Continuous on-line learning and planning in a pick-and-place task demonstrated through body manipulation.
Автор: A. de Rengervé, J. Hirel, P. Andry, M. Quoy, P. Gaussier
Источник: ETIS, CNRS ENSEA University of Cergy-Pontoise, F-95000 Cergy-Pontoise, France.
Abstract
When a robot is brought into a new environment, it has a very limited knowledge of what surrounds it and what it can do. One way to build up that knowledge is through exploration but it is a slow process. Programming by demonstration is an efficient way to learn new things from interaction. A robot can imitate gestures it was shown through passive manipulation. Depending on the representation of the task, the robot may also be able to plan its actions and even adapt its representation when further interactions change its knowledge about the task to be done. In this paper we present a bio-inspired neural network used in a robot to learn arm gestures demonstrated through passive manipulation. It also allows the robot to plan arm movements according to activated goals. The model is applied to learning a pick-and-place task. The robot learns how to pick up objects at a specific location and drop them in two different boxes depending on their color. As our system is continuously learning, the behavior of the robot can always be adapted by the human interacting with it. This ability is demonstrated by teaching the robot to switch the goals for both types of objects.
Introduction
Autonomous robots that start with no knowledge about the world and have to learn everything should not only depend on the unguided exploration of their possibilities for their development. They also should be able to learn from human caregivers or other robots by imitating them or interacting with them. A simple visuo-motor associative learning and a motor controller can provide the basis for letting low level immediate imitation emerge as a result of simple mechanisms. In a first phase, the system learns the body configuration as visuo-motor associations. Due to an ambiguity of perception caused by limited visual capabilities, the robot can confuse the hand of the human teacher with its own. The controller, following the homeostatic principle, tries to maintain an equilibrium between the visual and motor information according to the body learning. To do so, it moves the robot hand at the motor position that corresponds to the believed visual position of the robot hand. The robot consequently reproduces the observed gestures of the human. With almost the same mechanisms and the same controller, the robot can also learn by observation how to reproduce a demonstrated task encoded as a sequence of visual positions. Visual demonstration cannot always be enough to teach what is expected from the learner. During their first years, infants are also taught by “embodying” them i.e. by using passive manipulation. This process enables caregivers to guide the infant’s perception and attention so that the infant quickly learns what is taught.
Programming by demonstration provides robots with the ability to learn how to perform a task as a result of a demonstration provided by a human teacher. This demonstration can be done through passive manipulation. Dynamic Motion Primitives (DMP) is a framework for learning to perform demonstrated tasks. With little demonstration data from a human demonstrator, the system can determine through regression the adequate parameters for mixing the DMP to generate the correct movement. The learning system uses a statistical model based on Gaussian Mixture that isadapted to fit the data from training demonstrations using passive manipulation. Gaussian Mixture Regression can then provide a probabilistic estimation of the current state of the robot and of the adequate motor command. These systems have proved to be efficient for performing different tasks. They also enable generalization to different initial conditions and different goal positions.
One of the main issues is how to encode and represent the knowledge acquired through demonstration. The chosen model should enable the robot to continuously learn and integrate new knowledge into the representation of the task. Besides, this model should provide the basis for future action planning. Models with both learning by demonstration and planning have been developed in different works as programming by demonstration can speed up the learning of the knowledge needed for planning. Path planning and Gaussian processes have been combined to use planning capabilities and obstacle avoidance while the robot is reproducing a demonstrated grasp-and-pour task.
In sec. 2, an existing bio-inspired model for planning in mobile robot navigation task is used to learn the movements of a robotic arm. The neural network is adapted to work with proprioceptive states. A visual categorization system for goals corresponding to different types of object is implemented. Associations between object goals and proprioceptive state transitions are learned and adapted thanks to reinforcement learning. This system was implemented on a real robot to carry out an experiment of pick-and-place with objects, sorting them depending on their colors (sec. 3). Initially, the robot learns the actions to be done after one demonstration for each type of object. As it is continuously learning, new demonstrations are integrated in the model and can be used to adapt the behavior of the robot to match new conditions in the task i.e. a switch of the target boxes for each type of object (sec. 4).
Adaption of a bio–inspired cognitive map model to arm control
We previously developed a bio-inspired model of the hippocampus and prefrontal cortex. In our model, spatial states would be encoded in the entorhinal cortex and the hippocampus would learn to associate successive states, thus creating transitions cells. The prefrontal cortex would use information about these transitions to create a cognitive map and use it to plan actions toward the fulfillment of specific goals. This model was later used on a real robot navigating in an indoor environment. The aim of this paper is to reuse the principles of the model, result of a long series of experiments with mobile robots, and adapt them for planning in the proprioceptive space of a robotic arm. In addition, we take full advantage of the possible interactions between human and robot to speed up the learning process and allow for easy adaptation of the conditions of a pick-and-place task. As there are no separate phases of learning and reproduction, the system can adapt at any time. The model is shown in Figure 1.
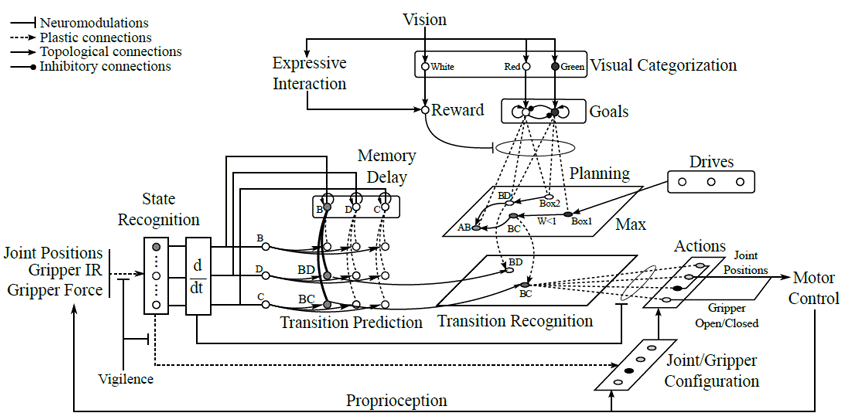
Figure 1 – General architecture for state categorization, transition learning, goal categorization, planning and action selection with the robotic arm with emphasis on the synaptic learning used in this paper.
According to our model, some brain structures could be involved in both navigation and arm control. The categorization of states would involve different areas in navigation (the entorhinal cortex with place cells) and in arm control (motor cortex for proprioceptive states). However, in both cases the hippocampus would be used to detect new events as changes in the encoded states. The prefrontal cortex would also play a role in planning strategies. The cerebellum, more involved in ballistic control of the movement and prediction of motor consequences, is not considered here.
The hippocampal part of the model focuses on generating attractors that correspond to transitions between learned proprioceptive states. When the robotic arm moves, its proprioception (joint angles, gripper IR and force sensor values) is categorized into distinct states. Each state is associated to a prototypical joint/gripper configuration. The categorization of the states is based on a recruitment of new states depending on a vigilance threshold. This algorithm takes inspiration from the Adaptive Resonance Theory. The states are encoded on the weights of the input links of recruited neurons. The computation of the activity (1) and learning (2) for those neurons is given by the following equations:
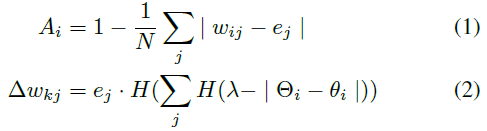
The activity of a neuron is similar to a measure of similarity with the encoded proprioceptive configuration. The most activated neuron is considered as the current state of the system. The recruitment of a new neuron depends on the difference between each current joint value θi and the corresponding joint value Θi of the best recognized configuration. If this difference is below a given vigilance threshold λ, it triggers the recruitment of a new neuron i.e. the encoding of a new state. The choice of the vigilance threshold λ determines the granularity of the states in the proprioceptive space.
The possible transitions between states are learned when the arm moves from one state to the next. This is done in an associative memory that receives information about the newly entered state and the last state. The transition activity is then transmitted to the cognitive map where a graph of the different transitions is created. The cognitive map encodes information about all possible paths by linking subsequent transitions.
In the original navigation architecture, the robot could find resources in its environment. To each type of resource corresponds a drive that represents the motivation of the robot to look for that kind of reward. From an animal’s perspective the reward could be food and the drive hunger, for instance. Upon detection of a resource the current transition in the cognitive map is associated to the relevant drive. Here the robot possesses two different contextual goals associated to two types of objects (red or green). The focal vision of the robotic system categorizes the scene using color detection. It can differentiate between two types of objects: a red can and a green can. When a red object is presented to the visual system, the corresponding goal will be activated and stay active until another object is presented. If the new object is green, the first goal will be inhibited and the second goal will stay active. The visual system can also recognize when a large amount of white is present in the visual field. This is a way to use visual interaction to give rewards to the system and use reinforcement learning to associate goals with transitions. When experimenters present a white object, they reward the current behavior of the robot and associate it with the active contextual goal. The learning of the association between goals and transitions is given by the following equation:
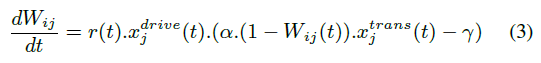
In this experiment we use a simple visual categorization system. We assume that the categorization of objects into goals and reward has already been learned. However, more natural and plausible approaches could be taken in the future. The reward signal can be linked to social cues. Zukowgoldring and Arbib stress the importance of some key words like “look” or “now, you do it” combined with gestures that are used by caregivers to raise the attention of their infants. Also, a robot head that can display and recognize facial expressions could be added to the robotic setup of this experiment to make the interaction between human and robots easier. With such as system, the human could directly give reinforcing or punishing signals through interaction, by displaying positive or negative emotions. This kind of interaction has already successfully been used for the social referencing of objects with good performances. The facial expression and direction of gaze of the teacher can also provide the necessary cues for guiding the attention of the visual system to interesting objects and help categorize them. The robot would then be able to learn from interaction with a human partner which objects are interesting and which different types of object should be categorized into different goals.
When a goal is active, its activity will be propagated in the map with weights w < 1. As a result, transition neurons in the cognitive map have an activity proportional to their distance (in terms of number of transitions) to the goal. Since a max operator on the input is used in the computation of the activity of each neuron, the map gives the shortest path to the strongest or closest goal. In any given state, the hippocampal system predicts all possible transitions from the current position. The activity in the cognitive map is used to bias the selection of a particular transition. The transition that has the highest potential, ie. that corresponds to the shortest path to get the reward, is selected. During the learning process, the system creates proprioceptive states and memorizes the joint/gripper configuration associated to each state. When a transition between states is performed and learned, the position associated to the second state is associated to the transition. As a result, when the competition between transition occurs and a particular transition is selected, the motor configuration of the target state is given as the target position to the motor control system.
The motor control architecture (Figure 2) receives the action from the cognitive map. If the arm is being manipulated by the human (by holding the wrist) this action is inhibited. Otherwise the action is transmitted to a force controller which computes the motor command of the robot by comparing the current and target configurations. When the arm is not being manipulated and the cognitive map transmits no action, a memory stores the value of the last action (or proprioceptive configuration if the arm was manipulated) to maintain the arm at that position. While the motor system receives no commands, a stress level increases until it finally reaches a sufficient value to inhibit the memory. A low-priority reactive behavior will then generate an attractor to a given rest position.
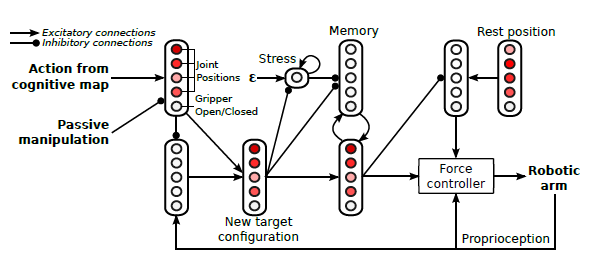
Figure 2 – Detailed architecture for motor control.
Interactive learning of a pick–and–place task
The presented model was implemented with a 6DOF Katana robotic arm. At first, the robot has no knowledge about its environment. The task to is a pick-and-place task (see Figure 3 for the robotic setup). An object (a colored can) is present in the reaching space of the robot at a given location (i.e. the pick-up place). The robot must grasp the can and drop it into one of two boxes, also at static positions in reaching space. A monocular camera is used as the visual system of the robot and is focused on the pick-up place. We assume that the visual attention of the robot is always directed toward that place.

Figure 3 – Pick-and-place task learned and adapted through passive manipulation. Example of demonstration for the red-can-in-box-2 condition and reproduction by the robot. The camera looks at the pick-up place to recognize the type of object by color detection (red or green).
At the beginning, the reactive behavior maintains the arm in rest position. The human teacher demonstrates how to grasp an object through passive manipulation of the arm. The first object is a red can. During the movement, proprioceptive states are recruited to encode the trajectory according to the process described in sec. II. The succession of states leads to transitions and the cognitive map being learned. After the arm has been manipulated by the human and brought to the object, the infrared sensors on the gripper detect the presence of an object in its range, triggering a grasping reflex. Force sensors on the gripper detect when an object is hold and determine the state of the gripper as opened or closed on an object. The arm is then manipulated again and brought above one of the drop boxes, learning the trajectory between the pick–up place and the drop box as shown by the human.A button located on the gripper commands the opening of the gripper. The button is used to simulate the interacting human forcing the opening of the gripper of the robot (which cannot be done due to mechanical limitations).
Once the object has been dropped into the box, a positive reinforcement is given by simply presenting a white sheet of paper in front of the camera. So when the robot releases the can, the goal associated to the dropped can (red or green) is linked to the current transition (i.e. changing the state of the gripper from closed to open when above this box). The robot then waits until the teacher demonstrates how to move from the box to its initial position or until the stress level activates the movement to the rest position. Once the loop is connected, the robot can plan the sequence of transitions to move to the position where it previously grasped the object. The robot starts reproducing the task without the help of a human. Since one of the goals (depending on the color of the last seen object) is always active, the robot will constantly try to reach that goal and thereof to drop objects at the learned places (i.e. into on of the boxes).
From its starting position, the cognitive map gives the shortest path in terms of states in order to reach the motivated transition (dropping the object into the correct box). The first step is to go to the pick-up place. If an object is detected, it is grasped and the arm proceeds to the next phase, otherwise the robot waits for an object to be presented. Here we present the red can again and let the robot reproduce what it has just been taught. The arm reaches the position above the box where it opens its gripper and goes back to the pick-up location where a new can has been placed. The action is rewarded by the human for another two reproductions, reinforcing this behavior. When the behavior has been sufficiently reinforced for the red can,the same learning process is used for the green can. The human first demonstrates how to drop the object in the second box and then lets the robot do the task, reinforcing this behavior for the next 2 reproductions. The robot is then given a series of red and green cans to verify that it correctly learned to place them in different boxes.
Conclusion
In this paper, we presented a bio-inspired model that enables a robot to build a representation of a task demonstrated through passive manipulation. This representation is based on proprioceptive states that are recruited and constitute the motor primitives of the system. It can be used by the system to plan its actions depending on visually categorized goals. Our system can continuously develop its model of the task through several interactions with humans. It was tested with a real robot on a changing pick-and-place task.
In this work, we described only one cognitive map built through interaction rather than exploration of the state space. Planning with large DOF systems can quickly lead to dimensionality problems that can be addressed by the use of hierarchical maps. We consider the integration of different layers in our cognitive map model. One cognitive map would still be mostly acquired by interacting with humans, whereas another could be completed by exploring the environment (by babbling). This level of representation would be more extensive and only called upon in cases when the robot cannot infer what to do from what it was interactively taught. Future work will also be dedicated to the integration of different control systems for the imitation of observed actions and the imitation of actions experimented through “embodying”. This raises a major action selection issue as the different systems might give different motor commands in parallel.
Finally, an interesting addition to the system would be for the robot to indicate to the human that it does not know what to do. Several works have stressed the importance of the behavior of the robot in the way the interacting human will teach it. The stress value of the motor control system only increases when the planning system cannot propose any action, it is thus a way to detect that the current knowledge is too limited to perform the task. The signal is used to trigger a return to the rest position but could also activate a visual cue indicating to the human the need for assistance. Signaling to the human that the robot needs help, e.g. by directing its gaze toward the caregiver, would lead to another interaction with the aim of addressing the current situation. If the human accepts to help the robot and demonstrates a solution, new information can be integrated in the representation of the task.
References
1. P. Bakker and Y. Kuniyoshi, “Robot See, Robot Do : An Overview of Robot Imitation,” in AISB96 Workshop on Learning in Robots and Animals, 1996, pp. 3–11.2. P. Andry, P. Gaussier, J. Nadel, and B. Hirsbrunner, “Learning Invariant Sensorimotor Behaviors: A Developmental Approach to Imitation Mechanisms,” Adaptive Behavior, vol. 12, no. 2, pp. 117–140, 2004.
3. P. Zukowgoldring and M. Arbib, “Affordances, effectivities, and assisted imitation: Caregivers and the directing of attention,” Neurocomputing, vol. 70, no. 13–15, pp. 2181–2193, 2007.
4. A. de Rengerve, S. Boucenna, P. Andry, and P. Gaussier, “Emergent imitative behavior on a robotic arm based on visuo-motor associative memories,” in Proc. IEEE/RSJ Int Intelligent Robots and Systems (IROS) Conf, 2010, pp. 1754–1759.
5. A. Billard, S. Calinon, R. Dillmann, and S. Schaal, “Survey: Robot Programming by Demonstration,” in Handbook of Robotics. MIT Press, 2008, vol. chapter 59.
6. A. J. Ijspeert, J. Nakanishi, and S. Schaal, “Learning attractor landscapes for learning motor primitives,” in advances in neural information processing systems 15. cambridge, ma: mit press, 2003, pp. 1547–1554.
7. S. Calinon, F. Guenter, and A. Billard, “On Learning, Representing and Generalizing a Task in a Humanoid Robot,” IEEE transactions on systems, man and cybernetics, vol. 37, no. 2, pp. 286–298, 2007.
8. R. Dillmann, O. Rogalla, M. Ehrenmann, R. Z?ollner, and M. Bordegoni, “Learning Robot Behaviour and Skills Based on Human Demonstration and Advice: The Machine Learning Paradigm,” 1999.
9. S. Ekvall and D. Kragic, “Robot learning from demonstration: a tasklevel planning approach,” International Journal of Advanced Robotic Systems, 2008.