
Орда Ольга Александровна
| Факультет: | компьютерных наук и технологий (ФКНТ) |
| Кафедра: | компьютерных систем мониторинга (КСМ) |
| Специальность: | «Компьютерный эколого-экономический мониторинг» |
| Тема квалификационной работы магистра: | «Система мониторинга для повышения эффективности управления факультетом» |
| Научный руководитель: | к.т.н., декан факультета КНТ Аноприенко Александр Яковлевич |
Автореферат
В предлагаемой работе анализируются процессы эволюции информационных систем. Под эволюцией будем понимать модификацию информационной системы в соответствии с новыми техническими требованиями [1]. В качестве примера такой эволюции в работе будет рассмотрено расширение информационной системы Донецкого национального технического университета, которое предусматривает добавление подсистемы мониторинга успеваемости. Следует отметить, что процесс эволюции любой системы тесно сопряжен с процессом рефакторинга. Согласно [2] процесс рефакторинга представляет собой изменение внутренней структуры системы, не затрагивающее внешнего поведения, с целью облегчения понимания работы системы, а, кроме того, что более важно в данном контексте, с целью упрощения ее дальнейшей модификации. Поскольку информационные системы гетерогенны, так как включают реляционную и объектно-ориентированную составляющую [3], следует анализировать эволюцию каждого из ее компонентов в отдельности. В частности, в литературе различают рефакторинг объектно-ориентированных систем [2, 4] и рефакторинг баз данных [5]. Следует отметить, что в работе большее внимание будет уделяться рефакторингу баз данных. Причиной для этого служит существующая архитектура информационной системы ДонНТУ (рис. 1). В ней не выделен уровень серверного программного обеспечения, которое бы изолировало клиентское программное обеспечение от непосредственного доступа к базе данных. Поэтому все клиентские модули по мере необходимости взаимодействуют с базой данных для получения и размещения данных. Такой подход к построению архитектуры оказал отрицательное влияние на структуру баз данных, что, в частности, проявилось в отсутствии качественной нормализации данных, а также в их избыточности и дублированию [6].
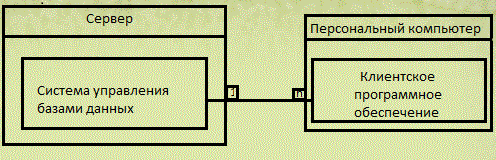
Рисунок 1 – Обобщенная архитектура информационной системы ДонНТУ (диаграмма развертывания, представленная в нотации UML [1, 7])
Следует отметить, что использование простой архитектуры привело к возникновению сильной связности между клиентскими модулями программного обеспечения и структурой базы данных. Речь идет о том, что при разработке многих клиентских модулей, входящих в состав информационной системы, использовались средства быстрой разработки. Это привело к тому, что структура базы данных зачастую расширялась и видоизменялась в соответствии с требованиями конкретного клиентского модуля, без учета какой либо общей стратегии. Это, в свою очередь, ведет к невозможности использования большинства способов рефакторинга, предложенных в [5]. Причина кроется в том, что из-за обилия клиентских модулей, которые непосредственно и различными способами взаимодействуют с базами данных невозможно однозначно разделить внутреннюю структуру и внешнее представление. А в таком случае, как следует из рассмотренного определения, процесс рефакторинга не может быть выполнен. Поэтому, выполняемое исследование будет направлено на выявление тех механизмов, которые бы позволили интегрировать новый клиентский модуль в существующую систему таким образом, чтобы четко разделить границу их взаимодействия. То есть, целью данного исследования является поиск подходов к расширению информационной системы, которые бы позволили обеспечить наименьшую связность нового компонента с уже существующими. Достижение данной цели позволит избежать усложнения ядра информационной системы, в данном случае центральной базы данных, при добавлении к ней новой функциональности. Например, одним из механизмов изоляции могут служить SQL-представления [7]. По сути, это виртуальные таблицы, которые построены на основе реальных таблиц и/или на базе других представлений. Они позволяют, в частности, обеспечивать уровень абстракции между данными, которые необходимы приложению и реальными данными, хранимыми в базе [7] (рис. 2). Представления являются важным механизмом абстракции, который предоставляется большинством СУБД.
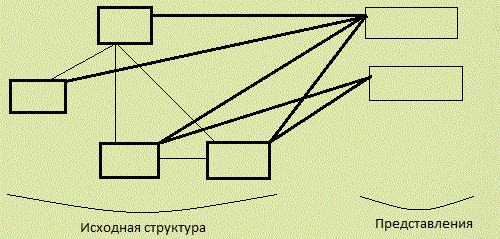
Рисунок 2 – Пример использования представлений для упрощения структуры данных
Использование представлений дает несколько преимуществ, во-первых, в том случае, если внутренняя структура базы измениться, интерфейс, предоставляемых представлениями может оставаться стабильным. Во-вторых, механизм представлений поддерживается СУБД, что позволяет ожидать достаточно высокой производительности при их использовании. В-третьих, если постепенно переводить клиентские модули на использование представлений, то в последующем можно избавиться от непосредственной связи клиентского программного обеспечения с внутренней структурой базы данных. Другим, значительно более сложным вариантом является создание уровня серверного программного обеспечения [3]. Этот уровень может обеспечить необходимый клиентскому программному обеспечению интерфейс доступа к данным. Кроме того, этот уровень может обеспечить ряд полезных функций, как например контроль доступа к данным. Кроме того, наличие серверного уровня позволяет использовать "тонких" клиентов [3] (рис. 3). То есть, использование слоя серверного программного обеспечения позволяет предоставить клиентам Web-интерфейс, что является немаловажным фактором для современных систем.
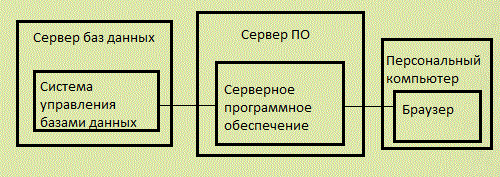
Рисунок 3 – Использование серверного программного обеспечения
Предполагается в дальнейшем детально исследовать взаимодействие двух описанных механизмов. Это, во-первых, даст возможность создать методику, определяющую действия, которые необходимо выполнять для интеграции новых компонент в существующую систему. Во-вторых, это позволит определить подходы к постепенному преобразованию системы так, чтобы она отвечала современным требованиям, которые касаются как внутренней структуры, так и способов взаимодействия с пользователями. Предварительно можно определить, что процесс интеграции модуля в существующую систему будет состоять из следующих шагов. Во-первых, нужно определить какие данные будут использоваться модулем, и выделить эти данные в существующей базе данных. Далее, необходимо определить какие данные будут добавляться в базу интегрируемым модулем. Для уже существующих данных создаются представления, которые позволят получить более качественную структуру, для новых данных добавляются новые таблицы. При этом, следует документировать расширение базы. Кроме того, если объем новых данных достаточно велик, то можно использовать дополнительную базу данных, чтобы избежать неконтролируемого роста уже существующей (рис. 4). Новые данные должны зависеть только от представлений, но не от исходных данных. То есть, уровень представлений должен обеспечивать изоляцию интегрируемой подсистемы на уровне данных.
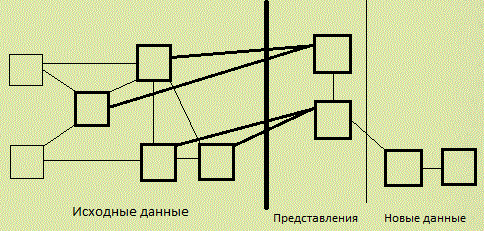
Рисунок 4 – Подготовка к интеграции нового модуля на уровне источника данных
Следующим шагом является разработка серверного программного обеспечения. Для рассматриваемой системы мониторинга успеваемости это программное обеспечение должно обрабатывать запросы пользователей, которые поступают через предоставляемый им сетевой интерфейс (рис. 5).

Pисунок 5 – Структура подсистемы, обеспечивающей взаимодействие посредством Web-интерфейса
(Анимация: объем - 137 КБ; размер - 569х176; количество кадров - 6; задержка между кадрами - 50 мс; задержка между первым и последнимкадрами - 3000 мс; количество циклов повторения - бесконечное.)
В частности, для системы мониторинга большинство запросов будет касаться анализа уже имеющихся данных. В частности, это анализ оценок студента за определенный период или анализ результатов по некоторому предмету. Следовательно, большую часть времени программное обеспечение будет осуществлять запросы на чтение из базы данных, причем эти запросы зачастую будут подразумевать некоторую предварительную обработку данных. Это приводит к необходимости последующего анализа еще одного механизма, получившего качественное развитие в известных СУБД, а именно, механизма хранимых процедур. Этот механизм позволяет выполнять на уровне СУБД предварительную обработку и подготовку данных. Ключевыми преимуществами использования этого механизма являются возможности, во-первых, избежать передачи избыточных данных, во-вторых, обрабатывать данные быстрее. В [3] упоминается важность использования хранимых процедур, например, рассматривается модель информационной системы, где уровень хранимых процедур выделен отдельно, как и уровень серверного программного обеспечения. Вообще именно в подходе к декомпозиции системы, предложенному Нильсоном [3], наибольшее внимание было уделено источнику данных, что в данном контексте, требует внимательного изучения этой модели. Кроме того, Нильсон предлагал свою модель, опираясь на использование СУБД Microsoft SQL Server 2000, которая используется в ДонНТУ [8, 9]. Итак, в квалификационной работе магистра предполагается выполнить исследование, которое касается поиска методики расширения существующих информационных систем, с целью добавления в них новой функциональности. Это исследование будет включать анализ механизмов, которые предоставляются современными СУБД для решения задач интеграции, а также анализ современных подходов к построению серверного программного обеспечения. Целью является создание методики, которая позволит расширять информационную систему таким образом, чтобы, как минимум, не ухудшать ее текущую внутреннюю структуру. Также методика должна позволить определить приоритетные направления развития системы. Апробация предлагаемой методики будет выполнена путем интеграции подсистемы мониторинга успеваемости.
Апробация предлагаемой методики будет выполнена путем интеграции подсистемы мониторинга успеваемости. Интеграция будет выполняться следующим образом: на первом этапе будет разработана независимая база данных, содержащая набор тестовых данных. Эта база данных будет использоваться в отладочной версии системы. Однако, она имеет и другое важное предназначение – она позволит формализовать те интерфейсы, которые необходимы для подключения новой подсистемы к уже существующей системе. То есть, эта тестовая база данных позволит точно определить требования со стороны подсистемы к основной базе. Для проектирования базы данных будет использоваться широко известный стандарт IDEF1X [6]. Вторым этапом является создание программного обеспечения. Как было отмечено ранее, это программное обеспечение представляет собой реализацию Web-сервиса. Следует отметить, что ряд проблем, например, объектно-реляционное преобразование данных на границе базы данных и программного обеспечения будет выполнено с помощью общеизвестных средств платформы Java (в частности, для решения данной проблемы будет использоваться технология Hibernate). Первоначальная отладка проекта будет выполняться независимо от базы данных информационной системы ДонНТУ. По завершении отладки будет выполнено замещение тестовой базы данных одним из механизмов доступа к основной базе, например, представлениями. После этого будет выполнено завершающее тестирование интегрируемой подсистемы. Описанный процесс разработки новых компонент информационной системы является частью выполняемого в квалификационной работе магистра исследования.
Литература
1. Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений / Буч. Г, Максимчук Р., Энгл М., Янг Б., Коналлен Д., Хьюстон К. – М.: ООО "И.Д. Вильямс", 2008. – 720 с.
2. Фаулер М. Рефакторинг: улучшение существующего кода / Фаулер М. – СПб.: Символ-Плюс, 2007. – 432 с.
3. Фаулер М. Архитектура корпоративных программных приложений / Фаулер М. – М.: Издательский дом "Вильямс", 2006. – 544 с.
4. Кериевски Д. Рефакторинг с использованием шаблонов / Кериевски Д. – М.: ООО "И.Д. Вильямс", 2006 – 400 с.
5. Эмблер С. Рефакторинг баз данных: эволюционное проектирование / Эмблер С., Садаладж П. – М.: "И.Д. Вильямс", 2007. – 672 с.
6. Кренке Д. Теория и практика построения баз данных 9-е изд. / Кренке Д. – СПб: Питер, 2005 – 859 с.
7. Буч Г. Язык UML. Руководство пользователя 2-е изд. / Буч Г., Рамбо Д., Якобсон И. – М.: ДМК Пресс, 2007. – 496 с.
8. Вьейра Р. SQL Server 2000. Программирование в 2 ч. Том 1. / Вьейра Р. – М.: БИНОМ. Лаборатория знаний, 2004. – 735 с.
9. Вьейра Р. SQL Server 2000. Программирование в 2 ч. Том 2. / Вьейра Р. – М.: БИНОМ. Лаборатория знаний, 2004. – 735 с.
10. Василенко А.Ю. Разработка веб-сервиса мониторинга успеваемости студентов /Василенко А.Ю. Автореферат. http://masters.donntu.ru/2009/fvti/vasilenko/diss/index.htm
Примечание
При написании данного автореферата квалификационная работа магистра еще не завершена. Дата окончательного завершения работы: 1 декабря 2010 г. Полный текст работы и материалы по теме работы могут быть получены у автора или его научного руководителя после указанной даты.