
Abstract
Maintenance
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the master's work
- 3. Description of the method PIV
- 4. Overview of parallel computing techniques
- 4.1 Classification of architectures of parallel computing systems
- 4.2 Hardware‐solutions
- 4.3 Software‐solutions
- Conclusions
- List of sources
Introduction
Nowadays, the range of tasks that require for their solution the use of powerful computing resources is constantly growing. This is due to the fact that there have been fundamental changes in the organization of scientific research. Due to the widespread introduction of computer technology, has increased significantly the direction of numerical modeling and numerical simulation. Numerical simulation by filling the gap between physical experiments and analytical approaches possible to study phenomena that are either too complex for the study of analytical methods are either too expensive or dangerous for the pilot study. In this numerical experiment will significantly reduce the cost of the process of scientific and technological search. It has become possible to simulate a real-time processes of intensive physical, chemical and nuclear reactions, the global atmospheric processes, the processes of economic and industrial development of regions, etc. Obviously, the solution of large-scale problems require significant computational resources.
1. Relevance of the topic
Currently, there are several implementations of Particle Image Velocimetry (PIV) [1], but none of them does not support distributed parallel computing, which could increase the speed at times. Due to the increase in productivity, will enable more rapid change in the parameters of the object.
This method is widely used in various fields of science and technology. The most popular application — a simulation of the behavior of the fluidized bed.
Currently, fluidized bed was used in a wide range of areas: food (coffee, tea, cereal, etc.), chemicals (polymers, polycarbonates, detergents, etc.), other industries (activated carbon, gypsum, sand, etc.). Particularly important application of fluidized bed in the energy field for the Bole effective combustion and reduce emissions.
2. The purpose and objectives of the master's work
The purpose of master's work is to speed up the PIV method, by means of parallel programming.
The objectives of the study are existing systems that implement the method of PIV, the analysis methods parallel computing processes, the use of one of the ways to speed up the implementation of the method of PIV. It is also necessary to conduct a comparative analysis of the speed of the system under different system configurations, to identify the optimum operating parameters, as well as to accelerate the research capabilities of computational processes.
3. Description of the method PIV
Imaging techniques to study the flows were known long before the advent of electronic computers. The first observation of fluid flow in reservoirs with the help of natural tracers were described by Leonardo da Vinci. Ludwig Prandtl (1875-1953) used a suspension of mica particles on the surface to analyze the flow of cylinders, prisms, and wing profiles in the experimental channel.
Gradually, from the qualitative observations there was a shift to measuring quantitative characteristics of the currents, and 60th years of XX century, a broad trend in diagnostics, known as "stroboscopic imaging." The principle of stroboscopic flow visualization techniques is to measure the displacement of tracer in a given section of the flow of liquid or gas for a known time interval. The domain measurement is the plane illuminated by a light blade (Fig. 1) [2].
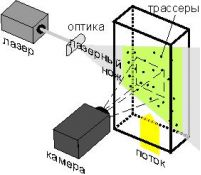
Figure 1 — Stroboscopic imaging
Разрешить написание латиницей The result is a measurement of the instantaneous velocity field in the measuring plane. One of the most representative works of the local time is the article [3], which shows the measured velocity fields and turbulent fluctuations in the boundary layer on a plate obtained by the manual handling of tracer pictures recorded on photographic film. However, manual processing was time consuming, takes a long time and is not possible to obtain sufficient data to calculate the statistical characteristics. This situation is typical for all research groups in the world, engaged in a quantitative flow visualization.
The emergence of the term PIV (Particle Image Velocimetry) — an international name for a method of digital flow visualization techniques, associated with the work of [4] in which the PIV method was selected as a special case of laser speklometrii LSV (Laser Speckle Velocimetry) [5] based on optical Fourier transform of the brightness of pictures.
An example of image processing method of PIV is shown in Figure 2.

Figure 2 — Image processing method of PIV (animation: 7 shots, 5 cycles of repetition, 163 KB)
4. Overview of parallel computing techniques
4.1 Classification of architectures of parallel computing systems
The earliest and best known is the classification of computing architectures, proposed in 1966 by M.Flinn. The classification is based on the concept of flow, which is defined as a sequence of elements, commands, or data processed by the processor. Based on the number of streams of commands and data streams Flynn identifies four classes of architectures: SISD, MISD, SIMD, MIMD.
SISD (single instruction stream / single data stream) — a single instruction stream and single stream of data (Fig. 3.a). This class includes the classical sequential machine, or another machine von Neumann type, for example, PDP-11 or VAX 11/780. In such machines there is only one stream of commands, all commands are processed sequentially one after the other and each team will initiate a single operation with a single data stream. It does not matter the fact that to increase the speed of processing of commands and speed of execution of arithmetic operations can be applied pipelining - as a CDC 6600 machine with scalar functional units, and CDC 7600 with conveyor fall into this class.
SIMD (single instruction stream / multiple data stream) — a single instruction stream and multiple data stream (Fig. 3.b). In architectures of this kind remains a stream of commands, including, in contrast to the previous class, the vector commands. This allows you to perform one arithmetic operation on many data at once — the elements of a vector. Way to perform vector operations is not specified, so the processing elements of a vector processor can be made either by the matrix, as in the ILLIAC IV, or through the pipeline, such as a car CRAY-1.
MISD (multiple instruction stream / single data stream) — the type of parallel computing architecture, where multiple functional units (two or more), perform various operations on the same data (Fig. 3.c).
Fault-tolerant computers that perform the same command is redundant in order to detect errors, as follows from the definition, belong to this type. This type is sometimes referred pipelined architecture, but not all agree with that, because the data will be different after processing at each stage in the pipeline. Some include a systolic array processor architecture for MISD.
It was created by a little computer with MISD-architecture, as MIMD and SIMD often are more suitable for general data parallel techniques. They provide better scaling and use computing resources than the architecture MISD [6].
MIMD (multiple instruction stream / multiple data stream) — a multiple instruction stream and multiple data stream (Fig. 3.d). This class assumes that the computer system has multiple devices processing commands combined into a single complex and working with her every command and data flow [7].
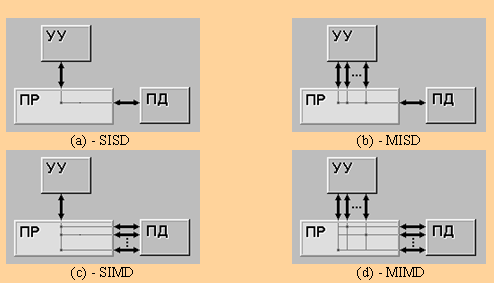
Figure 3 — Types of architecture of Flynn
4.2 Hardware‐solutions
Power of modern processors is sufficient to solve the basic steps most of the tasks and the union of several tens of processors to quickly and effectively to solve many tasks, without the need for mainframes and super computers.
An idea to create a parallel computer systems from public computers based on Intel processors and low-cost Ethernet-networks by installing Linux on these machines, and by combining with one of the freeware communication libraries (PVM or MPI), these computers in the cluster. Experiments have shown that in many classes of problems, and a sufficient number of nodes, such systems provide the performance, which can be obtained by using expensive supercomputers [8].
Also, in addition to cluster technology used by the architecture CUDA. CUDA - a hardware and software architecture that allows to perform calculations using graphics processors NVIDIA, enabled for GPGPU (arbitrary computation on graphics cards).
CUDA SDK allows programmers to implement a special simplified dialect of the C programming language algorithms feasible on GPU NVIDIA, and include special features in the text by a C program. CUDA gives developers the opportunity to organizing your own access to the graphics accelerator instruction set and manage their memory, to organize it difficult parallel computing [9]
Also, to meet the challenges of parallel programming multi-core processors can be used in conjunction with special software and libraries, for example, Microsoft Parallel Extensions to the. Net Framework.
4.3 Software‐solutions
To implement clustering technology, there are several communication libraries. Consider two of them: PVM and MPI.
PVM (Parallel Virtual Machine) is a software package that allows Unix unites and / or Windows computers over the network, and thus can be used as a single large parallel computer. Thus large computational problems can be solved more efficiently and effectively, using a set of power and memory of many computers. PVM enables users to use their existing hardware to solve the problem at minimal cost [10].
MPI stands for "Message passing interface" ("The messaging interface"). MPI — a standard software tool for communication between the separate processes of parallel tasks. MPI provides the programmer with a single mechanism of interaction processes within the parallel executable tasks, regardless of computer architecture (uniprocessor, multiprocessors with shared or separate memory), the mutual disposition processes (on the same physical processor or different) and the API of the operating system [11].
For implementation of parallel computing on GPU (CUDA) or CPU (multi-core processors), you can use OpenCL or OpenMP.
OpenCL (Open Computing Language) — a framework for writing computer programs related to parallel computing on different graphics (born GPU) and CPUs (English CPU) [12].
OpenMP (Open Multi-Processing) — an open standard for parallel programming languages C, C + + and Fortran. Describes a set of compiler directives, library routines and environment variables, which are designed for programming multithreaded applications on multiprocessor systems with shared memory.
Conclusions
To solve this problem will be used by a cluster consisting of multiple computers. The operating system will be used by Windows, and as a means of parallel computing using sockets. To implement clustering technology is applicable communication library MPI.
These tools were chosen based on the relatively low cost, availability and relatively easy project. Also, at the expense of such a structure possible user-friendly configuration of the system and increase productivity by add computers to the cluster.
List of sources
- Метод Particle Image Velocimetry: основы систем цифровой трассерной визуализации. [Электронный ресурс]. – 2011. – Режим доступа: http://cameraiq.ru/faq/flow_diagnostics/PIV_method/PIV_basic. – Загл. с экрана.
- PIV-метод. [Электронный ресурс]. – 2011. – Режим доступа: http://www.laser-portal.ru/content_184#_ftn1. – Загл. с экрана.
- Хабахпашева Е.М., Перепелица Б.В. Поля скоростей и турбулентных пульсаций при малых добавках к воде высокомолекулярных веществ // ИФЖ. 1968. T. 14, № 4. C. 598.
- Adrian R.J. Scattering particle characteristics and their effect on pulsed laser measurements of fluid flow: speckle velocimetry vs. particle image velocimetry // Appl. Opt. 1984. Vol. 23. P. 1690–1691
- Meynart R. Convective flow field measurement by speckle velocimetry // Rev. Phys.Appl. 982. Vol. 17. P. 301–330.
- MISD. [Электронный ресурс]. – 2011. – Режим доступа: http://ru.wikipedia.org/wiki/MISD. – Загл. с экрана.
- Воеводин В.В. Классификация Флинна. [Электронный ресурс]. – 2011. – Режим доступа: http://www.parallel.ru/computers/taxonomy/flynn.html. – Загл. с экрана.
- Сбитнев Ю.И. Параллельные вычисления. [Электронный ресурс]. – 1998-2011. – Режим доступа: http://cluster.linux-ekb.info. – Загл. с экрана.
- CUDA. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/CUDA. – Загл. с экрана.
- Parallel Virtual Machine. [Электронный ресурс]. – 2011. – Режим доступа: http://www.portablecomponentsforall.com/edu/pvm-ru. – Загл. с экрана.
- Сбитнев Ю.И. Кластеры. Практическое руководство. – Екатеринбург, 2009. – 45 с.
- OpenCL. [Электронный ресурс]. – 2012. – Режим доступа: http://ru.wikipedia.org/wiki/OpenCL. – Загл. с экрана.