Конвейерные умножители и FPGA архитектура
Mathew Wojko
Автор перевода: Волошин Дмитрий
Факультет электроники и вычислительной техники
Университет Ньюкасла
Каллаган, NSW 2308, Австралия
Краткий обзор. В данной работе рассматриваются методы реализации конвейерных умножителей на FPGA (field-programmable gate array). Основной акцент делается на использовании аппаратных ресурсов FPGA. Производительность реализаций умножителей определяется для коммерчески доступных архитектур FPGA, которые имеют две проблемы. Это нестабильность времени задержки соединений общей коммутации и соединений статического переноса. А также объём и эффективность использования ресурсов FPGA. Для каждой из этих проблем предлагается и исследуется соответствующее решение.
Операция умножения на FPGA считается дорогой. Для реализации высокопроизводительных умножителей, которые реализуют параллельный и конвейерный принципы, требуется большое количество логических ячеек. Введение логики быстрого переноса позволило умножителям достичь приемлемых скоростей для многих DSP (digital signal processing) операций. Однако, при увеличении разрядности операндов и большом количестве логических ячеек, происходит неэффективное использование ресурсов FPGA. Это ограничивает использование FPGA для широкого спектра арифметически интенсивных и DSP приложений.
Для повышения эффективности использования FPGA ресурсов предложено несколько методов. Mintzer [6] отмечал, что при умножении на константу, использовании распределённой логики и сохранении информации о коэффициенте умножения в Look-Up Table (LUT), достигается сокращение используемых ресурсов. Run-Time Reconfiguration (RTR) используется для обновления прошивки LUTs при изменении коэффициента умножения. В прошлых работах описывалась реализация реконфигурируемого умножителя на микросхемах FPGA серии XC6200 [7,1]. Обновление прошивки LUT осуществляется через интерфейс конфигурации SRAM (static random access memory) используя заранее рассчитанные конфигурационные данные. Новый подход, названный самоконфигурируемым методом умножения, представленный автором и ElGindy [10] для FPGA серии Xilinx XC4000 выполняет реконфигурирование LUT на микросхеме. При новых данных на входе, конфигурационные данные рассчитываются на микросхеме и параллельно сохраняются в LUTs. Другая работа по улучшению эффективности аппаратной реализации умножителей предлагает встраивание Flexible Array Blocks (FABs) способных выполнять умножение 4 х 4 бита в стандартной FPGA архитектуре [2].
Однако все эти методы являются компромиссными. Для умножителей с фиксированным коэффициентом, значение коэффициента не может быть обновлено. Реконфигурация сохранённых значений требует дополнительного времени, во время которого устройство обычно находится в режиме off-line. Кроме того, в FPGA с несколькими типами логических ячеек, имеет место фрагментация аппаратных ресурсов по типу логической ячейки. Данная работа представляет два альтернативных варианта реализации умножителей для FPGA архитектуры.
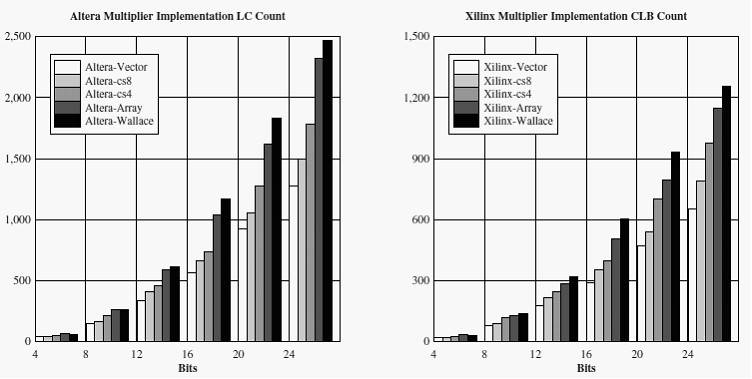
В этом разделе будут рассмотрены три метода реализации конвейерных умножителей на кристаллах Xilinx XC4036EX-2 [5] и ALTERA EPF10K70RC-2 [8]. Рассматриваются параллельный массив, параллельный сумматор (основанный на векторе) и умножитель Уолласа с сохранением переноса (за описанием методов обратитесь к [3,9,4]). При реализации всех этих методов, была проведена их конвейеризация на каждом этапе вычислений для достижения максимальной производительности. Устройства были синтезированы вплоть до физического уровня, чтобы использовать архитектурные функции (такие как статический перенос). На рисунке 1 приведено сравнение затрат логических элементов на реализацию каждого типа умножителя, а на рисунке 2 – сравнение их максимальных тактовых частот Figure 2.
Рис. 1. Аппаратные затраты на реализацию умножителей для Xilinx и Altera.
Сравнивая полученные данные можно сделать вывод, что аппаратные затраты на реализацию пропорциональны квадрату разрядности умножителя вне зависимости от целевой архитектуры и типа умножителя. Можно наблюдать относительные изменения того, как каждый тип умножителя отображается на FPGA архитектуру с 4-входовым LUT и статическим выходом переноса. Метод Уолласа предотвращает распространение значения переноса за счет дополнительной логики. Методы вектора и массива распространяют перенос на разрядность входных операндов, используя соединения статического переноса. Метод параллельного массива может быть использован при необходимости дополнительных ячеек для буферизации.
Однако максимальная тактовая частота умножителя по каждому из методов, зависит от архитектуры FPGA, как видно на рисунке 2. Это результат различий в стратегиях соединений обоих архитектур. Xilinx использует иерархическую структуру соединений, в которой длина пути сигнала зависит от длины промежутка между CLB (Configurable logic block). Архитектура Altera использует соединения, которые пересекают микросхему полностью. Для Xilinx, результаты реализации метода Уолласа при увеличении разрядности совпадают с методами массива и вектора. Для Altera существуют явные различия между ними. Это объясняется тем, что методы, основанные на массиве и векторе, широко используют соединения статического переноса, таким образом, сокращая зависимость от задержек распространения сигнала по линиям соединений общего назначения. Так как метод Уолласа не распространяет значения переноса, он не использует соединения переноса и более зависим от соединений общей маршрутизации. Результаты показывают, что архитектура Altera способна выдержать более значительные задержки соединений при увеличении разрядности операндов, чем иерархическая архитектура. Это было также проверено при анализе планов размещения и маршрутизации устройства на кристалле. Так как каналы маршрутизации становятся переполненными, определение альтернативных путей установка соединений требуют больше усилий для соединений Xilinx, чем Altera.

Рис. 2. Задержка срабатывания умножителей на микросхеме Xilinx и Altera
Данный тип умножителя (Carry Save/Propagate, CSP) был разработан как гибрид конвейерного векторного и умножителя с сохранением переноса для обеспечения конфигурируемого баланса между затратами логических элементов, максимальной тактовой частотой и использованием типов связей (статического переноса или общего назначения). За счёт задания глубины распространения переноса как параметра проекта, данная техника обеспечивает построения ряда умножителей с параметрами в диапазоне граничных вариантов от реализации умножителя на базе параллельного векторного сумматора до умножителя Уолласа.

Рис. 3. Пример 16-битного CSP умножителя с 8-битной глубиной распространения переноса
На рисунке 3 приведён пример 16-битного умножителя данного типа с 8-битной глубиной распространения переноса. Начальный массив частичных произведений приведен на уровне 1 (L1). Затем они параллельно суммируются и образуют n/2 результатов и 16 значений переноса на определённых 8-битных границах. В CSP методе переносы используются двумя способами. На каждом уровне они либо сохраняются как входной перенос для следующей ступени сложения, либо аккумулируются с другими значениями переносов для дальнейшего сложения с частичными произведениями (обозначены соответственно чёрным и серым). Операция умножения формирует два набора значений, это аккумулированные значения частичных произведений и аккумулированные значения переносов. Для уменьшения количества значений, к каждому набору применяется операция суммирования. На определённых этапах выполняется сложение с использованием накопленных значений переносов (они обозначены пунктирными овалами). Операции сложения выполняются до тех пор, пока массив значений не уменьшится до одного и не останется значений переноса, как на L7.
CSP умножитель был синтезирован с параметром распространения переноса от 4 до 8 для обоих FPGA архитектур. Затраты логических элементов и максимальные тактовые частоты приведены на рисунках 1 и 2 соответственно. При увеличении глубины распространения переноса затраты элементов снижаются так же как и максимальная тактовая частота. На рисунке 4 приведены графики функций аппаратных затрат в логарифмическом масштабе для каждой FPGA архитектуры. Для CSP умножителя, архитектура Altera способна к увеличению требований к затратам ресурсов путём балансировки использования соединений статического переноса и маршрутизации общего назначения. При этом используя больше логических элементов, то есть чем меньше глубина распространения переноса, тем выше аппаратные затраты и частота синхронизации. Архитектура Xilinx показывает увеличение затрат ресурсов, но при этом недостаточно эффективный баланс между используемыми типами соединений и требуемым количеством логических элементов.

Рис. 4. Задержки умножителей для устройств Xilinx и Alter.
Большинство параллельных методов умножения состоят из двух этапов: расчета массива частичных произведений и дальнейшего его параллельного сокращения (обычно) для получения результата операции. Рассматривая как методы умножения отображаются на архитектуры Xilinx и Altera FPGA, можно выделить два примера неэффективного использования ресурсов. Базовая архитектура логической ячейки, приведенная на рисунке 5(а), состоит их 4-входового LUT, быстрой логики статической арифметической связи и регистра. Это даёт типичное описание функциональности логической ячейки для архитектур Altera FLEX10k и Xilinx XC4000. Для первой фазы умножения (побитовая циклическая свертка) для умножителя на n-бит требует n2 2-бит AND элементов. Для расчета массива частичных произведений требуется n2 логических элементов. Реализация 2-битовых элементов AND на 4-битовых логических элементах является очень неэффективной. На второй фазе массив частичных произведений сокращается путём параллельного сложения. Пары значений складываются вместе для уменьшения количества частичных произведений вдвое на каждом этапе. Снова мы видим, что каждый логический элемент реализует полный сумматор, но при этом используется только два из четырёх входов плюс статические соединения переноса. Очевидно, что потенциальная производительность логических ячеек FPGA используется только на половину. Из-за этого, для реализации умножителей требуется большое количество логических ячеек, которые при этом используются неэффективно.
На рисунке 5(b) показана предлагаемая архитектура логической ячейки, которая гарантирует полное использование её потенциальной производительности. При этом может быть достигнуто уменьшение количества элементов, требуемых для реализации. В структуру логического элемента добавлены четыре статических межсоединения с пропускными транзисторами и элементами AND, и расширенное арифметическое устройство с четырьмя входами, двумя входными переносами, которое формирует один бит результата и два выходных переноса. Все статические межсоединения предназначены для связи между строками или столбцами и не могут быть использованы как общие входы логического элемента.
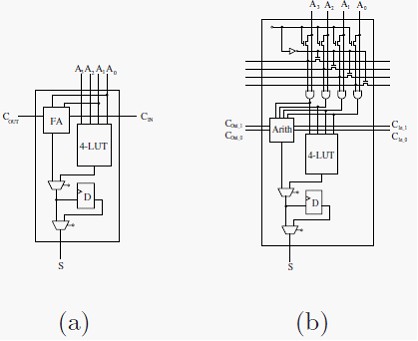
Рис. 5. Типовая и предложенная архитектуры логической ячейки.
При реализации умножителя, первая часть значений частичных произведений вычисляется при использовании четырёх верхних статических шин. Входы логического элемента могут быть коммутированы на статические шины или пропущены через элементы AND на входы LUT (конфигурированием пропускных транзисторов ячейки). Этот механизм обеспечивает выполнение операции AND для фазы операции умножения, когда четырёхбитные значения могут быть распространены на строку ячеек. Таким образом, множество 4 n-битных частичных произведений может быть сгенерировано на одной строке логических элементов. Эти значения могут быть добавлены для получения результата умножения 4 x n. Суммирование осуществляется на блоке ARITH, показанном на рисунке. Блок принимает 4 бита значений, к которым он прибавляет 2 входных переноса и формирует 3 бита результата. Бит 0 является битом результата, когда биты 2 и 3 используются последующими ячейками как биты входного переноса. Цепочка переноса требует двух бит для обеспечения сложения четырёх n-битных значений на одной строке логических элементов. Как результат, для реализации умножителя 4 x n бита, используя предложенную архитектуру, требуется n + 5 логических ячеек. В общем, для реализации умножителя n x n, используя предложенную архитектуру, требуется в 4 раза меньше логических элементов, чем при использовании стандартной архитектуры. При использовании данной структуры логического элемента, вершинная архитектура Xilinx позволяет генерировать значения частичных произведений при использовании дополнительного элемента AND, уменьшая требуемое для реализации количество логических элементов вдвое. Использование однобитной цепи переноса не даёт столь эффективного использования аппаратных ресурсов, как модифицированная логическая ячейка.
Для того, чтобы оценить эффективность модифицированного логического элемента, предлагаемые изменения были интегрированы в устройства Altera and Xilinx и сравнены с предыдущими реализациями умножителей [2]. В этой работе реализация умножителя на базе FABs сравнивается с реализациями на базе архитектур Xilinx 4000 и Altera FLEX. В качестве результатов представлено сравнение количества транзисторов и относительное количество на бит2 для каждого умножителя. Эти результаты представлены ниже в таблице 1, где также приведены результаты для модифицированных логических элементов, интегрированных в архитектуры FLEX и XC4000 для реализации векторного умножителя. Рассматривая результаты, мы можем видеть соответствующие улучшения факторов 3.79 и 3.91 транзисторов на бит для архитектур Altera and Xilinx, используя модифицированные логические элементы. Пока что данные результаты не могут достичь плотности, которая достигается при использовании FABs, они иллюстрируют то, как незначительные изменения в архитектуре существующих FPGA улучшают эффективность реализации умножителей, при этом, не меняя существующую платформу FPGA.
|
Реализация |
Транзисторов на ячейку |
Ячеек на бит2 |
Транзисторов на бит2 |
Относительная площадь |
|
FABs |
2300 |
0.0625 |
144 |
1 |
|
Altera 10k |
12000 |
0.26 |
3169 |
22 |
|
Xilinx 4000 |
3400 |
1.14 |
3880 |
27 |
|
Altera 10k Усовершенствованная |
12600 |
0.066 |
832 |
5.8 |
|
Xilinx 4000 Усовершенствованная |
3550 |
0.28 |
944 |
6.9 |
Таблица 1. Сравнение относительных требований к площади кристалла.
10. M. Wojko and H. ElGindy. Self configurable binary multipliers for LUT addressable FPGAs. In Tam Shardi, editor, Proceedings of PART’98, Newcastle, New South Wales, Australia, September 1998. Springer. 347