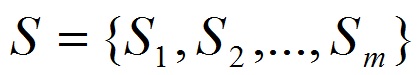

Introduction
At the present time is rapidly developing a new direction in theory and practice of artificial intelligence - evolutionary computation. This term is usually used for a general description of search algorithms, optimization or training based on some formal principles of natural evolutionary selection. Features of the ideas of evolution and self-organization lies in the fact that they are confirmed not only for biological systems in developing many billions of years. These ideas have now been successfully used in the development of many technical and medical software systems. Genetic algorithms have been based at the University of Michigan American researcher Holland and originally developed for optimization problems in a sufficiently effective mechanism for combinatorial enumeration options. Unlike many other works, to Holland was not only the solution of specific problems, but the study of the phenomenon of adaptation in biological systems and its application in computer systems. At the same time a potential solution - individual is linked - in binary code. The population includes many individuals. In the process of evolution there are three basic genetic operators: reproduction, crossover and mutation. Also in the 60s in Germany, Rechenberg laid the foundations of "evolutionary strategies" for solving optimization problems of real parameters in the calculation of transmission lines. This trend has evolved independently for many years and here has provided important fundamental results. Vogel, regardless of other researchers established evolutionary programming, where the potential solution is represented by a finite automaton. The main genetic operator is also a mutation which randomly changes the jump table-output automaton. A little later Koza from MIT U.S. laid the foundations of genetic programming. Here, as an individual played in the program LISP, which seemed a tree structure. These structures were developed genetic operators crossover and mutation. Currently, these areas are united in "evolutionary computation", which successfully applied to many problems. The individual areas interact successfully by borrowing the best features from each other.
Problem Statement
The most promising direction for solving the problems of medical prediction is based on data mining using modern software. In the first phase of which is necessary to identify risk factors and assess their information content. Typically, selection of data analysis is performed for a doctor in the following manner: first by the selection of risk factors related to a particular pathology and primarily on the formal principle: family history, perinatal factors, disease history, the unfavorable macro-environment, social and hygienic factors and t . etc. Then a group of risk factors determined by the time of exposure, the type (biological, environmental, etc.) and the number of influencing factors. For example, when analyzing the data provided by different doctors for the prediction of certain diseases in the field of gynecology can be concluded that the list of the collected factors, is relatively stable, with the same analysis for the majority of gynecological problems and very large. It includes medical and socio-demographic factors. It should be noted that the medical problems, to analyze a large number of unequal importance of risk factors that also may be interrelated, so the use of statistical methods in this case is inefficient. Now consider this problem from a mathematical point of view. Suppose there is a set of risk factors for S, containing m examples (1.1). Each example, Si data set S consists of n characteristic parameters Xi = (x1, x2, ..., xn) and the - the result of Yi
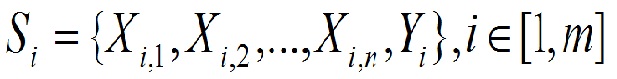
Thus, each i-th sample data set S represented by a set of values ??of risk factors X and Y. outcome In this case the risk factors X data set S may include both factors that contain useful information, as well as the factors that partially or completely uninformative. In addition, the informative factors may also contain noise. You must complete the selection of the relevant factors and assess the quality of the data set for evaluation criterion E (X). Then the problem reduces to finding a vector X, at which the permissible classification accuracy with the minimum of input parameters (1.3)
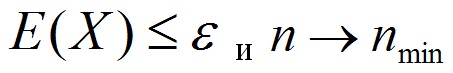
where є - margin of error, n-number of risk factors, nmin - the desired number of risk factors. As a criterion for evaluation, you can use the formula (1.4).
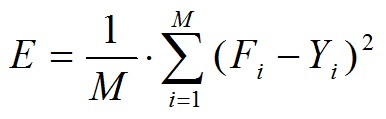
where M - number of training examples, F - the result, Y - the desired result.
Tasks and Objectives
The aim of this work is to obtain useful information from a set of parameters (risk factors) and prepare the data for training analysis system, designed to predict blood loss during delivery.
General theoretical information
GA uses the principles and terminology borrowed from biology - genetics. In the GA each individual represents a potential solution to some problem. In the classical GA individual is encoded string of binary symbols - chromosome, every bit of which is called a gene. A lot of individuals - potential solutions is population. Search for (sub) optimal solution is performed in the evolution of the population - successive transformations of a finite set of solutions to another by means of genetic operators reproduction, crossover and mutation. GA uses the following mechanisms of natural evolution:
The first principle is based on the concept of survival of the fittest and natural selection in Darwin, which was formulated by him in 1859 in his book "The Origin of Species by Means of Natural Selection." According to Darwin, individuals are better able to solve problems in their environment survive and reproduce more (reproduces). In genetic algorithms, each individual represents a solution to some problem. By analogy with this principle, individuals with the best values ??of the target (fitness) function have a better chance to survive and reproduce. The formalization of this principle gives the operator of reproduction.
The second principle is due to the fact that the child chromosome is composed of parts of chromosomes derived from parents. This principle was established in 1865, Mendel. His formalization provides the basis for the operator mating (crossover).
The third principle is based on the concept of mutation, discovered in 1900 de time. Originally, the term used to describe a significant (drastic) changes the properties of their children, and their acquisition of properties that are absent in the parents. By analogy with the principle of genetic algorithms use a similar mechanism to dramatically change the properties of offspring and thereby increase the diversity (variability) of individuals in the population (the set of solutions).
These three principles form the core of EV. Using them, the population (the set of solutions to this problem) has evolved from generation to generation. The evolution of artificial population - find the set of solutions to some problem we can formally describe the algorithm, which is shown in Fig. 2.1. GA takes a lot of parameters of an optimization problem and is encoded by sequences of finite length in a finite alphabet (in the simplest case of binary alphabet "0" and "1"). Pre simple GA randomly generates an initial population of strings (chromosomes). The algorithm then generates the next generation (population), using three basic genetic operators:
Reproduction operator (RR).
Operator crossover (OC).
Mutation operator (SM).
Genetic operators are mathematical formalization of the above three basic principles of Darwin, Mendel and de time of natural evolution. GA works as long as there will not be met given the number of generations (iterations) of the process of evolution, or at a certain generation will received a specified quality or due to premature convergence when released into a local optimum.

In each generation, a lot of artificial animals created using the old and adding new ones with good properties. Genetic algorithms - not just a random search, they effectively use the information stored in the evolutionary process. Unlike other optimization methods GA optimize different areas of the solution space simultaneously and are better able to find new areas with the best objective function value by combining the quasi-solutions of different populations.
The selection of factors by the GA
The first step is defined with mathematical techniques to solve the problem of forecasting the development of obstetric hemorrhage. To solve this problem, you can use a neural network (NN) [2,3]. To practice the most important is to determine the risk of blood loss at delivery of more than 0.5% of body weight, with a view to taking appropriate action. In this case, in fact, holds a classification into two classes: abnormal bleeding and allowed. To perform this task in a manner appropriate to use a multilayer feedforward NA. Next, using the GA determines the optimal set of input parameters. After successfully identified and trained to the National Assembly, holds the GA, which feeds different combinations of risk factors to the inputs of the National Assembly and then you try to train the network with a combination of selected risk factors. The principle of the implementation of the chromosome encoding is shown in Fig. 2.2. Each chromosome is a sequence of a certain number of bits (the maximum number of risk factors). The value of each bit is 1 if the quotient of that number is present in this set, and zero if this factor is absent. In the proposed approach for feature extraction used a genetic algorithm, which is a modified implementation scheme for the problem of multicriteria optimization. While most of these methods used to solve such problems, uses a single, composite optimized criterion [4]. Solution of the problem in this case is somewhat non-dominated subsets of attributes. Designed fitness function (2.1), which involves finding a solution which is optimal according to two criteria? considered classification accuracy and number of risk factors. Besides this the fitness function allows you to set the desired ratio of classification accuracy and number of risk factors.
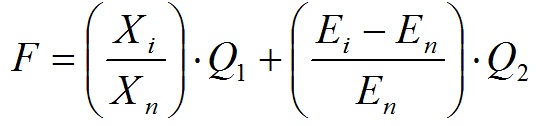
where Xi - the number of risk factors present in the i-th chromosome, Xn - the maximum number of risk factors, Ei - NA training error for the i-th chromosome, En - error of NN training using the maximum number of factors, Q1 and Q2 - coefficients, using which are regulated by the ratio between the accuracy of classification and the number of risk factors. It is recommended to select a range of values ??(2.2), and adhere to the conditions (2.3).

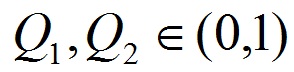
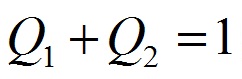
Genetic operators performed standard ones.
The easiest method of implementing the PR - Building a roulette wheel where each chromosome has a sector which is proportional to its value TF.
The simple statement krosingovera with a given probability Pc carried out in three stages (Figure 2.3):
Stage 1. Selects two chromosomes (parents) at random from the intermediate population formed by the operator of reproduction
Stage 2. Randomly chosen crossover point - the number k in the range [1,2 ... n-1], where n - the length of the chromosome (the number of bits in binary code)
Stage 3.Two new chromosomes A ', B' (descendants) are formed from A and B through the exchange of substrings after the crossing point:
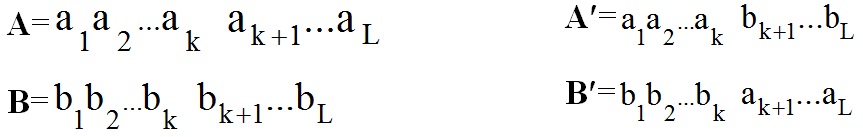
OK, done with a given probability Pc (selected by two parents do not necessarily produce offspring).
Mutation operator plays a secondary role and its probability is usually small. Mutation operator is performed in two stages:
Stage 1. In chromosome A (Fig. 3) randomly selected k-th position (bit) mutations (1 <= k <= n).
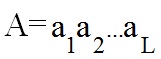
Step 2. Performed an inversion of the gene values ??in the k-th position. (Figure 4).
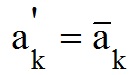
Finding
Discussed and solved an actual problem of selection of risk factors for obstetric hemorrhage for the development of medical analysis system risk prediction of pathological blood loss during delivery. Performed mathematical problem of selection of informative data. Designed fitness function for evolutionary method of selection of informative data. In the future plan to implement real-COP to the task.
Literature
1. Скобцов Ю. О. Основи еволюційних обчислень / Скобцов Ю. О. – Донецьк: ДонНТУ, 2009. – 316 с.
2. Рутковская Д. Нейронные сети, генетические алгоритмы и нечеткие системы / Рутковская Д., Пилинский М., Рутковский Л. - М.: Горячая линия – Телеком, 2006. – 452с.
3. Саймон Хайкин Нейронные сети: полный курс, 2-е издание. : Пер. с англ. – М. : Издательский дом «Вильямс», 2006. – 1104 с.
4. Васяева Т.А. Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. Том 1. - Херсон: ХНТУ, 2011. – 472 с.
5. Архангельский А.Я. Программирование в С++ Builder 6. – М.: ЗАО «Издательство БИНОМ», 2002г. – 1152с.