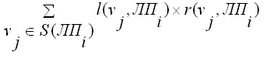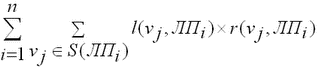|
Резюме |
| Биография |
| Библиотека |
| Ссылки |
| Отчет о поиске |
| Индивидуальный раздел |
|
||||||||||||
|
||||||||||||
|
||||||||||||
Введение |
||||||||||||
Введение |
||||||||||||
1. Актуальность работыЦифровые системы широко применяются в различных сферах промышленности, производства и управления. Важным этапом проектирования цифровых систем является моделирование их работы во времени. Большая размерность и сложность логических схем требует больших затрат вычислительных ресурсов и времени при моделировании. Увеличить производительность системы моделирования можно при использовании нескольких компьютеров, объединенных в вычислительную сеть. Моделируемая система разрезается на части, каждая из которых моделируются на отдельном компьютере, однако каналы связи, как и моделирующие процессоры, в такой вычислительной сети не являются постоянными. Например, каналы связи могут разрываться, компьютеры могут выключаться. Поэтому поддержка в системе моделирования динамической топологии графа процессоров является актуальной. 2. Цели и задачи исследованияОбъект исследования – методы и алгоритмы для динамического изменения топологии графа процессоров в распределенных вычислительных системах. Предмет исследования – оптимальная организация и свойства вычислительной сети для распределенного логического моделирования цифровых систем с динамической топологией графа процессоров. Цель исследования – организация вычислительной сети с ненадежными процессорами для распределенного логического моделирования за счёт использования алгоритмов для динамического изменения топологии графа процессоров. Задачи исследования:
3. Предполагаемая научная новизна:
4. Практическая значимость:
|
||||||||||||
Обзор исследований и разработок по теме |
||||||||||||
|
Моделирование систем с применением вычислительной техники используется в настоящее время при проектировании большинства технических устройств. В частности, при проектировании цифровых устройств моделирование их работы во времени производится как на этапе разработки, так и для верификации и тестирования. В ДонНТУ разработки, связанные с распределенным моделированием проводят Скобцов Ю.А., Фельдман Л.П., Ладыженский Ю.В. Также вопросами, связанными с распределенным логическим моделированием занимается к.т.н. Попов Ю.В. В наше время в Украине большинство университетов технического направления занимается изучением вопросами, связанными с моделированием различных систем и процессов в сферах промышленности, экономики, проектировании вычислительной техники. Моделирование как научное направление исследовалось в институте кибернетики академиком АН СССР Глушковым В.М. Работы, связанные с различными направлениями в имитационном моделировании, принадлежат таким ученым как Марьянович Т.П., Литвинов В.В., Коваленко И.Н., Калиниченко Л.А., Гусев В.В., Жук К.Д., Бакаев А.А. Распределенное моделирование как одно из направлений научных исследований начало развиваться в конце 70-х – начале 80-х годов XX века. Важнейшим этапом в разработке систем распределенного моделирования является внедрение алгоритмов синхронизации, которые необходимы для корректного выполнения процесса моделирования с одновременным использованием нескольких компьютеров в сети. Первые алгоритмы синхронизации были предложены в конце 70-х годов. Эти алгоритмы относятся к классу консервативных алгоритмов. Они описаны в работах Chandy K. M. и Misra J. (1987) и Bryant R.E. (1977). В начале 80-х годов D. Jefferson предложил Time Warp алгоритмы (алгоритмы деформации времени). Эти алгоритмы были положены в основу оптимистических алгоритмов синхронизации. Необходимо отметить также таких ученых, как Fersha A., Fujimoto R.M., которые провели много исследований и опубликовали большое количество материалов, связанных с распределенным моделированием. Динамическая топология и балансировка нагрузки в системах распределенного моделирования исследовалась такими учеными, как Theodoropoulos G., Logan B., Schlagenhaft R., Ruhwandl M., Sporrer C., Jla V., Bagrodia R. и др. |
||||||||||||
Основные результаты |
||||||||||||
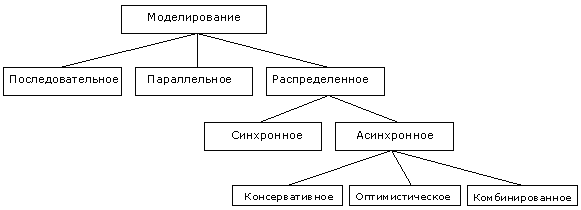
1. Исследование алгоритмов моделированияИзменения, которым подвергается система моделирования, оформляются в виде событий и состояний. Текущие значения в узлах схемы – это состояния системы, а изменения сигналов во времени – события. Моделирование выполняется в дискретном виртуальном времени [1,5,6]. Алгоритмы моделирования различаются порядком обработки и планирования новых событий [6] (см. рис. 1).
При последовательном выполнении моделирования используется один компьютер, события выполняются по одному, строго в порядке их наступления в виртуальном времени. При моделировании больших систем возникает недостаток вычислительных ресурсов, что может приводить к очень длительному выполнению моделирования [2]. Ускорение моделирования может быть получено при использовании параллельных и распределенных вычислительных систем. Предполагается, что моделирование системы на n компьютерах позволяет ускорить процесс моделирования в n раз [4]. При параллельном моделировании ускорение достигается за счёт того, что отдельные части алгоритма моделирования выполняются параллельно [1]. Моделирование выполняется на многопроцессорной вычислительной системе с общей памятью [5]. При распределенном моделировании используется несколько компьютеров, объединенных в вычислительную сеть. При этом моделируемая система разрезается на части, каждая из которых моделируется на отдельном компьютере (моделирующем процессоре – МодПр) [2]. При таком способе моделирования важно сохранение взаимосвязей между частями системы и синхронизация работы МодПр [7]. Наиболее простой способ синхронизации – использование в системе моделирования глобального виртуального времени, с которым должно совпадать локальное виртуальное время всех МодПр. Этот алгоритм распределенного моделирования является синхронным [2,5]. В асинхронных алгоритмах моделирования каждый МодПр выполняется в своем локальном виртуальном времени LVT. Поскольку LVT различается для всех МодПр, то в системе могут возникнуть события, выполнение которых невозможно. Например, могут возникнуть события, время выполнения которых уже прошло для МодПр, который должен их выполнить. Это может приводить к неверным результатам и тупикам [2]. Поэтому важным этапом в организации распределенной системы моделирования является организация корректной обработки событий во времени [1]. Консервативный алгоритм моделирования обеспечивает выполнение событий в строго хронологическом порядке. Каждый МодПр обрабатывает только безопасные внешние события, о которых известно, что не возникнет событий, время выполнения которых меньше [1]. В оптимистических алгоритмах МодПр не ожидают разрешения на обработку событий. Допустимым является появление событий в локальном прошлом, при этом производится возврат системы к предыдущему состоянию, что позволит выполнить данные события [2]. Данный подход позволяет МодПр не тратить время на ожидание друг друга, что ускоряет процесс моделирования [1,3]. Недостатком данного алгоритма является необходимость использования памяти для сохранения различных состояний системы. При использовании комбинированных протоколов МодПр обрабатывают события, запланированные на моменты времени от LVT до LVTH+∆t, где 0<=∆t<=+∞ – определяет степень оптимистичности протокола [2]. Горизонт расширения локального виртуального времени LVTH используется в консервативных алгоритмах синхронизации и является значением LVT, при котором МодПр перейдет в режим ожидания. Итак, при ∆t=0 комбинированный протокол синхронизации становится консервативным, а при ∆t=+∞ – оптимистическим [3]. |
||||||||||||
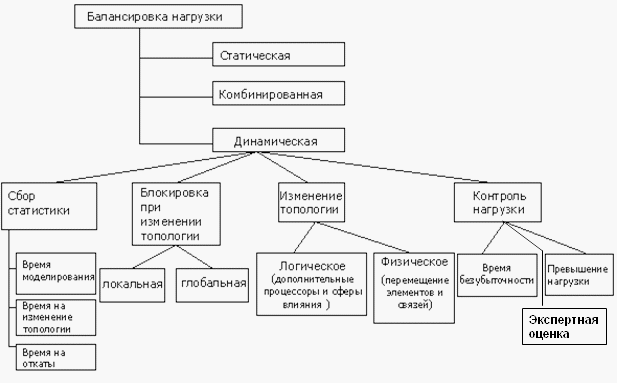
2. Классификация методов балансировки нагрузки при распределенном моделированииКлассификация методов балансировки нагрузки представлена на рисунке 2. При использовании статической балансировки нагрузки не учитываются особенности, существенно влияющие на общее время выполнения моделирования: изменение вычислительной среды, изменение доступной вычислительной мощности [10]. Для ускорения моделирования необходимо использовать динамическую балансировку нагрузки, основанную на вычислении параметров, используемых для принятия решения об изменении топологии. Комбинированная балансировка состоит из предварительного анализа моделируемой системы и механизма контроля нагрузки [9].
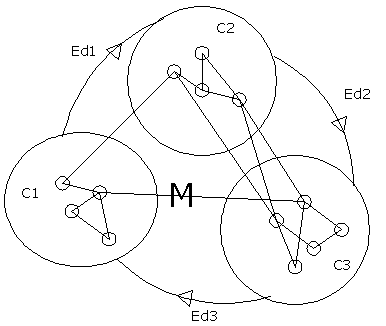
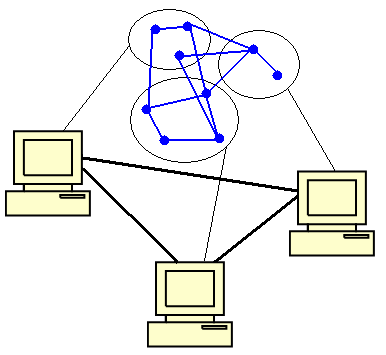
Для балансировки нагрузки характерна блокировка моделирующей системы при выполнении процедуры перераспределения. Глобальная блокировка требует приостановки моделирования на всех логических процессорах. Это может приводить к простою отдельных МодПр и нерациональному использованию вычислительных ресурсов. Локальная блокировка подразумевает, что моделирование приостанавливается только на тех процессорах, которые непосредственно участвуют в перераспределении. Возможность выполнения только локальных блокировок без необходимости глобальной блокировки всех процессоров предоставляется для архитектуры вычислительной сети, использующей коммуникационные логические процессоры [8]. Изменение топологии на физическом уровне представляет собой перемещение частей моделируемой системы с одного моделирующего процессора на другой. Применение данного метода описано в [9, 10]. Например, система распределённого моделирования Triad.Net [9] организована так, как изображено на рисунке 3.
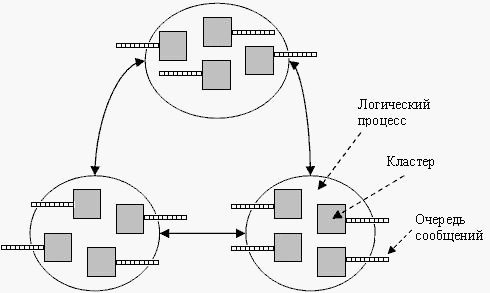
Подсистема балансировки определяет загруженность процессоров, на которых выполняется моделирование, загруженность линий связи, частоту обменов между моделируемыми объектами. На основании анализа этих сведений подсистема балансировки, не прерывая процесс моделирования, выполняет перераспределение объектов моделируемой системы по вычислительным узлам [9]. В [10] предлагается два метода, позволяющих ускорить процесс моделирования: мультикластерное представление моделируемой части схемы (см. рис. 4) на ЛП и динамическая балансировка нагрузки, основанная на перемещении кластеров в процессе моделирования с целью получения равномерной загрузки на все МодПр.
В [10] для получения равномерной загрузки МодПр предлагается механизм перемещения кластеров. Перемещения некоторого кластера на другой МодПр выполняется в такой последовательности [10]:
Изменение топологии на логическом уровне используется в подходе, описанном в [8]. Согласно этому методу, каждый логический процессор выполняет моделирование части системы в своей сфере влияния. Управлением сферами влияния руководят специальные коммуникационные логические процессоры (КЛП). Связь между ЛП отсутствует, данные между ними могут передаваться только через соответствующий КЛП. Если, например, необходимо передать данные между двумя ЛП, которые не связаны одним КЛП, то данные будут передаваться вверх по дереву связей КЛП [8]. В процессе моделирования производится сбор статистики: между какими группами ЛП происходит наиболее частый обмен данными, тогда для них можно добавить отдельный КЛП, что уменьшит нагрузку на остальные КЛП. Контроль нагрузки производится на основании значения общей стоимости доступа всех процессоров друг к другу для конкретного варианта распределения их сфер влияния [8]. Изменения состояния узлов схемы оформляется в виде событий. Поэтому некоторый узел схемы vj – это часть сферы влияния событий. Логический процесс ЛПi путем передачи сообщений о событиях может влиять на vj. Пусть ранг переменной vj для процесса ЛПi – это количество событий, приходящих от ЛПi и изменяющих значение переменной vj в интервале времени [t1; t2] [8]. Стоимость доступа логического процессора ЛПi к переменной vj (ранг vj для ЛПi – r(vj, ЛПi)) – это количество КЛП, которые должны быть пройдены, чтобы достигнуть изменения vj в интервале времени [t1;t2]. Стоимость обращения к локальным переменным l(vj, ЛПi) в собственном КЛП равна 0 [8]. Стоимость доступа некоторого ЛП ко всем переменным в сфере влияния S(ЛПi) определяется по формуле (1) [8]:
Общая стоимость доступа ко всем ЛПi, i=1..n всех ЛП конкретного распределения в интервале времени [t1;t2] определяется по формуле (2) [8]:
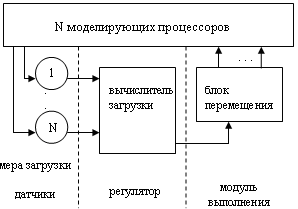
Наилучшей декомпозицией в интервале времени [t1;t2] является та, при которой общая стоимость является минимальной. Задача каждого КЛП – приближение общей стоимости доступа всех логических процессоров к минимальной [8]. Механизм контроля нагрузки, характерный для динамической балансировки нагрузки, описан в [10]. Он реализован в виде алгоритма в главном контролирующем процессе (см. рис. 5).
В процессе моделирования производится расчёт некоторых величин, позволяющих судить о текущей загрузке на ЛП: виртуальное время продвижения и время безубыточности [10]. |
||||||||||||
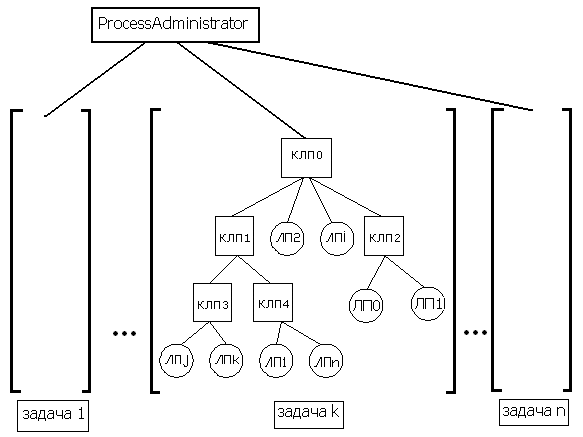
3. Описание архитектуры вычислительной сетиМоделирование производится с использованием нескольких процессоров, объединенных в вычислительную сеть (см. рис. 6).
В разработанной системе используется модификация предложенного в [8] подхода к организации моделирующей системы на основе управления сферами влияния. Моделируемой системой является класс цифровых логических схем. Данные о моделируемой системе представляются в виде структурно-функциональной модели схемы. В системе моделирования содержатся:
Администратор процесса моделирования предназначен для управления размещением задач моделирования на моделирующих процессорах (ЛП и КЛП) и регистрации доступных для моделирования процессоров. При изменении топологии моделирующей системы он может перераспределять выполняемые задания, используя эти сведения. Логические процессоры выполняют моделирование части схемы, входящей в их сферу влияния. Логический процессор содержит список событий EVL, виртуальные часы VT, структурно-функциональную модель схемы (SFSM) и перечень тех узлов, которые он должен моделировать (свою сферу влияния). Коммуникационные логические процессоры используются для обеспечения связи между логическими процессорами, непосредственно выполняющими моделирование. Для поддержания нагрузки процессоров в сбалансированном состоянии КЛП выполняют сбор статистики при моделировании и принимают решение о перераспределении сфер влияния между подчиненными ЛП. Поэтому КЛП содержит описание всей SFSM, данные о сферах влияния всех подчиненных ему ЛП. Коммуникационные логические процессоры используются для обеспечения связи между логическими процессорами, непосредственно выполняющими моделирование. Для поддержания нагрузки процессоров в сбалансированном состоянии КЛП выполняют сбор статистики при моделировании и принимают решение о перераспределении сфер влияния между подчиненными ЛП. Поэтому КЛП содержит описание всей SFSM, данные о сферах влияния всех подчиненных ему ЛП. С учетом приведенного описания структура системы моделирования представлена на рис. 7:
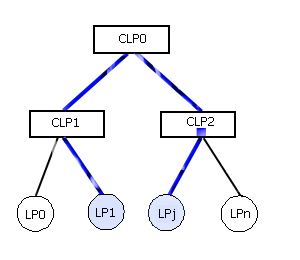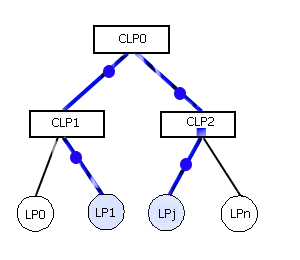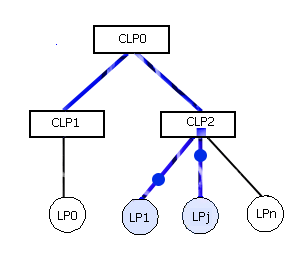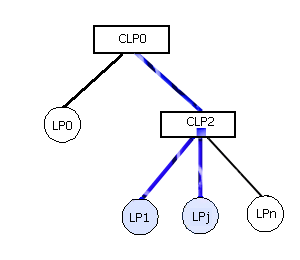
Моделирование одной цифровой логической схемы представляет собой одну задачу моделирования. Для загрузки задач для выполнения используется проект администратора процесса моделирования в виде файла [3]. Для выполнения каждой задачи администратор процесса моделирования выделяет вначале один главный КЛП (см. рис. 7). Далее на главный КЛП загружается вся моделируемая задача (СФМС, входное воздействие), после чего для данного КЛП выделяются подчиненные ЛП. При моделировании на основании текущей загрузки подчиненных процессоров каждый КЛП может принимать решение о необходимости выделения ему дополнительных ЛП, которые не заняты и о перераспределении сфер влияния между ними. При выявлении групп ЛП, между которыми производится наиболее частый обмен сообщениями возможно выделение для них отдельного КЛП с целью уменьшения нагрузки на остальные КЛП (см. рис. 8)
Принятие решения об изменении топологии моделирующей системы принимается на основании параметров, предложенных в [2] и описанных в п.2. |
||||||||||||
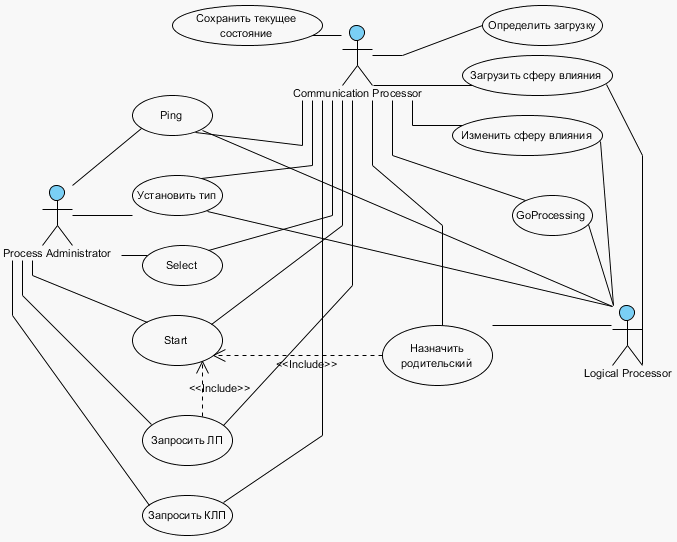
4. Разработка программной системыПри разработке программной системы для распределенного логического моделирования цифровых систем была определена архитектура вычислительной сети. На основании разработанной архитектуры разработана программная система. Описание программной системы выполнено с использованием UML-диаграмм. Определим основные требования, предъявляемые к системе в виде диаграммы прецедентов (см. рис. 9).
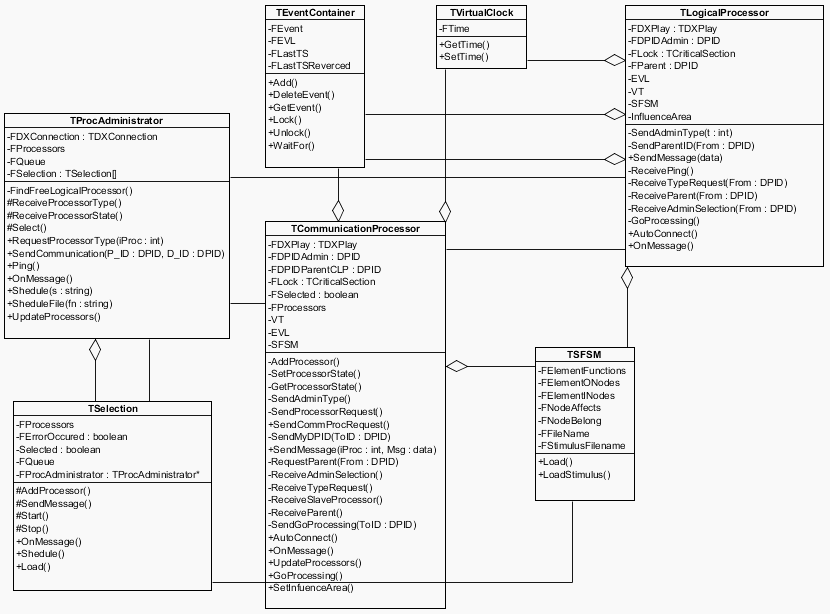
Как показано на рисунке 9, основными исполнителями в системе является администратор процесса моделировании Process Administrator, коммуникационные логические процессоры Communication Processor и логические процессоры, выполняющие моделирование (Logical Processor). Данные исполнители в системе могут выполнять ряд действий, оформленных в виде прецедентов. В основном функционирование объектов в системе сводится к передаче и приему сообщений различных типов. На основании требований, предъявляемых к системе, определим диаграмму классов (см. рис. 10).
Диаграмма классов показывает организацию моделирующих процессоров в системе (ЛП и КЛП). Они содержат виртуальные часы TVirtualClock, список событий TEventContainer. Структурно-функциональная модель схемы (класс TSFSM) входит в задачу, которая представлена в классе TSelection. Коммуникационный логический процессор содержит сведения о подчиненных ему процессорах в виде массива структур FProcessors. Эти сведения обновляются в зависимости от изменения числа доступных процессоров в методе UpdateProcessors. Также в рамках его методов ведется сбор данных о текущей интенсивности обмена сообщениями между подчиненными процессорами. |
||||||||||||
Выводы | ||||||||||||
|
В магистерской работе получено новое решение актуальной задачи моделирования цифровых систем с использованием распределенной вычислительной сети с динамической топологией, ненадежными процессорами и каналами связи. В результате исследований получены следующие основные результаты:
В дальнейшем планируется проведение экспериментального и теоретического исследования свойств разработанной вычислительной сети для распределенного логического моделирования цифровых систем. |
||||||||||||
Литература |
||||||||||||
|
||||||||||||
Важное замечание При написании данного автореферата магистерская работа еще не завершена. Предположительная дата завершения – |
||||||||||||
|
||||||||||||
Copyright © Балута Анжелика, ДонНТУ, 2011 |