Осипов Глеб Александрович
Факультет компьютерных информационных технологий и автоматики
Кафедра электронной техники
Специальность:
Научные, аналитические и экологические приборы
и системы
Тема выпускной работы:
Методы и средства определения фракционного состава дымного
пороха
Научный
руководитель: Чичикало Нина
Ивановна
Материалы по теме выпускной
работы:
Индивидуальный раздел
Эволюция графических процессоров
План:
1. Прошлое и первые шаги развития процессоров GPU.
2. Настоящее и современные сферы использования видеопроцессоров.
3. Будущее и тенденции развития графических процессоров.
"GPU уже достигли той точки
развития, когда многие приложения
реального мира могут с легкостью
выполняться на них, причем быстрее,
чем на многоядерных системах. Будущие
вычислительные архитектуры станут
гибридными системами с графическими
процессорами, состоящими из
параллельных ядер и работающими в
связке с многоядерными CPU".
Профессор
Джек Донгарра (Jack Dongarra)
Директор Innovative Computing Laboratory
Университет штата Теннеси
Введение
Мой индивидуальный раздел посвящен графическим процессорам,
их поколениям и сферам применения. Я выбрал эту тему потому что во
первых занимаюсь и исследую эту область с 2007 года. Во вторых из-за
того, что в настоящее время очень во многих сферах для моделирования и
вычислений используют суперкомпьютеры в состав которых входят, по
большей части, графические процессоры. Они превышают по скорости и
мощности обработки информации центральные процессоры в несколько раз.
Во первых нужно
сказать, что собой представляет графический
процессор. Спросив любого пользователя компьютера можно получить ответ,
примерно
такой: “Графический процессор? Ааа
вспомнил. Это процессор видеокарты”. Но никаких
других подробностей “рядовой” пользователь об ГПУ не
сможет нам рассказать. Вот что выдает
Википедия на
данный запрос:
Графический процессор (англ. graphics processing unit, GPU) —
отдельное
устройство персонального компьютера или игровой приставки, выполняющее
графический рендеринг. Современные графические процессоры очень
эффективно
обрабатывают и отображают компьютерную графику, благодаря
специализированной
конвейерной архитектуре они намного эффективнее в обработке графической
информации, чем типичный центральный процессор. Графический процессор в
современных видеоадаптерах применяется в качестве ускорителя трёхмерной
графики.
Побродив по интернету, можно наткнуться и на такое толкование ГПУ:
Графическое процессорное устройство
(англ. Graphics Processing Unit, GPU) – программируемое
вычислительное
устройство, изначально предназначенное для обработки графической
информации.
Оно занимается расчетами выводимого изображения, освобождая от этой
обязанности
центральный процессор (англ. Central Processing Unit, CPU), а также
производит
расчеты для обработки команд трехмерной графики (геометрическая
трансформация,
моделирование освещения). Итак ГПУ является часть видеокарты, которая в
свою очередь представляет собой одну из важнейших частей каждого
компьютера. А ведь когда-то без нее, можно было легко обойтись (первые
видеоплаты (к примеру модель S3 VIRGE) в основном использовались для
ускорения вывода 2D-графики). Но те
времена прошли, и сейчас видеоплаты уже пересекли границу бездонности
(имеется ввиду сферы применения). В данном разделе я прослежу не только
эволюцию ГПУ, но и видеокарт в целом.
1 . Прошлое и первые
шаги развития
процессоров GPU
Немного
истории, а так же терминов и определений, чтобы была так сказать
"основа", откуда можно отталкиваться...
Для создания трехмерного объекта (вся сцена получается из огромной
совокупности объектов), ему задаются вершины, которые определяют,
ключевые точки, а так же полигоны, образованные линиями, соединяющими
вершины. Это формирование "геометрии" объекта. Потом происходит
наложение цвета на полигоны по специальным алгоритмам (это называеться
закраской). Графические ускорители работают с полигонной графикой, и
это означает
что каждый обьект состоит из набора плоских многоугольников, которые в
свою очередь создаются из простейших треугольников. С обработкой
"геометрии" объекта справляется и процессор, однако
когда нужна и закраска, средств одного ЦП не хватает. Наложение текстур
на полигоны очень ресурсоемкая задача, и процессоры не могут справиться
с таким большим количеством трудных операций в секунду. Для
аппаратного ускорения всех сложных операций были созданы первые
3D-акселераторы. После создания и закраски объекта, так же важно
позаботиться и об его освещении. Естественно самые первые ускорители не
умели обрабатывать освещение, но это не говорит о том, что игры того
времени были совсем убогими. Из-за возрастающей нагрузки на ЦП,
видео-ускорители со временем получили аппаратный блок геометрических
вычислений - Hardware Transform & Lightning (T&L). Затем
модифицировав алгоритм расчета цвета точки, смогли, не усложняя
геометрическую модель, сильно улучшить её внешний вид. Данная техника
получила название BUMP MAPPING. Данный способ не был единственным для
улучшения картинки, на ряду с ним применялось еще десяток специальных
техник и методов. Но реализация всего ранее перечисленного требовала
возможности программирования пиксельных конвейеров или шейдеров [1].
Шейдер - небольшая программа,
позволяющая
программировать
графический ускоритель. На практике шейдер - короткая
последовательность машинных кодов, которую разработчик, как правило,
описывает на специальной разновидности ассемблера (NVIDIA предложила
свой собственный С-компилятор шейдеров, а Microsoft в свою очередь
включила стандартный High-Level Shader Language (HLSL)). При всем этом
шейдер позволяет творить чудеса с простыми и сложными моделями.
Существует несколько их версий (Shader Model), о которых я еще упомяну
далее по тексту. Не будем впадаться в подробности, а рассмотрим их
поверхностно. Начнем пожалуй с вершинных шейдеров (Vertex Shader),
которые являются развитием идеи T&L. Так получилось, что
данный
блок ускоряет некоторые геометрические преобразования, и тем самым
разгрузив центральный процессор, можно его использовать для того, чтобы
"шевелить" листьями деревьев и травой в детализированной сцене, так же
детализировать или огрублять объекты. Разработчик получает полный
контроль над механизмами T&L и может использовать Vertex
шейдеры для расчета специфической геометрической информации, которую
потом будут использовать пиксельные шейдеры.
Vertex Shader первой версии при небольших
объемах
геометрических вычислений в процессе рендеринга может быть сложной
многострочной программой. Первая версия имела большие ограничения, так
же не допускались переходы. А вот во вторая версия допускала переходы и
циклы, и еще позволяла организовывать функции, благодаря чему
реализовывался практически любой алгоритм. Третья же версия получилась
еще более продуманной, чем более ранние - она позволяла использовать в
вычислениях текстуры и создавать для каждой из вершин свои собственные
свойства. Исходя из этого вершинный блок постепенно становится
полноценным процессором с приличными возможностями. Но нужно учитывать
то, что они по своей сути, существуют для того чтобы разгрузить ЦП. Их
можно легко имитировать драйверами, подменив обычным процессором
соответствующий блок в ГПУ. Однако с пиксельными шейдерами такая уловка
не получается. Теперь рассмотрим пиксельные шейдеры чуть поближе.
Пиксельный шейдер (Pixel Shader) чаще всего задает
модель
расчета
освещения каждой отдельно взятой точки изображения, так же
производиться выборка из текстур и\или математические операции над
цветом и значением глубины. Пиксельные шейдеры могут и
автоматически генерировать текстуры, а так же производить с текстурами
различные операции. Если брать образно, то Pixel
Shader - это рельефные стены и\или естественное освещение, рябь
на воде, блики света, на металлических и стеклянных поверхностях,
реалистично выглядящие поверхности и разнообразные спецэффекты. Это
именно то чем все восхищаются в красивых и динамичных компьютерных
играх. Хотя на самом деле пиксельный шейдер не вычисляет, а
изменяет некий предварительно вычислительный стандартными способами
цвет, именно поэтому если видеоплат не поддерживает шейдеры, то она все
таки (хотя не всегда) выдаст на экран картинку или её часть.
И как вы уже поняли обработка пиксельных шейдеров - это
колосальная нагрузка ена ГПУ. Но овчинка действительно стоит выделки!
Реалистичность игрового мира - это вам не шуточки. И ради неё
можно и побороться. Ограничения на шейдерную программу здесь
жестче, чем в случае вершинных шейдеров.
Кроме арифметических вычислений так же присутствует и
специальные
текстурные, которые осуществляют выборку цвета и
арифметические вычисления с текстур. Если вопрос станет о версиях
пиксельных шейдеров, то можно легко сказать, что они тоже
эволюционировали со временем [10].
Все этого хорошо, однако неясно как это все работает в
результате. Начинаем разбираться.
Существует такая штука как графический конвейер,
который
реализует обработку графики конвейерным способом. А работает он по
следующей схеме:
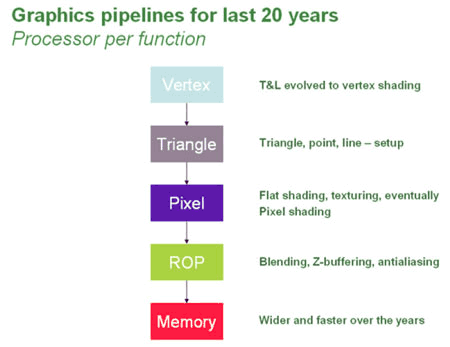
Рисунок 1 - Схема принципа работы
графического конвейера
Первый
этап:
В графический процессор
поступают
данные от ЦП об объекте,
который необходимо построить. Эта информация попадает в блок вершинных
процессоров и там же обрабатывает. Вершинный конвейер занимается
расчетом геометрии сцены и определяет положение вершин, которые при
соединении образуют полную каркасную модель трехмерного объекта,
так же здесь осуществляется математические операции с вершинами.
Все это происходит под управлением вершинных шейдеров. Вроде нет ничего
сложного.
Второй этап:
После блока вершинных конвейеров
данные поступают в блок (Triangle), где происходит сборка (Setup) трехмерной модели в
полигоны.
Третий этап:
Затем они попадают в блок
пиксельных процессоров (Pixel
Pipeline).
Там и происходит операция закраски, так же средствами пиксельных
шейдеров происходит растеризация для каждого пикселя изображения, а еще
и мультиплексирование, по пиксельное освещение, создание процедурных
текстур, пост обработка кадра и т.д.
Четвертый этап:
Затем данные попадают в
блок растровых операций ROP (Raster
Operations Pipes), где с использованием буфера глубины (Z-буфера)
определяются и отбрасываются те пиксели которые не будут видны
пользователю (в данном кадре). Здесь же реализуеться обеспечение
полупрозрачности. В данном блоке происходит: Antialising (сглаживание -
удаление лесенки на изогнутых линиях путем добавления вокруг пикселей,
создающих прямые линии из других пикселей, других оттенков), Blending
(вкратце - плавный постепенный переход от одного цвета к другому, или
преобразование одной геометрической формы в другую). Затем в ROP
снова собираются все фрагменты (пиксели) сцены в полигоны и уже
обработанная картинка передаеться в кадровый буфер (frame buffer). Этот
буфер нужен для того чтобы вывод и формирование картинки не зависели
друг от друга. А так как монитору нужно непрерывно получать видеосигнал
из данного буфера, применяется специальный преобразователь RAMDAC (RAM
Digital-to-Analog Convertor - цифро-аналоговый конвертор), который
непрерывно читает кадровый буфер и формирует сигнал, передаваемый через
дополнительные схемы на выход видеокарты. У современный ГПУ
несколько RAMDAC, это позволяет одновременно и
независимо выводить видеосигналы на несколько мониторов одновременно [5].
Описанный "классический" конвейер дает представление
об
основных этапах формирования изображения видеокартой. Графический
конвейер тут описан в упрощенном виде, из-за того что там дела
творяться дела гораздо сложнее и впадать в усложнение и подробности не
имеет смысла. Потому что главное то, что в ГПУ не один а несколько
конвейеров, и работают они паралельно , и за счет их количества
производительность ГПУ достигает больших результатов. Не
стоит забывать что "графический конвейер" - понятие условное, из-за
того что в графическом процессе используются несколько различных
конвейеров, которые выполняют разные функции (со временем заменены на
унифицированные). Так получилось, что под конвейером понимали
пиксельный процессор который подключен к своему блоку наложения текстур
(TMU - Texture Module Unit). Корректной характеристикой ГПУ будет число
конвейеров, но только если их количество совпадает с числом пиксельных
и вершинных процессоров и блоков TMU. Равное количество
различных процессоров было бы самым производительным решением, если бы
нагрузка на каждый из процессоров была одинаковой. Но в реальности все
не так идеально - нагрузка частенько неравномерная, и нужно искать
оптимальный вариант комбинируя процессоры в зависимости от
потребностей. Очень важно не переборщить с геометрическими
характеристиками, и в тоже время не пренебречь красотами
мультиплексирования и роскошью сложных пиксельных шейдеров. И поэтому
каждый из производителей определяют "свою" пропорцию пиксельных и
вершинных процессоров. Но решение по нахождению золотой середины
существует, об этом будет сказано чуть позже [4].
Каждый новый виток развития ГПУ представляет из себя некое
поколение, и
поэтому можно стандартизировать видеоплаты по поколениям, чем
собственно и займусь.
Первое поколение
История 3D-акселераторов,
берет начало
с
компании 3Dfx. Видео карты на основе процессора Voоdoo
Graphics, который впоследствие стал называться Voоdoo
I, появились в 1996 году и надолго прославили компанию
производителя. Типичное рабочее разрешение для данного чипа составляло
512 х 384 пикселей, максимальное 640 х 480 при глубине цвета в 16 бит,
и на своем борту имело 4 Мб видеопамяти. Одним из главных факторов
успеха компании было использование новой модели построения 3D
объектов, получившая название Glide. Сущность заключалась в обмене
информацией между чипом видеоплаты и видеопамятью, при этом вся
нагрузка ложилась на последнюю. Так же поддержало компанию на плыву и
следующая серия Voоdoo II, из-за улучшеных
показателей нового чипа по сравнению с предыдущим. Уточняю, что первые 3D-ускорители
представляли собой дополнительную плату подключаемую к обычному 2D-видеоадаптеру. Так
же не будем забывать об NVIDIA, главным конкурентом 3Dfx,
которые начали свой подъем с таких процессоров как Riva 128 и Riva
128ZX. Так же, в 1998 году она выпускает чип Riva TNT.
Если сравнить Voоdoo II и
Riva
TNT то можно понять, что у NVIDIА получился ресурсоемкий и
недостаточно мощный акселератор для того времени. Это стало стартом
гонки, которую впоследствии NVIDIA выиграет у 3Dfx,
но это будет в следующем поколении. Так же конкуренцию 3Dfx
составила компания ATI, хоть и первый чип Rage 3D значительно
проигрывал Voоdoo I, ATI в 1999г
удалось создать Rage 128 (Fury) Rage 128 Pro (Fury Pro), которые
обгоняли аналоги других компаний. А еще в них впервые появилась
аппаратная поддержка MPEG-2.
Еще одной причиной появления графических акселераторов можно
считать возросшее потребление вычислительных ресурсов компьютерными
играми, где обычные 2D-ускорители просто не
справлялись.
Современный пользователь вряд ли высоко оценит реалистичные
трехмерные сцены, сформированные акселераторами того времени. Это был
лишь первый шаг, к тому что мы можем наблюдать сегодня.
Второе поколение
Основоположником этого
поколения является чип GeForce 256
появившийся в
августе 1999 года, который привнес в 3D графику
новые возможности.
А еще поддерживалась новая технология Transform &
Lightning (T&L), и она заключается в преобразовании координат
вершин в плоские координаты, отображаемые на мониторе, и вычислении их
освещенности. Данная видеокарта GeForce 256 была дорогой и
непроизводительной на приложениях, которые не использовали возможностей
аппаратного T&L, и до сих пор использовали ЦП для
ручных вычислений. Именно из-за этого другие производители видеокарт
пророчили ей быстрое забвение. Однако ситуация коренным образом
изменилась с поддержкой T&L (примером могут служить
такие игры : Quake 3Arena, Unreal Tournament). Ввиду неоспоримого
преимущества аппаратного T&L перед программным
вскоре он стал де-факто стандартом при программировании трехмерных игр.
Компания ATI выпустила свою платы Radeon с его
поддержкой, а остальные конкуренты просто были вынуждены уйти с рынка
игровых видеоплат.
Третье поколение
ГПУ этого поколения
добавил еще болше возможностей по
программированию к графическим процессорам предыдущего поколения.
Шейдеры данного поколения писались на ассемблере графического
процессора, их длина не превосходила 20 команд, не было поддержки
переходов, а вычисления производились в формате с фиксированной
запятой. К представителям третьего поколения 3D-ускорителей
относят Nvidia GeForce 2-4, ATI Radeon 8500-9200. Изменения в ГПУ в
этом этапе были эволюционного характера. А трехмерная
графика в виртуальном мире становилась все реалистичнее, однако
кординальных изменений привнесено не было.
Четвертое поколение
А вот представители
данного поколения стали уже полностью
программируемыми. Основным интерфейсом выделялся Direct3D, который
первым обеспечил поддержку шейдеров (язык HLSL).
OpenGL с версии 2.0 также добавляет поддержку высокоуровневого языка
программирования шейдеров GLSL. Появление операций ветвления и циклов
позволило создать более сложные шейдеры. В 2003 г. на ГПУ впервые
появилась поддержка вычислений с 32 -разрядной точностью.Так же начали
появляться приложения, использующие графические процессоры для
высокопроизводительных вычислений, таким образом, начало складываться
направление общих вычислений GPGPU (General Purpose GPU). Для
програмирования ГПУ был предложен SIMD подход (Single Instruction
Multiple Data). Подход, предполагает, что группа параллельно работающих
порцессоров осуществляют действия над разными данными, но при этом все
они в произвольный момент времени должны выполнять одинаковую команду.
В виде примеров ГПУ четвертого поколения можно назвать процессоры
Nvidia GeForce серий 5ххх-7ххх и ATI
Radeon 9500 - X800.
Притом на этом этапе наблюдается повсеместное вытеснение стандарта
AGP более быстрым PCI-Express. За счет использования шейдерного
рендеринга удалось достичь высочайшего уровня реалистичности
виртуального мира за все пройденное ранее время.
А теперь рассмотрим данное поколение чуть подробнее.
Начну пожалуй с ГПУ от компании Nvidia. Итак в 2005
году
чип G70 (GeForce 7800) стал дальнейшим развитием ранее выпущенных видео
процессоров. Он имеет 24 пиксельных конвейера, по одному текстурному
блоку на конвейер (24 TMU), 8 вершинных конвейеров и 16 блоков
растровых операций (ROP). Остальные характеристики занесены в таблицу
1. Смотрим и разбираемся.
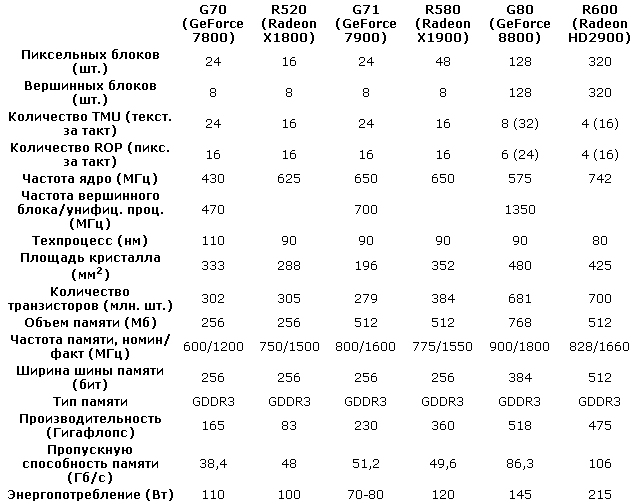 Таблица 1 Сравнительная характеристика некоторых чипов 4ого поколения
Таблица 1 Сравнительная характеристика некоторых чипов 4ого поколения
Тут графический процессор состоит из
нескольких пиксельных конвейеров, работающих параллельно, и чем больше
конвейеров, тем более производительнее ГПУ. За счет того что пиксели
"расселены" по разным конвейерам. Заведено объединять пиксельные
процессоры в группы по 4 штуки, чтобы они обрабатывали не отдельные
пиксели, а блоки по 4 пикселя.
Рисунок 2- Архитектура 6 блоков обработки по 4 процессора в каждом
Сердцем процессора G70
являются 2 шейдерных блока
(векторные ALU (Arithmetic & Logic Unit), базовое устройство
выполняющее основные вычислительные операции) и 2 мини ALU
(простейшие скалярные ALU, параллельное исполнение простых
операций). Благодаря
этим "упрощенным" ALU можно увеличить математическую производительность
процессора, а следовательно, и скорость исполнения пиксельных шейдеров.
В нашем случае каждый пиксельный процессор может выполнять 8 инструкций
типа MADD (Multiply Add, поэлементное умножение двух 4-компонентных
векторов с прибавкой к полученному вектору третьего вектора - к этой
штуке мы тоже еще вернемся) за такт, а суммарная производительность 24
процессоров на инструкциях такого типа достигает цифры в 165 гигафлопс
(например, у предшественника - GeForce 6800 Ultra, производительность
достигала всего 54 гигафлопс).
Также очень важно, сколько операций с плавающей запятой
производит вычислительное устройство за заданное время. Причем данный
показатель является основным мерилом производительности компьютерных
процессоров или других вычислительных устройств, и называется этот
показатель FLOPS (Floating point Operations Per Second - операции с
плавающей запятой в секунду) - эта величина как раз и показывает
производительность вычислительного устройства (как правило, из-за
высокого уровня производительности используются производные величины от
FLOPS, образуемые путем использования стандартных приставок системы СИ
(мегафлоп, гигафлоп, терафлоп и т.д.). Как и большинство других
показателей производительности, данная величина определяется с помощью
тестовых программ, которые запускаются на подопытном устройстве (широко
распространена программа Linpack, первоначально библиотека на языке
Фортран, содержавшая набор подпрограмм для решения систем линейных
алгебраических уравнений, впоследствии на основе ее появился тест
Linpack benchmark, с помощью которого определяется вычислительные
способности не только "обычных" устройств, но и суперкомпьютеров TOP500
(данный тест, по сути, является основным тестом в рейтинге TOP500) [8].
Чем хорош флопс - при всей своей теоретичности он наиболее
объективный, наиболее приближенный к реальным способностям устройства,
в то время как остальные тесты являются чересчур субъективными и
зависят от многих факторов. В основном они позволяют оценить испытуемую
систему лишь в сравнении с рядом других аналогичных устройств. Правда,
"флопс" не абсолютно точный показатель, есть много сложных нюансов (уже
в самом термине "операция с плавающей запятой" много неопределенности,
не говоря уже многих моментах, влияющих на результат и не связанных с
производительностью вычислительного устройства - пропускная работа
оперативной памяти, кэш-памяти, пропускная способность шины и т.д.).
Впрочем, если опираться на результаты только одной программы (например,
той же Linpack, но и тут есть одна проблема - все производители должны
использовать одну и ту же программу, а такое не всегда происходит) и
при этом брать средние значения, то можно получить более-менее
правдивые результаты. Но есть проблемы другого рода - например,
существуют системы, для которых, например, Linpack, не подходит из-за
конструктивных особенностей. Например, суперкомпьютер MDGrape-3 имеет
рекордную теоретическую производительность в 1 Петафлопс (для
сравнения: первый номер TOP500, BlueGene/L, имеет только 280,6
Терафлопс), но он применим только для узкого круга задач, и поэтому
очень сложно определить его "реальную" производительность (чтобы хоть
приблизительно определить его место в TOP500), так как Linpack с ним не
дружит.
Вернувшись к чипу G70
значительная
часть вычислений пиксельного конвейера всегда связана с использованием
одной или нескольких текстур и, соответственно, выборки из них, которая
происходит не очень быстро, то для увеличения скорости выборки уже
давно применяются специальные текстурные блоки (TMU), единственная
задача которых - осуществлять выборку из текстур и их фильтрацию. В
идеале - на определенное число конвейеров приходится равное число TMU,
и за такт каждый из них способен произвести одну выборку. И если,
например, TMU вдвое меньше чем конвейеров, а для проведения вычислений
над точкой нужно две текстуры (что не такая и редкость в играх), то
текстурные модули будут выдавать вдвое меньше данных, чем способны
обработать конвейеры, и в итоге пикселы будут сходить с конвейера не
каждый такт, а допустим, каждый второй такт. Поэтому число TMU является
довольно важным параметром графического ядра. Но не стоит забывать и
про вершинные процессоры, которые долгое время просто немного
"шлифовали", не внося особых изменений - чтобы увеличить
производительность данных конвейеров, обычно просто увеличивали их
число. Правда, в G70 инженеры прибегли к необычному решению - ввели
разделение частот, и теперь у пиксельных процессоров своя частота, а у
вершинных своя. Что, конечно же, повлияло на увеличение
производительности. В свою очередь, вершинные процессоры также играют
немаленькую роль в обработке изображения, так как работают с геометрией
объекта, а затем отправляют свои данные на сборку (setup), после чего
следует растеризация, обработка в пиксельных конвейерах, а затем все
пикселы попадают в блок растровых операций (ROP). При этом данный "блок" (имеется ввиду
совокупность блоков ROP) перетерпел некоторые изменения. Если ранее в
ускорителях NVIDIA было по одному блоку ROP на пиксельный конвейер, то
в G70 их "всего" 16 (а точнее, они объединены в 4 блока по 4 ROP в
каждом) на 24 пиксельных процессоров. Для оптимизации расхода
транзисторов просто-напросто используются одни и те же ROP'овские ALU в
разных целях в зависимости от задачи. При этом блоки ROP и пиксельные
конвейера общаются между собой с помощью быстрого коммутатора, который
перераспределяет рассчитанные квады между блоками. Также увеличение
числа и сложности пиксельных конвейеров (которые стали тратить много
сил на математические вычисления) привело к тому, что такое же число
ROP будет не самым оптимальным решением, так как велик шанс того, что
какие-то части ROP будут просто простаивать, и не последнею роль в этом
будут играть малые возможности памяти (при имеющейся пропускной
способности не факт, что за 1 такт удастся записать в кадровый буфер
даже 16 полноценных пикселов - надо сказать, последняя по своим
возможностям недалеко ушла от VRAM той же GeForce 6800 Ultra. Т.е. в
GeForce 7800 просто было найдено оптимальное и более производительное
соотношение, которое не уменьшало производительность, но и не
увеличивало число транзисторов.
В свое время выход GeForce 7800 вывел
NVIDIA в лидеры. Ответ конкурента в виде R520 задержался на долгих 4
месяца, впрочем, даже после появления Radeon X1800 ситуация не сильно
изменилась. А вот выход R580 с его доселе невиданными характеристиками
автоматически вывел ATI на первой место. Но, конечно, NVIDIA не
собиралась с этим мириться, и вскоре свет увидел новый чип - G71.
Данный GPU по сути представляет собой "вылизанный до блеска" G70, о чем
говорит практически идентичная архитектура. Правда, вылизан он был
действительно идеально. Судите сами: с тем же количеством пиксельных и
вершинных процессоров, с теми же 24 TMU и 16 ROP, что и у G70, причем
их структура не перетерпела изменений, G71 имеет увеличенные частоты
(характеристики смотрите в сравнительной таблице), при этом он уменьшил
свое энергопотребление, тепловыделение и размеры. Конечно, это отчасти
удалось достичь благодаря переходу на более тонкий 90-нм техпроцесс. Но
как объяснить то, что новый GPU "потерял" транзисторы? Ведь по
сравнению с G70 у G71 их на 25 миллионов меньше. Повторю - G71 имеет
все то же самое, ничего не пропало. Есть только два более-менее
разумных объяснения этого факта (как вы понимаете, NVIDIA не раскрыла
секрет): первое предполагает героизм инженеров, которые провели
колоссальную работу по оптимизации разных частей GPU; второй
вариант - возможно, в G70 было зарезервировано какое-то число блоков
для увеличения числа выхода годных чипов. То ли выход годных чипов на
90-нм процессе был достаточно высок, то ли NVIDIA смогла позволить себе
больше брака, но в результате она просто удалила "запасные"
транзисторы. Это, конечно, догадки, факт в том, что NVIDIA удалось на
основе G70 сделать совершенно новый продукт с новой
производительностью, что помогло ей сократить разрыв с ATI. Благодаря
этому этапу стало возможным создать такие интересные продукты как
GeForce 7900 GX2 и GeForce 7950 GX2, которые, по сути, являлись
уникальными - у ATI ничего подобного небыло.
Представителем ATI у нас будет чип R520, и не просто
потому, что
он является ответом G70, а в первую очередь из-за того, что в этом чипе
ATI немного отступила от концепции "классической" архитектуры и при
этом заложила основы для дальнейшего многолетнего развития, в том числе
и в эпоху унифицированной архитектуры. Когда-то очень давно ATI висела
практически на волоске. Видеокарта, которая продвигалась в то время (а
именно - Radeon 8500) как hi-end-решение по производительности
дотягивала лишь до "начального уровня" конкурента. Продажи падали,
компания терпела большие убытки. Положение спас вышедший R320 (и его
модификации). С тех пор почти 3 года ATI просто занималась шлифовкой
удачной линейки Radeon 9xxx, причем по старому и проверенному способу -
увеличение числа конвейеров, оптимизация, иногда переход на новый
техпроцесс и т.д. В какой-то степени ситуация начала повторяться в 2005
г., когда NVIDIA выпустила GeForce 7800, а ATI чересчур долго тянула с
ответом. Результат - провальный квартал, снижение продаж и $104 млн.
убытков. Почему тянули? - ответов тут несколько: параллельная
разработка R500 (графический чип Xbox 360, который, кстати, немного
повлиял на архитектуру R520); накладки с переходом на новый 90-нм
техпроцесс, но самое главное то, что это время требовалось для
завершения работ над новой архитектурой, которую без больших угрызений
совести можно назвать "революционной". За это время была проделана
действительно колоссальная работа. Во-первых, радикально переработана
святая святых GPU - блок пиксельных процессоров. В прошлом он состоял
из однотипных и простых пиксельных конвейеров, каждый из которых
вычислял цвет отдельно взятого пиксела. Последний, однажды попав на
один из конвейеров, обрабатывался прописанной ему программой (шейдером)
и болтался внутри конвейера, пока не закончится вычисление его цвета.
При этом почти все зависимые устройства (например, TMU) подключены
непосредственно к исполнительным устройствам конвейера - схема очень
проста и эффективна, но лишь до определенного момента. На смену прежней
архитектуре был предложен своеобразный суперскалярный процессор,
который, по сути, работает как один большой конвейер, имеющий
возможность обрабатывать несколько пикселов одновременно [1].
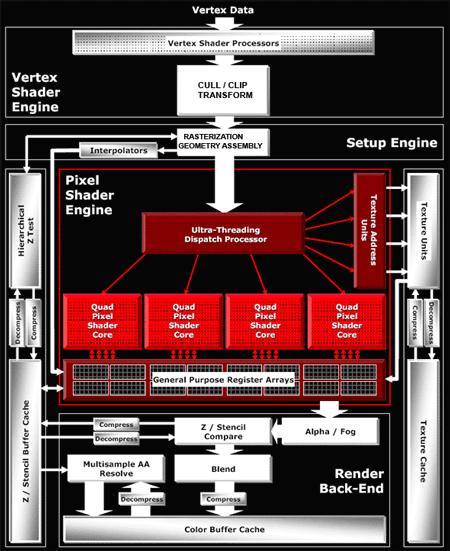 Рисунок 3 Схема архитектуры чипа R520
Рисунок 3 Схема архитектуры чипа R520
Вместо того чтобы
сразу пихать пикселы в разные конвейеры,
R520 накапливает их вместе с шейдерными инструкциями в специальном
огромном планировщике - Ultra-Threading Dispatch Processor. В данном
планировщике все квады хранятся в длинной очереди и по мере
освобождения вычислительных ресурсов отправляются на обработку. Причем
устройства, на которые планировщик отправляет данные, различны - TMU,
ROP (которых, кстати, в этих GPU было по 16) или пиксельные процессоры.
Это автоматически развязывает руки разработчикам - теперь можно
спокойно варьировать соотношение пиксельных процессоров и текстурных
модулей, так как они больше не подключены друг к другу. Тем более что
раньше TMU своими зачастую медленными операциями могли вообще
блокировать весь конвейер, так как пиксельным процессорам приходилось
ждать от них ответа. И конечно, динамического переупорядочивания
инструкций в GPU не предусмотрено (это ж вам не CPU), поэтому
высвободить немного вычислительных мощностей под более нужные вещи не
было возможности (те же пиксельные процессоры). Благодаря данному
чудо-планировщику ATI смогла наконец-то организовать поддержку Shader
Model 2.0a и 3.0 (т.е. поддержку условных переходов, которую NVIDIA, к
слову, реализовала еще в чипах NV4х), с которыми она до этого не сильно
дружила. Ведь ради упрощения пиксельных конвейеров их схемы делались
таким образом, чтобы они всякий раз настраивались на определенную
операцию (сложение, вычитание, умножение), через которую пропускалось
огромное количество пикселей. Схема была очень эффективна благодаря
своей простоте, но для шейдеров с условными переходами (т.е. сложных
программ) такой подход, мягко говоря, не предназначен. NVIDIA решает
данную задачу так: в конвейере все пикселы обрабатываются "по кругу",
но в решающий момент над некоторыми из них производят операцию, а
некоторые просто игнорируют. Шейдерами с условным переходом занимается
специальный диспетчер ветвлений шейдера - GigaThread. Конечно, подход
не идеальный, но самое главное - проблема решается. А вот ATI
умудрилась реализовать поддержку Shader Model 3.0 практически
бесплатно, без лишней свистопляски: все хранится в планировщике, то
есть имеется возможность пускать только те квады, с которыми
действительно нужно что-то делать сейчас, остальные же ожидают "в
курилке". Таким образом, конвейер продолжает и дальше работать по
старой схеме, но при этом он не спотыкается на условных
переходах. Можно, конечно, решить проблему совсем просто - с помощью
специальных "предсказателей" (вообще, содержимое GPU можно назвать, с
большой натяжкой, блоком предсказаний) - но это ж вам не CPU. R520 на
первый взгляд немного смахивает на G70 своими пиксельными процессорами,
но реального сходства мало, так как скалярные и векторные ALU работают
отдельно. Вот только пиксельные процессоры G70 будут производительней
(так как могут выполнять немного больше сложных и простых команд за
такт), чем у R520, у которого их к тому же всего 16. Они дают скромную
суммарную производительность в 83 гигафлопс (у G70 - 165). Тут
сравнивать, конечно, тяжело, но заметим, что при сопоставимом числе
транзисторов (смотрите таблицу) ATI смогла всунуть только 16 пиксельных
процессоров. Это, по сути, плата за сложность архитектуры. Ведь чем
сложнее устройство, тем оно и менее производительно, а самое главное,
менее рентабельно. У ATI всегда с этим проблема - пытаясь догнать и
перегнать конкурента с его неизменно простым и эффективным подходом, ей
приходится "брать грубой силой" - идти на постоянные усложнения,
серьезные переработки и инновации, которые часто выливаются в побочные
эффекты - цена, тепловыделение и т.д. Ведь только благодаря сложности
R520 ATI сумела догнать - но, к сожалению, не перегнать - G70. Впрочем,
R520 оказалась хорошо масштабируемой архитектурой, позволив ATI
практически сразу выпустить монстроподобный R580, который, к слову,
если не принимать во внимание увеличенное число пиксельных процессоров
(до 48), а также цены, тепловыделения, размеров, частот и немного
большей производительности, существенно не отличается от R520. На
что NVIDIA ответила улучшенным G70, при этом оставив "все как есть", и
спокойно догнала ATI. Но не перегнала - не считая 7950 GX2, на который
ATI ответила выходом X1950 XTX, но до NVIDIA не дотянув. Как говорится,
почувствуйте разницу в подходах - простым и сложным[6].
А теперь перейду к следующему разделу.
2. Настоящее и
современные сферы
использования видеопроцессоров
Пятое поколение
GPU пятого поколения
характеризуются расширенными
возможностями
программирования. На этом этапе GPU начинает поддерживать
геометрические шейдеры, которые, в отличие от вершинных, позволяют
обрабатывать не только одну вершину, но и целый примитив. Также
появляется полная поддержка унифицированной шейдерной архитектуры, за
счет которой осуществляется более гибкое использование ресурсов
графического процессора. Например, в условиях с симуляцией тяжелой
геометрии сцены унифицированная шейдерная архитектура может
задействовать все блоки GPU для вычисления вершинных и геометрических
шейдеров. И наоборот, когда геометрия не является сложной, а
симулируется множество сложных пиксельных эффектов, все вычислительные
блоки могут быть направлены на выполнение только пиксельных шейдеров.
Кроме этого, GPU пятого поколения начинают поддерживать целочисленные
операции, а также операции с двойной точностью. Появляются
специализированные средства, позволяющие взаимодействовать с GPU
напрямую, минуя уровень интерфейса программирования трехмерной графики.
Поддержка 32-битных вычислений с плавающей запятой становится
повсеместной, и это способствует активному росту направления GPGPU, для
которого создаются средства программирования. Появляются потоковые
библиотеки программирования GPU (RapidMind, Accelerator), а также
первые коммерческие применения GPGPU (nVidia CUDA, AMD FireStream).
Более того, отпадает необходимость в использовании специализированного
физического ускорителя (англ. Physics Processing Unit, PPU) PhysX,
поскольку GPU получили возможность аппаратно ускорять физические
расчеты и освобождать, тем самым, CPU от излишних вычислений. Этот этап
продолжается по настоящее время. Представителями GPU пятого поколения
являются модели nVidia GeForce 8ххх – GTX 5хх, ATI Radeon X 1ххх
– HD 6ххх.
Сегодня мы имеем немного другие архитектуры и несколько
измененный графический конвейер. Связанно это с появлением последней
версией API - DirectX 10, и новой, 4 версией шейдеров (Shader Model
4.0). Основные цели, которые поставила перед собой Microsoft при
разработке API DirectX 10 были таковы:
-снизить зависимость от центрального процессора; -предоставить
разработчикам унифицированный набор инструкций для программирования
пиксельных и вершинных шейдеров; -увеличить функциональность пиксельных
и вершинных шейдеров; -предоставить разработчикам возможность создавать
новые геометрические эффекты непосредственно в шейдере; -дать
возможность графическим процессорам управлять потоками данных внутри
себя (с помощью Stream Output), увеличивая тем самым эффективность
исполнения кода; -увеличить эффективность работы с текстурами,
максимальное разрешение текстур, поддержать новые форматы HDR и
произвести другие эволюционные изменения [12].
Все это было
реализовано в полной мере, и результаты мы
сможем увидеть в играх следующего поколения, вооружившись новыми
графическими ускорителями, поддерживающими DirectX 10 и Shader Model 4.
В четвертой версии шейдеров в первую очередь было принято решение
отказаться от поддержки низкоуровневого ассемблерного языка
программирования, теперь применяется только высокоуровневый язык,
например HLSL 10 (High Level Shader Language). Было снято ограничение
на количество инструкций в шейдерах и увеличено количество
поддерживаемых шейдерами текстур, которые ими используются, плюс
введена обязательная поддержка FP32. Все эти (и другие) изменения
призваны открыть весь потенциал унифицированных шейдеров и максимально
повысить быстродействие и производительность системы. Сам смысл
унифицированных шейдеров мы рассмотрим на примере иллюстраций: при
разделении на вершинные пиксельные процессоры мы часто можем
столкнуться с ситуацией, когда одни работают на полную катушку, другие
вполсилы. Теперь же, когда мы имеем набор унифицированных процессоров,
мы можем распределять нагрузку в зависимости от ситуации, и тем самым
повысить общую производительность всего GPU.
При этом к основным двум типам шейдеров (пиксельные
и
вершинные) был добавлен еще один - геометрический шейдер (Geometry
Shader), умеющий самостоятельно добавлять новые вершины (а также точки,
линии и треугольники), работать с ними и, по сути, рисовать новые
примитивные фигуры, собирая их и делая с ними все что угодно (в рамках
своих входных алгоритмов). Это все заставило немного изменить сам
графический конвейер - смотрим на блок-схему и разбираемся, что
изменилось:
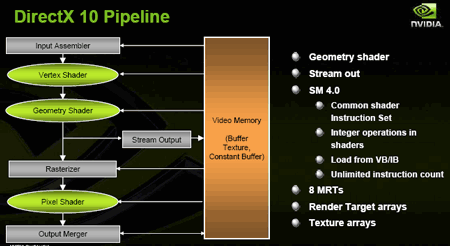
Рисунок 4 - Схема графического
конвейера с поддержкой DirectX 10
Первое изменение - блок
Input Assembler (IA) помимо общения с
центральным процессором получает вершинные данные из буфера вершин
(Vertex buffer) или данные из буфера индексов (Index buffer,
обеспечивает прирост производительности, так как позволяет избежать
повторного просчета данных с тем же индексом). Данный блок может
повторно вводить на конвейер данные, рассчитанные вершинными,
пиксельными и геометрическими блоками, загруженные в память с помощью
потокового вывода (Stream Output). Благодаря этому можно снова и снова
вводить на конвейер одни и те же требуемые данные, не повторяя их
расчет, что, конечно же, разгружает сам конвейер и увеличивает
производительность. При этом потоковый вывод может также загружать
данные из памяти непосредственно в геометрический блок и тем самым
"отсекать" пиксельные и вершинные блоки, заставив работать конвейер (на
определенном необходимом этапе) без них. Но основная задача Stream
Output - снабжать геометрический блок нужной ему информацией. Все
остальное осталось без больших изменений, но и вышеперечисленного
хватает с головой, чтобы поднять производительность и вычислительные
способности графического ускорителя на новый качественный уровень.
Первым графическим процессором нового поколения по праву
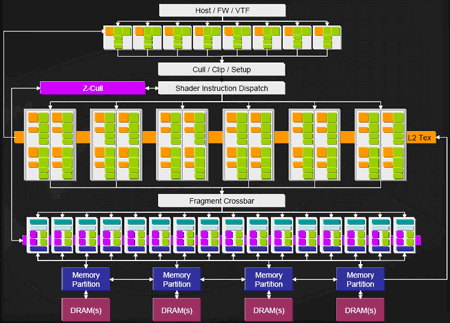
считается G80 (GeForce 8800) от NVIDIA. Вот с него и начнем. Как вы
понимаете, изменение архитектуры графического конвейера повлекло за
собой и изменение ядра GPU, теперь вместо отдельных пиксельных и
вершинных блоков имеем один большой многофункциональный блок, а проще
сказать, унифицированный.
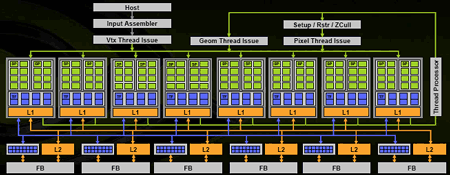 Рисунок 5 - Архитектура GeForce 8800
Рисунок 5 - Архитектура GeForce 8800
У G80 128 унифицированных
процессоров (они же скалярные ALU),
собранных в 8 больших блоков — именно они, эти 8 блоков (16 ALU +
4 TMU), являются основными вычислительными единицами. В любой момент
времени такой блок может заниматься своим делом - пиксельными,
шейдерными или геометрическими операциями; напротив, ни один из 128 ALU
независимо от остальных такого себе позволить не может. В каждом из
блоков содержится по 16 ALU, что в сумме дает наши 128 унифицированных
процессоров, причем теперь они называются потоковыми процессорами
(Stream Processors). Потоковые из-за возможности повторной обработки
данных, выведенных одним процессором с помощью другого процессора. В
классическом конвейере данные сначала должны пройти до конца и быть
выведены в кадровый буфер, теперь же данные, обработанные одним
процессором, которые загружаются в кэш (stream output), могут быть
вычитаны другим процессором (stream input). При этом все обработанные
данные, выходящие из шейдерных блоков, могут снова поступить на вход
конвейера. Такая "карусель" находится под управлением нового блока
(Thread Processor), который вместо кэширования данных и отправки на
следующие стадии конвейера пускает их по кругу, если, конечно, есть
такая необходимость. Также переработан диспетчер ветвлений
(GigaThread), теперь он может производить вычисления над несколькими
шейдерами с ветвлением одновременно, а не последовательно, как в случае
с G7x [2].
Векторные исполнительные
блоки в графических процессорах ATI
Radeon X1000 работают по схеме "3+1", т.е. способны выполнять за такт
одну векторную операцию над четырехэлементными векторами или одну
векторную операцию для трехэлементных векторов плюс одну скалярную
операцию. Векторные исполнительные блоки в графических процессорах
NVIDIA GeForce 6 работают по схеме "2+2", т.е. способны выполнять
одновременно две векторные операции для двухэлементных векторов или
одну векторную операцию для четырехэлементных векторов, а GeForce 7
кроме схемы "2+2" мог работать и по схеме "3+1". В графическом
процессоре NVIDIA GeForce 8800 применяются полностью скалярные блоки,
которые работают по схеме "1+1+1+1". Теоретически, такой подход
обеспечивает большую гибкость. Что касается ROP, то они практически
остались без изменения, и у G80 их шесть штук, каждый из которых
способен обрабатывать 4 пиксела за такт (или 16 субпикселей, как
показано на рисунке - синие квадратики вблизи кэша L2), что означает
возможность обработки всего 24 пикселов за один такт в цвете и с
Z-буфером (т.е. с данными о глубине). При работе только с Z-буфером
специальная технология обеспечивает обработку до 192 самплов за такт,
при условии, что один сампл соответствует одному пикселю. При включении
4-кратного полноэкранного сглаживания возможна обработка в Z-буфере до
48 пикселей за такт. Кроме всего этого, G80 еще имеет блоки,
запускающие на исполнение данные тех или иных форматов (Vertex,
Geometry и Pixel Thread Issue). Они подготавливают данные для
числодробилки в шейдерных процессорах в соответствии с форматом данных,
текущим шейдером и его состоянием, условиями ветвлений и т.д., причем
впоследствии они будут объединены в один блок (т.е. почти как
Ultra-Threading Dispatch Processor у ATI).
Еще есть Setup/Raster/ZCull - блок, разбивающий полигоны на
пиксели. И про Input Assembler я говорили чуть выше.
Все остальное я благополучно опустил и перейду к первому
процессору
нового поколения от AMD - R600, который был разработан новоиспеченным
графическим подразделением, созданным из купленной в 2006 г. ATI.
Причем, AMD переняла от ATI ее постоянную карму – "догонять"
конкурента (вообще, у AMD и у ATI в этом смысле много общего). Так что
выхода R600 все ждали почти полгода, и как результат –
"привычное" падение продаж, потеря позиций на рынке и миллионные
убытки. Впрочем, AMD тоже не привыкать к подобным ситуациям, ведь за 30
лет своего существования она заработала в чистом виде аж целых $300
млн. Как уже было сказано выше, основные шаги к унифицированной
архитектуре ATI сделала еще в R520 (и в R500, который был первым
унифицированным процессором, отчего AMD называет R600 "архитектурой
унифицированных шейдеров второго поколения"), т.е. основные изменения
коснулись только пиксельных и вершинных блоков.
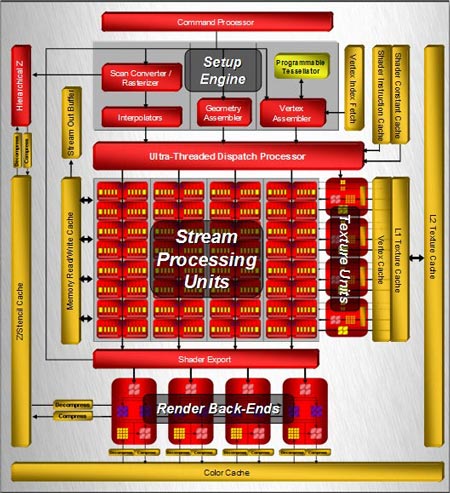 Рисунок 6- Архитектура чипа R600
Рисунок 6- Архитектура чипа R600
Итак, шейдерный
блок
состоит из 320 унифицированных суперскалярных потоковых процессоров,
которые сгруппированы в 64 блока (вычислительные единицы). Каждый из
них содержит по 5 ALU плюс блок ветвлений и условных переходов (Branch
Execution Unit), который освобождает основные ALU от этих задач и, по
идее, снижает потери от переходов на ветвящемся коде шейдера.
Согласитесь, число "320" выглядит довольно внушительно по сравнению с
"128" у NVIDIA, но сравнивать их только по числу потоковых процессоров
некорректно (хотя и по частоте они также несопоставимы, так как частота
скалярных процессоров у G80 отличается от частоты всего ядра, и при
этом она больше, чем у R600). У R600 процессоры не однородны, и в
каждом из 64 блоков только один из 5 ALU может выполнять сложные
операции (SIN, COS, LOG, EXP и т.д.). Остальным четырем под силу только
самые простые инструкции умножения или сложения (MADD), в то время как
у G80 все процессоры могут выполнять любые операции, будь-то сложные
или простые. Это влечет за собой большую производительность, как в
"чистом" виде (т.е. в гигафлопсах, которых R600 может дать только 475,
а вот из G80 в идеале можно выжать аж 518), так и в реальных
приложениях. Именно по этому Radeon HD 2900 XT позиционируется AMD как
ответ на GeForce 8800 GTS, а с 8800 GTX должен будет "драться" 2900
XTX, которого еще нет. К слову, AMD с каждым месяцем будет все сложнее
перегнать NVIDIA, так как последняя не собирается сидеть сложа руки, и
уже успела выпустить модель с суффиксом Ultra. Эта версия отличается от
GTX повышенными частотами, что, конечно же, привело к росту
производительности. Да и не стоит забывать про упорные слухи о GeForce
8800 GTX Ultra и сдвоенной 9800 GX2. Как и у
предшественников, в R600 для
распределения и хранения шейдерных инструкций применяется
Ultra-Threading Dispatch Processor, который помимо пиксельных
инструкций теперь хранит и ставит в очередь векторные и геометрические.
Что касается блоков выборки (TMU), то они также претерпели изменения,
но незначительные. Их у нас всего четыре штуки, но при этом нет большой
потери производительности. А для того чтобы не начинать отдельный
долгий разговор с пояснениями, скажу, что и у NVIDIA их немного - по
сути восемь штук. Просто мы смотрим на число выдаваемых текстур за
такт, и видим что у AMD 16 текстур с фильтрацией и 16 без, что,
конечно, намного меньше, чем у NVIDIA с ее 32 "чистыми" текстурами (по
сути, получается всего 16, поскольку фильтрация либо есть, либо ее
нет). С ROP (которые, к слову, не перетерпели больших изменений) все
так же - R600 имеет всего 4 таких блока, но они способны выдать 16
пикселов за такт (у NVIDIA, как вы помните, 6 ROP, т.е. 24 пиксела) [4].
Бурное развитие и
усложнение GPU, их растущая
производительность и простота программирования не могли не впечатлять
ценителей производительности. И первыми это подметили разнообразные
университеты и исследовательские институты, которые начали активно
работать в данном направлении примерно с 2003 г. Именно этот год можно
считать настоящим началом новой "не-игровой" жизни для GPU, так как
начиная с этого года стали появляться научные статьи, посвященные
алгоритмам и принципам расчетов общего назначения средствами
графических процессоров (GPGPU - General-Purpose Computation on GPUs).
А с 2004 г. регулярно организуются научные конференции в рамках GPGPU.
Оказывается GPU под силу не только расчет и построение игровых сцен, но
и тяжелые ресурсоемкие научные расчеты (например, расчеты синтеза
белка, коллапса сверхновой, построение нейронных сетей и т.д.). Причем,
графический процессор может выполнять их в несколько раз (до 10 и
более) быстрее, чем самый производительный и дорогой CPU. И хотя число
задач, которые под силу GPU, все-таки ограничено, оно постоянно растет
- стараниями ученых мужей, усилиями производителей видеокарт, которые
постоянно усложняют GPU, проводят различные мероприятия, семинары и
мастер-классы по программированию на GPU.
Успешные примеры "не-игрового" использования ГПУ
- CUDA
Showcase -
список приложений, использующих CUDA
(на сайте NVidia).
- RapidMind
Case Studies - примеры
использования RapidMind для программирования
ГПУ (и
не только).
- AMD
Stream Computing Blog - примеры
использования вычислительной
платформы AMD
Stream Computing для программирования ГПУ от AMD.
- Core
Image - компонент интерфейса
программирования Mac OS X,
использующий
вычислительные мощности графического процессора для отрисовки эффектов
пользовательского интерфейса.
- Windows
Presentation Foundation 3.5 SP 1 Beta 1 - версия WPF,
включающая в
себя
аналогичную технологию (только с использованием HLSL как языка
шейдеров).
Удачные сферы применения вычислительных возможностей ГПУ
- обработка сейсмических данных;
- вычислительная гидродинамика;
- компьютерное моделирование;
- получение спутниковых изображений, ГИС;
- моделирование погоды;
- вычислительные финансы;
- биоинформатика;
- молекулярная динамика;
- анализ данных;
- супервычисления [7].
Гибридные системы на
основе ГПУ
Кластерные системы,
использующие ГПУ
- Решение
астрономической задачи N тел на кластере из ГПУ (pdf).
- Exploring weak scalability for FEM
calculations on a GPU-enhanced cluster (pdf).
- Using
GPUs to Improve Multigrid Solver Performance on a Cluster (pdf).
- ClawHMMER: A Streaming HMMer-Search
Implementation (pdf).
Вычислительные
среды, использующие ГПУ
- Проект
Folding@Home
[9].
Вычислительные
библиотеки,
использующие ГПУ
- CUBLAS
и CUFFT - прикладные библиотеки, использующие CUDA для
умножения
матриц и преобразования Фурье.
- CUDA
Data-Parallel Primitives Library - библиотека
некоторых
распространенных
операций с данными, реализованных при помощи CUDA. Поддерживается
умножение
разреженной матрицы на вектор, сканирование и некоторые другие
операции.
- ACML-GPU
- процедуры математической библиотеки
AMD ACML, реализованные на
графическом
процессоре.
3 Будущее и тенденции
развития
графических процессоров
Какие то десять лет
назад компания Intel давала прогнозы, связанные с тем, что процессоры
достигнут 10 ГГц по частоте, однако судьба распорядилась иначе. Никто
не мог предположить то, что главная вычислительная мощь будет уже не
у CPU, а у видеопроцессоров. Вот так выглядит график роста
количества операций с плавающей запятой (FLOPs) у CPU и GPU за
последние десять лет [13].
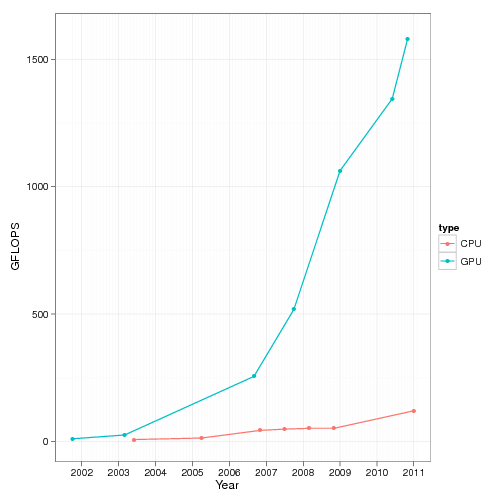
Рисунок 7 - График роста количества операций с
плавающей запятой для ЦП и ГПУ
Длительное
время основной тенденцией развития интегральных микросхем –
центральных и графических процессоров – оставалось увеличение их
скоростных показателей при однопоточном режиме работы. В течение более
чем двадцати лет такой подход позволял увеличивать производительность
микропроцессоров в среднем на 50% ежегодно. Однако такое развитие
микросхем прекратилось в 2002 году, когда на смену одноядерным и
"однопоточным" решениям пришли многоядерные процессоры для
одновременной обработки двух и более потоков команд и данных. Смена
курса позволила увеличивать производительность процессоров уже на 70%
каждый год, и в ближайшее время ситуация вряд ли существенно изменится.
Развитие тенденции увеличения количества вычислительных блоков
продолжится еще в течение нескольких лет, что приведет к появлению к
2015 году графического процессора, оснащенного сотнями тысяч ядер.
По некоторым прогнозам, к этому сроку
возможна разработка процессора с пятью тысячами вычислительных блоков,
что позволит добиться производительности в 20 ТФлопс/с. Для сравнения,
большинство суперкомпьютеров, входящих сегодня в список пятисот самых
мощных вычислительных систем в мире, обладают пиковой
производительностью в несколько десятков ТФлопс. Другими словами, один
лишь графический процессор для настольных компьютеров через несколько
лет сравняется с производительностью целого вычислительного комплекса.
Разумеется, одной из основных задач в данном случае станет
разработка
технологии изготовления столь сложных интегральных микросхем. Согласно
прогнозам, к 2015 году графические процессоры будут изготовляться по
11-нм техпроцессу, что позволит размещать на небольшом
полупроводниковом кристалле миллиарды транзисторов.
Понятно, что общеупотребимые сегодня
металлические
проводники должны уступить место более совершенным вариантам. В
частности, упоминается переход на технологию оптических межсоединений.
Можно вспомнить и последние открытия, касающиеся уникальных свойств
графеновых проводников, которые оказываются в тысячи раз лучше медных.
Впрочем, пока серьезных подвижек, говорящих о возможности скорой
коммерциализации новейших технологий, нет – разработки пока
находятся на стадии лабораторных проектов с не очень ясным сроком
выхода на мировой рынок. Ясно одно – интегральные микросхемы в
ближайшем будущем станут гораздо миниатюрнее, производительнее своих
современных аналогов. Это позволит выполнять сложные математические
вычисления на компьютере за меньшее время и предоставит возможности для
решения задач, которые до этого времени считались неразрешимыми в силу
их значительной вычислительной ресурсоемкость [11].
Заключение
Сегодня графические
процессоры
из устройств с традиционным
фиксированным набором функций конвейера трехмерной графики постепенно
превратились в гибкий вычислительный механизм общего назначения. Так же
стало популярным использование современных графических процессоров для
осуществления высокопроизводительных математических вычислений. Это
позволяет значительно увеличить скорость вычислений по сравнению с
теми, что обычно выполняются на центральном процессоре компьютера.
Ссылки
1. History of video games [Электронный
ресурс]. – Режим доступа: http://en.wikipedia.org/wiki/History_of_video_games Дата
обращения: 06.04.2011.
2.
What is CUDA? [Электронный ресурс]. – Режим доступа:
http://www.nvidia.com/object/what_is_cuda_new.html
Дата обращения: 16.04.2011.
3.
Что
такое вычисления на GPU? [Электронный ресурс]. – Режим доступа:
www.nvidia.ru/page/gpu_computing.html
Дата обращения: 11.04.2011.
4.
Графический
процессор [Электронный ресурс]. – Режим доступа: http://www.megabook.ru/Article.asp?AID=607324
Дата обращения: 24.05.2011.
5. Краткая история и основные принципы работы
3D-ускорителей [Электронный
ресурс]. – Режим
доступа: http://www.izcity.com/data/hard/article528.htm
Дата обращения: 27.03.2011.
6.
Эволюция видеокарт [Электронный
ресурс]. – Режим
доступа: http://www.overclockers.ua/video/gpu-evolution/?print
Дата обращения: 15.03.2011.
7. Графические процессоры для
высокопроизводительных вычислений [Электронный
ресурс]. – Режим доступа: http://gpu.parallel.ru/
Дата обращения: 24.03.2011.
8.
15
лет истории видеокарт в картинках [Электронный ресурс]. – Режим
доступа: http://3dtutorials.ru/novosti/895-15-let-istorii.html
Дата обращения: 05.04.2011.
9.
История
компьютерных игр [Электронный ресурс]. – Режим доступа: http://www.stainlesssteelstudios.com/62.html
Дата обращения: 30.04.2011.
10.
Как
все начиналось [Электронный
ресурс]. – Режим
доступа: http://www.stainlesssteelstudios.com/58.html
Дата обращения: 10.05.2011.
11. Графические процессоры возьмут 20 ТФлопс к
2015 году [Электронный ресурс].
– Режим
доступа: http://www.3dnews.ru/news/graficheskie_protsessori_vozmut_20_tflops_k_2015_godu/
Дата обращения: 13.05.2011.
12.
История
появления графических процессоров (Автор Виктор Скрябин) [Электронный
ресурс].
– Режим доступа: http://cgm.computergraphics.ru/issues/issue18/gpuhistory
Дата обращения: 09.04.2011.
13. Заметки на полях. Что быстрее, CPU или GPU
? [Электронный ресурс]. – Режим доступа: http://www.3dnews.ru/video/what_is_faster_gpu_or_cpu Дата
обращения: 21.04.2011.
Материалы по теме выпускной
работы: