УДК 004.8
Семантический анализ естественных языков и его приложения
Шатохин Н.А. E-mail: n.shatokhin@gmail.com
Донецкий национальный технический университет
ВведениеВ связи со стремительным развитием сети Интернет, возникла необходимость быстро находить хранящуюся в ней информацию. Обычно, поиск производится с помощью поисковых серверов. Однако, существующие системы недостаточно совершенны. Алгоритмы, лежащие в их основе, базируюся на принципе сравнения образцов. Чем большей длины образец был найден, тем лучше считается поиск. При таком подходе выдается множество ссылок на случайную информацию или не соответствующую теме поиска. Для улучшения качества поиска необходимо применять методы, позволяющие определить идентичность темы, заданной для поиска, и содержания аннотации найденной информации. Эта задача может быть решена с помощью методов, используемых для анализа естественного языка. Описанию соответсвующих методов и программных средств посвящена настоящая статья.
Смысл и значение в естественном языкеВ лингвистической семантике слову “смысл” соответствуют два близких, но различных понятия. В первом случае под семантикой понимается значение — информация, связываемая со словом конвенционально (например, в толковом словаре), во втором — смысл — совокупность ассоциаций и коннотаций, связываемых со словом в сознаниях коммуникантов. Хотя каждая из этих двух ипостасей с равным правом претендует на то, чтобы быть предметом семантики, здесь мы зафиксируем первое понимание. Тогда основная цель семантического анализа — переход от значения отдельных слов к значению высказываний.
Работы в области семантического анализа ведутся достаточно давно как отечественными, так и зарубежными специалистами. По-видимому, в числе первых следует указать работы Хомского (1957), в которых предполагалась трансформационная грамматика, целями которой было: построение глубинной синтаксической структуры; запись значений каждого предложения; обнаружение семантических аномалий.
Можно назвать и Кембриджский лингвистический кружок (1959), в котором был предложен некоторый язык-посредник, который должен отождествлять семантически эквивалентную информацию и снимать межъязыковую синонимию.
Ч. Филмор в 1996 году предложил так называемые предикатно-аргументные структуры, в которых языковым инструкциям (аргументам) приписывались роли: агент, объект, место, адресат, инструмент, источник.
Важной вехой в исследовании семантики естественного языка явилась Модель «Смысл-Текст» (Мельчук, 1974), в которой выбор значений определялся максимальной повторяемостью семантических элементов в пределах предложения.
Монтегю принадлежат попытки «логизирования» семантики высказывания; при этом значения высказывания рассматриваются как истинностные значения.
В отличие от этого, предлагаемый здесь подход опирается, с одной стороны, на синтаксис русского языка [1], с другой — на теорию неоднородных семантических сетей [2].
Описание используемой моделиКаждое предложение состоит из различных классов слов — частей речи. В зависимости от семантики каждого члена предложения, а также отношений между ними, все предложение может иметь тот или иной смысл. Следовательно, чтобы определить значение всего предложения, необходимо определить значение, каждого его члена и их взаимодействие друг с другом.
Опишем алгоритм действий.
Шаг 1. Морфологический анализ. На этом этапе в тексте распознаются слова и разделители. При этом сложные предложения разбиваются на несколько простых. Тип связи между ними запоминается.
Шаг 2. Синтаксический анализ. На этапе синтаксического анализа предложение разбирается по составу — в нем выделяются подлежащее, сказуемое и второстепенные члены. Также определяется к какой части речи относится каждый из членов. Для этого используется словарь — структура вида:
Таблица 1
Словарь
| Слово | Часть речи | С какими частями речи способно взаимодействовать | Позиция | Дополнительно |
Здесь,
Позиция — где располагается слово, относительно связанного с ним (спереди, сзади, где-угодно),
Дополнительно — дополнительные свойства слова, например, род, множественное или единственное число и т.п.
Шаг 3. Семантический анализ. На этом этапе определяется значение каждого из простых предложений. Зная, как они были связаны в сложном, можно определить семантику исходного текста. Для этого можно использовать исчисление высказываний.
Этап семантического анализа делится на три подэтапа.
Шаг 3.1. Реляционный анализ. С помощью словаря определяются отношения между членами предложения. Для этого берется самое левое слово и по словарю определяется что это за часть речи и с какими членами оно может состоять в отношениях. Если возможное отношение всего одно, либо его можно определить с помощью поля «Позиция», то данное отношение сохраняется и осуществляется переход к следующему слову. Иначе используются дополнительные свойства.
Шаг 3.2. Построение семантической сети. Зная отношения между всеми членами предложения, строим граф, в котором в качестве вершин будут записаны слова, а каждое ребро будет соответствовать определенному отношению.
Шаг 3.3. Определение семантики предложения. Имея семантическую сеть, можно перевести входное предложение в запрос понятный машине.
Рассмотрим действие алгоритма над предложением «Когда прошли первые Олимпийские игры?»
Это предложение простое, разбивать на части его не нужно. На первом шаге выделяем в предложении отдельные слова. На этапе синтаксического разбора выделяем подлежащее и сказуемое. Предположительно, подлежащее - это существительное в именительном падеже. Здесь подлежащее Олимпийские игры — поскольку это термин, то в словарь его лучше занести, как одно слово. Пытаемся найти сказуемое. Предположительно это должен быть глагол, множественное число. Сказуемое — прошли.
Определяем отношения между членами предложения. Берем первое слово — когда. Это временной союз, который определяет время действия, описываемого глаголом. Единственный глагол здесь — прошли. Это сказуемое, определяет действие совершенное подлежащим — Олимпийские игры. Берем третье слово — первые. Это числительное множественного числа, которое может относится только к существительному множественного числа. Здесь это — Олимпийские игры.
Все связи определены, строим семантическую сеть.
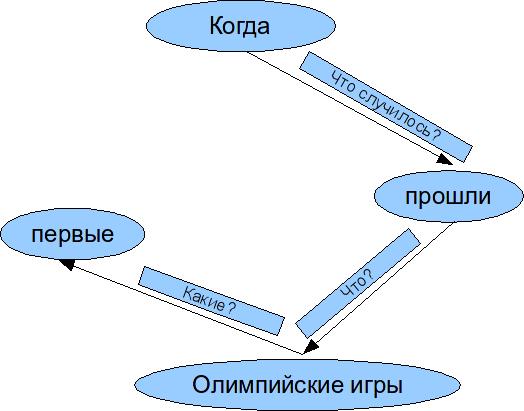
Рис. 1. Семантическая сеть
Сеть построена. Теперь можно попытаться составить запрос. Зная смысл каждого слова, лежащего в вершине семантической сети, можно определить смысл всего предложения. Узел когда говорит о том, что пользователь хочет узнать дату. Узел прошли — что дату проведения. Узел Олимпийские игры — что дату проведения Олимпийских игр. И, наконец, узел первые — что дату проведения первых по счету Олимпийских игр.
На MySQL этот запрос мог бы выглядеть так:

Рис. 2. SQL-запрос
Создание справочных систем в различных предметных областяхОдним из возможных применений изложенных соображений является создание и использование справочных систем.
Справочная система (СС) — программа, предназначенная для получения пользователем максимально точной информации по интересующей его теме. СС содержит базу знаний и способна осуществлять поиск в ней по заданным пользователем параметрам.
Наполнение базы знаний может происходить в автоматическом режиме. Специальный модуль способен по расписанию открывать указанные источники (это могут быть, например, сайты журналов по требуемой тематике или энциклопедии) и загружать статьи в базу.
Существует несколько способов получить доступ к данным, хранящимся в базе знаний. Пользователь может ввести конкретный вопрос на естественном языке и получить короткий ответ на него, либо задать обобщенный и система выдаст полный текст статьи. Кроме того, можно также воспользоваться электронным каталогом.
Электронный каталог — это систематизированное описание хранящихся в системе статей. Обычно каталог представляет собой иерархическую или сетевую структуру рубрик, каждая из которых содержит описания статей, соответствующих данной рубрике, и ссылки непосредственно на сами статьи.
Рубрики каталога могут создаваться по полям статьи, например по авторам, или по названиям изданий, но возможно и создание тематических каталогов, где рубрики соответствуют темам в предметной области. Тематические каталоги разбивают все статьи справочной системы на множества (возможно, пересекающиеся) тематически близких статей, что может использоваться при поиске и навигации.
ЗаключениеПрименение семантического анализа есественных языков позволяет повысить качество поиска информации. Способность системы понимать запросы, сформулированные в виде обыкновенных вопросов, и давать на них короткие ответы сокращает время на получение полезной информации, избавляя пользователя от необходимости самостоятельно перечитывать текст статьи.
Литература- Валгина Н. С. Синтаксис современного русского языка: Учебник. — М.: Агар, 2000. — 416с.
- Осипов Г. С. Приобретение знаний интеллектуальными системами: Основы теории и технологии. — М.: Наука, 1988 — 440 с.
- Шатохин Н. А., Дмитриева О. А. Семантический анализ информации и обработка естественных языков. // Сборник материалов пятой всеукраинской научно-технической конференции студентов, аспирантов и молодых ученых КМИТ-2009 — Донецк, ДонНТУ — 2009. — с. 258-259
- Шатохин Н. А., Дмитриева О. А. Семантический анализ информации. // Сборник материалов четвертой международной научно-технической конференции студентов, аспирантов и молодых ученых ИКТ-2008 — Донецк, ДонНТУ — 2008. — с. 350-353
- Г. С. Осипов, И. В. Смирнов, И. А. Тихомиров, Реляционно-ситуационный метод поиска и анализа текстов и его приложения / Г. С. Осипов, И. В. Смирнов, И. А. Тихомиров / Искусственный интеллект и принятие решений. — 2008. — № 2. — с. 3-10
