Подход к построению мульти-агентной системы для проведения содержательного поиска во множестве информационных источников
1. Введение
Во многих областях человеческой деятельности на данный момент накоплены
большие объемы данных. Рост информационных потоков, связанных с деловой
активностью человека, требует внедрения автоматизированных методов и систем
хранения и обработки данных. В связи с этим, новые и накопленные ранее
материалы переводятся в электронный формат в разного рода банки и хранилища
данных. По историческим, техническим и другим причинам тематически связанные
данные сохраняются в различных форматах под управлением различных СУБД и
других систем хранения и обработки данных.
Очевидно, что для изучения и анализа информации требуется открытый доступ
к локальным и удаленным информационным источникам. Эта задача успешно решается
с развитием интернет/интранет технологий доступа к хранилищам данных [1]. С
другой стороны встает проблема интеграции данных. Различные коллекции, базы
персоналий и публикаций по единой тематике, даже расположенные на одном
физическом сервере, зачастую имеют различные логические входы и не
предоставляют возможности сквозного связывания данных из разных источников.
Необходимость учета всей имеющейся информации по определенному вопросу требует
от поисковых механизмов обеспечения прозрачных для пользователей средств
доступа к распределенной информации.
Одним из решений задачи интеграции является реструктуризация имеющихся
данных. Это может требовать приведения содержательно сопоставимых данных к
единообразному представлению или расширение структур данных путем добавления
уникальных идентификаторов, позволяющих сопоставлять данные из различных
источников. Так или иначе, эта задача является весьма трудоемкой, особенно для
удаленных друг от друга хранилищ, так как требует и технического, и
организационного взаимодействия владельцев баз данных. Кроме того, после
реорганизации данных потребуется качественная модификация средств доступа к
информации с учетом новых структур данных.
Другими подходами являются использование существующих систем поддержки
хранилищ данных (data warehouse) [подробнее 2, 3] или систем-посредников
(mediator system) [например 4, 5] для обеспечения интеграции данных. Подобные
системы обеспечивают интеграцию информационных источников, но работают на
уровне метапоисковых систем, передающих запрос множеству источников данных и
затем аккумулирующих и фильтрующих результаты поиска. Другими словами не
учитывается семантическая связанность данных в рамках предметной области, что
затрудняет выполнение запросов на поиск связанной информации (например, запрос
«найти персональную информацию об авторах статей за прошлый год» к базам
данных публикаций и персоналий). Эта задача ложится на разработчиков
дополнительного программного обеспечения, учитывающего логику и модель
предметной области, что в целом делает систему менее эффективной и требует
дополнительных затрат.
Поэтому предлагается модель поисковой системы, поддерживающей возможность
содержательного поиска связанной информации в рамках заданной предметной
области. Система ориентирована на работу с множеством разнородных
информационных источников и позволяет интегрировать их, осуществляя сквозной
поиск связанной информации. Система основана на мульти-агентном подходе и
позволяет не прекращать обработку запросов при выполнении модификаций набора
и структур используемых баз данных.
2. Концепция поисковой системы
Для обеспечения содержательного поиска в систему включена база знаний,
описывающая используемую предметную область и определяющая специализацию
поисковой системы. В системе так же содержится информация о структурах
используемых баз данных и связях данных с понятиями предметной области.
Поисковые механизмы основаны на применении мульти-агентного подхода, что
обеспечивает одновременную работу с множеством запросов и информационных
источников.
2.1. База знаний
База знаний содержит описание предметной области и представляет
концептуальный уровень информации в системе, необходимый для интеграции
источников данных и организации содержательного поиска в них.
Для описания различных понятий предметной области и связей между ними в
базу знаний включена онтология. Описание предметной области опирается на
словарь-тезаурус, что в совокупности позволяет проводить разбор и анализ
естественно-языковых запросов.
Онтология в системе представлена неоднородной семантической или фреймовой
сетью, что позволяет описывать разнородные понятия и связи между ними.
Взаимосвязь тезауруса и онтологии осуществляется с помощью ссылок от каждого
понятия в словаре на некоторый фрагмент онтологии. Фрагмент может состоять из
набора понятий (вершины сети) и отношений (связи), а так же иметь ограничения,
частично определяющие используемые элементы онтологии (например, заданные
условия на слоты фрейма, описывающего используемое понятие). Такая организация
связи тезауруса с онтологией позволяет вводить в словарь составные термины,
состоящие из совокупности простейших элементов онтологии.
В итоге можно считать, что в базе знаний содержится множество фрагментов
онтологии с заданными на них ограничениями.
Онтология, описывающая модель предметной области (МПО) и являющаяся основой
базы знаний, может быть построена в ручном режиме с помощью специального
редактора базы знаний или в автоматизированном режиме на основе схем данных
доступных информационных хранилищ. При этом в первом случае сразу строится
общая онтология для всех источников данных, а во втором случае построение
происходит за два этапа. В начале для каждой доступной базы данных строится
своя локальная онтология, описывающая соответствующую МПО, а потом происходит
процесс интеграции в одну более общую онтологию. Построенная таким образом
онтология (и МПО на ее основе) является наиболее полной и точной с точки
зрения источников данных, так как для каждого ее элемента найдутся
соответствующие данные хотя бы в одном из доступных источников. С другой
стороны все имеющиеся данные будут представлены в модели, а, следовательно,
доступны для поиска.
2.2. Связь знаний и данных
Связь онтологии со структурой имеющихся данных необходима для описания
структур доступных баз данных в терминах используемой предметной области.
В системе в унифицированном виде хранится информация о структурах всех
доступных для поиска баз данных. Это позволяет построить соответствие между
хранимой информацией и понятиями используемой предметной области. Схема данных
информационного хранилища представляется как сеть понятий и связей с
ограничениями, соответствующими ограничениям на атрибуты конкретных типов
хранимых данных (на элементы реляционных таблиц или члены структур данных в
объектных базах данных). Кроме того, выделяется связь специального вида для
сопоставления одинаковых, с точки зрения предметной области, данных,
находящихся в различных информационных источниках. Такую связь будем называть
склейкой или G-связью.
Большинство существующих СУБД предоставляют информацию о структурах баз
данных, поэтому сеть, представляющая структуры данных для всех доступных для
поиска источников, может быть построена автоматически. После этого можно
сопоставить понятия и связи из базы знаний элементам структуры каждой базы
данных. Сопоставление происходит на уровне атрибутов онтологических понятий с
одной стороны и членов классов, описывающих структуру базы данных, с другой.
Ограничения, используемые в понятиях базы знаний, накладываются на
соответствующие структуры баз данных. Причем, если ограничения предметной
области в совокупности с собственными ограничениями базы данных вызвали
противоречие, то либо база данных не соответствует используемой модели
предметной области, либо выбраны не подходящие элементы для сопоставления. В
общем случае, после процедуры сопоставления, часть элементов онтологии
связывается с частью элементов структуры конкретной базы данных. Если для
какого-то термина базы знаний не нашлось соответствия в структуре данных, то
можно считать, что соответствующая информация отсутствует.
Связанность понятий базы знаний посредством семантических отношений
отображается на схемы данных. Это дает возможность выбирать цепочки данных,
связанных с точки зрения предметной области.
Интеграция различных баз данных возможна, если в базе знаний существует
понятие, соответствующее элементам структур различных источников данных. Такие
элементы связываются в общей схеме данных выделенной G-связью, что
используется для проведения сквозного поиска во множестве баз данных.
Переход от одной базы данных к другой при поиске может происходить если
определена G-связь, выполняющая роль функции преобразования данных.
Предположим, что элементы T1 и T2 из схем баз данных D1 и D2 соответственно
связаны с одним и тем же понятием базы знаний. В такой ситуации, в общем
случае, для структур T1 и T2 существуют набор однозначно сопоставимых
атрибутов, а также атрибуты, принадлежащие одной структуре, но не входящие в
другую. Склейка структур T1 и T2 происходит следующим образом. Каждому
элементу t1 типа T1 сопоставляется множество элементов типа T2 для которых
значения общих для T1 и T2 атрибутов совпадают со значениями для t1, а
значения остальных атрибутов достраивается с учетом существующих элементов
типа T2 и ограничений на них. При этом важно учитывать правила сопоставления
значений атрибутов данных из разных источников, так как одна и та же
информация может быть представлена в разном виде (на разных языках, в разных
единицах измерения и т.п.). Для этого при сравнении значений используются
функции сопоставления значений атрибутов, представленные в виде арифметических
выражений или таблиц.
Процессы построения структуры базы данных, связывания ее с базой знаний и
интеграции с другими имеющимися источниками данных выполняются для любой новой
или модифицируемой базы данных. На период модификации база данных и все ее
связи блокируются, что позволяет корректно продолжать работу поисковой системы
на ограниченном множестве данных.
2.3. Процесс поиска связанной информации
Поиск связанной информации по запросу пользователя представляет собой
выборку данных, удовлетворяющих запросу. В поисковом запросе указывается тип
искомой информации и задаются ограничения, которым должны удовлетворять
найденные данные. Используя связи между элементами онтологии можно построить
цепочки связей между данными искомого типа и типами данных, используемыми в
ограничениях из поискового запроса. Учитывая построенные цепочки и связи
конкретных данных в информационных хранилищах, все множество данных можно
разбить на группы связанных между собой элементов данных. Если элементы такой
группы удовлетворяют всем ограничением запроса, то входящая в группу
информация искомого типа есть один из результатов запроса. Полный результат
запроса получается при проверке всех возможных наборов связанных данных,
содержащих данные искомого типа.
Процесс поиска и извлечения связанной информации из множества источников
данных происходит по следующей схеме. Запрос, изначально заданный в терминах
предметной области, отображается на общую схему данных. Ограничения могут быть
заданы в виде поискового шаблона определенного типа и/или логическими
выражениями над значениями атрибутов понятий предметной области.
После предварительного преобразования запрос представляет собой часть общей
схемы данных с дополнительными ограничениями и помеченными искомыми вершинами.
Между вершинами, связанными ограничениями, и искомыми вершинами с учетом
имеющихся связей строятся всевозможные пути (цепочки вершин и связей схемы
данных) по которым будет происходить выборка связанной информации.
Возможны две стратегии построения цепочек связанных данных. В одном случае
цепочки связанных данных строятся от искомой информации до данных входящих в
заданные ограничения. В другом случае исходные данные для поиска могут быть
выбраны с учетом заданных в запросе шаблонов и ограничений. Обе стратегии поиска
могут использоваться одновременно. После этого вдоль всех построенных путей
выполняется выборка данных с сохранением информации о связи отдельных
элементов данных. Последовательное построение всех цепочек связанных элементов
данных, с учетом имеющихся ограничений, приведет к образованию сети связанных
данных, удовлетворяющих всем заданным условиям поиска.
Полученная сеть данных является результатом поиска и может использоваться
для расширения или уточнения первоначального запроса. Визуальное представление
этой сети позволяет наглядно представить результаты поиска и обеспечить
навигацию по ним.
3. Общая архитектура и схема функционирования поисковой системы
Для обеспечения описанной выше схемы функционирования система поиска
включает в себя следующие элементы. Это база знаний, модуль хранения и
управления объединенной схемой данных и связями с базой знаний, ядро
поддержки жизненного цикла агентов, лексический процессор, транслятор для
преобразования запроса в термины схемы данных, а также интерфейс пользователя
для задания запроса и просмотра результатов и интерфейсы для настройки
системы.
База знаний системы содержит взаимосвязанные онтологию и тезаурус,
описывающие предметную область. На основе понятий и связей, хранящихся в базе
знаний, происходит интеграция информационных источников и построение цепочек
связанных данных.
Объединенная схема данных всех доступных информационных источников
обслуживается специальным модулем, составляющим часть ядра системы. Здесь
также хранится информация о связях модели данных с моделью предметной области
из базы знаний, методы преобразования данных между различными источниками и
методы доступа к различным источникам данных.
Ядро поддержки жизненного цикла агентов выполняет стандартные функции
порождения, мониторинга и разрушения агентов, а также управляет процессом
обмена сообщениями между агентами.
Лексический процессор необходим для преобразования запроса из
первоначального вида (возможно естественно-языковое представление) к элементам
онтологии с заданными дополнительными ограничениями.
После преобразования лексическим процессором запрос переводится в термины
схемы данных с помощью специального транслятора. Транслятор учитывает
существующие связи между базой знаний и схемой данных и выбирает часть схемы
данных соответствующую запросу, помечая искомые типы данных.
Интерфейс пользователя для задания запроса и просмотра результатов
предоставляет возможность формулировать запрос к системе (например, на
естественном языке) и просматривать результаты поиска. Кроме того,
пользователем может быть задана дополнительная информация, например область
поиска данных. Модуль визуализации, являющийся частью интерфейса пользователя,
позволяет просматривать визуальное представление результата поиска в виде сети
связанных данных, что дает возможность осуществлять навигацию по имеющимся
данным и облегчает взаимодействие с системой.
Интерфейсы настройки требуются для управления системой и мониторинга
текущего состояния. В системе присутствуют специальные редакторы и средства
для построения и модификации базы знаний, определения и управления связями
базы знаний с объединенной схемой данных, а также для описания методов
преобразования данных между различными источниками для осуществления сквозного
поиска. При необходимости изменить структуру используемой базы данных или
методы доступа к ней предусмотрена возможность блокирования соответствующей
части объединенной схемы данных, что позволяет системе корректно продолжать
работу на ограниченном множестве данных.
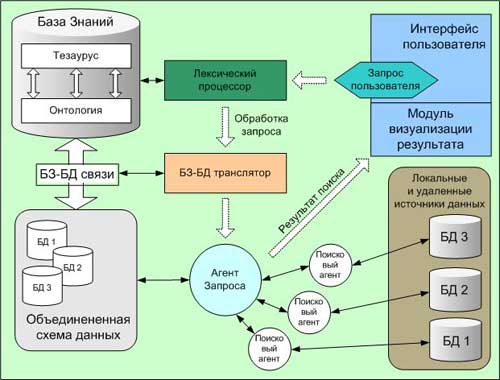 Рис. 1. Схема обработки запроса пользователя.
Рис. 1. Схема обработки запроса пользователя.
Функционирование поисковой системы при обработке запроса пользователя
происходит по следующей схеме (Рис. 1). Запрос пользователя, преобразованный
лексическим процессором в термины предметной области, отображается на общую
схему данных, после чего порождается агент запроса, управляющий процессом
сбора информации. Для доступа к информации в конкретных базах данных агент
запроса создает специализированных поисковых агентов. На основании найденной
информации и знаний, содержащихся в онтологии, строится ассоциативная сеть,
являющаяся результатом запроса. Используя специальный интерфейс навигации по
результатам поиска, пользователь может осуществлять просмотр и навигацию по
визуальному представлению этой сети.
После предварительной обработки лексическим процессором запрос пользователя
представляется как подмножество элементов онтологии, некоторые элементы такого
подмножества помечаются как искомые. На атрибуты понятий входящих в запрос
могут быть наложены ограничения в виде арифметических или логических
выражений, что дает возможность задания более гибких поисковых шаблонов.
Для уточнения смысла запроса могут быть заданы связи, то есть цепочки
понятий и семантических связей в сети, представляющей онтологию, объединяющие
заданные (на значения которых заданы ограничения) и искомые понятия. Если
такие связи нельзя извлечь из первоначального вида запроса, то между заданными
и искомыми понятиями в соответствии с базой знаний строятся все возможные
цепочки связей, которые используются для последующей организации поиска.
Получаем, что запрос является фрагментом онтологии с заданными значениями и
ограничениями для атрибутов части входящих в него понятий, где некоторые
понятия помечены как искомые.
Используя связи базы знаний со структурами баз данных, запрос, как фрагмент
онтологии с ограничениями, переводится во фрагмент общей структуры всех
доступных баз данных с ограничениями на входящие в него элементы. При этом
такое преобразование считается успешным, если в полученном фрагменте структур
данных существует хотя бы один элемент, помеченный как искомый. В противном
случае, в предположении, что запрос понят системой корректно, очевидно, что в
системе отсутствует искомая информация.
В процессе поиска рассматриваются все допустимые с точки зрения запроса
пути от вершин для которых заданы ограничения до искомых вершин во фрагменте
общей схемы данных, построенном по запросу. Сначала ищется информация,
частично определенная в запросе с помочью образцов и ограничений. Далее
рассматриваются следующий элемент схемы данных и связь с ним в рамках
выбранного пути до искомой вершины фрагмента сети, представляющего запрос. Для
каждого такого перехода по звеньям пути порождается поисковый агент,
настроенный на работу с базой данных, содержащей информацию, соответствующую
новой вершине. Эта информация выбирается агентом в соответствии с информацией
найденной для исходной вершины. Порождение поисковых агентов и выборка
информации происходит до тех пор, пока не будет достигнута вершина, помеченная
в запросе как искомая, либо результат очередной выборки данных не окажется
пустым.
Переход от одной базы данных к другой, при поиске вдоль пути до искомой
вершины, происходит по схеме описанной ранее. В соответствии с определенными
заранее G-связью и функциями сопоставления значений атрибутов, данные из одной
базы данных преобразуются в формат сопоставимый с данными из другой базы
данных. После этого процесс поиска продолжается в новой базе данных.
Поиск информации по каждому пути от каждой заданной вершины запроса до
каждой искомой производится параллельно. Множество заданных в запросе образцов
и ограничений рассматривается как конъюнкция условий поиска, поэтому если
пути от различных заданных вершин пересекаются, то результаты поиска также
пересекаются. Аналогично этому результаты должны удовлетворять всем
ограничениям, заданным в запросе, поэтому все результаты поиска, не
удовлетворяющие какому-либо ограничению, отбрасываются.
Сбором результатов управляет поисковый агент. В процессе поиска строится
сеть связанных между собой результатов сходная со структурой самого запроса.
Используя специальный интерфейс визуализации результатов поиска, пользователь
может осуществлять навигацию по визуальному представлению этой сети. Подобная
визуализация упрощает процедуру выбора наиболее важной информации
пользователем за счет явного визуального представления связей между найденными
данными. Кроме того, упрощается процедура задания уточняющих или дополняющих
поисковых запросов.
4. Заключение
В статье представлен подход к построению мульти-агентной системы
содержательного поиска информации в рамках заданной предметной области.
Интеграция источников данных осуществляется на основе описания модели
предметной области, что позволяет проводить сквозной поиск и выборку
информации, связанной с точки зрения предметной области. Система построена на
основе мульти-агентного подхода и ориентирована на одновременную работу с
множеством запросов и разнородных информационных источников.
На основе предложенного подхода ведется разработка и реализация системы
содержательного поиска в реляционных базах данных.
Дальнейшее развитие системы направлено на разработку лексического
процессора для обработки естественно-языковых запросов.
Другим направлением развития системы является использования
недоопределенных типов данных и методов работы с ними [6, 7] для корректной
обработки неполных или отсутствующих данных в процессе поиска.
Литература
1. Фролов А.В., Фролов Г.В. Базы данных в Интернете: практическое руководство по созданию Web-приложений с базами данных. - М.:Издательско-торговый дом «Русская редакция», 2000.
2. The Data Warehousing Information Center. http://www.dwinfocenter.org/
3. Data Warehousing and OLAP. A Research-Oriented Bibliography (in progress).
http://www.cs.toronto.edu/~mendel/dwbib.html
4. Larry M. Stephens, Michael N. Huhns. Database Connectivity Using an Agent-Based Mediator System.
http://www-cdr.stanford.edu/~petrie/jat/CoopIS99-paper.pdf
5. Amarnath Gupta, Bertram Ludascher, Maryann E. Martone. An Extensible Model-Based Mediator System with Domain Maps.
http://www.nbirn.net/Publications/Papers/ extensible_model_based_mediatior_sic_demo.pdf
6. Нариньяни А.С. Недоопределенность в системах представления и обработки знаний // Изв. АН СССР. Техн. Кибернетика. - 1986. - № 5.
7. Телерман В.В., Ушаков Д.М. Недоопределенные модели: формализация подхода и перспективы развития // Проблемы представления и обработки не полностью определенных знаний. - Сб. РосНИИ ИИ.- М.- Новосибирск, 1996.
|