1 Введение
Много современных веб-сайтов используют веб-рекомендации для увеличения удобства пользования, удовлетворенности потребителя и коммерческой прибыли. Много алгоритмов были разработаны для генерации рекомендаций, применяя различные подходы статистического анализа данных к некоторой доступной им информации, например на характеристиках текущей страницы, продукта, веб-пользователя и т.д. [5, 9] Однако, до сих пор никакой алгоритм не использует преимущества всех доступных источников знаний и никакой алгоритм не имеет превосходства над всеми другими. Поэтому, потребность в гибридных подходах, которые комбинируют преимущества разных алгоритмов, была очевидна [5].
В этой статье мы представляем новый подход, способный к объединению многих рекомендованных алгоритмов. Наш подход использует центральную базу данных рекомендаций для того, чтобы сохранить рекомендации, прибывая из различных алгоритмов и применяет методы обучения, чтобы непрерывно оптимизировать сохраненные рекомендации. Оптимизация рекомендаций основана на том, как они полезны пользователям и веб-сайту, то есть как охотно пользователи щелкают по ним или сколько прибыли они приносят. Стимул для нашего подхода оптимизации был наблюдением, что популярность и уместность отдельных рекомендаций не всегда хорошо предсказывается системами рекомендаций. Информация о веб-сайте и пользователях представляется в базе данных рекомендаций в форме графов онтологии. Это позволяет нам семантически обогащать рекомендации и вводить знание из дополнительных источников. Это также помогает для адаптации системы к различным типам веб-сайтов. Предварительная версия архитектуры была коротко изложена в [7]. В текущей статье мы описываем архитектуру прототипных реализаций системы и представляем результаты оценки.
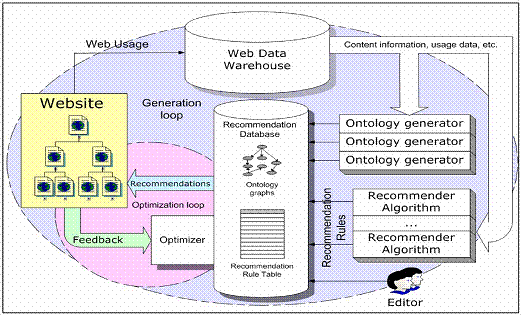
Рис.1. Архитектура системы рекомендаций.
Мы реализовали прототип нашей системы на двух веб-сайтах: веб-сайт Database Group, университет Лейпцига http://dbs.uni-leipzig.de и интернет-магазин программного обеспечения http://www.softunity.com. Чтобы обозначить источник примеров и понятий в статье, мы отмечаем их или с EDU (образовательным) для веб-сайта Database Group или с EC (электронная коммерция) для www.softunity.com.
В следующем разделе мы объясняем архитектуру системы и ее основных компонентов. Раздел 3 описывает выбор рекомендаций, используя графы онтологии и правила рекомендаций. В Разделе 4 мы объясняем системы рекомендаций и генерацию рекомендаций. Методы оптимизации представляются в Разделе 5. Раздел 6 содержит оценки реальных экспериментальных данных. В Разделе 7 мы обеспечиваем краткий обзор связанной работы. Раздел 8 суммирует бумагу.
Краткий обзор архитектуры
Архитектура нашей системы рекомендаций изображена на Рис. 1. Веб-сайт взаимодействует с веб-пользователем, предоставляет рекомендации и учитывает ответную реакцию. Веб-хранилище данных хранит информацию о контенте веб-сайта (например, продукты и каталог продукции, страницы HTML, и т.д.), пользователях и журналах использования, сгенерированных веб-сервером или сервером приложений. Это служит источником информации для системы рекомендации алгоритмов, генераторов онтологии и позволяет оценивать OLAP данные использования и эффективности рекомендаций. База данных рекомендации хранит семантическую информацию в форме трех направленных нециклических графиков онтологии (для контента веб-сайта, веб-пользователей и времени) и рекомендации в форме правил, которые описываются в следующем разделе. Набор генераторов онтологии ответственен за генерирование графов онтологии. Набор алгоритмов генерирует рекомендации, используя данные от веб-хранилища данных. Графы онтологии и правила рекомендации могут также быть созданы и отредактированы вручную. Оптимизатор совершенствует базу данных рекомендации, основанную на обратной связи, полученной от веб-сайта, используя обучение. В нашей системе рекомендации мы отличаем цикл генерации и цикл оптимизации. Цикл генерации выполняется равномерно. Это включает генерирование/обновление онтологии и правил рекомендации, использующих информацию о контенте и недавнюю информацию об использовании от веб-хранилища данных. Цикл оптимизации выполняется непрерывно, выбирает и представляет рекомендации из базы данных. Кроме того, учитывается обратная связь, то есть пользовательские реакции на представленные рекомендации. Оптимизатор использует эту информацию, чтобы совершенствовать рекомендации в базе данных и влиять на выбор будущих рекомендаций.
Выбора рекомендации основанный на графе онтологии
Рис. 2 показывает выбор рекомендаций, используя графы онтологии. Чтобы запросить рекомендации: веб-сайт определяет текущий контекст веб-сайта и требуемое число рекомендаций. Контекст веб-сайта является рядом параметров, которые характеризуют в настоящий момент просматриваемый контент веб-сайта, текущего веб-пользователя и момент времени. Пример контекста веб-сайта дается ниже:
WebsiteContext {ProductID =. ECD00345.; UserCountry =. DE.; UserOperatingSystem =. Windows.; Дата =.21.03.2005.;...} (EC).
Очевидно, выбор подходящих параметров в контексте веб-сайта зависит от определенного веб-сайта, особенно относительно текущего контента. Система рекомендации отображает обеспеченный контекст веб-сайта в семантический контекст, который состоит из узлов трех графов онтологии {ContentNodes, User-Nodes, TimeNodes}. Используя политику выбора, рекомендации, связанные с соответствующими узлами графов онтологии, выбираются и наконец представляются. Этот двухступенчатый процесс выбора стремится поддерживать прикладную рекомендацию имеющую высокую гибкость. Присвоение рекомендациям семантических понятий, как ожидают, будет более устойчивым, чем прямое использование низкоуровневых контекстов веб-сайта, значения которых могут часто изменяться (например, из-за реструктурирования веб-сайта).
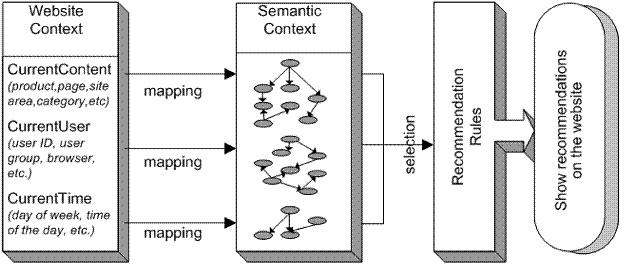
Рис.2. Выбор рекомендаций используя семантический контекст.Рис. 3 показывает пример графа онтологии для контента веб-сайта. Графы онтологии для веб-пользователей и времени создаются похожим способом. Мы используем ориентированные ребра, чтобы следовать от более определенных понятий до более общих, от субкомпонентов до агрегированных компонентов, и т.д. Рекомендации могут быть присвоены любому узлу в таком графе. Выделенный с толстыми строками в Рис. 3 пример того, как семантика, сохраненная в графе онтологии, может использоваться, чтобы искать дополнительные рекомендации для Product4. Мы в состоянии получить рекомендации непосредственно для Product4, также рекомендации, которые связываются с некоторым общим свойством, которым Product4 обладает (в нашем случае) и рекомендации некоторым темам каталога продукции, где Product4 является частью (История, Книги).
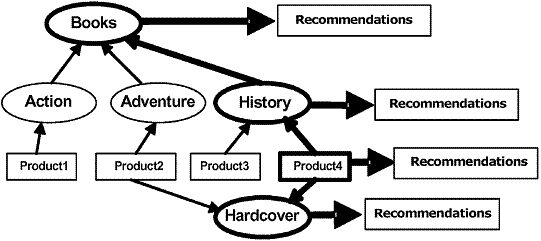
Рис. 3. Демонстрационный граф онтологии для размерности контента (EC)Отображение между веб-сайтом и семантическими контекстами определяется, отображая пункты, которые являются операторами, записанными на простом языке предиката. Язык предиката поддерживает логические операторы (AND, OR, NOT), операторы сравнения (<>, =, <>>, =, <=) и оператор LIKE, который действительно представляет соответствие в виде строки с подстановочным знаком, подобным оператору SQL с тем же самым именем. Некоторые из узлов в графах онтологии сразу соответствуют определенному набору параметров и могут быть отображены, используя отображающиеся пункты. Другие представляют абстрактные понятия и могут быть достигнуты только, пересекая граф онтологии и иметь не связанные отображающиеся пункты. Графы онтологии автоматически сгенерированы генераторами онтологии и могут быть отредактированы вручную редакторами веб-сайта. Каждый из трех графов онтологии отображается отдельно. В нашем приложении EC графики онтологии создаются генераторами онтологии, используя каталог продукции, общие свойства продуктов и бизнес-логику веб-сайта. Приложение EDU использует вручную указанную иерархию контента веб-сайта и группы пользователей, определенные анализом данных (алгоритм дерева решений J48). Большинство отображающихся пунктов автоматически определяется генераторами онтологии вместе с созданием онтологии и просто использует оператор равенства. Вручную указанные пункты отображения могут быть более сложными. Примеры отображающихся пунктов:
ProductID=.ECD00345. -> ContentNode=1342 (EC)
UserCountry=.DE. -> UserNode=3 (EC)
UserDomain LIKE .%.edu. OR UserDomain LIKE .%uni-%. -> UserNode =2
(EDU)
Рекомендации, связанные с узлами в графах онтологии, представляются правилами, сохраненными в базе данных рекомендации. У правил рекомендации есть форма:
RuleContext{Content,User,Time} -> RecommendedContent, Weight
RuleContext обращается к узлам к одному или нескольким из трех графов онтологии. Эти значения могут также быть, устанавлено в NULL, обозначая, что правило не зависит от соответствующей размерности. RecommendedContent является указателем на рекомендуемый контент, например, рекомендуемый продукт или URL. Weight используется в качестве критерия для выбора правил рекомендации для представлений. Мы реализовали несколько политик для того, чтобы выбрать узлы графов онтологии и таким образом выбрать связанные рекомендации. Эти политики включают: ?прямое соответствие, прямое + наследование ? и ?комбинированное. Прямое соответствие, производится выбор рекомендации, используя только соответствующие узлы, руководствуясь отображающимися пунктами. Политика ?прямое + наследование использует? эти узлы так же как все их родители в графиках онтологии. В комбинированной ? политике соответственно применяется прямая политика, если эта политика неспособна возвратить требуемое число рекомендаций, применяется политика наследования. После того, как текущий семантический контекст устанавливается, выбирая узлы в графах онтологии, мы используем следующий общий SQL-запрос, чтобы выбрать рекомендации из таблицы правил базы данных рекомендаций:
SELECT TOP N RecomNode From Rules WHERE
(ContentNode in (CurrentContentNode1, CurrentContentNode2,?) OR
ContentNode is NULL) AND
(UserNode in (CurrenUserNode1, CurrentUserNode2,?) OR
UserNode is NULL) AND
(TimeNode in (CurrentTimeNode1, CurrentTimeNode2,?) OR
TimeNode is NULL)
ORDER BY Weight DESC
Мы упорядочиваем рекомендации и возвращаем требуемое число рекомендаций с самым высоким весом.
Правила Рекомендации Создания
Правила рекомендации сгенерированы алгоритмами системы рекомндаций и сохранены в базе данных. Алгоритм рекомендации может также предоставить начальный вес для каждого сгенерированного правила рекомендации от интервала [0.. 1]. В прототипной реализации мы определяем рекомендации продукта:
1. Подобие контента. Этот алгоритм рекомендации определяет для каждого продукта (EC) или страницы HTML (EDU) (узел контента) М. подобных продуктов, используя текстовый счет подобия TF/IDF.
2. Образцы последовательности. Продукты (EC) или страницы HTML (EDU), чаще всего следующие за другими продуктами/страницами в тот же сеанс пользователя, рекомендуются им.
3. От элемента к элементу совместная фильтрация. (EC) Продукты, которые чаще всего появляются вместе в одной пользовательской корзине, рекомендуются друг для друга.
4. Поисковая система алгоритма рекомендации (EDU). Этот алгоритм рекомендации применим к пользователям из поисковой системы. Это извлекает поисковые ключевые слова из поля Referrer HTTP и использует внутреннюю поисковую систему, чтобы генерировать рекомендации для каждого ключевого слова. Алгоритм рекомендации был описан и реализован в [17].
Если алгоритмы рекомендации генерируют правило, которое уже существует в таблице правила рекомендаций с различным весом, вес в таблице берет предпочтение по весу, предоставленному данным алгоритмом. Мы исследовали два подхода к установке начальных весов недавно сгенерированных правил рекомендаций. В первом подходе мы просто обнуляем все начальные веса (ZeroStart). Второй использованный подход нормализует рекомендованные специфичные веса или относительные приоритеты для соответствующих контекстов. Когда несколько алгоритмов рекомендаций генерируют ту же самую рекомендацию, мы используем максимум их весов. Начальные веса, как ожидают, будут важны прежде всего для новых рекомендаций, так как веса для представленных рекомендаций непрерывно адаптируются.
Оптимизация основанная на обратной связи
Цель нашей оптимизации состоит в том, чтобы скорректировать веса правил рекомендации таким способом, что более полезные рекомендации показывают чаще, чем менее полезный. В наших приложениях мы определяем утилиту через пропускную способность рекомендаций:
AcceptanceRate=Nclicked / Npresented,
где Nclicked является числом щелчков по рекомендации , а Npres является числом раз, когда рекомендация была представлена. Однако, наш алгоритм оптимизации также в состоянии работать с утилитой, определенной иначе, например как оборот продаж или прибыль, принесенная рекомендацией. Каждый раз, когда веб-пользователь запрашивает веб-страницу с рекомендациями, несколько правил рекомендаций из базы данных выбираются и показываются. Мы называем такое событие представлением. Веб-пользователь тогда может предпринять некоторые меры относительно представленных рекомендаций. Например, пользователь может щелкнуть по рекомендации, купить рекомендуемый продукт, или проигнорировать рекомендацию. Каждому из этих действий соотносится действительное значение с данным, названным обратной связью. Оптимизатор оценивает все представления и корректирует веса участвующих правил рекомендациий согласно полученной обратной связи. Новые правила рекомендаций могут быть добавлены в базу данных в любое время. И онлайновая и офлайновая оптимизация возможна. Есть два ключевых аспекта, которые должны учитываться в нашем алгоритме оптимизации. Во-первых, утилита отдельных рекомендаций может измениться в течение долгого времени, из-за различных интересов веб-пользователей. Алгоритм оптимизации должен быстро реагировать на существенные изменения в пользовательских интересах, не слишком остро реагируя на краткосрочные колебания. Кроме того, мы обращаем внимание на исследование и использование. С одной стороны мы хотели бы представить рекомендации, которые являются преимущественно полезными согласно нашим современным знаниям. С другой стороны, мы хотели бы учесть насколько хороши другие рекомендации, для которых наших современных знаний недостаточно [16, 8]. В следующих подразделах мы обсуждаем эти аспекты более подробно.
Тенденции интереса.
Мы можем обработать тенденцию интереса несколькими способами:
- полагая, что более старая обратная связь и более новая обратная связь одинаково важны (никакого старения). В этом случае, вес правила рекомендации равен пропускной способности рекомендации и тенденция интереса не принимается во внимание.
- хранят последние n значения обратной связи для каждой рекомендации, управляют и генерируют веса правил рекомендации от них. Этот подход, однако, требует дополнительной памяти в случае онлайновой оптимизации.
- использование устаревающего деления (также названный экспоненциальным сглаживанием). Здесь, с каждым представлением исходный вес правила рекомендации уменьшается частью его значения:
Q (r) = (1-1/T) *Q (r) + Feedback(r) / T.
В этой формуле Q (r) является весом правила r рекомендации,Т стареющий параметр (T> 1). Обратная связь является численным значением, которое описывает пользовательский ответ на представление данной рекомендации. Умножение веса (1-1/T) реализациями старения, начиная с этого способа, которым последние представления оказывают большое влияние на получающееся значение веса, в то время как содействие прошлых представлений уменьшается по экспоненте с каждым следующим представлением. Точное значение параметра T должно быть определено экспериментально, в зависимости от того, насколько динамичные пользовательские интересы для веб-сайта.
Сравнение исследования и использования
Мы исследовали два метода балансирования между исследованием и эксплуатацией. В методе для награды, компромиссом между исследованием и эксплуатацией устанавливается статический параметр ?. С вероятностью (1-?) метод выбирает лучшие рекомендации согласно их весам. С вероятностью ? выбирает случайные рекомендации для представления, чтобы дать им шанс, который будет исследоваться. Этот метод также вызывают ? - жадный в литературе [16]. Преимущество этого метода является очень простым и понятным управлением эксплуатацией по сравнению с исследованием. Недостаток - то, что это исследует все рекомендации с равной вероятностью, не принимая во внимание, как они были обещаны. Значения обратной связи (r) для этого метода следующие:
1, если по рекомендации r щелкнули
0, если по рекомендации r не щелкнули
В методе штрафа награды балансирование между исследованием и эксплуатацией делается, динамически используя негативные отклики. Когда по некоторой рекомендации r в представлении щелкают, r получает позитивные отклики, все другие рекомендации получают негативные отклики. Когда ни по какой рекомендации не щелкают, после предопределенного тайм-аута все участвующие рекомендации получают негативные отклики. Чтобы препятствовать тому, чтобы веса скользили в экстремумы, значения обратной связи должны быть выбраны таким способом, что для любого данного контекста приблизительное равновесие сохраняется в течение процесса:
? (позитивные отклики) ?. ? (негативные отклики)
Например:
1, если по рекомендации r щелкнули
-p, если по рекомендации r не щелкнули
где p является вероятностью, что по рекомендации щелкают, усредняется по всем представлениям рекомендации веб-сайта. Для обоих наших приложений. (EDU) и (EC), значение p?0.01. С методом штрафа награды мы не должны жертвовать фиксированной долей представлений для исследования. Однако, недостаток этого метода является потребностью в осторожном выборе значений обратной связи, потому что иначе процесс обучения ухудшается. Также возможно объединить метод штрафа награды с ? - случайным выбором рекомендаций для исследования.
Прототип и оценка
В этом разделе мы описываем реализации нашего прототипа и оцениваем полученные результаты. В подразделе 6.1 мы представляем технические детали реализации и эффекты рекомендаций на поведении покупки пользователей. В подразделе 6.2 мы сравниваем различные алгоритмы оптимизации и политики выбора правила рекомендации.
6.1 Прототипные реализации, рейтинги щелчков и экономическая эффективность
Прототип системы был реализован и применялся в двух веб-сайтах. Первый является веб-сайтом Database Group, университета Лейпцига (http://dbs.uni-leipzig.de, приблизительно 2000 просмотра в день). Это показывает две рекомендации (N=2) на всех страницах HTML сайта. Второе приложение является маленьким коммерческим онлайновым хранилищем программного обеспечения (http://www.softunity.com, приблизительно 5000 просмотров в день). Здесь, наш подход используется, чтобы автоматически выбрать и представить пять рекомендаций (N=5) на страницах детали продукта. У обоих веб-сайтов есть приблизительно 2500 страниц контента. База данных рекомендации содержит приблизительно 60000 правил для (ЭДУ) и 35000 правил для (EC). Прототип использует сервер базы данных MySQL для сервера базы данных рекомендации и Microsoft SQL Server для веб-хранилища данных. Весь алгоритм рекомендаций и оптимизатор, так же как веб-сайты непосредственно, реализуются, используя язык сценариев PHP. Рис. 4 показывает, что число щелчков на правило рекомендации распределяется согласно закону подобному Zipfian (на рисунке только рекомендации как минимум со 100 просмотрами). Данные показывают, что относительно небольшой процент правил рекомендации приносит большинство щелчков. Это поддерживает нашу эвристику оптимизации, так как она показывает, что мы можем достигнуть полного улучшения пропускной способности, представляя самые успешные рекомендации чаще. Вообще, веб-пользователи на 2.07 % www.softunity.com становятся клиентами (эта метрика обычно расценивается как CCR( потребительская скорость преобразования). Для веб-пользователей, которые щелкнули по рекомендации, это значение составляет 8.55 %, то есть больше чем в четыре раза. Анализ клиента и данных покупки также показал, что 3.04 % всех купленных продуктов был сразу куплен после щелчка по рекомендации, и 3.43 % всех купленных продуктов рекомендовался в том же самом сеансе. Рис. 5 показывает эффекты нашего алгоритма оптимизации с точки зрения покупательного поведения, в отличие от неоптимизированного выбора рекомендаций. Неоптимизированный алгоритм использует начальные веса, предоставленные алгоритмы рекомендаций, чтобы выбрать рекомендации, и не делает никакой основанной на обратной связи оптимизации. Данные показывают, что оптимизированный подход приводит к значимому увеличению числа дополнений к покупкам.
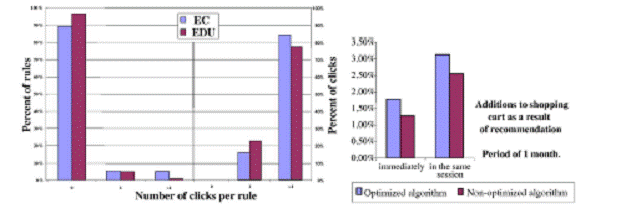
Рис. 4. Небольшое количество рекомендаций Рис. 5. Дополненительные покупки в результате
приносит большинство щелчков (EC, EDU) рекомендации (EC)Алгоритмы оптимизации и Политики Выбора Рекомендации
Чтобы оценить эффективность различных алгоритмов оптимизации, мы сравнили производительность только для награды и алгоритмов оптимизации штрафа награды с выбором рекомендаций, основанных на начальном весе, предоставленном алгоритмом рекомендации. В течение испытательного срока алгоритм выбора был выбран с равной вероятностью из одного из следующих:
• только для награды, ? =0.2, никакого устаревания
• только для награды, ? =0.05, никакого устаревания
• штраф награды, частичное устаревание с T=200
• штраф награды, частичное устаревание с T=500
• без оптимизации
Рис. 6 показывает, что оптимизированные алгоритмы достигают более высоких пропускных способностей чем алгоритмы без оптимизации. Алгоритм, который использует штраф так же как награду, смог достигнуть более высоких пропускных способностей чем алгоритм, который использует только награду, и с некоторой вероятностью выбирает случайные правила рекомендации для исследования. Слишком быстрое устаревание (в нашем случае T=200) может оказать негативное влияние на оптимизацию. Относительно маленькое улучшение алгоритма штрафа награды может быть приписано факту, что в наших приложениях успешные и неудачные рекомендации могут быть отчетливо разделены даже более простыми алгоритмами. Алгоритм, который использовал нуль в качестве начальных весов для правил рекомендации, был протестирован на веб-сайте EDU. Его пропускная способность была только на 4 % ниже чем одного из алгоритмов, который использовал рекомендации специфичных начальных весов. Рис. 7 показывает пропускные способности сеанса (число сеансов, где по крайней мере одна рекомендация была принята разделенна на общее количество сеансов) для различных политик выбора рекомендации, представленных в Разделе 3. Были протестированы пять политик. Случайная политика использовалась для сравнения. В дополнение к политикам, описанным в разделе 3, мы протестировали политики, только наследование и только одноуровневые элементы, которые использовались, чтобы моделировать сценарии, когда никакие непосредственно соответствующие рекомендации не могут быть найдены. Политика только наследование, игнорирует прямые рекомендации соответствия и берет только рекомендации от более высоких уровней иерархии. Политика только одноуровневые элементы ищет рекомендации среди одноуровневых элементов иерархии (узлы, имеющие общего родителя с текущим узлом), также игнорируя прямые соответствия. Согласно результатам испытаний, политика прямого соответствия является лучшей, чем прямую + родители. Однако, прямая + родительская политика в состоянии найти рекомендации даже в случаях, когда никакие непосредственно соответствующие рекомендации не доступны.
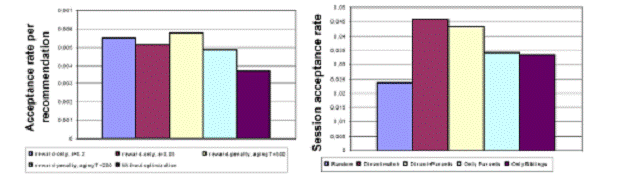
Рис. 6. Пропускная способность различных Рис. 7. Пропускная способность сеанса
алгоритмов оптимизации (EC) политик выбора правил (EDU)Группы пользователей
Рис. 8 показывает сравнение пропускных способностей для различных групп пользователей. Группы пользователей были созданы, используя алгоритм дерева решений J48 по данным использования нескольких месяцев от веб-сайта ЕDU. Веб-сайт DBS структурируется в нескольких интересующих областях, самых важных, из которых обучение и исследование: Для алгоритма дерева решений, интересующая область (обучение/исследование), которое посещает веб-пользователь, служил атрибутом классификации; другие атрибуты были страной, системой просмотра и операционной системой веб-пользователя. Однако, после того, как дерево было сокращено, только страна атрибута, казалось, была важна в дополнение к интересующей области. Получающееся дерево было преобразовано в узлы графа онтологии с отображающимися пунктами. Рис. 8 указывает, что пропускные способности отличаются существенно для групп пользователей и что для продуманного веб-сайта, ориентированные на исследование пользователи принимают представленные рекомендации почти вдвое больше, чем ориентированные на исследование пользователи. Рис. 9 показывает насколько хорошими наши группы пользователей являются в предсказании пользовательских интересов. Здесь, столбцы другого цвета показывают принятие для рекомендаций, указывающих на контент различных областей интереса. Исследование группы пользователей довольно эффективно, так как его пользователи только щелкнули по рекомендациям, приводящим к области исследования веб-сайта. Пользователи группового исследования предпочли связанные с исследованием рекомендации, но соответствующая пропускная способность не намного выше чем для пользователей не принадлежащих любой из двух определенных групп пользователей.
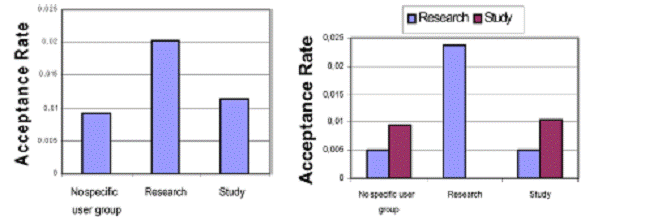
Рис. 8. Пропускные способности Рис. 9. Пропускные способности группы пользователей
различных групп пользователей (EDU) на основе правила рекомендации (EDU)Связанные работы
Обзор гибрида системы рекомендаций включает список достоинств и недостатков различных алгоритмов рекомендаций и классификации методов гибридизации может быть найден в [5]. Работа в [17] также использует хранилище данных, чтобы хранить информацию использования и неявную пользовательскую обратную связь. Однако, в [17] обратная связь используется, чтобы изучить, как переключать различные алгоритмы рекомендаций, которые работают независимо, тогда как в нашем подходе обратная связь влияет на веса отдельных рекомендаций ( подход переключений по сравнению со взвешенным подходом согласно классификации в [5]). [17] описывает несколько стратегий, согласно которым может быть выбран лучший алгоритм рекомендаций. Объединение совместной фильтрации с алгоритмами основанными на контенте адресуется в [6], [13] и [3]. Их подходы стремятся объединить оба алгоритма в одном алгоритме специфичным для алгоритма способом. Наш подход, напротив, просматривает эти алгоритмы как независимые, но динамически комбинирует их результаты, в некотором смысле, оптимизированные для данного веб-сайта.
Вывод
Мы описали архитектуру, реализацию и использование новой системы рекомендации. Она использует многократные методы, чтобы генерировать рекомендации, хранит их в семантически включенной базе данных рекомендации и затем совершенствовало их используя онлайновую оптимизацию. Наши результаты для двух демонстрационных веб-сайтов показали, что основанная на обратной связи оптимизация может значительно увеличить пропускную способность рекомендаций. Даже простые методы оптимизации могли существенно улучшить принятие рекомендаций по сравнению с неоптимизированным алгоритмом. Мы также показали, что веб-рекомендации и наш подход оптимизации оказывают значительное влияние на поведение покупок клиентами веб-сайта электронной коммерции.Литература
[1] S. Acharyya, J. Ghosh: Context-Sensitive Modeling of Web-Surfing Behavior using Con-cept Trees. Proc. WebKDD, 2003
[2] M. Balabanovic: An Adaptive Web Page Recommendation Service. CACM, 1997
[3] J.Basilico, T.Hofmann.: Unifying collaborative and content-based filtering. Proc. 21th ICML Conference. Banff, Canada, 2004
[4] S. Baron, M. Spiliopoulou: Monitoring the Evolution of Web Usage Patterns. Proc. ECML/PKDD, 2003
[5] R. Burke: Hybrid Recommender Systems: Survey and Experiments. User Modeling and User-Adapted Interaction, 2002
[6] Claypool, M., Gokhale, A., Miranda, T.: Combining Content-Based and Collaborative Fil-ters in an Online Newspaper. In: Proc. ACM SIGIR Workshop on Recommender Systems, 1999
[7] N. Golovin, E. Rahm: Reinforcement Learning Architecture for Web Recommendations. Proc. ITCC2004, IEEE, 2004
[8] S. ten Hagen, M. van Someren and V. Hollink: Exploration/exploitation in adaptive recom-mender systems. Proc. European Symposium on Intelligent Technologies, Hybrid Systems and their Implementation in Smart Adaptive Systems, Oulu, Finland. 2003
[9] A. Jameson, J. Konstan, J. Riedl: AI Techniques for Personalized Recommendation. Tuto-rial presented at AAAI, 2002
[10] G. Linden, B. Smith, and J. York: Amazon.com Recommendations: Item-to-Item Collabo-rative Filtering. IEEE Internet Computing. Jan. 2003
[11] B. Mobasher, X. Jin, Y. Zhou. Semantically Enhanced Collaborative Filtering on the Web. Proc. European Web Mining Forum, LNAI, Springer 2004
[12] M. Nakagawa, B. Mobasher: A Hybrid Web Personalization Model Based on Site Connec-tivity. Proc. 5th WEBKDD workshop, Washington, DC, USA, Aug. 2003
[13] P. Paulson, A. Tzanavari: Combining Collaborative and Content-Based Filtering Using Conceptual Graphs. Lecture Notes in Computer Science 2873 Springer 2003
[14] E. Reategui, J. Campbell, R. Torres, R. Using Item Descriptors in Recommender Systems, AAAI Workshop on Semantic Web Personalization, San Jose, USA, 2004
[15] B. Sarwar, G. Karypis, J. Konstan, J. Riedl: Analysis of Recommendation Algorithms for E-Commerce. Proc. ACM E-Commerce, 2000
[16] R.S. Sutton, A.G. Barto: Reinforcement Learning: An Introduction. MIT Press,1998.
[17] A. Thor, E. Rahm: AWESOME - A Data Warehouse-based System for Adaptive Website Recommendations. Proc. 30th Intl. Conf. on Very Large Databases (VLDB), Toronto, Aug. 2004