
Abstract on the theme of masters work
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Capturing an image with face from the video shot
- 4. Convolution Neural Network
- 5. Software model
- Conclusion
- References
Introduction
The problem of pattern recognition refers to the class of problems that are difficult to formalize. At the present time, it is particularly urgent because of the need to automate the processes of communication (visual, verbal) in the intellectual systems. Therefore, the search and implementation methods of human recognition by computer systems continue. Artificial neural networks are very perspective to solve the problems of this class. They are induced by biology, because they composed of the elements the functionality of which are similar to most elementary functions of a biological neuron. Despite superficial similarities, artificial neural networks demonstrate properties that are the characteristic of the living brain. Particularly, they are trained on the base of experience. They then generalize the previous precedents on new examples and extract essential properties of the incoming information, which includes extra data [1].
1. Theme urgency
In recent years the problem of recognition human faces has become increasingly important. Face recognition is a practical application of pattern recognition theory, which task includes automatic localization of the face on the photo and, if necessary, identification of the person by the face. Face recognition is applicable in the following areas: security systems, forensics, computer graphics, human-computer interaction, virtual reality, computer games, e-commerce, personalization and data protection, etc. Thus, the relevance of this problem takes place [2].
Master's thesis is devoted to an actual scientific problem of pattern recognition, where the image appears as the picture of human face. We get the image from the video shot. In fact, the problem is divided into two subproblems. First, person stands out from the video flow. Then there is recognition of the selected face. Platform Java SE, IDE Eclipse, and several supporting libraries are used as tools.
Great contribution to the development of the theme of pattern recognition in DonNTU was made by Oleg Fedyaev and his masters S. Kulikov, K. Driga, Yu. Makhno, G. Kostetsckaya, A. Sowa, and others.
The research of this topic has been conducted since the 80s in the world. Jan LeKun an American scientist, made a great contribution to the development of systems of pattern recognition using neural networks. Intel Corporation wrote its own open source library of computer vision OpenCV [3], that is accessable to everybody.
2. Goal and tasks of the research
The aim of this research is to develop a subsystem that will accurately detect human faces in real time. Such system can be used to identify individuals such as students, members of the lecture audience.
The main purposes of the research are:
- To search for a method that selects with maximum accuracy of images of human faces in a picture from the video flow.
- To design a parametric model of the convolutional neural network.
- To construct the logical and physical model of the convolutional neural network.
- To develop software model of face recognition.
Object of research: neural network face recognition system.
Subject of research: The structure of convolution neural network and its learning algorithms, algorithms for the selection of faces from the video flow.
Actual scientific results are planned to receive the following areas within the master's thesis:
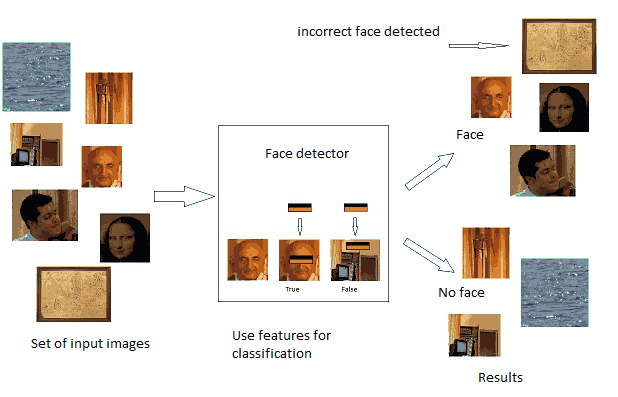
Currently the problem of recognition human faces is becoming more relevant. The process of direct face recognition
precedes an important stage in automatic localization of faces in the picture, the methods of implementation
which are currently being actively developed. The Viola-Jones method is considered below [4].
Despite the fact that this method was described in 2001, it remains one of the most efficient algorithms of face selection.
Also, this algorithm was on the top 10 algorithms of artificial intelligence [5] in 2007 year.
It's based on Adaptive boosting algorithm[6].
There is a set of standard objects, i.e. image and the class to which it belongs (-1 – no faces in the picture, 1 – there is a face).
Besides, there are a number of simple classifiers, from which we can build more sophisticated and powerful one.
In the multi-step process of compilation and training of the final classifier emphasis are made on standards,
which are recognized worse. Algorithm adapts to the most
Figure 1 – The idea of the Viola-Jones algorithm The algorithm is based on three key concepts:
a) Usage of the "Integral Image" which allows to calculate the area of the scanning window in several times
faster than the algorithm for the detection of skin color. The integral image at point (x, y) includes
the amount of pixels that are located to the left of and above the image:
where ii(x,y) – value of the integral image at (x,y) point. The following recurrence formulas are used to calculate the integral image:
where s(x,y) – accumulated sum of the line, s(x,-1)=0,
ii(-1, y)=0. b) An adaptive learning algorithm selects a small number of low level signs
of more than 180 thousand characters. There are many motivations for
using signs, rather than individual pixels. The most important reason – a sign that
can encode different meanings that are difficult to define and study, using a
finite set of training data. Signs are computed faster than pixel values
that will be discussed in detail below. Viola-Jones algorithm
uses three types of signs: two rectangles, three and four rectangles.
A cascade of classifiers constructs on these classifications.
Each element of the next stage has more stringent conditions of passing than the previous one (using
more primitives). Thus only the
Figure 2 – Boosting's algorithm Boosting is used for
selection of a small finite set of features for a high-level training
classifier. For training the neural network classifier a simple
(weak) learning algorithm is used.
c) Usage of the cascade of Haar [7], which selects a small
number of features and combines them into a higher level of symptoms.
As a result we get a cascade of 38 steps on a large data set consisting of 507 individuals
with more than 75 million scanning windows. Faces are recognized with 10 features per second
calculation for each window. The resulting detector slides on the image in different scales.
Thus the invariance is archived.
Neural networks are successfully used for solving many problems of pattern recognition: recognition of
character, object recognition, and many others. Currently classic neural network architectures are used for solving problems
of recognition (multi-layer perceptron network with radial basis
function, etc.), but the usage of this networks is ineffective for the following reasons: In addition, there are difficulties in applying
traditional neural networks to real problems of pattern recognition and classification of images.
First, as a rule the images have a large dimension,
respectively, grows the size of a neural network (number of neurons, weights).
A large number of parameters increases the capacity of the system and
respectively, requires more training samples, which increase
time and computational complexity of the learning process. Convolutional neural network architecture is designed to overcome these shortcomings.
Convolutional neural networks provide a partial resistance to change scale displacements,
rotations, changing angles, and other distortions.[9]. The works of French origin, the American scientist Jan LeKun focused
on solving these problems. These works are associated with the development and research of
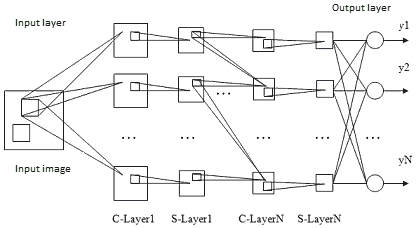
convolutional neural networks. The idea of convolutional neural networks lies in the alternation
of convolutional layers (C-layers), layers of sub-sample (S-layers) and using the output layer
neurons. Convolutional networks are based on three mechanisms used to achieve invariance to the transfer,
scale, low distortion:
Consistent application of convolution and subsampling increase the level of features:
if the first layer extracts the local features of the image areas, the subsampling layers are extracted
common features, which are called the signs of a high order.
Figure 3 shows a network of convolution, which recognizes the input image [10].
Figure 3 – Architecture of the convolutional neural network In the set-theoretic model of level the convolutional neural network (CNN) is presented in the form of a tuple 3:
where M – amount of layers in the network; η – number
of layer; 1≤η≤M; Nη –
amount of the feature cards in the η layer;
C, S – weights of the C and S layers respectively,
fη,φη –
the activation function of neuron of the η-layer,
C and S layers respectively; N – amount of neurons in the last layer of the neural network;
w – the matrix of output layer weights; ψ – the activation function of neurons of the output layer.
Parametric model does not reflect the behavioral (functional) aspect of the elements of a neural network.
This lack eliminates a logical model as class diagrams, which contains the main objects of a parametric model of the CNN, endowed with the properties and the operating ability of the neural network. Building a logic model begins with the definition of entities (classes and objects) of the system.
In figure 4, we can see the implementation of the system as a class diagram.
Based on the topology of the convolutional neural network identified the following classes:
Neuron keeps all necessary information for a neuron (inputs, weights, outputs);
abstract class BasePlane describes the workings of all types of planes (input, C-plane,
S-plane, output), training and recognition methods. Also, the structure of relations between maps of adjacent layers are realized in this class.
An abstract class SubPlane (extension of the class BasePlane) realizes methods specific to the convolutional and
subsampling planes. ImagePlane class encapsulates the work of the image, i.e., translates it into a two-dimensional array of input values and keeps the image.
ConvolutionalPlane class implements the functionality of C-layer network.
Class SubSamplingPlane is an implementation of S-layer network.
Class OutputPlane is a layer of neurons, which are completely linked to
previous network layer (S2), generates output values of the network.
NeuralNet class is a
Figure 4 – Logical model of the convolutional neural network in the form of UML diagram General view of the programming model is shown in figure 5. Stages of Software
Product are:
Figure 5 – Software neural net model of face recognition
Creating intelligent recognition systems, particularly faces
is one of the most popular topics today. This
master's paper attempts to create a software product that has several sub-tasks:
to connect to a web camera, get a shot,
release the face on this shot, create a database of faces, train convolutional neural
network and, finally, recognized a face. Steps of selection and recognition of faces
are implemented at the moment, and can work independently of each other.
The next step will be the merging of two software
products without depending on operator. Master's work is not yet complete. Final completion will be in January 2013.
The full text of the work and materials on the topic can be obtained from the author or his head after that date.
3. Capturing an image with face from the video shot
complex
objects in the learning process. This is the adaptability of the algorithm.
Figure 1 shows the idea of localization of the face in the image of this algorithm:
![]()
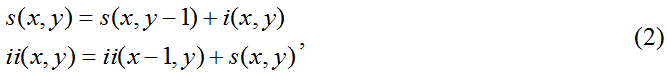
right
samples reach the end.
Education is based on the idea of boosting. Several
thousands of positive
and negative
images are required for successful learning.
Figure 2 shows the algorithm of boosting:
4. Convolutional Neural Network
Second, the lack of a full mesh architecture is that the
topology of the input is completely ignored. Input variables can be presented
in any order without affecting the goal of learning.
![]()
black box
. At the entrance we get the image and the output layer generates
output signals. In general, the layers can interact with each other [11]. 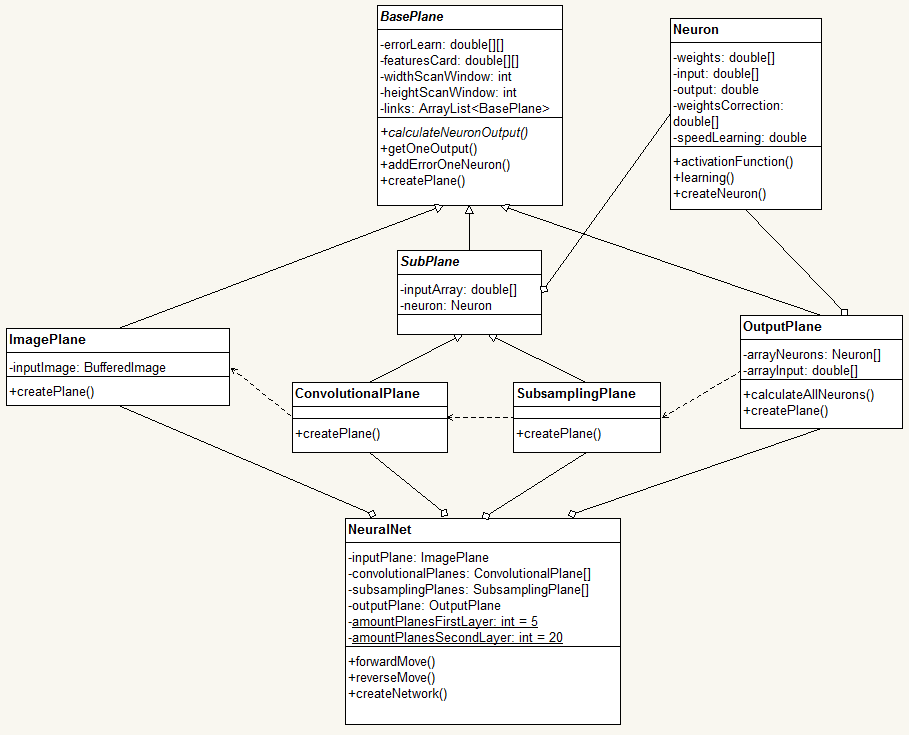
5. Software model

(animation: 9 frames, 5 cycles of repeating, 196 kilobytes) Conclusion
References