Исходная статья размещена по адресу:http://www.docstoc.com/docs/3944884/Causes-of-Failure-in-Information-Technology-Telecommunications-/
Традиционная техника и модели, используемые для определения показателей надёжности и отказов телекоммуникационных сетей, основаны на классических моделях отказов, таких как прогнозирование Среднего времени между отказами и Среднего времени между перерывами в обслуживании. Сетевые отказы происходят по многим различным причинам и во многих различных формах. Данные классические модели только лишь предполагают, что отказы вызваны аппаратным компонентом сети. В связи с широким использованием Интернет-технологий необходимо исследовать другие факторы, вызывающие отказы в телекоммуникационных сетях или способствующие им. Были установлены и определены две дополнительные модели отказов, помимо уже существующих и опубликованных моделей отказов отказ по причине Атаки системы с целью нарушения нормального обслуживания пользователей и отказ вследствие Катастрофических событий. Наряду с этим была установлена и определена начальная схема обобщённой модели прогнозирования, основанная на Теории динамической системы.
Введение
В течение свыше тридцати лет Спецификация Министерства обороны США MIL-HDBK-217F является стандартной мерой для оценки надёжности, свойственной электронному оборудованию и системам. Она основана на анализе среднего времени, в часах, необходимого для отказа электронных компонентов, называемого Среднее время между отказами (СВМО). Было использовано несколько подобных стандартов, таких как Bellcore TR-322, а также множество модификаций и производных, чтобы предсказать поведение телекоммуникационного оборудования, находящегося в настоящий момент в производстве. Хотя процедура определения СВМО хорошо отрегулирована, применение данного прогнозирования надёжности в модели телекоммуникационных сетей «часто неправильно понимается и неправильно используется». Исследование показало, что чрезмерно оптимистическое прогнозирование отказов происходит в результате неправильного понимания и неправильного применения оценки СВМО.
Несмотря на неправильное понимание и неправильное употребление данных прогнозов, телекоммуникационная промышленность все ещё значительно сфокусирована на их использовании. Изучение технической документации у ведущих изготовителей телекоммуникационного оборудования (Cisco и Juniper Networks) показывает, что имеется обширная документация по прогнозированию отказов, основанном на стандартах СВМО и Среднего времени между перерывами в обслуживании (СВМПО), но мало сказано о других причинах сетевых отказов. Такой коллективный взгляд на данную проблему наблюдается во всей телекоммуникационной промышленности, где можно найти множество информации относительно использования прогнозирования СВМО и мало информации относительно других категорий сетевых отказов.
Киас (2001) выделил пять категорий ошибок, которые могут привести к общему системному отказу в системах обработки данных и которые выходят за рамки прогнозирования отказов СВМО. К ним относятся:
1. Ошибка оператора
2. Проблемы массовой памяти
3. Проблемы аппаратного обеспечения компьютера
4. Проблемы программного обеспечения
5. Сетевые проблемы
Данное исследование рассматривает пять категорий, предложенных Kyas (2001) с целью определения того, являются ли необходимыми дополнительные категорий или есть ли возможность описать общую модель прогнозирования отказов.
Категории Сетевых Отказов
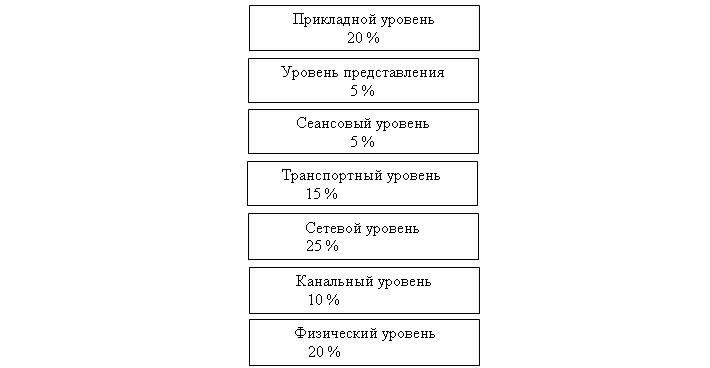
Категория 1: Проблемы аппаратного обеспечения
Рисунок 1. Частота ошибок локальной сети на уровнях модели взаимодействия открытых систем
Дополнительные отказы, не категоризированные Киасом (2001)
Хотя пять категорий Киаса (2001) объясняют большое количество сетевых отказов, следующие две дополнительные категории также заслуживают рассмотрения и обсуждения:
1. Отказы по причине Атаки системы с целью нарушения нормального обслуживания пользователей (черви, вирусы, троянские кони и вредоносные программы);
2. Отказы вследствие стихийных бедствий, таких как пожар, наводнение, землетрясения, простои и т.п.
Категория 6: Атака системы с целью нарушения нормального обслуживания пользователей.
Атаки системы с целью нарушения нормального обслуживания пользователей являются главным источником сетевых отказов начиная с 2000 года. В настоящее время они происходят несколько раз в год, приводя к нарушению сервисного обслуживания по всему миру. Частота данных сетевых отказов возрастает в тревожащем темпе. Только частные, строго контролируемые сети, не имеющие доступа к Интернету, невосприимчивы к такой форме атаки, используя воздушные зазоры в сети. Воздушные зазоры это физическая брешь без возможности соединения, в которой данные вручную переносятся между узлами. Такой подход не является практичным для преимущественного большинства сетей, полагающихся на Интернет-связь.
Примером воздействия Атак системы с целью нарушения нормального обслуживания пользователей служат вирус Code Red/Кодовый красный вирус и более поздняя вариация, червь Slammer, нарушившие работу миллионов компьютеров, запустив хорошо слаженную, распространённую Атаку системы с целью нарушения нормального обслуживания пользователей. Эти атаки привели к существенным потерям доходов корпораций по всему миру. Увеличение частоты осуществления или угрозы Атаки и воздействие данного типа сетевых отказов на нарушение работы сети (и доходы корпораций) значительны, и поэтому Категория Атаки системы с целью нарушения нормального обслуживания пользователей должна быть включена в любую действующую модель анализа отказов корпоративной сети, подключённой к Интернету.
Возможно даже более хитрый вредоносный код будет запущен, чтобы нанести серьёзный ущерб во всем мире. Исследователи недавно постулировали, как вирус, продублировавший вирус Warhol, мог бы разрушить весь Интернет в течение пятнадцати минут. Например, Slammer остановил Интернет-обслуживание в Индии, вывел из строя миллион машин в Корее, вывел из строя банкоматы в крупной банковской компании «Бэнк ов Америка», нарушило работу университетов и главного Канадского банка в течение нескольких дней в 2003 году.
Такие черви как Code Red и Slammer, вероятно, созданы и запущены индивидуумом или небольшим числом индивидуумов. Существует даже более опасная угроза, если вредоносный код станет частью атаки в информационной войне. Имеется достаточного документальных подтверждений того, что такие страны как Китай имеют активную программу развития для проведения компьютерной войны. Такая форма атаки может нанести ущерб обществу, основанному на информационных технологиях (не только одна зараженная сеть). Угрозы весьма реальны, и будучи запущенной, вредоносный код вызывает сбои в системе, пока не будет уничтожен.
Сложно спрогонозировать процент сетевых отказов, вызванных этим видом ошибки, поскольку это явление наблюдается с недавнего времени и происходит хаотично. Однако потенциальное воздействие этого отказа огромно и широко распространено, и не должно быть недооценено.
Категория 7: Сценарии бедствия.
Заключительная категория отказов, которая рассматривается в данной работе, это категория сценариев бедствия, происходящих вследствие различных обстоятельств, многие из которых связаны с окружающей средой, а некоторые являются синтетическими/искусственными. К экологическим катастрофам относятся наводнения, землетрясения, ураганы, длительные отключения электричества, простои, торнадо и пожары.
Синтетические/искусственные бедствия могут включать воровство, вандализм, поджог, войну и террористические акты. В каждом из этих сценариев бедствия можно перечислить ещё много причин. В некоторых случаях наблюдается региональная распространённость, что может быть полезным в предсказании такого случая. Однако во многих других случаях никакой предыдущий опыт или средства прогнозирования не приносят пользы. Планирование бедствия только недавно стало высоким ИТ приоритетом, поскольку коллективное мышление мира сосредоточилось на борьбе с угрозой широко распространённого терроризма.
Развитие всесторонней методологии анализа отказов
Были представлены несколько категорий, определяющих возможную причину и типы отказов телекоммуникационных сетей. В некоторых случаях оценка вероятности и природы отказа предсказуемы, а во многих других любая оценка была бы только догадкой и, таким образом, была бы неточна. Возникает вопрос и, соответственно, проблема, что делать дальше.
Очевидно, можно оценить каждую из этих семи категорий и осуществить количественные и гипотетические прогнозы. Этому можно уделить первостепенное внимание и использовать как входные данные при оценке степени риска для телекоммуникационной инфраструктуры. Этот подход может обеспечить методологию, в соответствии с которой корпорация может оценить и ответить на широкий диапазон отказов в сети. Однако можно использовать также альтернативный и, возможно, менее гипотетический подход – Теорию динамических систем.
Теория динамических систем, впервые предложенная Томом, описывает катастрофы как раздвоения различных видов равновесия или фиксированных точек притяжения. Она используется для характеристики большого количества естественных и синтетических явлений, начиная от популяций насемкомых и заканчивая опрокидыванием кораблей в море. Определенные типы отказов в телекоммуникационных системах, очевидно, могут быть описаны с помощью этой теории. Такие сетевые отказы как колебание маршрута являются наиболее подходящими объектами для описания с помощью данного подхода с целью моделирования отказа.
Остаются открытыми вопрос и проблема применения Теории динамических систем ко всем различным категориям сетевых отказов и сравнения результатов с существующими моделями, использующими в качестве предсказателей СВМО и СВМПО.
Заключение
Данная работа представляет семь категорий возможных отказов в телекоммуникационных инфраструктурах, предлагающих намного более широкую перспективу, чем общие промышленные методы анализа СВМО. Кроме того, представлена Теория динамических систем как заслуживающий на внимание подход для описания всех категорий отказов. Данное и дальнейшее исследование будет использовать инструменты, предоставленные Теорией динамических систем для определения максимального количества категорий отказов, которые можно рассматривать одновременно.