Источник: http://www.theserverside.com/news/1365083/Distributed-Computing-Made-Easy
В случае, если Вы не заметили, распределенные вычисления трудны.
Проблема в том, что они становится все более важным в мире разработки приложений для предприятий. Сегодня, разработчики непрерывно должны решать такие вопросы, как: Как повысить масштабируемость, масштабируя приложение на более, чем один узел? Как можно гарантировать высокую доступность, устранение одиночных точек отказа, и убедится, что вы встретите вашего клиента SLA? Все вопросы, так или иначе, подразумевают распределенные вычисления.
Для многих разработчиков самый обычный способ решения проблемы состоял бы в том, чтобы разделить архитектуру на группы компонентов или служб, которые распределены между различными серверами. Хотя это и не удивительно, учитывая наследия CORBA, EJB, COM и RMI, которые поддерживают большинство разработчиков, если вы решите пойти по этому пути, то у вас много неприятностей. В большинстве случаев это не стоит усилий, и даст вам больше проблем, чем решит.
Например, Мартин Фаулер считает, что проект, как этот "... всасывает как перевернутый ураган" и продолжает с последующим обсуждением (из его книги Patterns of Enterprise Application Architecture):
“Таким образом, мы приходим к моему первому закону распределенных объектов проекта : Не разносить свои объекты.
Как же тогда Вам эффективно использовать несколько процессоров? В большинстве случаев решением является кластеризация. Положите все классы в один процесс, а затем запустите несколько копий этого процесса на различных узлах. Таким образом, каждый процесс использует локальные вызовы, чтобы выполнить работу и, таким образом, вещи быстрее. Вы можете также использовать мелкомодульные интерфейсы для всех классов в рамках процесса и, это приведет к лучшему обслуживанию с простой моделью программирования ”
Главным преимуществом использования кластеризации является упрощенная модель программирования. Как мне кажется, кластеризация и распределение в целом, это что-то, что должно быть прозрачным для разработчика приложений. Это несомненно сквозная проблема, которая должна быть ортогональной и состоять из слоев приложения, службы, которые принадлежат среде выполнения. Иными словами, то, что нам, в конечном счете, нужно это кластеризация на JVM уровне.
В этой статье я проведу вас через довольно общую, но распространенную, проблему распределенных вычислений, и покажу, как она может быть упрощена - стать почти тривиальной - с помощью кластеризации на уровне JVM.
Во-первых, давайте определим проблему. Нам нужна какая-то система, которая:
Для упрощения реализации, мы должны будем для поддерживать только задачи, которые являются так называемыми трудно параллельными, что означает, что они не имеют общедоступного состояния, но могут быть выполнены в полной изоляции. К счастью, большинство приложений на самом деле попадают в эту категорию.
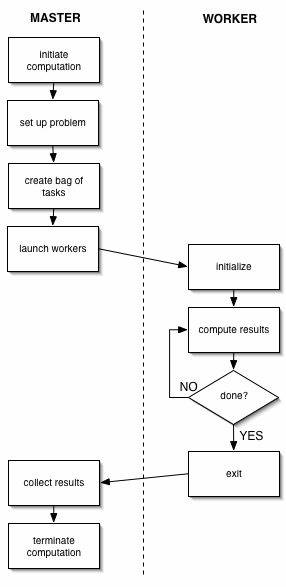
Одной из самых известных и распространенных моделей, которые решают нашу проблему, является так называемая "мастер/рабочий" модель. Итак, давайте посмотрим, как она работает.
Модель "Мастер/работник" состоит из двух логических сущностей: мастера, и одного или более экземпляров работников. Мастер инициирует вычисление, создавая множество задач, помещает их в какое-то общедоступное пространство, а затем ждет пока рабочие возьмут и завершат задачу.
Общедоступное пространство, как правило, какой-то вид общей очереди, но он также может быть реализован как Tuple Space (например, в среде программирования Linda, где модель широко используется).
Одним из преимуществ использования этой модели является то, что алгоритм автоматически балансирует загрузку. Это возможно из-за простого факта, что набор работ является общим, и работники продолжают выбирать работу из множества, пока не будет работы, которую нужно сделать.
Алгоритм обычно имеет хорошую масштабируемость до тех пор, пока количество задач, намного превысит число рабочих и, если задачи занимают приблизительно одинаковое количество времени для выполнения.
Начнем с реализации проекта как регулярного многопоточного приложения на одном узле, основанного на модели "мастер/рабочий", которая была освещена в предыдущем разделе.
Интерфейс ExecutorService в пакете java.util.concurrent (начиная с Java 5) оказывает прямую поддержку модели "мастер/рабочий", и это именно то, что мы будем использовать. Мы также собираемся использовать возможности зависимых инъекций Spring Framework для соединения и настройки системы.
У нас есть две сущности: Мастер, который координирует планирование работы и накапливает результат, и Общая Очередь, которая представляет собой общее пространство, где находится работа. Эти сущности определяются как две различных компоненты Spring под названием мастер и очередь, которые соединены и настроены в конфигурационный файл компонент Spring. Нет необходимости определять компоненту Работник, поскольку работник становится "скрытым" и управляется ExecutorService.
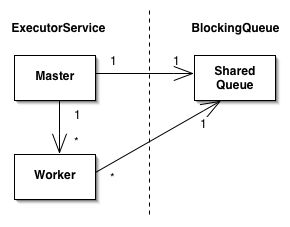
На рисунке выше показано, что концептуально, ExecutorService состоит из Мастера, который содержит ссылку на общую очередь (в нашем случае BlockingQueue), а также из N числа Работников, где каждый Работник имеет ссылку на ту же общую очередь.
Мастер
Компонента Мастер реализуется интерфейсом ExecutorService. Этот интерфейс предоставляет методы, которые могут производить
Будущее, или список Будущих, для отслеживания прогресса в одной или нескольких асинхронных задач, например, график работы и
ожидание пока работа будет завершена. Компонента Мастер реализуется с помощью прокси-модели и просто делегатов на экземпляр
ThreadPoolExecutor, который является конкретной реализацией интерфейса ExecutorService, использующий пул потоков для
управления потоками Работников. Делегирование таким образом предоставляет более простую конфигурацию, как значения по
умолчанию в конфигурации компонент Spring.
Вот как мы могли бы осуществить компоненту Мастер:
public class Master implements ExecutorService {
private final ExecutorService m_executor;
public Master(BlockingQueue workQueue) {
m_executor = new ThreadPoolExecutor(
10, 100, 300L, TimeUnit.SECONDS, workQueue);
}
public Master(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
BlockingQueue workQueue) {
m_executor = new ThreadPoolExecutor(
corePoolSize, maximumPoolSize,
keepAliveTime, TimeUnit.SECONDS, workQueue);
}
public List invokeAll(Collection work) throws InterruptedException {
return m_executor.invokeAll(work);
}
... // remaining methods are omitted
}
Общая Очередь
При создании, компоненты Мастер передается ссылка на компоненту общей очереди, которая является экземпляром одного
из классов, реализующего интерфейс ava.util.concurrent.BlockingQueue.
Компонента Очередь содержит все в ожидающие работы. Мы должны иметь один экземпляр этой очереди, который может быть доступен для всех работников, и поэтому мы определяем ее как Singleton в компоненте XML-файл конфигурации.
Это называется блокирующей очередью, потому что она будет блокироваться и ждать больше работ, которые будут добавлены в очередь, если очередь пуста. Кроме того, опционально возможный лимит может быть установлен и будет, если установлено, предотвращать чрезмерное расширение очереди, если лимит будет превышен, то очередь будет блокироваться, пока хотя бы один элемент не будет удален.
Сборка
Эти две компоненты теперь могут быть подключены с помощью конфигурационного файла компонент Spring:
<beans>
<bean id="master" class="demo.masterworker.Master">
<constructor-arg ref="queue"/>
</bean>
<bean id="queue" class="java.util.concurrent.LinkedBlockingQueue"/>
</beans>
Использование
Использование реализации "мастер/работник" теперь просто вопрос получения компонент из контекста приложения и
вызова invokeAll (..), или одного из других подобных методов, а порядке следования работы:
ApplicationContext ctx =
new ClassPathXmlApplicationContext("*/master-worker.xml");
// get the master from the application context
ExecutorService master = (ExecutorService) ctx.getBean("master");
// create a collection with some work
Collection<Callable> work = new ArrayList<Callable>();
for (int i = 0; i < 100; i++) {
work.add(new Callable() {
public Object call() {
... // perform work - code omitted
}
});
}
// schedule the work and wait until all work is done
List<FutureTask> result = master.invokeAll(work);
Обсуждение
Это было хорошее упражнение и реализация полезна сама по себе, но эта статья о распределенных вычислениях, так теперь
давайте посмотрим, как мы можем превратить эту многопоточную, одиночную JVM реализацию в распределенную мульти-JVM
реализацию.
Terracotta for Spring это среда выполнения для Spring-базированных приложений, что обеспечивает прозрачную и высокопроизводительную кластеризацию для вашего Spring приложения с нулевыми изменениями кода приложения.
С Terracotta for Spring, разработчики могут создавать Spring приложения с одним узлом, как обычно. Они просто должны определить, какие контексты Spring приложений, которые они хотят сосредоточить в файле конфигурации. Terracotta for Spring обрабатывает остальное. Spring приложения группируются автоматически и прозрачно и гарантированно имеют ту же семантику в кластере, как на одном узле.
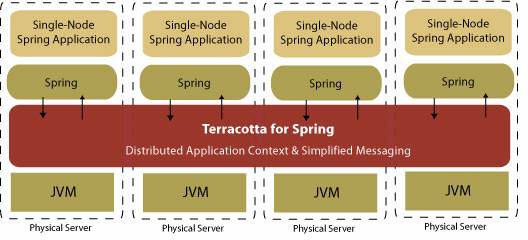
Основными функциями, которые мы будем использовать в нашем приложении:
До сих пор мы только осуществляли регулярную, одноузловую, многопоточную реализацию модели "мастер/работник" (которая может быть использована в качестве одноузловой). Но интересно то, что для того, чтобы превратить эту реализацию из многопоточного приложения в распределенное мульти-JVM приложение, нам не нужно писать код вообще. Все, что нам необходимо сделать, это поместить его в Terracotta for Spring вместе с его конфигурационным файлом XML, в котором мы просто определим какие Spring компоненты мы хотим сгруппировать. В нашем случае это означает, что компонента очереди, так как эта очередь должна быть доступна во всем кластера, будет распределена. Это то, что мы выполняем, просто настраивая компоненту как Singleton в конфигурационном XML-файле компонент, а также список общих компонент в конфигурационном файле Terracotta for Spring.
Вот пример конфигурационного файла, который сделает одноузловую реализацию распределенной. Важные части выделены жирным
шрифтом. Во-первых, у нас есть путь(и) к конфигурационному файлу(ам) компонент Spring, которые используются для настройки
контекста приложения, которое мы хотим сделать общим. Во-вторых, у нас есть имена компонент кластера, и имя должно быть
определено в одном из конфигурационных файлов компонент.
<?xml version="1.0" encoding="UTF-8"?>
<tc:tc-config xmlns:tc="http://www.terracottatech.com/config-v1">
<application>
<dso>
<spring>
<application name="*">
<application-contexts>
<application-context>
<paths>
<path>*/master-worker.xml</path>
</paths>
<beans>
<bean name="queue"/>
</beans>
</application-context>
</application-contexts>
</application>
</spring>
</dso>
</application>
</tc:tc-config>
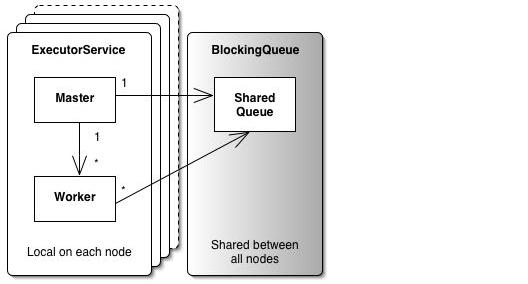
Теперь мы имеем наше одноузловое, многопоточное приложение, превращенное в распределенное, многоузловое приложение. На практике это означает то, что мы теперь в состоянии запустить исходный код, который был написан для одиночного JVM - без всякой мысли о распределении или кластеризации - в распределенной среде, с точно такими же семантиками, что и на одном узле. Мы также видели, что мы можем прозрачно группировать, не только пользовательские классы, но основные классы библиотек Java, в том числе их абстракций параллелизма.
Terracotta for Spring использует аспектно-ориентированные технологии для адаптации приложения в классе времени загрузки. На этом этапе он расширяет приложение в целях обеспечения того, чтобы семантики Java правильно поддерживались в кластере, в том числе ссылки на объекты, координации потоков, сбор мусора и т.д.
Например, она (как уже упоминалось выше) поддерживает семантику регулярных синхронизированных блоков в кластере, принимая блокировку для экземпляра объекта, который вы синхронизируете перед входом в блок и снимая блокировку сразу после выхода из блока. Можно декларативно определить точную семантику для блокировки (чтение, запись или одновременно). Другим примером является вызов notifyAll (), который включен в кластерные широкие уведомления с учетом всех узлов, которые утверждены для блокировки.
Это то, что происходит под укрытием в нашем приложении, когда Terracotta координирует доступ к BlockingQueue и FutureTasks (в кластере). Terracotta поддерживает распределенное использование абстракций координации любых других потоков, таких как барьеры, семафоры, взаимные исключения и т. д., а также любые абстракции, написанные пользователем. Единственным требованием является то, что она должна будет использовать Java-примитивы синхронизации внутренне (статью о том, как реализовать распределенные барьеры с использованием Terracotta можно найти здесь).
Я также упоминал, что Terracotta не использует сериализацию. Это означает, что любое регулярный Plain Old Java Object (POJO) может быть общим, также как и ссылки из общего экземпляра (часть общего объекта графа). Это также означает, что Terracotta не передает весь граф объекта на все узлы, а разлаживает граф в чистые данные и отправляет только фактические "дельта" по проводам, то есть фактические изменения, данные, которые являются "устаревшими" на других узлах. Так как она имеет центральный сервер (см. ниже), который отслеживает, кто на кого ссылается на каждом узле, он может также работать в "ленивом" режиме и отправлять изменения только в узел(ы), который ссылается на объекты, которые являются "грязными" и нуждаются в изменениях.
Архитектура основана на базе "звезды", это значит, что есть центральный сервер, который управляет клиентами, он использует TCP/IP, поэтому сервер просто должен быть где-то в сети. Клиент в этом случае просто ваше обычное приложение вместе с библиотеками Terracotta. Сервер это не одиночная точка отказа, а SAN-базированное приложение для поддержки отказоустойчивости активно-пассивный способом. Это означает, что вы можете иметь произвольное число (пассивных) серверов в очереди и при отказе выбранного сервера подключаться именно там, где главный сервер дал сбой.
Как вы могли заметить, с использованием Terracotta for Spring можно превратить регулярную одноузловую многопоточную реализацию в распределенную, мульти-JVM реализацию без каких-либо изменений кода и при сохранении точно таких же семантик. Это очень мощно и открывает совершенно новый способ реализации распределенных приложений (см. Будущая работа ниже). Основные моменты в этой работе показали, что Terracotta for Spring поддерживает:
Я считаю, что такой способ разработки распределенных приложений с совместными состоянием, координацией ресурсов и управлением распределенной памятью, осуществляемые на уровне JVM, можно упростить, до реализации обычных приложений, благодаря этому мы можем сосредоточиться на логике и концепциях, и нам не нужно беспокоиться о механизмах распределения и проблемах.
Было бы интересно, к примеру, упражнение реализовать систему Blackboard, что, как правило, очень трудно, из-за всех потенциальных проблем, связанных с распределенными вычислениями, которые необходимо решить. Но используя Terracotta, реализация может быть упрощена до одноузлового многопоточного приложения, например, можно работать на более высоком уровне, уделяя особое внимание на разработку концепций и алгоритмов, в то время как другие общие проблемы, как распределенный обмен состоянием, распределенная координация, управления распределенной памятью и т.д. То же самое касается реализации Tuple Space, такие как JavaSpaces т.д.
Terracotta for Spring это свободное программное обеспечение для использования в производстве. Вы можете найти более подробную информацию здесь:
Выражаю благодарность Евгению Кулешову и Крису Ричардсону за ценную обратную связь.
Jonas Boner является старшим инженером Terracotta Inc. с упором на стратегию, развитие продуктов и архитектуры, а также техническую евангелизацию. До Terracotta, Jonas был старшим инженером по разработке программного обеспечения для команды JRockit в BEA Systems, где он работал над инструментами среды исполнения, JVM поддержкой AOP и технологией евангелизации. Он является основателем рамках AspectWerkz AOP и коммиттером для проета Eclipse AspectJ 5.