
Реферат за темою випускної работи
Зміст
1. Цілі і завдання дослідження, заплановані результати
2. Аналітична модель обчислення продуктивності мережевого процесора
3. Аналіз за допомогою мережевого графіка
4. Створення мережевого графіка
5. Апроксимація кривих обслуговування і вхідних потоків
Вступ
Щомиті в телекомунікаційних мережах відбувається обмін великою кількістю пакетів, які повинні оброблятися різним чином. Для підтримки дієздатності мереж і обробки даних пакетів служать такі пристрої як свiтчi, адаптери, роутери, брандмауери і тому інше.
Кількість пакетів, які необхідно обробити мережевим системам, весь час збільшується, в той же час, обробка пакетів стає все більш і більш складною. Це створює гігантську проблему продуктивності. Вирішити дану проблему допомогають мережеві процесори.
1. Цілі і завдання дослідження, заплановані результати
У даній роботі буде показано, яким чином можливо аналітично обчислити продуктивність мережевого процесора. Основні завдання дослідження:
1. Розглянути існуючу аналітичну модель обчислення продуктивності мережевого процесора.
2. Дослідити характеристики, що впливають на продуктивність мережевого процесора.
3. Вивчити поняття мережевого графіка.
4. Провести аналіз продуктивності типової архітектури мережевого процесора, за допомогою мережевого графіка.
Об'єкт дослідження: продуктивність мережевого процесора.
Предмет дослідження: аналітична модель обчислення продуктивності мережевого процесора.
У рамках магістерської роботи планується отримання актуальних наукових результатів за наступними напрямками:
1. Дослідження мережевих процесорів: вимоги надані до архітектури, основні модулі, алгоритми роботи.
2. Дослідження впливу топології мережі на її характеристики.
3. Побудова експертної системи, що моделює оптимальні архітектури мережевих процесорів, виходячи із заданої конфігурації мережі.
Для експериментальної оцінки отриманих теоретичних результатів і формування фундаменту наступних досліджень, в якості практичних результатів планується розробка системи, що дозволяє підібрати оптимальну архітектуру мережевого процесора, виходячи із заданих вимог, розрахувати різні характеристики, як мережевого процесора так і мережі в цілому.
2. Аналітична модель обчислення продуктивності мережевого процесора
Мережевий процесор розглядається як колекція різних елементів обробки(таких як CPU, ядро, мікро-пристрої, і спеціальні юніти, такі як шифратор, апаратний класифікатор і так далі) і модулів пам'яті, які з'єднані між собою комунікаційними шинами. [1] На кожному з цих елементів обробки реалізується одна або більше задач обробки. Залежно від послідовності, в якій ці завдання обробляють пакет, і зв'язку цих завдань з різними елементами обчислення мережевого процесора, будь-який пакет, що надходить в мережевий процесор, проходить через специфічну послідовність різних елементів обробки. Потік, якому належить пакет, пов'язаний зі своєю кривою вхідного потоку. Таким чином, всі ресурси мають свої сервісні криві (криві обслуговування). Так як пакети в потоці рухаються від одного елемента обробки до іншого, а також проходять через комунікаційні ресурси, такі як шини, обидві криві: сервісні та вхідного потоку, — будуть модифіковані згідно формулам, які наведені нижче:
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
![]() (4)
(4)
, де ![]() —потік пакетов, після обробки ресурсом
—потік пакетов, після обробки ресурсом ![]() ,
, ![]() і
і ![]() — верхня і нижня крива вхідного потоку. Аналогічно,
— верхня і нижня крива вхідного потоку. Аналогічно,![]() и
и ![]() — верхня і нижня криві залишившихся сервісів ресурсу
— верхня і нижня криві залишившихся сервісів ресурсу ![]() .
.
Звідси, максимальна затримка наскрізної передачі даних будь-якого пакета, необхідна пам'ять чіпа мережевого процесора і утилізація різних ресурсів, може бути обчислена за формулами (5), (6) і (7) відповідно.
![]() (5)
(5)
![]() (6)
(6)
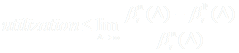 (7)
(7)
Формально процедури, представлені вище, являють
собою наступне. Для безлічі потоків ![]() , що входять до мережевого процесора, існує граф завдань
, що входять до мережевого процесора, існує граф завдань ![]() . Будь-яка вершина
. Будь-яка вершина ![]() означає комунікаційну задачу або завдання обробки. Для будь-якого потока
означає комунікаційну задачу або завдання обробки. Для будь-якого потока ![]() , визначимо набір завдань пакетної обробки
, визначимо набір завдань пакетної обробки ![]() , які мають бути реалізовані всіма пакетами
, які мають бути реалізовані всіма пакетами ![]() . На додаток, підмножина спрямованих ребер
. На додаток, підмножина спрямованих ребер ![]() визначає порядок, в якому завдання в
визначає порядок, в якому завдання в ![]() повинні бути реалізовані для будь-якого пакета
повинні бути реалізовані для будь-якого пакета ![]() . Таким чином, якщо
. Таким чином, якщо ![]() являє собою дві задачі, такі, що для будь-якого пакета, який належить
являє собою дві задачі, такі, що для будь-якого пакета, який належить ![]() , задача
, задача ![]() повинна бути виконана
негайно після задачі
повинна бути виконана
негайно після задачі ![]() , то спрямоване ребро
, то спрямоване ребро ![]() належить множині
належить множині ![]() . Звідси, для кожного потоку
. Звідси, для кожного потоку ![]() існує унікальний
шлях через граф
існує унікальний
шлях через граф ![]() , починаючи від однієї з його вершин джерел і закінчуючи
однією з вершин одержувача. Вершини цього шляху являють собою задачі
пакетної обробки, які реалізовані на пакетах, що належать
, починаючи від однієї з його вершин джерел і закінчуючи
однією з вершин одержувача. Вершини цього шляху являють собою задачі
пакетної обробки, які реалізовані на пакетах, що належать ![]() .
.
рисунок 1 показує гіпотетичну блокову архітектуру мережевого процесора [2,3]. PPC позначає ядро Power-PC 440, PLB і OPB — дві шини, які є локальною шиною процесора і переферической шиною чіпа. Цифри на стрілках в даному рисунку, визначають порядок дій, які виконуються різними блоками в процесі руху пакета через архітектуру.
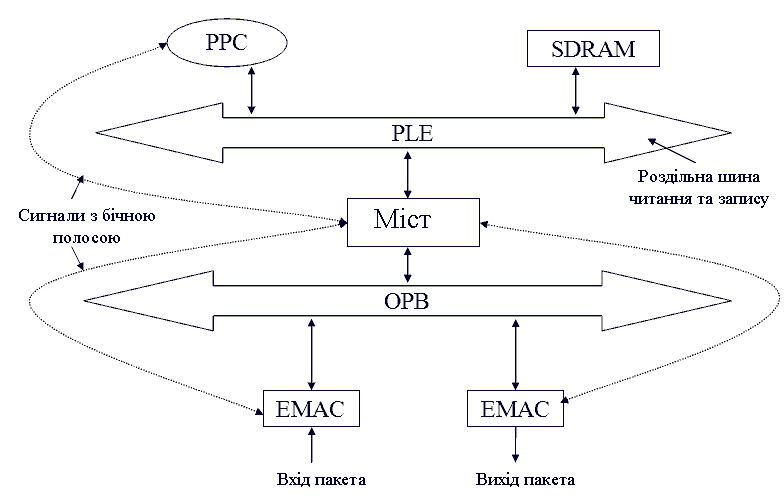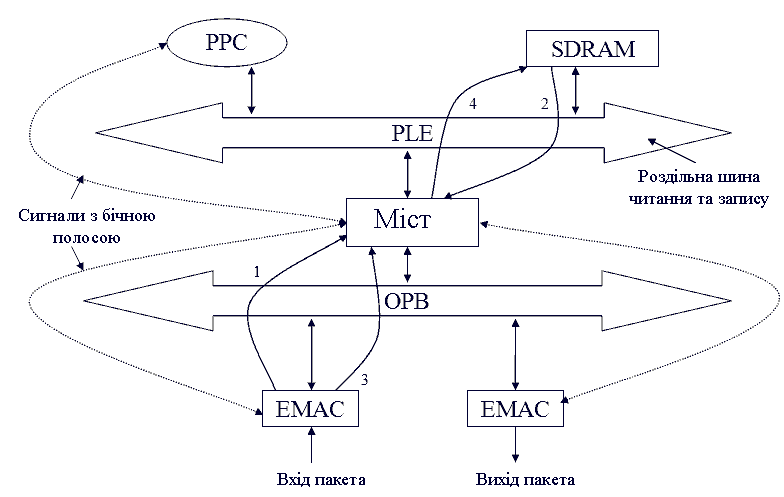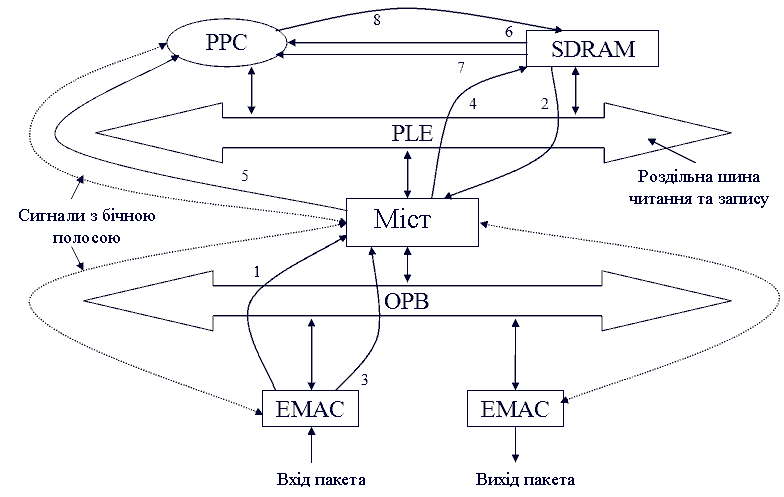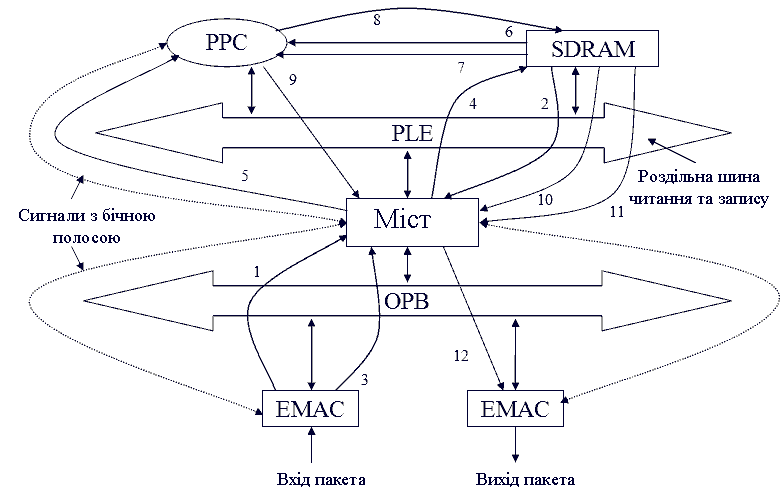
Рисунок 1 - Гіпотетична блокова архітектура мережевого процесора. Анімация виконана за допомогою Photoshop CS2. Затримка: 1с, затримка після фінального кадру: 2с. Кількість кадрів: 12. Приблизний розмір: 30Кб.
Виходячи з рисунка 1, можна побудувати графік завдань у відповідності з необхідним маршрутом пересилки пакету від одного ресурсу до іншого. Цей графік задач може бути використаний для обчислення навантаження на різних шинах (таких як OPB або PLB), вимог до пам'яті чіпа даної архітектури для зберігання буферізірованний пакетів і затримки при пересилання пакетів.
3. Аналіз за допомогою мережевого графіка
Вихідна крива вхідного потоку охоплює характеристики оброблюваного потоку пакетів (наприклад, його пакетні дані), які можуть відрізнятися від характеристик потоку, наявних до входу в ресурс. Таким чином, виходить, що сервісна крива показує можливості ресурсу для обробки, які залишилися після обробки потоку. Ідея полягає у використанні даної вихідної кривої вхідного потоку, як входу в інший ресурсний вузол (точніше, вузол ресурсу, в якому відбувається наступна задача обробки пакета, визначена графіком завдань, описаним вище). Аналогічним чином, виходить, що сервісна крива першого ресурсу використовується для обробки пакетів з можливого другого потоку. Дана процедура, відповідна пересилці пакетів в архітектурі, яка зображена на рисунку 1. [4]
У загальному випадку, безліч потоків входить в мережевий процесор і обробляється різними ресурсами в порядку, визначеному графіком завдань описаним вище. Так як пакети з декількох потоків перебувають у ресурс, вони обслуговуються в порядку, визначеному політикою планування, яка реалізована на ресурсі. Наприклад, кілька шин використовують схему фіксованих пріоритетів управління доступу шиною. Інші правила планування можуть використовувати FCFS (first-come-first-serve) або схему циклічного обслуговування. Тут ми ілюструємо аналітичну модель, припускаючи, що всі ресурси мають фіксований пріоритет. Однак, дана модель може бути з легкістю розширена для роботи з іншими правилами планування. Припустимо, що існує У схемі з фіксованими пріоритетами, ![]() потоків
потоків ![]() , які надходять до ресурсу
, які надходять до ресурсу ![]() . Даний ресурс, в свою чергу, обслуговує ці потоки в
порядку зменшення пріоритету, тобто,
. Даний ресурс, в свою чергу, обслуговує ці потоки в
порядку зменшення пріоритету, тобто, ![]() має найбільший
пріоритет, а
має найбільший
пріоритет, а ![]() наіменьший. Для
кожного пакета потоку
наіменьший. Для
кожного пакета потоку ![]() , деяка задача по обробці пакета, яка реалізована на
ресурсі
, деяка задача по обробці пакета, яка реалізована на
ресурсі ![]() , обробляє даний пакет і потребує
, обробляє даний пакет і потребує ![]() элементів обробки
элементів обробки ![]() . Наприклад,
. Наприклад, ![]() може бути кількістю інструкцій процесора або циклами шини, якщо
може бути кількістю інструкцій процесора або циклами шини, якщо ![]() — комунікаційний ресурс. З цього моменту позначимо
— комунікаційний ресурс. З цього моменту позначимо ![]() , как
, как ![]() , де
, де ![]() — номер ресурса. Кожний потік
— номер ресурса. Кожний потік ![]() , що надходить до ресурсу
, що надходить до ресурсу ![]() , пов'язан з його верхніми і нижніми кривими вхідного потоку
, пов'язан з його верхніми і нижніми кривими вхідного потоку ![]() и
и ![]() відповідно і
отримує обслуговуючий сервіс із
відповідно і
отримує обслуговуючий сервіс із ![]() , який може бути прив'язаний до верхніх і нижніх кривих
обслуговування
, який може бути прив'язаний до верхніх і нижніх кривих
обслуговування ![]() и
и ![]() відповідно. Сервіс, доступний із
відповідно. Сервіс, доступний із ![]() в незавантаженому стані, прив'язаний до верхніх і нижніх кривих обслуговування
в незавантаженому стані, прив'язаний до верхніх і нижніх кривих обслуговування ![]() и
и ![]() відповідно.[5]
відповідно.[5]
![]() обслуговує потоки в
порядку зменшення пріоритетів крива залишившихся сервісів потоку використовується
для обслуговування потоків з більш низькими пріоритетами.
обслуговує потоки в
порядку зменшення пріоритетів крива залишившихся сервісів потоку використовується
для обслуговування потоків з більш низькими пріоритетами. ![]() . Якщо
. Якщо ![]() і
і ![]() вихідні криві вхідного потоку з вузла ресурсу
обчислюються за допомогою формул
(1) — (2), то
вихідні криві вхідного потоку з вузла ресурсу
обчислюються за допомогою формул
(1) — (2), то ![]() и
и ![]() . Функції мінімуму/максимуму використовуються з моменту, коли
вузол ресурсу може почати обробку пакета і тільки після того як завдання,
реалізовано на
. Функції мінімуму/максимуму використовуються з моменту, коли
вузол ресурсу може почати обробку пакета і тільки після того як завдання,
реалізовано на ![]() , буде закінчено.
, буде закінчено.
Отже, дані криві обслуговування для незавантаженого ресурсу ![]() і
і ![]() , та криві вхідного потоку
, та криві вхідного потоку ![]() , показують, як можуть бути визначені криві обслуговування
, показують, як можуть бути визначені криві обслуговування ![]() и
и ![]() . Як було описано вище:
. Як було описано вище:
![]() ,
, ![]() ,
, ![]()
![]()
![]()
![]()
![]()
![]()
![]() ,
, ![]() ,
, ![]()
, де ![]() и
и ![]() для
для ![]() визначено з формул
(3) і (4). У кінцевому рахунку, сервісні криві, що залишилися після
обробки всіх потоків мають вигляд:
визначено з формул
(3) і (4). У кінцевому рахунку, сервісні криві, що залишилися після
обробки всіх потоків мають вигляд:
![]()
![]()
Описане вище може бути використано для обчислення
максимальної утилізації ресурсу, використовуючи нерівність (7). Оброблені потоки з їх результуючими кривими вхідного потоку ![]() и
и ![]() тепер входять у вузол
ресурсу для подальшої обробки.
тепер входять у вузол
ресурсу для подальшої обробки.
4. Створення мережевого графіка
Використовуючи раніше отримані результати можна описати процедуру створення мережевого графіка. Він може бути використаний для визначення властивостей архітектури, таких як вимоги до пам'яті чіпа, затримки в передачі пакетів та утилізація різних ресурсів чіпа, таких як процесори і шини.
Входи необхідно конструювати, розглядаючи мережу як графік завдань, який визначає для кожного потоку послідовність завдань обробки пакетів, які будуть виконані для кожного пакета потоку. Також необхідно брати в облік цільову архітектуру, на якій ці завдання будуть виконуватися.
Мережевий графік містить один вузол джерела і вузол
ресурсу і один вузол цільового ресурсу. Тобто, для кожного потоку
пакетів існує вузол джерела пакетів та цільовий вузол пакета. Для кожного
завдання обробки пакета потоку існує вузол в мережі, позначений завданням і
ресурсом, на якому це завдання виконується.[6] Для
двох послідовних завдань потоку ![]() и
и ![]() , якщо
, якщо ![]() імплементована на
ресурсі
імплементована на
ресурсі ![]() , а
, а ![]() на ресурсі
на ресурсі ![]() , то існує грань в мережевому графіку з вузла
, то існує грань в мережевому графіку з вузла ![]() до узла
до узла ![]() . Для даного потоку, якщо
. Для даного потоку, якщо ![]() и
и ![]() — две завдання, що виконуються на одному
ресурсі
— две завдання, що виконуються на одному
ресурсі ![]() и
и ![]() передує
передує ![]() в графі завдань, то
існує грань з вузла
в графі завдань, то
існує грань з вузла ![]() в узел
в узел ![]() .
.
Криві вхідних потоків і криві облуговування ресурсів проходять з одного вузла в інший в мережевому графіку і змінюються в процесі, відповідно до формул (1) — (4).
Для даного потоку ![]() , приймемо верхньої кривої вхідного потоку
, приймемо верхньої кривої вхідного потоку ![]() , перед входом в мережевий процесор. Припустимо, що цей
потік проходить через вузли мережевого графіка, який має вхідні нижні
сервісні криві рівні
, перед входом в мережевий процесор. Припустимо, що цей
потік проходить через вузли мережевого графіка, який має вхідні нижні
сервісні криві рівні ![]() . Тоді
. Тоді ![]() , яка використовується для облуговування даного потоку може
бути обчислена таким чином:
, яка використовується для облуговування даного потоку може
бути обчислена таким чином:
![]() ,
,
![]()
![]() ,
,
![]()
Звідси, максимальна затримка і загальна кількість
невиконаних завдань по відношенню до пакетів потоку ![]() можуть бути розраховані
за допомогою формул (8) та (9) відповідно.
можуть бути розраховані
за допомогою формул (8) та (9) відповідно.
![]() (8)
(8)
![]() (9)
(9)
5. Апроксимація кривих обслуговування і вхідних потоків
Формули (1) — (4) надмірні для обчислення звичайних кривих обслуговування та вхідного потоку. Більш того, ці формули повинні перераховуватися для всіх вузлів мережного графіка.[7] В доповнення, якщо криві переважно отримані з сліду пакета, то результуючі криві можуть бути описані кількома параметрами, такими як максимальний розмір пакета, швидкість передачі пакетів, швидкість прибуття пакетів. Виходячи з цього, можна запропонувати кусково лінійну апроксимацію кривих обслуговування і прибуття. використовуючи дану апроксимацію, формули (1) — (4) будуть обчислюватися більш ефективно.
Кожна крива, в цьому випадку, апроксимується, використовуючи комбінацію трьох сегментів лінії. Це дозволяє нам точно змоделювати криву прибуття в форматі T-SPEC, яка широко використовується в комунікаційних мережах.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: січень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Список джерел
1. IBM Blue Logic. Режим доступу http://www.chips.ibm.com/bluelogic свободный.
2. IBM сoreconnect bus architecture. Режим доступу http://www.chips.ibm.com/products/coreconnect свободный.
3. S. Shenker, J. Wroclawski, General characterization parameters for integrated service network elements, RFC 2215, IETF, September 1997.
4. S.G. Abraham, B.R. Rau, R. Shreiber, Fast design space exploration through validity and quality filtering of subsystem designs, Technical Report HPL-2001-220, Compiler and Architecture Research Program, Hewlett Packard Laboratories, August 2000.
5. A. Agarwal, Performance tradeoffs in multithreaded processors, IEEE Transactions on Parallel and Distributed Systems 3 (5) (1992) 525–539.
6. Alpha Architecture Reference Manual, Digital Press,1992.
7. J.Y. Le Boudec, P. Thiran, Network Calculus––A Theory of Deterministic Queuing Systems for the Internet, Lecture Notes in Computer Science, vol. 2050, Springer, Berlin, 2001.
8. D.C. Burger, T.M. Austin, The SimpleScalar tool set, Technical Report CS-TR-1997-1342, University of Wisconsin, Madison, 1997.
9. Samarjit Chakraborty, Simon Kunzli, Lothar Thiele, Andreas Herkersdorf, Patricia Sagmeister. “Performance evaluation of network processor architectures: combining simulation with analytical estimation”. Computer Engineering and Networks Laboratory, Swiss Federal Institute of Technology (ETH) Zurich, Gloriastrasse 35, CH-8092 Zurich, Switzerland.