНС. Стратегия соединения определяется человеком вручную.
1. Для каждого поступающего изображения из обучающей вы- борки окно фиксированного размера перемещается по всей площади этого изображения, извлекая локальные образцы. Перемещение происходит дискретными шагами по 4 пиксе- ля.
2. Самоорганизующаяся карта обучается на векторах, полученных на предыдущем этапе. Таким образом она квантует 25– мерный вектор в одно из 125 топологических значений .
3. Сканирующее окно, описанное в первом этапе, перемещает- ся по всем изображениям обучающей и тестирующей выбо- рок. Локальные образцы подаются на карту Кохонена, на выходе которой формируются новые обучающаяи тести- рующая выборки. Теперь каждое входное изображение представляется посредством 3 карт. Размер этих карт равен размеру входного изображения,деленного на размер шага .
4. СНС обучается на новой обучающей выборке.
Эксперимент по исследованию характеристик работы системы про- водился с фотографиями лиц (5обучающих фотографий на 5 тести- рующих фотографий одного и того же человека). Всего использовалось 400 фотографий 40 человек. Ошибка распознавания в зависимости от количества классов составила от 1,33% до 5.75%.
Для оценки наиболее оптимального метода необходимо определить параметры, по которым проведем сравнительный анализ. Первый пара- метр — процент правильного распознавания (ППР) : диапазон от 0 до 100%; второй — относительная временная стоимость(ОВС), который делится на категории : высокая, средняя, низкая и отражает временные затраты работы системы; третий — сложность системы (высокая, сред- няя, низкая) и четвертый параметр — возможность обучения системы (да или нет). В таблице 1 приведены и оценены все вышеописанные методы.
Таблица 1. Сравнительный анализ методов
|
№ |
Название |
ППР |
ОВС |
Слож- ность систе- мы |
Обуча- емость |
|
1 |
Геометрический метод №1 |
90% |
- |
сред- няя |
нет |
|
2 |
Геометрический метод №2 |
98% |
высо- кая |
сред- няя |
нет |
|
3 |
Скрытые марковские модели |
84% |
сред- няя |
сред- няя |
да |
|
4 |
Сверточнаянейрон- ная сеть |
98-99% |
сред- няя |
сред- няя |
да |
Таблица показывает, что из всех приведенных систем только неко- торые способны обучаться ипереобучаться, т.е. улучшать качество своей работы. Это является одним из самых важных свойств при созда- нии аппаратно-программного средства идентификации лиц. Однако вторым важным параметром является процент правильного распознава- ния системы. Руководствуясь этими двумя параметрами как критериями выбора наиболее оптимального метода, можно заключить, чтоопти- мальным вариантом являетсясистема построенная с использованием сверточной нейронной сети.
1. Brunelli R. and Poggio T.Face recognition: features versus tem- plates// IEEE Trans. on Pattern Analysis and Machine Intel.- 1993. — Vol.15. — No 10. — P. 1042-1052.
2. StarovoitovV.,SamalD.,G.Votsis,and S.Kollias “Face recognition by geometric features”, Proceedings of 5-th Pattern Recognition and Information Analysis Conference, Minsk, May 1999.
3. Ara V.Nefian , Monson H. Hayes. Hidden Markov models for face recognition // IEEE Trans. on Pattern Analysis and Machine Intel.-1993. — Vol.27. — No 15. — P. 985-997.
4. Lawrence S., Giles C. L., Tsoi A. C. and Back A. D. Face recognition: a convolutional neural network approach// IEEE Trans. on Neural Networks.- Special Issue on Neural Networks and Pattern Recognition.- 1997.- P.97-113.